機械学習を学び始めると、過学習とデータリークがごちゃごちゃになりやすいです。
どちらも「学習時はうまくいっているように見えるのに、本番では外れる」という意味では似ています。
でも、原因はまったく違います。
この記事では、ダミーデータを使って
- 過学習とは何か
- データリークとは何か
- なぜ「CVが良すぎる」と危ないのか
- 何を疑えばよいのか
を、初心者向けに順を追って説明します。
コードは Google Colab でそのまま実行できます。
まず結論
最初に一言で言うと、違いは次の通りです。
過学習: モデルが複雑すぎて、訓練データのノイズまで覚えてしまう
データリーク: 本来は使ってはいけない情報が、学習や評価に混ざってしまう
似ているようで、本質はかなり違います。
用語説明
訓練データ(train data)
モデルを学習させるためのデータです。
モデルはこのデータを見て、予測のルールを作ります。
テストデータ(test data)
学習には使わず、最後に「本当に未知データでどれくらい当たるか」を確認するためのデータです。
交差検証(Cross-Validation, CV)
データを何回かに分けて、
- 一部で学習
- 残りで評価
を繰り返し、平均的な性能を見る方法です。
「たまたまこの分割だけ良かった」を減らすためによく使います。
過学習(overfitting)
訓練データに合わせすぎることです。
本来学ぶべきパターンだけでなく、たまたま入っているノイズや偶然まで覚えてしまいます。
その結果、
- train はすごく良い
- でも test や CV はそこまで良くない
という状態になりやすいです。
データリーク(data leakage)
本来、予測時には使えない情報が、学習や評価に紛れ込むことです。
たとえば、
- 予測したい未来の情報を特徴量に入れてしまう
- 正解ラベルにほぼ等しい列が混ざる
- 前処理をデータ分割前にまとめてやってしまう
- 同じ人・同じ製品・同じ時系列の未来が train と test の両方に入る
などが典型例です。
その結果、
- train だけでなく
- CV や test まで異様に良く見える
ことがあります。
過学習とデータリークの違いを表にすると
| 観点 | 過学習 | データリーク |
|---|---|---|
| 原因 | モデルが複雑すぎる | 使ってはいけない情報が混ざる |
| 何を覚えているか | ノイズや偶然 | 禁止情報・未来情報・答えに近い情報 |
| trainスコア | 高くなりやすい | 高くなりやすい |
| CV/testスコア | trainより低くなりやすい | 不自然に高くなることがある |
| 本番での挙動 | 徐々に悪くなることが多い | 急に崩れることがある |
| 対策 | モデルを簡単にする、正則化、データを増やす | 分割方法と前処理を見直す、禁止情報を除く |
まずはライブラリを読み込む
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
実験1: 過学習とは何かをダミーデータで見る
まずは過学習の例を見ます。
どういうダミーデータを作るか
今回は、分類しやすい2次元データに対して、さらに意味のないノイズ特徴量を40個追加します。
そこに、深い決定木を当てます。
すると、
- 浅い木は大事なパターンだけを拾う
- 深い木はノイズまで覚えてしまう
という構図が見えやすくなります。
seed = 42
rng = np.random.default_rng(seed)
# もともとの信号データ(2次元)
X_signal, y = make_moons(n_samples=180, noise=0.45, random_state=seed)
# 意味のないノイズ特徴量を40個追加
noise_features = rng.normal(size=(180, 40))
X = np.hstack([X_signal, noise_features])
# train / test に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, stratify=y, random_state=seed
)
# CVの設定
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=seed)
# 木の深さを変えながら、train / CV / test の精度を比較
records = []
for depth in range(1, 13):
model = DecisionTreeClassifier(max_depth=depth, random_state=seed)
model.fit(X_train, y_train)
train_acc = model.score(X_train, y_train)
cv_acc = cross_val_score(model, X_train, y_train, cv=cv).mean()
test_acc = model.score(X_test, y_test)
records.append([depth, train_acc, cv_acc, test_acc])
result_overfit = pd.DataFrame(
records, columns=["max_depth", "train_acc", "cv_acc", "test_acc"]
)
best_row = result_overfit.loc[result_overfit["cv_acc"].idxmax()]
print(result_overfit.round(3))
print("\nBest by CV")
print(best_row.round(3))
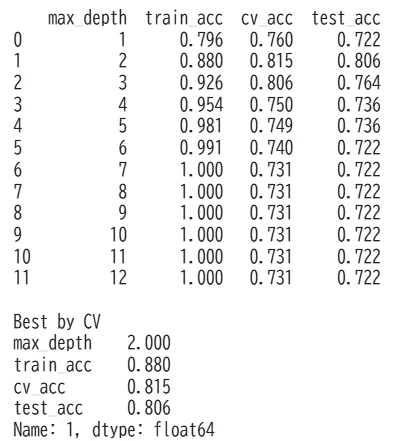
だいたい次のような傾向になります。
-
max_depth=2あたりで CV が最大 - 深くするほど train は上がる
- でも CV と test はむしろ下がる
-
max_depth=12ではtrain=1.000なのにcv=0.731,test=0.722
続いて図にします。
plt.figure(figsize=(8, 4.8))
plt.plot(result_overfit["max_depth"], result_overfit["train_acc"], marker="o", label="Train accuracy")
plt.plot(result_overfit["max_depth"], result_overfit["cv_acc"], marker="o", label="CV accuracy")
plt.plot(result_overfit["max_depth"], result_overfit["test_acc"], marker="o", label="Test accuracy")
best_depth = int(best_row["max_depth"])
plt.axvline(best_depth, linestyle="--", label=f"Best CV depth={best_depth}")
plt.xlabel("max_depth")
plt.ylabel("Accuracy")
plt.title("Overfitting example: deeper tree fits training data too well")
plt.ylim(0.65, 1.05)
plt.grid(alpha=0.3)
plt.legend()
plt.tight_layout()
plt.savefig("figure1_overfitting_curve.png", dpi=150, bbox_inches="tight")
plt.show()
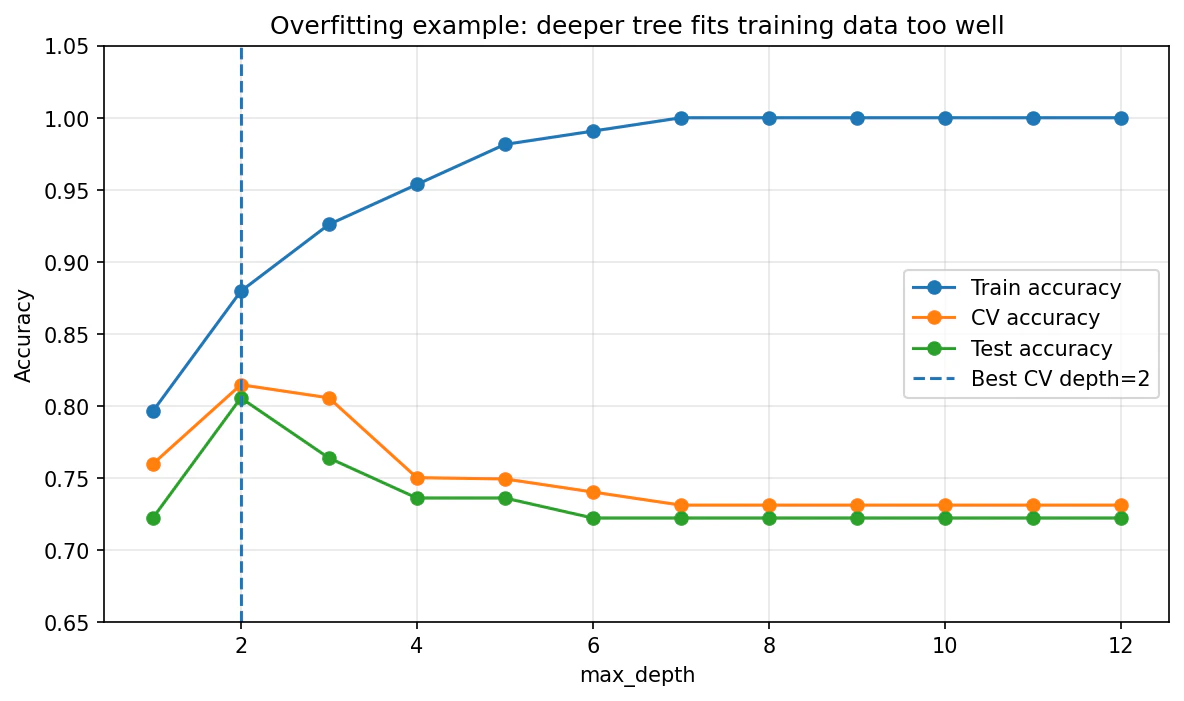
この図の見方はとても重要です。
-
青線(train) は木を深くするほど上がっていき、最後は
1.0 - 橙線(CV) は途中で頭打ちになり、むしろ下がる
- 緑線(test) も同じように下がる
つまり、
訓練データにはどんどん合っていくのに、未知データには強くならない
ということです。
これが過学習です。
過学習は「覚えすぎ」
今回の深い決定木は、データの本質だけでなく、
「このサンプルだけたまたまこうだった」というノイズまで拾ってしまっています。
だから train だけを見ると優秀に見えますが、
CV や test では通用しません。
実験2: データリークとは何かをダミーデータで見る
次はデータリークです。
過学習との違いをはっきりさせるため、今度はモデル自体は単純なロジスティック回帰を使います。
つまり、モデルをやたら複雑にはしません。
それでも、使ってはいけない情報を混ぜると、CVが異様に高く見えてしまいます。
どういうリークを作るか
今回は説明用に、かなり分かりやすいリークを作ります。
- まず、普通の特徴量
x1, x2, x3から目的変数yを作る - そのあとで、
future_info = y + 小さなノイズという列を追加する
この future_info は、ほぼ答えそのものです。
当然、本番予測の時点では使えません。
実務ではここまで露骨ではなくても、
- 未来にしか分からない値
- 予測後に確定する値
- 正解ラベルから作った列
- train/test分割前にやってしまった target encoding
などは、実質的に同じ問題を起こします。
def make_base_data(n, seed):
rng = np.random.default_rng(seed)
x1 = rng.normal(0, 1, n)
x2 = rng.normal(0, 1, n)
x3 = rng.normal(0, 1, n)
# 3つの特徴量から y を作る
logit = 1.2 * x1 - 1.0 * x2 + 0.6 * x3 + rng.normal(0, 1.0, n)
y = (logit > 0).astype(int)
X = np.column_stack([x1, x2, x3])
return X, y
n_train = 400
n_prod = 400
# 学習用データ
X_train_base, y_train = make_base_data(n_train, seed=1)
# 本番を想定した未知データ
X_prod_base, y_prod = make_base_data(n_prod, seed=2)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
まずはクリーンな特徴量だけで学習する
clean_model = Pipeline([
("scaler", StandardScaler()),
("lr", LogisticRegression(max_iter=1000))
])
clean_model.fit(X_train_base, y_train)
clean_train = clean_model.score(X_train_base, y_train)
clean_cv = cross_val_score(clean_model, X_train_base, y_train, cv=cv).mean()
clean_prod = clean_model.score(X_prod_base, y_prod)
print("Clean features")
print(f"train_acc = {clean_train:.3f}")
print(f"cv_acc = {clean_cv:.3f}")
print(f"prod_acc = {clean_prod:.3f}")
出力は次のようになります。
train_acc = 0.840cv_acc = 0.827prod_acc = 0.842
かなり自然です。
train, CV, 本番想定の精度がだいたい近いので、そこまで違和感はありません。
次にリーク列を混ぜる
# ほぼ答えそのもの、という禁止情報を追加
rng_train_leak = np.random.default_rng(10)
future_info_train = y_train + rng_train_leak.normal(0, 0.05, n_train)
X_train_leak = np.column_stack([X_train_base, future_info_train])
leak_model = Pipeline([
("scaler", StandardScaler()),
("lr", LogisticRegression(max_iter=1000))
])
leak_model.fit(X_train_leak, y_train)
leak_train = leak_model.score(X_train_leak, y_train)
leak_cv = cross_val_score(leak_model, X_train_leak, y_train, cv=cv).mean()
print("With leakage")
print(f"train_acc = {leak_train:.3f}")
print(f"cv_acc = {leak_cv:.3f}")
次の結果になります。
train_acc = 1.000cv_acc = 1.000
モデルは単純なロジスティック回帰なのに、
いきなり完璧です。
この時点で、
これは本当に賢いモデルなのか?
それとも、見てはいけないものを見ていないか?
と疑うべきです。
「リークしたテスト」だとテストも完璧に見えてしまう
参考までに、もしテスト側にも同じように future_info を作ってしまうと、
テスト精度まで完璧に見えます。
rng_test_naive = np.random.default_rng(11)
future_info_test_naive = y_prod + rng_test_naive.normal(0, 0.05, n_prod)
X_test_leak_naive = np.column_stack([X_prod_base, future_info_test_naive])
leak_naive_test = leak_model.score(X_test_leak_naive, y_prod)
print(f"Naive leaked test score = {leak_naive_test:.3f}")
実行すると 1.000 となります。
つまり、リークがデータセット全体に入り込んでいると、CVもtestも両方だまされる ことがあります。
本番を想定するとどうなるか
実際の本番では future_info は存在しません。
そこで、予測時には意味のない値しか入らない状況を、ダミーで再現します。
rng_prod = np.random.default_rng(999)
future_info_prod_like = rng_prod.normal(0, 1, n_prod) # 本番では意味を持たない値
X_prod_like = np.column_stack([X_prod_base, future_info_prod_like])
leak_prod_like = leak_model.score(X_prod_like, y_prod)
print(f"Production-like score = {leak_prod_like:.3f}")
実行すると約 0.548 まで落ちます。
つまり、
- train は完璧
- CV も完璧
- naive test も完璧
- でも本番想定では崩壊
です。
これがデータリークの怖さです。
図で比較する
summary = pd.DataFrame({
"model": ["Clean features", "With leakage"],
"train_acc": [clean_train, leak_train],
"cv_acc": [clean_cv, leak_cv],
"production_like_acc": [clean_prod, leak_prod_like],
}).round(3)
print(summary)
metric_labels = ["Train", "CV", "Production-like"]
clean_scores = [clean_train, clean_cv, clean_prod]
leak_scores = [leak_train, leak_cv, leak_prod_like]
x = np.arange(len(metric_labels))
width = 0.35
plt.figure(figsize=(8, 4.8))
plt.bar(x - width / 2, clean_scores, width, label="Clean features")
plt.bar(x + width / 2, leak_scores, width, label="With leakage")
plt.xticks(x, metric_labels)
plt.ylim(0.4, 1.05)
plt.ylabel("Accuracy")
plt.title("Leakage example: CV can look perfect while production fails")
plt.grid(axis="y", alpha=0.3)
plt.legend()
plt.tight_layout()
plt.savefig("figure2_leakage_bar.png", dpi=150, bbox_inches="tight")
plt.show()
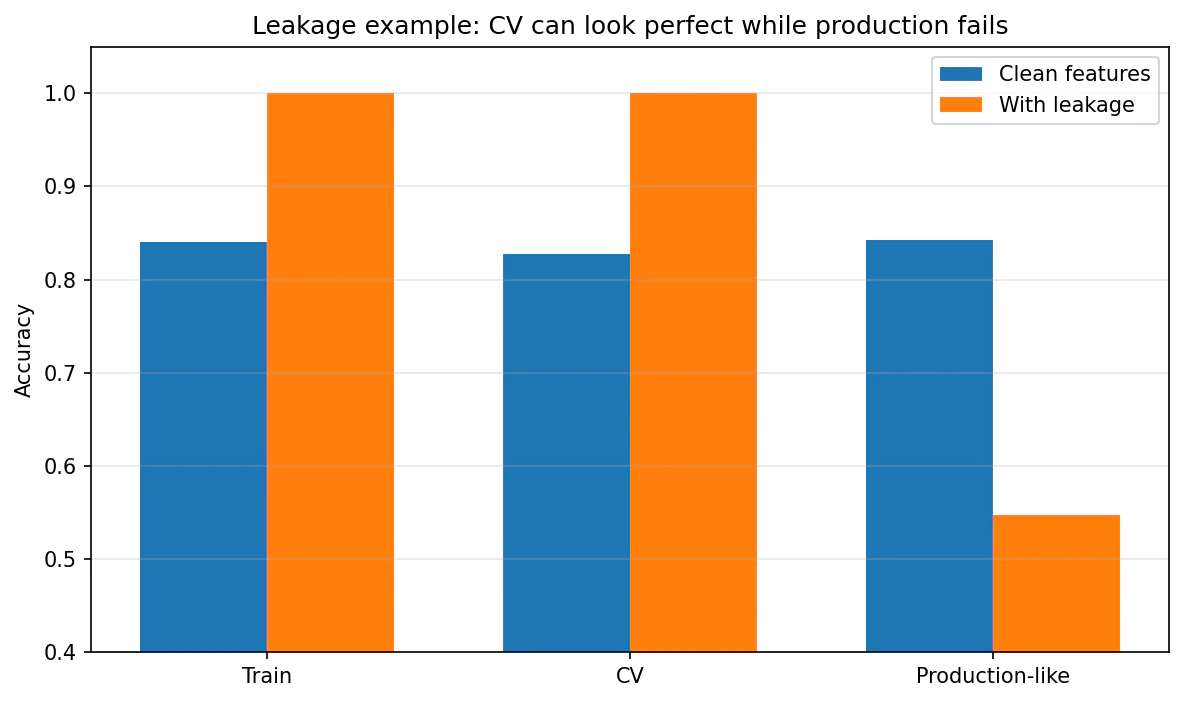
この図では、
- Clean features は train / CV / Production-like がほぼ同じ
-
With leakage は train と CV が
1.0 - でも Production-like は
0.548
になっています。
ここが、過学習との決定的な違いです。
過学習とデータリークの違いを今回の実験で言い直すと
過学習
- モデルが深すぎる
- train には合わせられる
- でも CV や test は伸びない
- trainだけ異様に高い
データリーク
- モデルは単純でも起こる
- CV まで異様に高くなる
- test すら高く見えることがある
- 本当にクリーンな本番では崩れる
- CVまで異様に高い
つまり、
過学習は「覚えすぎ」
データリークは「見てはいけないものを見ている」
と考えると区別しやすいです。
CVが良すぎるときに疑うべきこと
「CVが高い」こと自体は悪くありません。
でも、高すぎる ときは要注意です。
たとえば、
- ノイズが多いはずの問題なのに 0.99 や 1.00 に近い
- シンプルなモデルなのにほぼ完璧
- 現場感覚ではそんなに簡単な問題ではない
- test や本番だけ急に悪くなる
といった場合です。
そんなときは次を疑います。
1. 未来情報が混ざっていないか
- 解約予測なのに「解約手続き開始済み」が入っている
- 病気予測なのに診断後の検査値が入っている
- 売上予測なのに集計期間の後半データが入っている
2. 正解ラベルに近い列が入っていないか
- ラベルそのもの
- ラベルから作った特徴量
- 集計のしかた次第で答えが漏れている列
3. 前処理を分割前にまとめてやっていないか
たとえば、
- 標準化
- 欠損補完
- PCA
- 特徴量選択
- target encoding
を、train/testに分ける前に全データに対して実行すると危ないことがあります。
今回のコードでは Pipeline を使っているので、
CV の各 fold の内側で正しく前処理されます。
4. 同じ対象が train と test の両方に入っていないか
- 同じ患者
- 同じ顧客
- 同じ製品
- 同じ画像から切り出したパッチ
- 同じ時系列の近接時点
こういう場合、モデルは「本質」を学んでいるのではなく、
対象固有のクセを覚えて当てているだけかもしれません。
5. 時系列なのにランダム分割していないか
未来を予測したいのに、
未来側の情報が train に入っていたら、それは本番では再現できません。
よくある誤解
「CVが高ければ安心」
必ずしもそうではありません。
CVの計算のしかた自体が汚れている と、CVも簡単にだまされます。
「過学習とデータリークは同じ」
違います。
- 過学習は、許された情報を使って学びすぎる
- データリークは、そもそも使ってはいけない情報を使ってしまう
です。
「正則化すればデータリークも直る」
直りません。
L1/L2 正則化や木の深さ制限は、過学習には効くことがあります。
でも、リークは設計ミスなので、データ分割や特徴量の作り方を直す必要があります。
まとめ
この記事のポイントを最後に整理します。
- 過学習は、モデルが複雑すぎてノイズまで覚えること
- データリークは、本来使えない情報が学習や評価に混ざること
- 過学習では、train は高いが CV/test はそこまで伸びない
- データリークでは、CV まで異様に高くなることがある
- 「CVが良すぎる」ときは、まずリークを疑う価値がある
一言でまとめるなら、
過学習は「覚えすぎ」
データリークは「カンニング」
です。
機械学習では、モデルを賢くする前に、
評価のしかたがクリーンかどうか を疑うのがとても大事です。
おわりに
今回は説明のため、かなり分かりやすいリークを人工的に作りました。
実務ではもっと見えにくい形で起こります。
- 前処理の順番
- 特徴量作成のタイミング
- train/test の分け方
- 同一対象の混入
- 時系列の扱い
このあたりを丁寧に確認するだけで、
「CVでは神モデルだったのに本番で壊れる」をかなり防げます。
まずは今回のコードをColabで動かして、
過学習では train だけが上がること、
データリークでは CV まで不自然に上がること
を自分の目で確認してみるのがおすすめです。