Introduction
きっかけ
最近はデータを扱うのが好きなので、うまくいったデータ分析をまとめました。オープンデータが流行っているので、実際の行政データをFoliumを用いて地図上に表示したので、忘れないように備忘録的にまとめます。地図上にプロットした理由は、ただただ数字を眺めていても面白くないからです。社会的な意義はありません。
結論
人口データを地図上にコロプレス(Choropleth)図という形式でプロットしてみました。右上に色分けの細かなボーダー部分を凡例としてまとめています。こちらはデータから自動で出力しています。
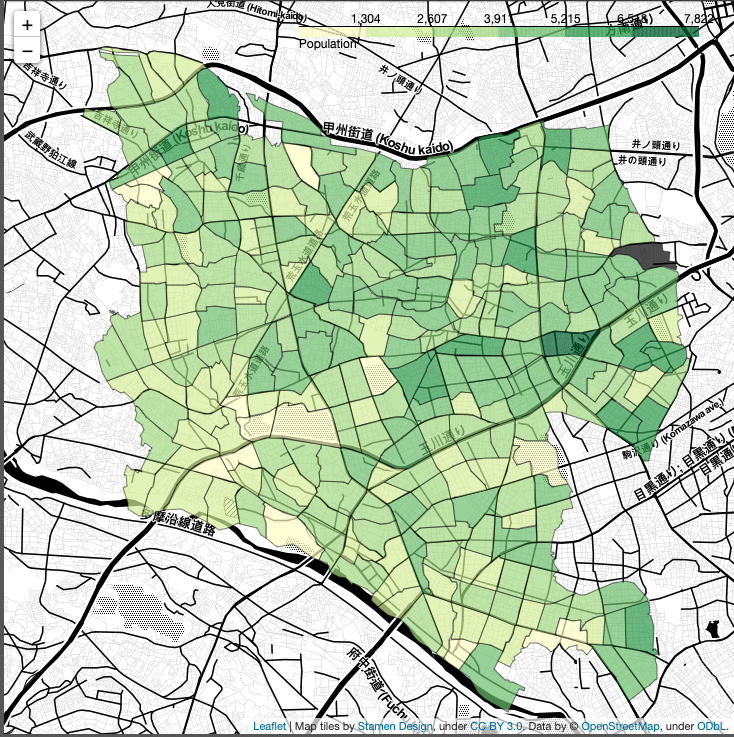
本日のお品書き
・地図にのせるデータの準備
・地図上へのデータ表示
対象者
・foliumの初心者の人
・1を聞いて10を理解できるエンジニア
・地図上へデータをプロットしたい方
・Macユーザーの人
・データの前処理に苦しむ方
非対象者
・foliumが超お得意な人
・説明下手な筆者を攻撃しようとするエンジニア
・3Dの地図上へおしゃれにデータをプロットしたい方
・Windowsユーザーの人
・データの前処理エキスパートの方
自己紹介

環境情報 1
macOS Catalina ver:10.15.7
conda 4.9.2
folium 0.12.0
geopandas 0.9.0
jupyterlab 3.0.11
pandas 1.2.3
Python 3.8.5
Cf.) Python2系とかPython3系の意味が分からない人へ!
Pythonには2系と3系があって、最近始めた人ならほとんどPython3系だと思います。一応バージョンを確認する方法を記載しておきます。
MacOSに入っているターミナル(Terminal)でPythonのインタラクティブ(対話)モードを起動すればバージョン情報が表示されます。
$ Python
>Python 3.8.5 (default, Sep 4 2020, 02:22:02)
[Clang 10.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.>>>
インタラクティブモードを辞めるには*exit()*を入力しましょう!
Let's Start
今回の記事も基本的に、JupyterLab上での開発です。JupyterLabもJupyter Notebookも大きくは変わらないので、わからない方はJupyter Notebookだと思っていただければと思います。
全体的なディレクトリ構造は以下のようになっています。ディレクトリ構造は、これから個別に紹介していきますので、特に気にしなくて大丈夫です。
├── data
│ ├── geodata
│ │ ├── h27ka13112.dbf
│ │ ├── h27ka13112.prj
│ │ ├── h27ka13112.shp
│ │ └── h27ka13112.shx
│ ├── karasu202106.xls
│ ├── kinuta202106.xls
│ ├── kitazawa202106.xls
│ ├── setagaya202106.xls
│ └── tamagawa202106.xls
├── foliumHTML
│ ├── femalePopulationChoropleth.html
│ ├── malePopulationChoropleth.html
│ └── totalPopulationChoropleth.html
└── setagaya_Choropleth.ipynb
地図にのせるデータの準備
データの取得元
まずは解析に用いるデータの紹介です。
今回は、世田谷区の町丁別の人口データを解析しております。
使用データは2種類あります。人口データと地図のポリゴンデータです。(2021年6月12日現在)
data部分のディレクトリ構造はこの章の最後に載せてあります。
人口データ
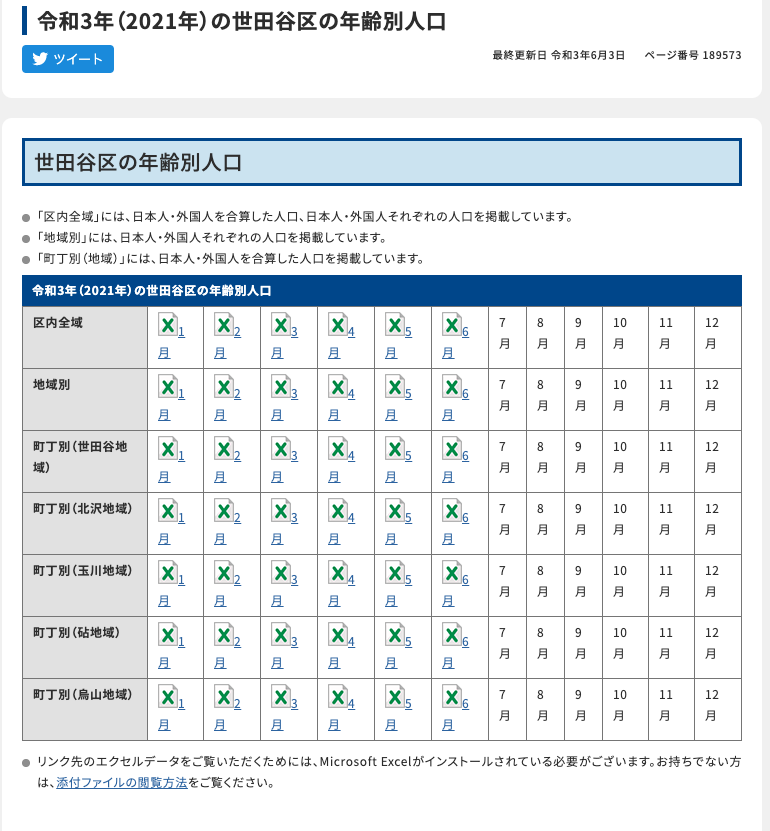
[世田谷区の年齢別人口] (https://www.city.setagaya.lg.jp/mokuji/kusei/001/003/003/d00189573.html)
必要なデータは、6月の「町丁別(世田谷地域)」「町丁別(北沢地域)」「町丁別(玉川地域)」「町丁別(砧地域)」「町丁別(烏山地域)」という5つのExcelファイルを利用します。
地図のポリゴンデータ
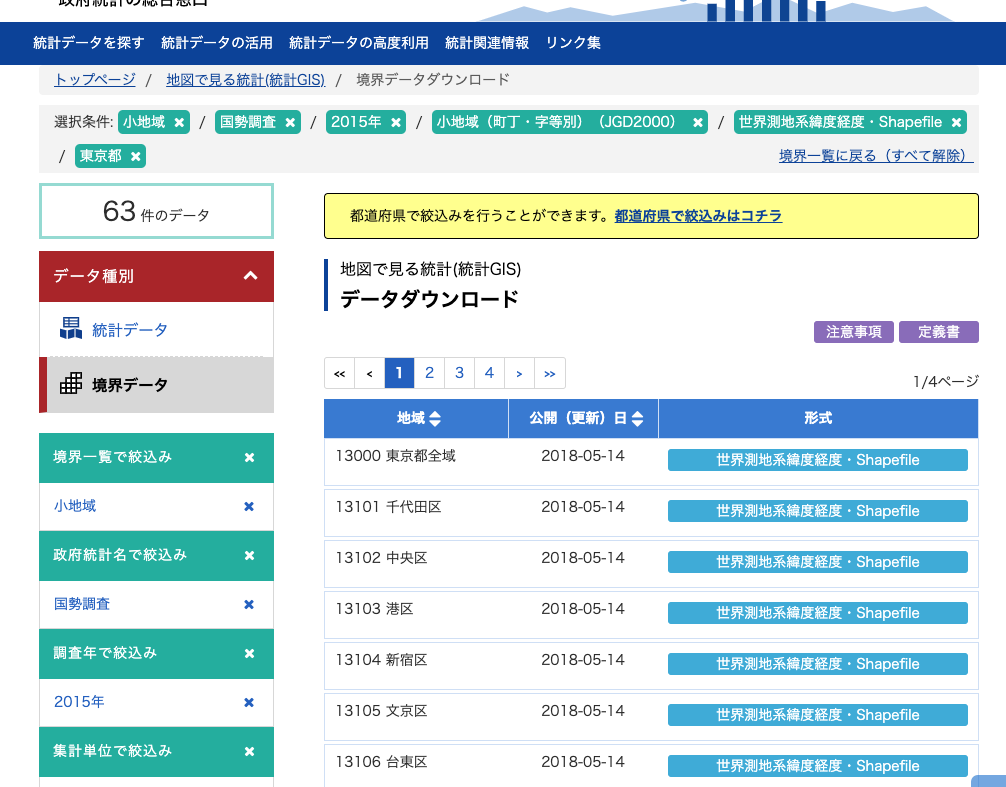
こちらの画面のもう少し下に世田谷区のデータがあります。

こちらのShapefileを使用しますので、Zipファイルを解凍してください。そしてgeodataというディレクトリを作成して移動させます。下記に今回の収集したデータを格納しておくディレクトリ構造をまとめておきます。
data
├── geodata
│ ├── h27ka13112.dbf
│ ├── h27ka13112.prj
│ ├── h27ka13112.shp
│ └── h27ka13112.shx
├── karasu202106.xls
├── kinuta202106.xls
├── kitazawa202106.xls
├── setagaya202106.xls
└── tamagawa202106.xls
上記のディレクトリ構造は、dataというディレクトリ内に人口データとgeodataというディレクトリを配置し、geodataの中に地図のポリゴンデータを配置しております。
以後、こちらのディレクトリ構造を前提として、進めていきますので、異なる場合には自分の環境に置き換えて読み進めてください。
データの前処理
※ここは長くなります。
まずは試行錯誤を重ねて、前処理がうまくいくように成功したコードを共有します。前処理とは、料理をしやすくするための下準備みたいものです。他人の作ったExcelデータをPythonで利用するためには、前処理をしておかないと臭みや苦味が残ってしまうのです。
import pandas as pd
SETAGAYA_AREA_LIST= ["karasu", "kinuta", "kitazawa", "setagaya", "tamagawa"]
DATA_MONTH = "202106"
num = 0
def getAreaDf (num):
"""
それぞれの地域のエクセルデータを取得する。
num:Max -> 4, Min -> 0
"""
print(SETAGAYA_AREA_LIST[num] + DATA_MONTH + "というエクセルデータを解析開始")
DATA_PATH = "data/" + SETAGAYA_AREA_LIST[num] + DATA_MONTH + ".xls"
origin_columns = pd.read_excel(DATA_PATH).columns
origin_sheet = pd.read_excel(DATA_PATH, skiprows=1)
#Unnamedの除去
origin_columns = [s for s in origin_columns if not s.startswith('Unnamed')]
new_list = []
# 0,1,2が一つの組み合わせ
for i in range(len(origin_sheet.iloc[0])//3):
row = []
# カラム
columns = origin_columns[i+1].replace("\u3000", "")
num = i*3 + 1
#総数
total = origin_sheet.iloc[0][num]
male = origin_sheet.iloc[0][num + 1]
female = origin_sheet.iloc[0][num + 2]
row.extend([columns, total, male, female])
new_list.append(row)
area_df = pd.DataFrame(new_list, columns=['name',"total","male","female"])
print(type(area_df))
return area_df
# 烏山地域のデータをDataFrameへ変更します。
setagaya_population_df = getAreaDf(num)
# 砧、北沢、世田谷、玉川地域のデータをDataFrameへ変更します。
for n in range(1, len(SETAGAYA_AREA_LIST)):
area_df = getAreaDf(n)
setagaya_population_df = pd.concat([setagaya_population_df, area_df]).reset_index(drop=True)
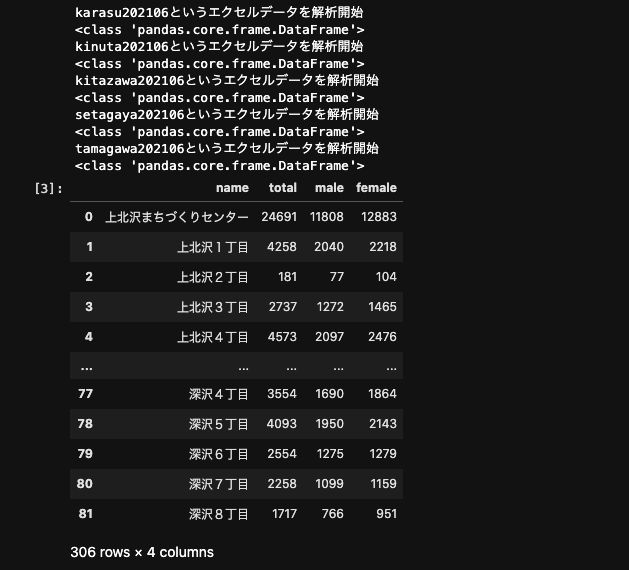
setagaya_population_df
見やすいように、いくつかコメントを追加しています。実際はもっと雑なコードです。
上記のコードを実行すると、下記のように出力されます。
それでは、個別のソースコードの解説をしていきます。
import pandas as pd
Pandasをインストールして、pdという名前で使います。ええと、それ以上の説明を自分には出来ません。ここではつまずかないでください!
SETAGAYA_AREA_LIST= ["karasu", "kinuta", "kitazawa", "setagaya", "tamagawa"]
DATA_MONTH = "202106"
num = 0
def getAreaDf (num):
"""
それぞれの地域のエクセルデータを取得する。
num:Max -> 4, Min -> 0
"""
print(SETAGAYA_AREA_LIST[num] + DATA_MONTH + "というエクセルデータを解析開始")
DATA_PATH = "data/" + SETAGAYA_AREA_LIST[num] + DATA_MONTH + ".xls"
この部分のコードは、ファイル名が下記の5つのファイルなので、同じ処理を関数で行うためにまとめただけです。別に関数化する必然性はありません。2
├── karasu202106.xls
├── kinuta202106.xls
├── kitazawa202106.xls
├── setagaya202106.xls
└── tamagawa202106.xls
5つのファイルなので、Min(Minimum)は0、Max(Maximum)は4ですね。
ここからが、魔の前処理ゾーンです。
読み進めるのが辛くなったら、次の章を読んでください。自分も書いていて涙がこぼれるくらい辛いです。私には、読むのを強要なんて出来ません。
origin_columns = pd.read_excel(DATA_PATH).columns
origin_sheet = pd.read_excel(DATA_PATH, skiprows=1)
# Unnamedの除去
origin_columns = [s for s in origin_columns if not s.startswith('Unnamed')]
上記のソースコードの解説前に下記のコードの出力結果を説明いたします。
origin_file = pd.read_excel(DATA_PATH)
カラム部分にUnnamedというものが複数見れると思います。さらに0行目のindex部分に「年齢」と「総数」、「男」、「女」という文字列が何度も周期的に見れると思います。この辺をうまく処理するために、下記のコードを挟んでいます。
origin_columns = pd.read_excel(DATA_PATH).columns
origin_sheet = pd.read_excel(DATA_PATH, skiprows=1)
# Unnamedの除去
origin_columns = [s for s in origin_columns if not s.startswith('Unnamed')]
上記の前処理3で作成した origin_sheet と origin_columns を使用していきます。
new_list = []
# 0,1,2が一つの組み合わせ
for i in range(len(origin_sheet.iloc[0])//3):
row = []
# カラム
columns = origin_columns[i+1].replace("\u3000", "")
num = i*3 + 1
#総数
total = origin_sheet.iloc[0][num]
male = origin_sheet.iloc[0][num + 1]
female = origin_sheet.iloc[0][num + 2]
row.extend([columns, total, male, female])
new_list.append(row)
range(len(origin_sheet.iloc[0])//3)
「総数・男・女」部分が周期的に現れているので、3列ずつ処理していくためにfor文でループさせています。
Pandasのデータ解析に用いるiloc部分の詳細はこちらの記事をご覧ください。
columns = origin_columns[i+1].replace("\u3000", "")
ここでは、町丁目の名称に含まれる空白を除去しています。この空白と言うのが、非常に厄介です。
num = i*3 + 1
total = origin_sheet.iloc[0][num]
male = origin_sheet.iloc[0][num + 1]
female = origin_sheet.iloc[0][num + 2]
ここは、周期性を変数として扱っています。実際にはそれぞれの地域の人口を取得しています。
row.extend([columns, total, male, female])
new_list.append(row)
上記で定義した町丁目の名前、総数の人口、男性の人口、女性の人口をリストにしています。
row -> new_list に追加しているのは、二重リストにしたいからです。
area_df = pd.DataFrame(new_list, columns=['name',"total","male","female"])
print(type(area_df))
return area_df
area_df = pd.DataFrame(new_list, columns=['name',"total","male","female"])
先ほど作成した二重リストをDataFrameに変更しています。
print(type(area_df))
<class 'pandas.core.frame.DataFrame'>
先ほど出力されていた部分はこちらです。ここでprintして、pandas.core.frame.DataFrameじゃない場合は、修正をしてください。
例えば、listだったり、pandas.core.frame.Seriesになってしまうかもしれません。
# 烏山地域のデータをDataFrameへ変更します。
setagaya_population_df = getAreaDf(num)
# 砧、北沢、世田谷、玉川地域のデータをDataFrameへ変更します。
for n in range(1, len(SETAGAYA_AREA_LIST)):
area_df = getAreaDf(n)
setagaya_population_df = pd.concat([setagaya_population_df, area_df]).reset_index(drop=True)
setagaya_population_df
ここで関数化したものが生きてきます。
一番初めに定義した下記の部分をfor文でループしています。
SETAGAYA_AREA_LIST= ["karasu", "kinuta", "kitazawa", "setagaya", "tamagawa"]
DATA_MONTH = "202106"
num = 0
pd.concat でDataFrame同士を結合させています。
ここで、5つのExcelデータを一つのDataFrame形式に結合が完了しました。
地図上へのデータ表示
さていよいよ地図上へデータを表示していきます。Pythonで地図情報を扱うことができるライブラリはいくつかありますが、今回はfoliumを使用します。
Foliumの使い方
こちらのリンクをご覧ください。
地図データの読み込み
import geopandas as gpd
setagaya_area_shdf = gpd.read_file('data/geodata/h27ka13112.shp', encoding="SHIFT-JIS")
こちらで、shpファイルを読み込んでいますが、data/geodata/には、下記のように4つのファイルを格納してください。
data
└─ geodata
├─ h27ka13112.dbf
├─ h27ka13112.prj
├─ h27ka13112.shp
└─ h27ka13112.shx
shpファイルのみしかない場合は、下記のようなDrive Errorを出力します。必要最低限のデータのみだとダメなんですね!開発中に、大変焦りました。
DriverError: Unable to open data/geodata/h27ka13112.shx or data/geodata/h27ka13112.SHX. Set SHAPE_RESTORE_SHX config option to YES to restore or create it.
地図上にChoropleth
まずは全体的なコードをご覧ください。
import folium
CATEGORY = 'total'
copyright_st = '© ' \
'Map tiles by <a href="http://stamen.com">Stamen Design</a>,' \
' under <a href="http://creativecommons.org/licenses/by/3.0">CC BY 3.0</a>.' \
'Data by <a href="http://openstreetmap.org">OpenStreetMap</a>,' \
'under <a href="http://www.openstreetmap.org/copyright">ODbL</a>.'
_map = folium.Map(location=[35.63850, 139.62586],
attr=copyright_st,
zoom_start=13,
tiles='Stamen Toner')
folium.Choropleth(geo_data = setagaya_area_shdf.to_json(),
data=setagaya_population_df,
columns=['name', CATEGORY],
key_on="properties.S_NAME",
fill_color="YlGn",
fill_opacity=0.7,
line_opacity=0.5,
legend_name="Population"
).add_to(_map)
_map.save('foliumHTML/' + CATEGORY + 'PopulationChoropleth.html')
さて個別に見ていきましょう!
import folium
foliumのimportです。
CATEGORY = 'total'
使用するデータとファイル名を一致させるために変数にしています。
ええと、データ解析にはそんなに大切ではない部分です。
copyright_st = '© ' \
'Map tiles by <a href="http://stamen.com">Stamen Design</a>,' \
' under <a href="http://creativecommons.org/licenses/by/3.0">CC BY 3.0</a>.' \
'Data by <a href="http://openstreetmap.org">OpenStreetMap</a>,' \
'under <a href="http://www.openstreetmap.org/copyright">ODbL</a>.'
Foliumのコピーライトを記載しています。ここの内容が地図情報の右下に表示されます。
地図情報には、コピーライトが必要なようですね。
_map = folium.Map(location=[35.63850, 139.62586],
attr=copyright_st,
zoom_start=13,
tiles='Stamen Toner')
foliumの地図情報の基礎を作成しています。
location は、地図情報を開いた際に表示される初期位置です。数字は緯度経度です。大体世田谷区辺りを示しています。
attr は、先ほど定義したコピーライトです。
zoom_startは、地図情報を開いた際の拡大縮小の初期設定です。
tilesは、使用する地図の種類です。
詳しくは、こちらをご覧ください(二回目)
folium.Choropleth(geo_data = setagaya_area_shdf.to_json(),
data=setagaya_population_df,
columns=['name', CATEGORY],
key_on="properties.S_NAME",
fill_color="YlGn",
fill_opacity=0.7,
line_opacity=0.5,
legend_name="Population"
).add_to(_map)
こちらは、値によって色を変えるコロプレス図の設定方法です。
コロプレス地図とは?
統計数値を地図に表現する場合の一方法として、数値をいくつかの階級に区分し、区域単位、たとえば市区町村別に、各階級に応じた色彩または明暗によって表す地図。
geo_data には地図情報を含むデータを指定してください。どうやらJSON形式しか受け入れてくれないみたいなので、to_json()を付与してください。この入力できるデータ形式には苦しめられました。
data には、統計データを指定してください。今回で言うと、世田谷区の人口データが入っているDataFrameです。
columns は統計データの中から可視化したいデータを指定してください。
key_on は、地図データのなかで、統計データと一致させたいデータを指定してください。今回の例では、統計データのnameと地図データのproperties.S_NAMEを一致させています。
fill_color は、表示される色合いです。今回の場合は、多いと緑少ないと黄色という設定にしています。他にも色々と設定できるみたいです。下記にリンクを載せておきます。
fill_opacityは、色合いの透明度です。
line_opacityは、町丁目ごとの境界線の透明度です。
legend_nameは、統計情報の凡例の名称です。
他の可視化方法やコロプレス図の詳細に関しては以下のリンクをご覧ください(英語)
fill_colorの詳細です。(英語)
(string with hexadecimal, RGB, or named color, default "#3388ff") – Color of the circle interior.
_map.save('foliumHTML/' + CATEGORY + 'PopulationChoropleth.html')
最後です。今まで定義した地図情報をHTMLファイルとして出力する部分です。
foliumHTML/totalPopulationChoropleth.html
というファイルができていると思います。
JupyterLab上で実行すると、下記のような画像が表示される場合があります。Trust HTMLをクリックすると地図情報を見ることができます。

ここまでお読みいただきありがとうございます。お疲れ様でした。さて先ほど作成したHTMLファイルを実行して Trust HTML をクリックすると、下記のような画像が手に入ります。
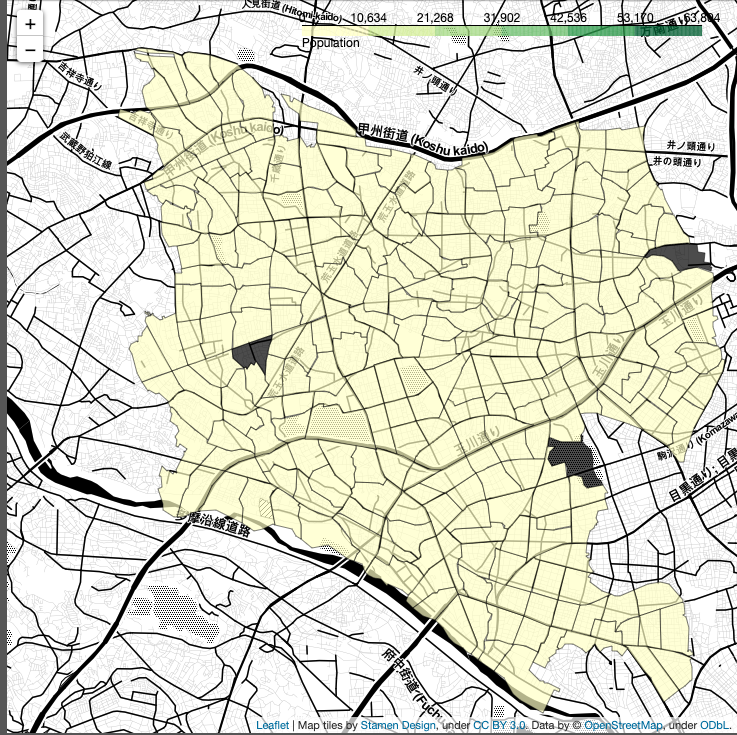
あれ?色が違う!!!!
そうなんです。これが前処理の大切さと大変さです。
この章では、もう疲労困憊だと思うのでソースコードのみ紹介します。なぜこのような画像になるかは、次の章の「大変だったこと」の中で詳細を共有いたします。
for index, row in setagaya_population_df.iterrows():
# print(index)
# print(row)
if not row['name'] in SETAGAYA_CITY_NAME:
# print(row['name'])
if row['name'] == "砧8丁目 ":
setagaya_population_df.at[index, 'name'] = "砧8丁目"
pass
elif row['name'] == "駒 沢 公 園":
setagaya_population_df.at[index, 'name'] = "駒沢公園"
pass
elif row['name'] == "池尻4丁目(33~39番)":
# print(row)
pass
elif row['name'] == "池尻4丁目(1~32番)":
# print(row)
pass
else:
print(index)
try:
setagaya_population_df.drop(index, axis=0, inplace=True)
# print(row['name'])
except KeyError as err:
# print(row)
print(err)
地図のデータを読み込んだあと、foliumを使用する前に、上記のソースコードを実行すると、無事に冒頭で紹介したような結果を見ることが出来ます。
性別で分類
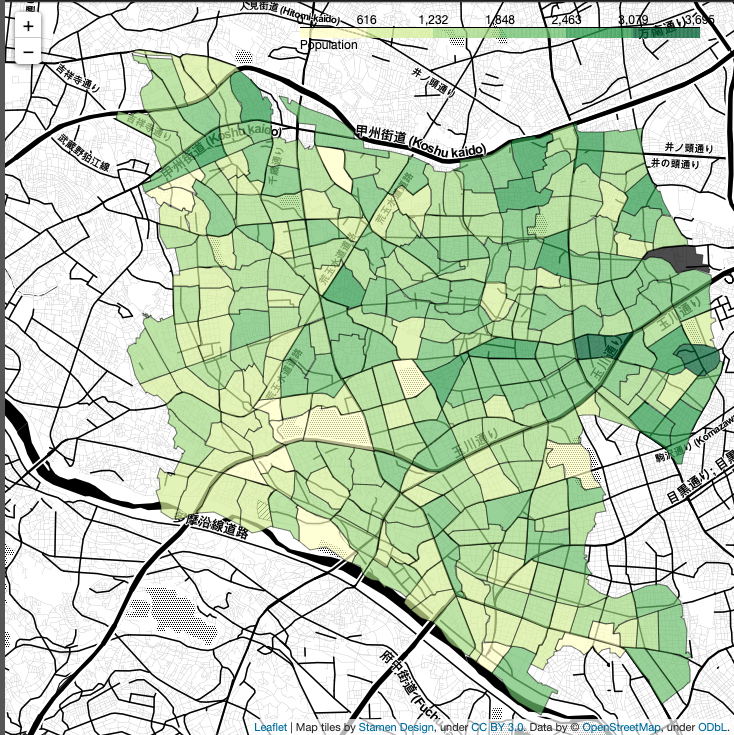
男女合わせた人口だけでなく、男性のみ、女性のみの結果も合わせて紹介いたします。
CATEGORY = 'male'
CATEGORY = 'female'
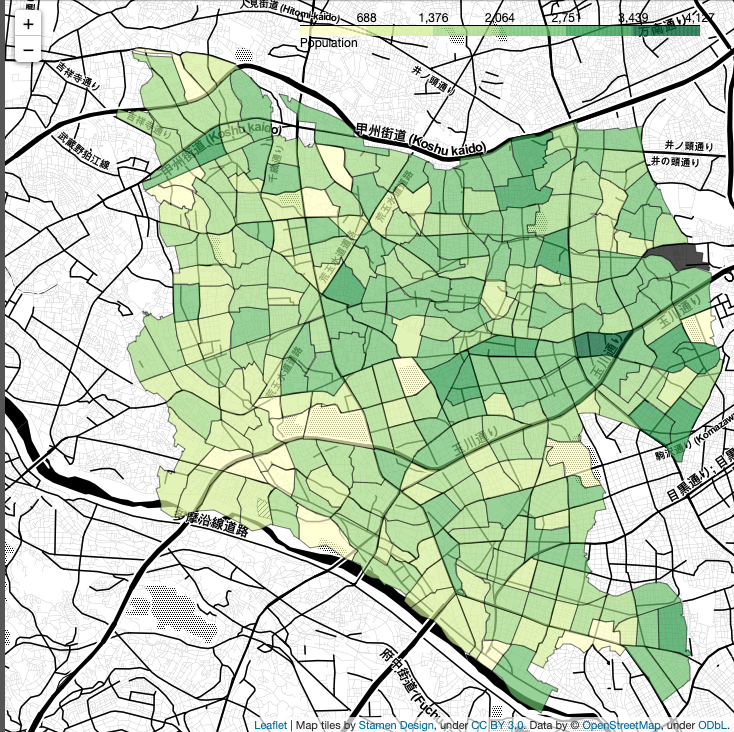
今回の検証ではあまり優位な差は見られませんでしたが、このような手法を使えば簡単に地図上で統計情報を扱えるようになると思います!3
To be Continued
大変だったこと(ポエムや感想など)
大変なことはたくさんありますが、大まかに分類するとデータの探索が2データを可視化方法の探索が1、ライブラリの勉強が1、データの前処理が5、その他が1って感じです。
データの前処理さえ終わればもうほぼ完了です。
データの前処理
ええと、ベストな方法なんてありません笑
エクセルデータを眺めながら何が不要なのかを分析しながら地道に省いていくしかありません。
最初はエクセルデータそのものをPythonで扱いやすいように、編集してしまうのもいいと思います。
前処理で時間を奪われるとデータ分析が楽しめなくなってしまうため、細かなことは気にしないで、可視化まで最短距離で突き進むことが大切だと思います。
GeoLocationのデータを含めて一つに集約しようとして迷い道
Choroplethのドキュメントをきちんと読んでいなかったため、地図データと統計データを一つのDataFrameにまとめようとしていたため、全然可視化できない時間を費やしました。
試す前に仕様をきちんと読もうと思いました。
名寄せの問題、空白に苦しめられた。
本文では省略した部分ですが、なぜ最初のコロプレス図は、黄色くなってしまったのかを紹介いたします。
地図情報には表示されていませんが、統計データの中には地域人口(複数の町丁目をまとめたもの)が含まれています。つまり地図情報には存在しない統計データは省く必要があります。
一方で黒くなっている地域もあると思います。そちらは統計データと地図データの町丁目の名称の名寄せがうまくいってないからです。
具体的には、このような名称となっています。統計データは砧8丁目 で、地図データは 砧8丁目 です。違いは最後の半角スペースの有無です。その他にも空白や町丁目の名称の差異があると地図情報はきちんと表示されません。ソースコードにおいては、個別の条件分岐を行って対応しています。もっと良い方法があれば教えてください。
for index, row in setagaya_population_df.iterrows():
# print(index)
# print(row)
if not row['name'] in SETAGAYA_CITY_NAME:
# print(row['name'])
if row['name'] == "砧8丁目 ":
setagaya_population_df.at[index, 'name'] = "砧8丁目"
pass
elif row['name'] == "駒 沢 公 園":
setagaya_population_df.at[index, 'name'] = "駒沢公園"
pass
elif row['name'] == "池尻4丁目(33~39番)":
# print(row)
pass
elif row['name'] == "池尻4丁目(1~32番)":
# print(row)
pass
else:
print(index)
try:
setagaya_population_df.drop(index, axis=0, inplace=True)
# print(row['name'])
except KeyError as err:
# print(row)
print(err)
To be Continued
再会のゆびきり
今後もQiitaやZennで、技術情報を発信しています。
noteには、備忘録を記録しています。
新着情報はX(旧: Twitter)で配信いたします。
フォローをお願いいたします。
Sempleの自由帳
Sempleのアイデア帳
Sempleのドキュメント
Sempleのツイッター
参考記事