はじめに
「ブートストラップ法」という言葉を初めて聞くと、次のような疑問が出てきやすいと思います。
ブートストラップは、いったい何を近似しているの?
結論から言うと、ブートストラップが近似しているのは、ざっくり言えば
統計量の標本分布
です。
もう少し日常的な言葉にすると、
同じ調査を何度もやり直したとき、標本平均や中央値などの値がどれくらいブレるのか
を、手元にある1回分のデータだけから推測しようとする方法です。
この記事では、架空の購買金額データを使って、次の流れで確認します。
- 母集団とは何か
- 標本とは何か
- 統計量とは何か
- 標本分布とは何か
- ブートストラップ分布とは何か
- ブートストラップは何を近似しているのか
Google Colabでそのまま実行できるコードも載せます。
まず用語を整理する
母集団
母集団とは、本当は知りたい対象全体のことです。
例えば、あるECサイトで
今月の全購入者の平均購入金額を知りたい
とします。
このとき、今月の全購入者の購買金額すべてが母集団です。
ただし現実には、母集団全体を完全に観測できるとは限りません。
標本
標本とは、母集団から一部だけ取り出して観測したデータのことです。
例えば、全購入者のうち30人だけを調べた場合、その30人分の購買金額が標本です。
統計量
統計量とは、標本から計算する値です。
代表例は次のようなものです。
- 標本平均
- 標本中央値
- 標本分散
- 相関係数
- 回帰係数
この記事では、わかりやすくするために主に標本平均を使います。
例えば、30人分の購買金額があるとき、
sample.mean()
で計算される値が標本平均です。
標本分布
ここが一番大事です。
標本分布とは、
母集団から同じサイズの標本を何度も取り直し、そのたびに統計量を計算したときの分布
です。
例えば、母集団から30人をランダムに選んで標本平均を計算します。
その調査を1回だけでなく、何千回も繰り返したとします。
すると、標本平均は毎回少しずつ変わります。
- ある回では 24.1
- ある回では 26.3
- ある回では 28.0
- ある回では 23.7
というように、標本平均そのものがばらつきます。
この「標本平均のばらつき方」が、標本平均の標本分布です。
ダミーデータを作る
ここからは、教材用に「本当は存在する母集団」を人工的に作ります。
現実の分析では母集団全体はわからないことが多いですが、この記事では説明のために、あえて母集団を作っておきます。
これにより、
- 本当の標本分布
- ブートストラップで作った分布
を比較できます。
Google Colab用コード:準備
Colabで日本語ラベルを表示するために、japanize-matplotlibを入れます。
!pip -q install japanize-matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.rcParams["figure.figsize"] = (8, 4)
plt.rcParams["axes.grid"] = True
母集団と標本を作る
今回は、架空の購買金額データを作ります。
購買金額のようなデータは、少額の購入が多く、一部に高額購入があるため、右に裾が長い分布になりがちです。
そこで、ここでは対数正規分布を使います。
# 教材用の「本当は存在する母集団」
rng_population = np.random.default_rng(42)
population_size = 100_000
population = rng_population.lognormal(
mean=3.0,
sigma=0.7,
size=population_size
)
# 現実で手元にあるつもりの標本
n = 30
rng_sample = np.random.default_rng(75)
sample = rng_sample.choice(
population,
size=n,
replace=False
)
print(f"母平均(教材用にだけ分かっている値): {population.mean():.2f}")
print(f"標本平均(手元の30件から計算): {sample.mean():.2f}")
print(f"標本標準偏差: {sample.std(ddof=1):.2f}")
次の結果になります。
母平均(教材用にだけ分かっている値): 25.65
標本平均(手元の30件から計算): 25.82
標本標準偏差: 19.83
母平均は25.65ですが、現実の分析ではこの値は普通わかりません。
手元にあるのは、30件の標本だけです。
母集団と標本を図で見る
bins = np.linspace(0, 100, 31)
plt.figure(figsize=(8, 4))
plt.hist(
population,
bins=bins,
density=True,
alpha=0.4,
label="母集団(教材用)"
)
plt.hist(
sample,
bins=bins,
density=True,
alpha=0.7,
label="手元の標本 n=30"
)
plt.axvline(
population.mean(),
linestyle="--",
linewidth=2,
label=f"母平均 {population.mean():.2f}"
)
plt.axvline(
sample.mean(),
linestyle="-",
linewidth=2,
label=f"標本平均 {sample.mean():.2f}"
)
plt.xlim(0, 100)
plt.xlabel("購買金額(架空データ)")
plt.ylabel("密度")
plt.title("図1: 母集団と、そこから1回だけ得られた標本")
plt.legend()
plt.tight_layout()
plt.savefig("fig1_population_and_sample.png", dpi=200, bbox_inches="tight")
plt.show()

図1を見ると、母集団は右に裾が長い分布になっています。
一方、手元の標本は30件しかないので、母集団の形を完全には再現していません。
ただし、今回は標本平均が母平均にかなり近くなっています。
ここで重要なのは、現実には青い母集団全体は見えていない、ということです。
本当の標本分布を作ってみる
次に、教材用に「本当の標本分布」を作ってみます。
現実には母集団全体が見えないので、これは普通できません。
しかし今回は教材用に母集団を人工的に作ったので、母集団から30件の標本を何度も取り直すことができます。
B = 5000
rng_sampling = np.random.default_rng(123)
sampling_means = np.array([
rng_sampling.choice(
population,
size=n,
replace=False
).mean()
for _ in range(B)
])
print(f"標本平均の平均: {sampling_means.mean():.2f}")
print(f"標本平均の標準偏差: {sampling_means.std(ddof=1):.2f}")
次になります。
標本平均の平均: 25.72
標本平均の標準偏差: 3.76
ここで出てきた sampling_means が、教材用に作った「標本平均の標本分布」です。
標本平均の標準偏差は、よく標準誤差とも呼ばれます。
つまり、今回の設定では、30件の標本から計算した平均値は、だいたい数単位くらいブレるということです。
しかし現実には「何度も標本を取り直す」ことはできない
ここまでの話は、教材用だからできました。
現実の分析では、多くの場合、手元にある標本は1つだけです。
例えば、30人分の購買金額データだけが手元にあるとします。
このとき本当は、
母集団から30人を選び直す調査を5000回繰り返したい
のですが、それはできません。
そこで登場するのがブートストラップです。
ブートストラップの考え方
ブートストラップでは、手元の標本を「仮の母集団」とみなします。
そして、その手元の標本から、同じサイズのデータを復元抽出します。
復元抽出とは、選んだデータを戻してから、また選ぶことです。
例えば、手元の標本が次のような5個の値だったとします。
[10, 20, 30, 40, 50]
ここから復元抽出で5個取り出すと、例えば次のようになります。
[20, 20, 50, 10, 40]
同じ値が複数回出てもよいのがポイントです。
もし復元抽出ではなく非復元抽出にすると、元のデータを並べ替えるだけになってしまい、標本平均は変わりません。
だからブートストラップでは、基本的に replace=True を使います。
ブートストラップ分布を作る
手元の標本から復元抽出を5000回行い、そのたびに平均を計算します。
rng_bootstrap = np.random.default_rng(456)
bootstrap_means = np.array([
rng_bootstrap.choice(
sample,
size=n,
replace=True # ここが重要:復元抽出
).mean()
for _ in range(B)
])
print(f"ブートストラップ平均の平均: {bootstrap_means.mean():.2f}")
print(f"ブートストラップ平均の標準偏差: {bootstrap_means.std(ddof=1):.2f}")
次になります。
ブートストラップ平均の平均: 25.83
ブートストラップ平均の標準偏差: 3.53
この bootstrap_means が、ブートストラップ分布です。
本当の標本分布とブートストラップ分布を比べる
ここで、教材用に作った「本当の標本分布」と、手元の標本だけから作った「ブートストラップ分布」を重ねてみます。
summary = pd.DataFrame({
"対象": [
"母集団",
"手元の標本",
"真の標本分布(教材用シミュレーション)",
"ブートストラップ分布"
],
"平均": [
population.mean(),
sample.mean(),
sampling_means.mean(),
bootstrap_means.mean()
],
"標準偏差": [
population.std(ddof=1),
sample.std(ddof=1),
sampling_means.std(ddof=1),
bootstrap_means.std(ddof=1)
]
})
summary
次になります。
| 対象 | 平均 | 標準偏差 |
|---|---|---|
| 母集団 | 25.65 | 20.69 |
| 手元の標本 | 25.82 | 19.83 |
| 真の標本分布(教材用シミュレーション) | 25.72 | 3.76 |
| ブートストラップ分布 | 25.83 | 3.53 |
次に図で重ねます。
bins = np.linspace(15, 40, 50)
plt.figure(figsize=(8, 4))
plt.hist(
sampling_means,
bins=bins,
density=True,
alpha=0.5,
label="真の標本分布(教材用)"
)
plt.hist(
bootstrap_means,
bins=bins,
density=True,
alpha=0.5,
label="ブートストラップ分布"
)
plt.axvline(
population.mean(),
linestyle="--",
linewidth=2,
label=f"母平均 {population.mean():.2f}"
)
plt.axvline(
sample.mean(),
linestyle="-",
linewidth=2,
label=f"標本平均 {sample.mean():.2f}"
)
plt.xlabel("標本平均")
plt.ylabel("密度")
plt.title("図2: 真の標本分布とブートストラップ分布の比較")
plt.legend()
plt.tight_layout()
plt.savefig("fig2_sampling_vs_bootstrap.png", dpi=200, bbox_inches="tight")
plt.show()
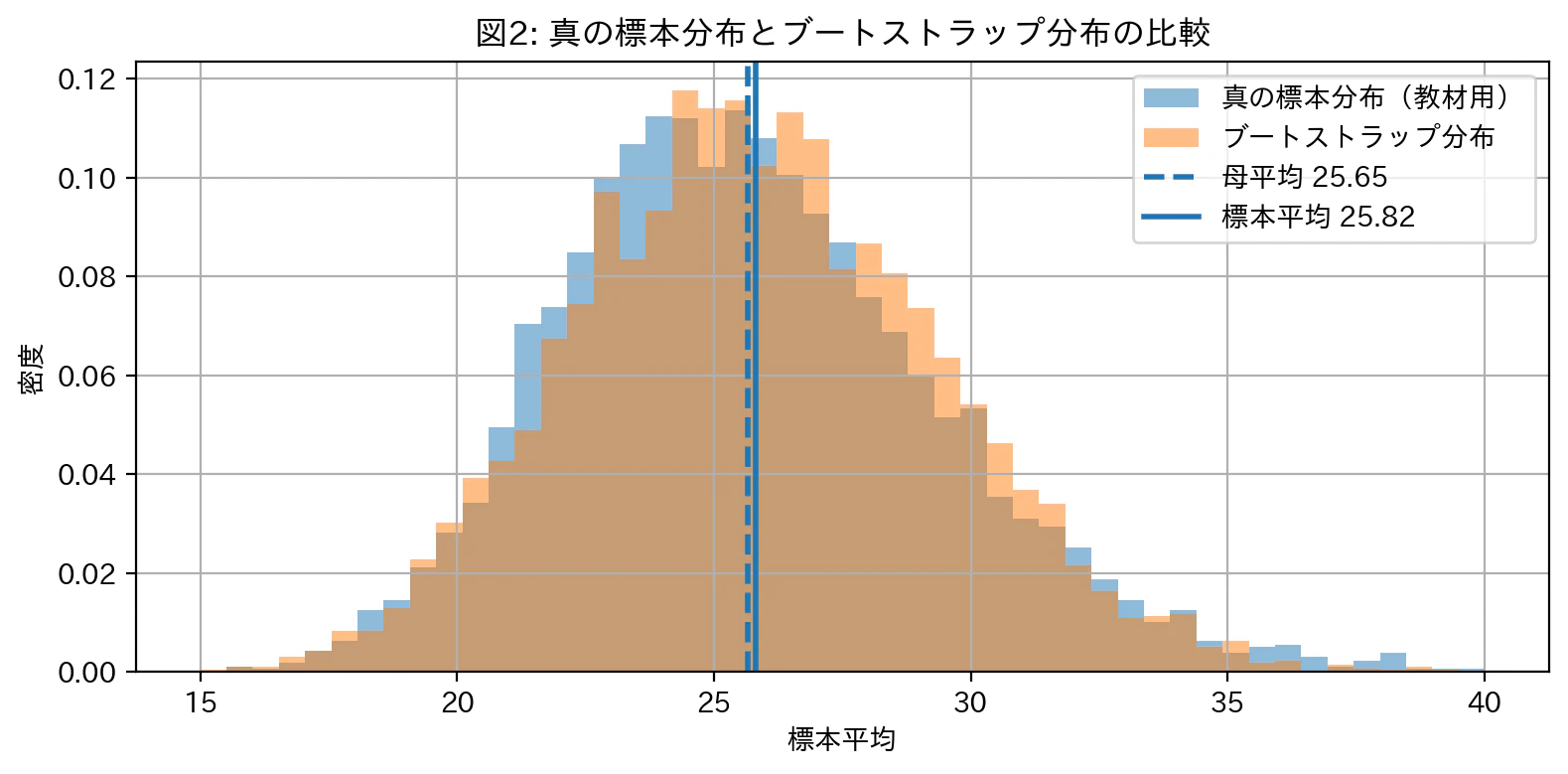
図2では、2つの分布がかなり近い形になっています。
青っぽい分布は、教材用に母集団から何度も標本を取り直して作った「真の標本分布」です。
オレンジっぽい分布は、手元の30件だけから復元抽出して作った「ブートストラップ分布」です。
現実には青い分布は作れません。
しかし、ブートストラップを使うと、手元の標本だけから、それに近い分布を作ろうとできます。
つまり、ブートストラップは何を近似しているのか
ここまでの流れをまとめると、次のようになります。
本当は知りたいものは、
母集団から標本を取り直したとき、統計量がどうばらつくか
です。
つまり、統計量の標本分布です。
しかし現実には、母集団から何度も標本を取り直すことはできません。
そこでブートストラップでは、
手元の標本を仮の母集団とみなして、そこから何度も標本を取り直す
ということをします。
その結果として得られるブートストラップ分布を使って、
本当の標本分布の形やばらつき
を近似します。
より短く言うと、
ブートストラップは、統計量の標本分布を近似している
ということです。
ブートストラップは「母集団そのもの」を完全に復元しているわけではない
ここは誤解しやすいポイントです。
ブートストラップは、手元の標本を使っているだけです。
したがって、手元の標本に含まれていない値を魔法のように知ることはできません。
例えば、手元の標本に非常に高額な購入者が一人も入っていなければ、ブートストラップでもその高額購入者は出てきません。
つまり、ブートストラップがしているのは、
未知の母集団を完全に復元すること
ではありません。
そうではなく、
手元の標本を母集団の代理として使い、統計量のばらつき方を推測すること
です。
ブートストラップ信頼区間を作る
ブートストラップ分布を使うと、信頼区間のようなものも作れます。
ここでは、最も素朴なパーセンタイル法を使います。
bootstrap_means の下位2.5%点と上位97.5%点を取ると、95%ブートストラップ信頼区間になります。
ci_low, ci_high = np.quantile(
bootstrap_means,
[0.025, 0.975]
)
print(f"標本平均: {sample.mean():.2f}")
print(f"95%ブートストラップ信頼区間: [{ci_low:.2f}, {ci_high:.2f}]")
次になります。
標本平均: 25.82
95%ブートストラップ信頼区間: [19.30, 33.09]
図でも見てみます。
plt.figure(figsize=(8, 4))
plt.hist(
bootstrap_means,
bins=40,
density=True,
alpha=0.7,
label="ブートストラップ平均"
)
plt.axvline(
ci_low,
linestyle="--",
linewidth=2,
label=f"2.5%点 {ci_low:.2f}"
)
plt.axvline(
ci_high,
linestyle="--",
linewidth=2,
label=f"97.5%点 {ci_high:.2f}"
)
plt.axvline(
sample.mean(),
linestyle="-",
linewidth=2,
label=f"標本平均 {sample.mean():.2f}"
)
plt.xlabel("標本平均")
plt.ylabel("密度")
plt.title("図3: ブートストラップ分布から信頼区間を作る")
plt.legend()
plt.tight_layout()
plt.savefig("fig3_bootstrap_ci.png", dpi=200, bbox_inches="tight")
plt.show()

この図では、ブートストラップで得られた標本平均の分布が描かれています。
左右の点線が、下位2.5%点と上位97.5%点です。
この範囲を使って、
手元の標本から見ると、平均購入金額はだいたいこのくらいの範囲にありそう
という不確実性の目安を作れます。
「近似しているもの」をもう少しだけ数式で見る
標本を次のように書きます。
$$
X_1, X_2, \dots, X_n
$$
平均や中央値などの統計量を
$$
T(X_1, X_2, \dots, X_n)
$$
とします。
本当の標本分布は、母集団から何度も
$$
X_1, X_2, \dots, X_n
$$
を取り直して、そのたびに
$$
T(X_1, X_2, \dots, X_n)
$$
を計算したときの分布です。
しかし母集団はわかりません。
そこでブートストラップでは、手元の標本から復元抽出して
X_1^*, X_2^*, \dots, X_n^*
を作り、
T(X_1^*, X_2^*, \dots, X_n^*)
を何度も計算します。
この分布を使って、本当の標本分布を近似します。
よくある誤解
誤解1:ブートストラップをするとデータ数が本当に増える
増えません。
ブートストラップで作るデータは、手元の標本から復元抽出したものです。
新しい観測データが手に入ったわけではありません。
誤解2:ブートストラップは母集団を完全に再現する
再現しません。
手元の標本にない情報は、基本的には出てきません。
ブートストラップは、あくまで手元の標本を母集団の代理として扱う方法です。
誤解3:ブートストラップはどんなデータにもそのまま使える
必ずしもそうではありません。
例えば、次のような場合は注意が必要です。
- 標本サイズがとても小さい
- 標本が母集団を代表していない
- 時系列データのように、データ同士が独立とは言いにくい
- 外れ値の影響が非常に大きい
- 最大値や最小値など、極端な統計量を扱う
時系列データならブロックブートストラップ、階層構造のあるデータならクラスタ単位のリサンプリングなど、データの構造に合わせた工夫が必要になることがあります。
まとめ
この記事では、ダミーデータを使ってブートストラップが何を近似しているのかを確認しました。
ポイントは次の通りです。
- 母集団とは、本当は知りたい対象全体
- 標本とは、母集団から一部だけ取り出したデータ
- 統計量とは、標本から計算する平均や中央値などの値
- 標本分布とは、標本を何度も取り直したときの統計量の分布
- 現実には母集団から何度も標本を取り直せない
- ブートストラップでは、手元の標本を仮の母集団とみなす
- そこから復元抽出を繰り返して、統計量の分布を作る
- その分布によって、統計量の標本分布を近似する
最初の問いに戻ると、
ブートストラップは何を近似しているのか?
への答えは、
母集団そのものではなく、統計量の標本分布を近似している
です。
特に重要なのは、
推定値そのものだけでなく、その推定値がどれくらい不確実なのかを知るための方法
としてブートストラップを見ることです。
平均値、中央値、相関係数、回帰係数など、「この値はどれくらいブレるのだろう?」と考えたい場面で、ブートストラップはとても便利な考え方です。