統計や機械学習を学び始めると、「尤度(likelihood)」と「確率(probability)」が似たように見えて混乱しがちです。
実際、数式の形はかなり似ています。
でも、見ている向きは逆です。
確率は「パラメータを固定して、どんなデータが出るか」を見る
尤度は「データを固定して、どんなパラメータがもっともらしいか」を見る
この記事では、コイン投げのダミーデータを使ってこの違いを直感的に整理します。
コードは Google Colab でそのまま実行できます。
まずは用語から
この記事では次の3つが重要です。
- データ: 実際に観測した結果
- モデル: データが生まれる仕組みを数式で表したもの
- パラメータ: モデルの性質を決める値
今回の例では、次のように考えます。
- コインを1回投げて、表なら
1、裏なら0とする - コインが表を出す確率を
pとする - コインを20回投げた結果を観測する
このとき p がパラメータ、20回の結果がデータです。
今回の結論を先に1枚で
| 観点 | 固定するもの | 動かすもの | 知りたいこと |
|---|---|---|---|
| 確率 | パラメータ p
|
データ | どんな結果がどれくらい起きるか |
| 尤度 | データ | パラメータ p
|
どの p が観測結果をもっともよく説明するか |
「同じ式でも、どちらを固定してどちらを動かしているか」が違いの本質です。
ダミーデータを用意する
今回は乱数ではなく、再現性のある固定のダミーデータを使います。
1 が表、0 が裏です。
import numpy as np
import matplotlib.pyplot as plt
from math import comb
# 1 = 表, 0 = 裏
dummy_data = np.array([1, 0, 1, 1, 1, 0, 1, 1, 0, 1,
1, 1, 0, 1, 0, 0, 1, 1, 1, 1])
n = len(dummy_data)
k_obs = int(dummy_data.sum())
print(f"試行回数 n = {n}")
print(f"表の回数 k = {k_obs}")
print(f"裏の回数 n-k = {n-k_obs}")
print("dummy_data =", dummy_data.tolist())
実行すると、今回のダミーデータは20回中14回が表です。
試行回数 n = 20
表の回数 k = 14
裏の回数 n-k = 6
確率の視点: p を固定して、どんな結果が出るかを見る
まずは「このコインは表が 70% で出る」と仮定してみます。
つまり p = 0.7 を固定します。
このとき、20回投げたときに表が k 回出る確率は二項分布で
$$
P(K = k \mid p) = \binom{n}{k} p^k (1-p)^{n-k}
$$
で表せます。
ここで重要なのは、p を固定して、k のほうを動かしていることです。
つまり「どんなデータがどれくらい起こりやすいか」を見ています。
p_fixed = 0.7
k_values = np.arange(n + 1)
probabilities = np.array([
comb(n, k) * (p_fixed ** k) * ((1 - p_fixed) ** (n - k))
for k in k_values
])
print(f"P(K={k_obs} | p={p_fixed}) = {probabilities[k_obs]:.4f}")
plt.figure(figsize=(8, 4.5))
plt.bar(k_values, probabilities)
plt.axvline(k_obs, linestyle="--", label=f"observed k={k_obs}")
plt.xlabel("Number of heads (k)")
plt.ylabel("Probability")
plt.title(f"Probability distribution when p={p_fixed} and n={n}")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("figure1_probability.png", dpi=150, bbox_inches="tight")
plt.show()
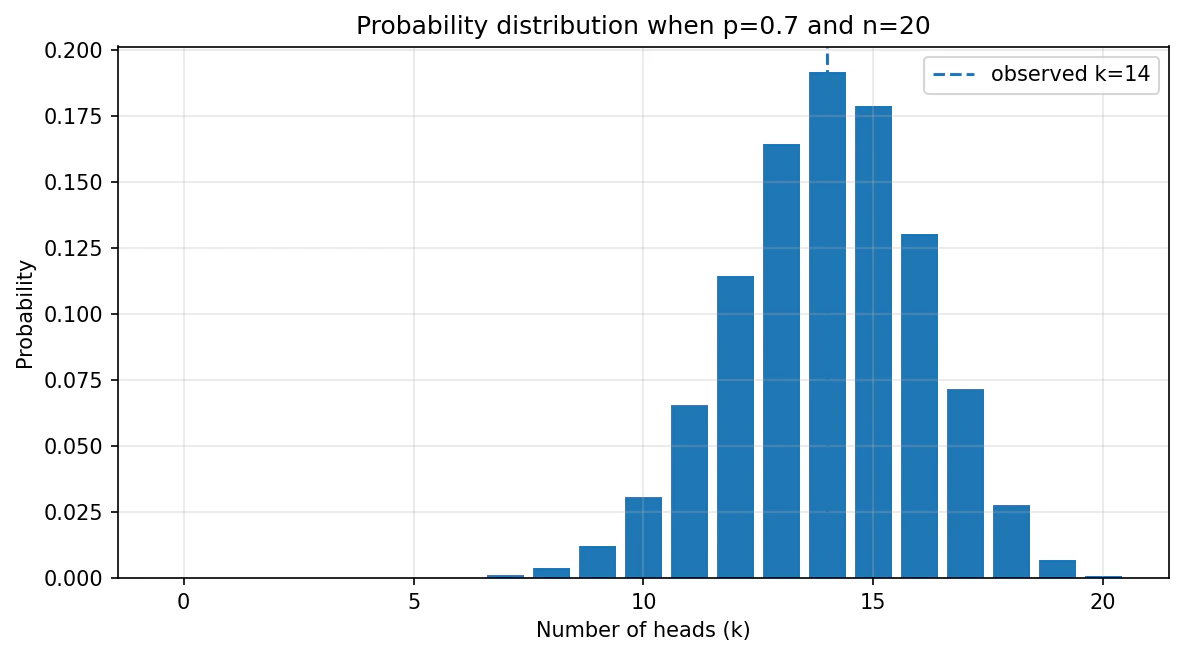
この図では、p=0.7 というコインを20回投げたとき、表の回数 k が何回くらいになりやすいかを見ています。
山の中心が 14 前後に来ているので、p=0.7 なら「20回中14回表」はかなり自然な結果だと分かります。
今回のダミーデータである k=14 の確率は、およそ 0.1916 です。
尤度の視点: データを固定して、どの p がもっともらしいかを見る
次は視点を逆にします。
今度はデータのほうを固定します。
つまり「20回投げて14回表だった」という観測結果はもう手元にある、と考えます。
そのうえで、
-
p = 0.3のコインだったら、この結果はどれくらい自然か? -
p = 0.5のコインだったらどうか? -
p = 0.7のコインだったらどうか?
を比べます。
この「観測したデータに対して、各 p がどれくらいもっともらしいか」を表すのが尤度です。
観測値 K=14 を固定すると、尤度は
$$
L(p \mid K=14) \propto p^{14}(1-p)^6
$$
の形になります。
p に依存しない $\binom{20}{14}$ は、「どの p がよりもっともらしいか」を比べるだけなら省略できます。
p_grid = np.linspace(0.001, 0.999, 500)
likelihood = np.array([
comb(n, k_obs) * (p ** k_obs) * ((1 - p) ** (n - k_obs))
for p in p_grid
])
# 見やすさのため、最大値が 1 になるように正規化
relative_likelihood = likelihood / likelihood.max()
p_hat = k_obs / n
print(f"最尤推定値 p_hat = {p_hat:.2f}")
plt.figure(figsize=(8, 4.5))
plt.plot(p_grid, relative_likelihood, linewidth=2)
plt.axvline(p_hat, linestyle="--", label=f"MLE p̂={p_hat:.2f}")
plt.xlabel("p")
plt.ylabel("Relative likelihood")
plt.title(f"Likelihood of p after observing {k_obs} heads out of {n} tosses")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("figure2_likelihood.png", dpi=150, bbox_inches="tight")
plt.show()
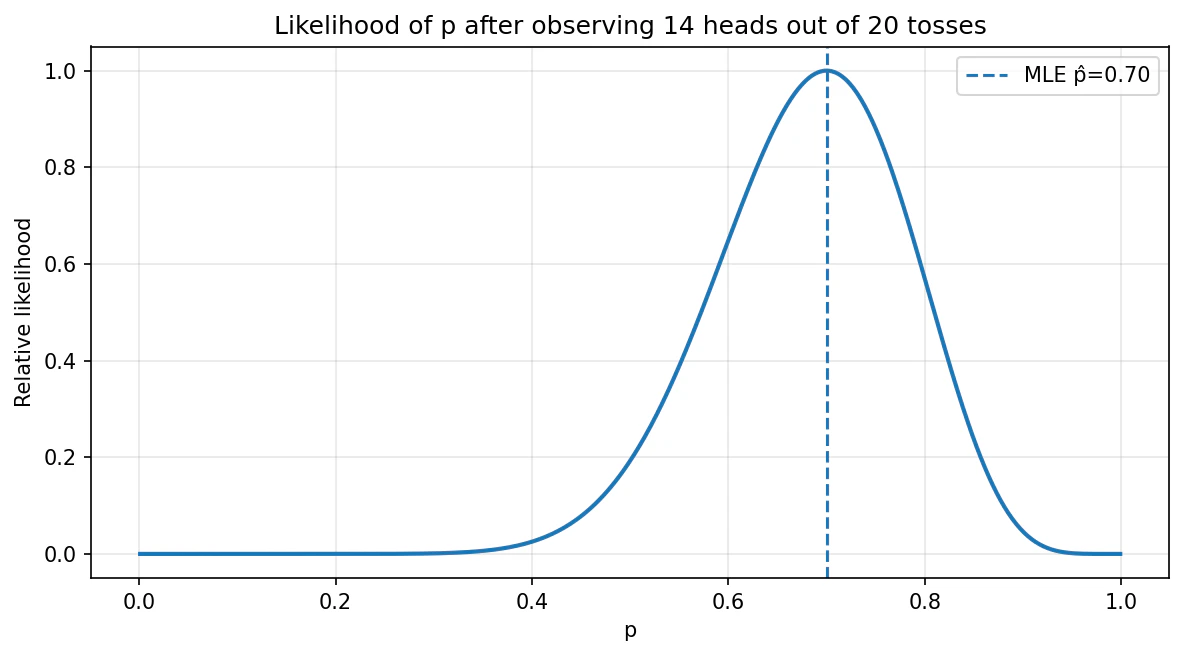
この図では、データは固定で、p のほうを動かしています。
山の頂点が p=0.70 付近にあるので、今回の観測結果 14/20 を最もよく説明するのは p=0.70 付近だと分かります。
これが最尤推定です。
今回の例では
$$
\hat{p} = \frac{14}{20} = 0.7
$$
となります。
「同じ式っぽい」のに、なぜ意味が違うのか
ここがいちばん混乱しやすいところです。
確率も尤度も、見た目はほとんど同じ式を使います。
$$
\binom{n}{k} p^k (1-p)^{n-k}
$$
でも、意味は次のように違います。
-
確率:
pを固定して、kがどう動くかを見る -
尤度:
kを固定して、pがどう動くかを見る
つまり、数式が同じでも、何を変数として見ているかが違うのです。
尤度は「パラメータの確率」ではない
初心者がつまずきやすいのがここです。
p=0.7 の尤度が高いからといって、それは
- 「
p=0.7である確率が高い」
という意味ではありません。
尤度は、あくまで観測データに照らしたときの “もっともらしさのスコア” です。
確率分布なら、データ側について全部足すと 1 になります。
でも尤度は、p について足したり積分したりしても 1 になる必要はありません。
尤度は「確率そのもの」ではなく、
観測済みデータに対して、各パラメータを比較するためのものさしです。
ここを押さえると、尤度と確率をかなり区別しやすくなります。
この記事の例で一言で言うと
今回のダミーデータは「20回中14回表」でした。
-
確率の話では
p=0.7のコインを使うと、k=14回表が出る確率はどれくらいか?
を考えます。 -
尤度の話では
k=14回表という結果が得られたとき、どのpがもっともらしいか?
を考えます。
同じ現象を見ていても、問いの向きが逆なのです。
まとめ
- 確率は、パラメータを固定してデータの起こりやすさを見る
- 尤度は、データを固定してパラメータのもっともらしさを見る
- 数式が似ていても、何を固定して何を動かすかが違う
- 尤度は確率ではなく、パラメータ比較のためのスコア
- 尤度が最大になるパラメータを選ぶのが最尤推定
統計や機械学習の本で P(data | parameter) のような式が出てきたら、
- いま固定しているのはどちらか?
- いま比べたいのはどちらか?
を見ると、確率なのか尤度なのかを見分けやすくなります。
おわりに
今回はコイン投げで説明しましたが、正規分布や回帰モデルでも本質は同じです。
「データを生成する向き」で見るのが確率、
「観測データからパラメータを逆向きに評価する」のが尤度です。
この違いが腑に落ちると、最尤推定、交差エントロピー、ベイズ推定あたりもかなり読みやすくなります。