この記事は元々2024年8月23日に個人ブログで公開された内容をQiitaに移行したものです。
以前、Tensorflowの学習済みモデルを走らせるWeb APIを建てたいことがありました。
当時はシンプルにAWS EC2インスタンス上にPythonでWebサーバーを建てて、そこでTensorflowを実行していたのですが、これ結構無駄なお金がかかってしまっていたんです。
というのも、Tensorflowを実行するにはそこそこのインスタンスのスペックが必要(nano, microではスペック不足で動かず、最低でもmini以上が必要)であり、さらに私が建てたかったWeb APIは高頻度で呼び出されることは想定されていませんでした。つまり、「安くないタイプのインスタンスを、そんなに呼ばれないのに24時間起動し続ける」というもったいないことをしていたんですね。
最近このWeb APIを、AWS Lambdaで建て直しましたので、この記事ではその方法を共有します。
AWS LambdaでサーバーレスなAPIを建てれば、呼ばれた時だけ課金されるので、「呼ばれる頻度が高くない」という前提であればかなりコストを抑えることができます。
テンプレート用意
今回は私が以前作った「AWS Lambdaで楽にWeb APIを建てるためのテンプレ」を使っていきます。
このテンプレを使って新しいリポジトリを作成し、お手元にgit cloneしておいてください。
クローンしたら、リポジトリのルートに移動しておいてください。
※このテンプレを使ったAPIを建てる手順はすべて以下の記事で解説していますので、まずはこの記事を参照しながらサクッとWeb APIを建ててみてください。
[link]
上記の手順で無事APIを建てることができたなら、あとはこのコードを一部変更して、Tensorflowを走らせるAPIに改造していきます。
Tensorflowの公式イメージをベースにする
テンプレのDockerfileはubuntu:20.04をベースイメージにしていますが、今回はTensorflowを使う目的で、Tensorflowの公式イメージをベースにしようと思います。Dockerfileの1行目を次のように書き換えます。
FROM tensorflow/tensorflow:2.16.2
Tensorflowのバージョンは好きなものを選択してください。
ライブラリを追加する
requirements.txtを編集し、必要なライブラリを追加します。今回は例としてPillowをインストールしますが、ここではアプリケーションに必要なライブラリを自由に記述してください。
awslambdaric # This is mandatory
pillow==10.4.0
Tensorflowのベースイメージを使っているので、Tensorflowはすでにインストール済みです。ここではTensorflowを記載する必要はありません。
学習済みモデルを用意する
学習済みモデルを別途用意して、Build時にDockerイメージの中に組み込みます。
今回は例として、VGG16の学習済みモデルを使用します。VGG16はImageNetデータセットで学習された画像分類モデルで、入力画像を1000クラスに分類することができます。
VGG16の学習済みモデルは一般公開されているので、ダウンロードします。
mkdir models
curl -Lo models/vgg16_weights_tf_dim_ordering_tf_kernels.h5 https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels.h5
加えて、結果表示のために画像クラスの名前リストもダウンロードしておきます。(例えば1番目のクラスは「ドクターフィッシュ」、2番目は「ゴールドフィッシュ」といった情報ですね。)
curl -Lo models/imagenet_class_index.json https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
最後に、これらのファイルをDockerイメージに組み込むために、Dockerfileを以下のように更新します。
FROM tensorflow/tensorflow:2.16.2
RUN apt-get update && apt-get install -y python3-pip
COPY ./requirements.txt /requirements.txt
RUN pip install -r /requirements.txt
ARG APP_DIR="/app"
RUN mkdir ${APP_DIR}
COPY app.py ${APP_DIR}
COPY ./entry_script.sh /entry_script.sh
ADD ./aws-lambda-rie /usr/bin/aws-lambda-rie
# ここから
ARG MODEL_DIR="${APP_DIR}/models"
RUN mkdir -p ${MODEL_DIR}
COPY models/vgg16_weights_tf_dim_ordering_tf_kernels.h5 ${MODEL_DIR}
COPY models/imagenet_class_index.json ${MODEL_DIR}
ENV TF_CPP_MIN_LOG_LEVEL="2"
# ここまで追加
WORKDIR ${APP_DIR}
ENTRYPOINT [ "/entry_script.sh" ]
CMD [ "app.handler" ]
app.pyを書き換える
実際にどのような処理を行い、どのようなレスポンスを返すのかはapp.pyに記述します。今回はWeb APIのリクエストとして画像データを受け取り、レスポンスとしてVGG16による分類結果を返すような処理を記述していきます。
app.pyを以下のように更新します。
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
from tensorflow.keras import preprocessing
import numpy as np
import base64
import PIL
import io
import json
def handler(event, context):
# 学習済みモデルをロード
model = VGG16(weights='models/vgg16_weights_tf_dim_ordering_tf_kernels.h5')
# リクエストBodyから入力画像(base64形式)を取得
input_image_base64 = event["inputImageBase64"]
# 入力画像をPIL形式に変換
img = base64_to_pil(input_image_base64)
# サイズをVGG16のデフォルトである224x224にリサイズ
img = img.resize((224, 224))
# 読み込んだPIL形式の画像をarrayに変換
x = preprocessing.image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# 予測
preds = model(preprocess_input(x))
# 最も高い確率のクラス名を取得
max_index = np.argmax(preds)
with open("models/imagenet_class_index.json") as f:
class_index = json.load(f)
class_name = class_index[str(max_index)][1]
# レスポンス
res = {
"class": class_name
}
return res
# base64画像文字列をデコードしてPIL画像に変換
def base64_to_pil(img_base64):
img_data = base64.b64decode(img_base64)
img = PIL.Image.open(io.BytesIO(img_data))
return img
DockerイメージをBuildする
改めてDockerイメージをbuildします。
docker build -t lambda-api .
ローカルでテストする
ローカルでDockerコンテナを起動してテストします。
docker run --rm -p 8000:8080 lambda-api:latest
Web APIがlocalhost:8000/2015-03-31/functions/function/invocations でアクティブになります。
テスト用に、何か適当な画像を送信してみましょう。
パブリックドメインのワンちゃんの画像を使います。

この画像を、こちらのサービスなどを利用してBase64形式の文字列に変換して、以下の形式のリクエストでWeb APIを叩きます。
{
"inputImageBase64": "/9j/..."
}
するとVGG16によってクラスが予測され、結果が以下のように返ってきます。
{
"class": "beagle"
}
「beagle」とは「ビーグル犬」のことなので、正しく分類できていることがわかります。
ここまで来ればあとはLambdaにデプロイするだけなので、テンプレの手順に従ってサクッとデプロイしちゃいましょう。
注意点:Lambdaのタイムアウトとメモリ
AWS Lambdaはデフォルトだとタイムアウトが3秒でメモリが128MBですが、これだとTensorflowを動かすには不足です。
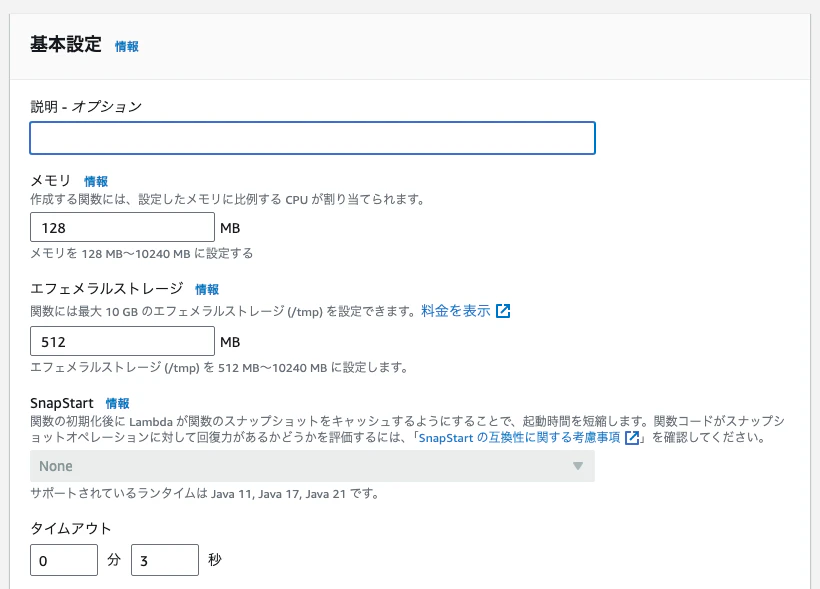
タイムアウトに関してですが、Tensorflowは実行時間がかかるものです。モデルの大きさにもよりますが、30秒以上はあったほうが良いと思います。
メモリに関しても、Tensorflowは結構メモリを食います。少なくとも1000MBはあったほうが良いと思いますが、これもモデル次第でもっとあったほうが良さげです。多めに設定してみて、実際のメモリ利用を見てみて、ちょうど良い値まで減らすと良いでしょう。
しかもAWS Lambdaでは、CPU数はメモリの大きさに依存します。大きいメモリを設定すればCPU数も増えるのです。
TensorflowをCPUで動かすためには多めのCPU数が必要です。もちろんメモリを多く設定すると料金も増えますが、CPU数が増えることが実行時間の削減に繋がるので、結果的に料金の節約になります。
Lambdaのメモリ数とCPU数の関係は以下の記事にまとめられています。私の場合はTensorflowを実装する時は3CPUはほしいので、3CPUが出る3072MBを設定しています。
