はじめに
実務で
「ルートボリューム(OS部分)が破損したとき、
リアルタイムで更新されているDドライブをデタッチ&アタッチで救えるのか?」
という質問に対して答えられなかったので、ハンズオンして検証しました。
やりたいこと:
- 使用中のEC2からデータボリュームをデタッチ&アタッチして
データの復旧ができるか - スナップショットからの復元との差を比較する
前提条件・環境
- OS: Amazon Linux 2023
- インスタンス: t2.micro
- EBSボリューム:
- ルートボリューム(OS用): 8 GiB
- データボリューム(ログ保存): 10 GiB
※データボリュームにはリアルタイムでログデータが書き込まれる想定
- 実務では週次でAMIを取得している前提に合わせ、
ルートボリュームのみのAMIを作成しておきます。
ハンズオン手順
 EC2作成
EC2作成
Amazon Linux 2023 でEC2を起動。
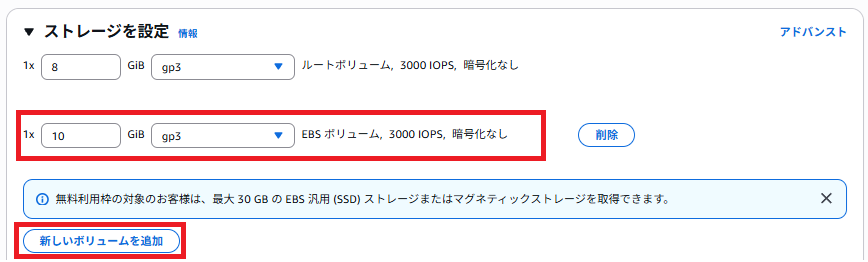
ストレージ設定で8GiBのルートボリュームに加え、10GiBのデータボリュームを追加します。
 AMI取得
AMI取得
復旧用にAMIを取得します。
デフォルトでは「ルートボリューム+データボリューム」の両方が含まれる設定になっていますが、データボリュームは除外してルートボリュームのみをAMI化します。
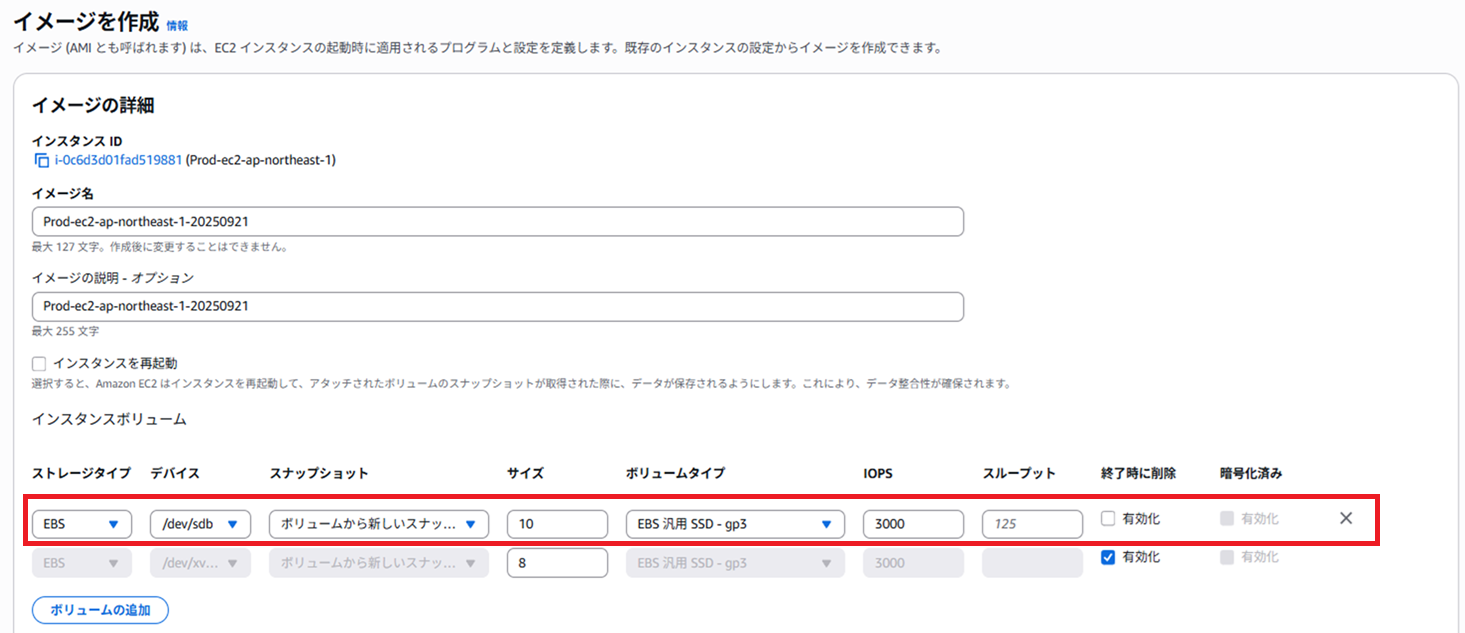
EC2作成時にDドライブ用の10GiBのストレージを追加しているため
ルートと合わせて2つのEBSを含めたAMIを取得する設定になっていますが、
Dドライブを含んだAMIは今回必要ないので設定から削除します。
 Dドライブをマウント
Dドライブをマウント
EC2上で以下のコマンドを入力して、Dドライブ用に作成したEBSをマウントします。
#以下のコマンドを上から実行
sudo su -
mkdir /mnt/d_drive
mkfs -t xfs /dev/xvdb
mount /dev/xvdb /mnt/d_drive
エラーなくコマンドが終了したら、「lsblk」コマンドで確認します。
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
xvda 202:0 0 8G 0 disk
├─xvda1 202:1 0 8G 0 part /
├─xvda127 259:0 0 1M 0 part
└─xvda128 259:1 0 10M 0 part /boot/efi
xvdb 202:16 0 10G 0 disk /mnt/d_drive
#xvdbのMOUNTPOINTに「/mnt/d_drive」が表示されていればマウント成功
 Dドライブにログを書き込む
Dドライブにログを書き込む
リアルタイム更新をするために、ログを追記し続けるシェルを実行します。
#/mnt/d_drive/にtestディレクトリを作成
mkdir -p /mnt/d_drive/test
cd /mnt/d_drive/test
#write_log.shを作成
cat << 'EOF' > write_log.sh
#!/bin/bash
while true; do
date "+%Y-%m-%d %H:%M:%S" >> /mnt/d_drive/test/test.log
sleep 10
done
EOF
#実行権限付与
chmod +x write_log.sh
#write_log.shを実行
./write_log.sh &
10秒ごとにtest.logへ現在時刻が追記されていきます。
実行後、正常にログが書き込まれていることを確認します。
ll
total 8
-rw-r--r--. 1 root root 20 Sep 21 06:57 test.log
-rwxr-xr-x. 1 root root 97 Sep 21 06:53 write_log.sh
#test.logの中身を確認
tail -f test.log
2025-09-21 06:57:18
2025-09-21 06:57:28
2025-09-21 06:57:38
2025-09-21 06:57:48
2025-09-21 06:57:58
 スナップショット取得(before)
スナップショット取得(before)
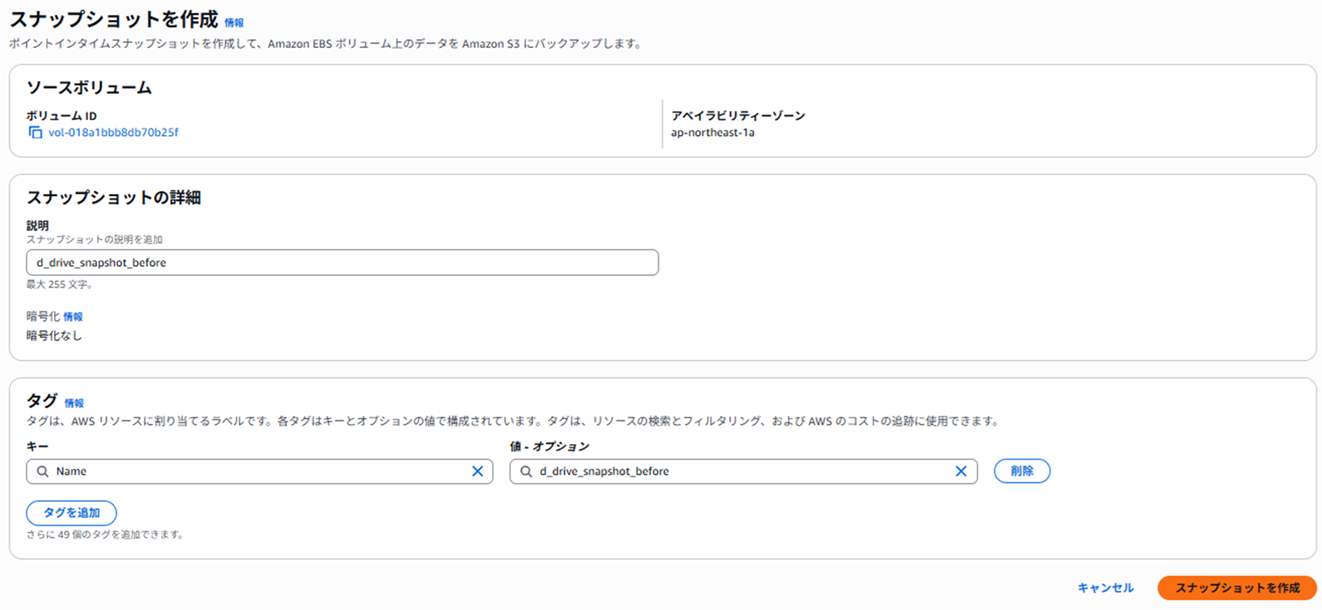
不具合想定でEC2を破壊する前に、Dドライブのスナップショットを取得します。
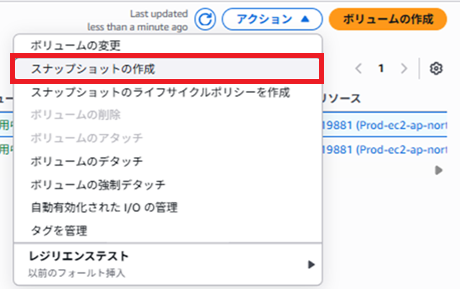
[ボリューム] → [スナップショット作成]
対象: Dドライブ(10GiBのやつ)
 ルートボリューム破損を模擬
ルートボリューム破損を模擬
ブートに必要なファイルを削除して再起動し、意図的に起動不可にします。
#以下のコマンドを上から実行
sudo rm -rf /boot/vmlinuz-* /boot/initramfs-* /boot/*-grub*
sudo reboot
再起動後、ステータスチェックが失敗すれば破損成功です。
実務では絶対やらないでください!!!
 復旧パターン①:スナップショットから復元
復旧パターン①:スナップショットから復元
まずはスナップショット時点でのログの中身を確認してみます。
![]() で取得したAMIから新しいEC2を作成し、
で取得したAMIから新しいEC2を作成し、
![]() で作成したスナップショットから新しいDドライブを作成しアタッチします。
で作成したスナップショットから新しいDドライブを作成しアタッチします。

[ボリューム] - [スナップショット] - [スナップショットからボリュームを作成]
スナップショットからボリュームを復元できたら、復元したボリュームを
AMIから復元した新しいインスタンスにアタッチします。
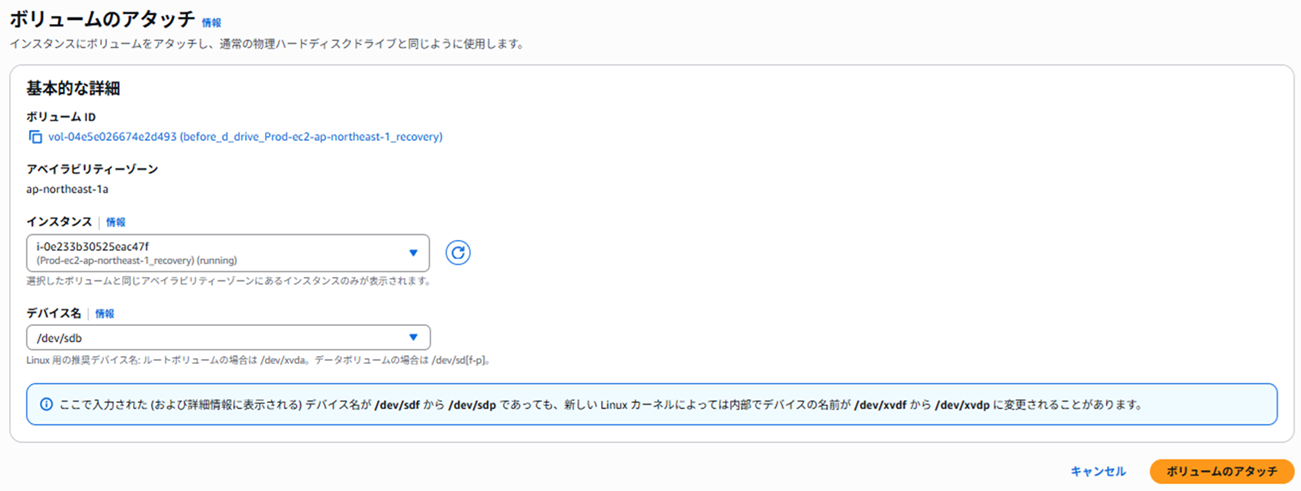
EC2上で以下のコマンドを実行し、ログの中身を確認します。
#以下のコマンドを実行
sudo su -
mkdir /mnt/d_drive
mount /dev/xvdb /mnt/d_drive
cd /mnt/d_drive/test
#test.logの中身を確認
tail -f test.log
...
2025-09-21 07:09:49
2025-09-21 07:09:59
2025-09-21 07:10:09
2025-09-21 07:10:19
2025/9/21 7:10:19までのログが記録されています。
(スナップショット取得時点までのログまでで止まっていました)
 復旧パターン②:デタッチ & アタッチ
復旧パターン②:デタッチ & アタッチ
破損したEC2からデータボリュームを直接デタッチし、新しいEC2にアタッチします。
アタッチ後、EC2上でtest.logを確認します。
sudo su -
mkdir /mnt/d_drive
sudo mount /dev/xvdb /mnt/d_drive
cd /mnt/d_drive/test
#test.logの中身を確認
tail -f test.log
...
2025-09-21 07:14:59
2025-09-21 07:15:09
2025-09-21 07:15:19
2025-09-21 07:15:29
2025-09-21 07:15:39
2025-09-21 07:15:49
2025-09-21 07:15:59
スナップショットより新しいログ(= 破壊直前までのデータ)が確認できました!
まとめ
壊れたEC2からでも、別ボリュームでアタッチされているEBSはその場で
デタッチ&アタッチして救えることが分かりました。
実務で分からないことは家で実践、大切ですね!
(実際のシステムは単純じゃないと思うので、今回のように簡単にはいかなそうですが…)
ここまで読んでいただきありがとうございました!