はじめに
LLMや自然言語処理の話を読んでいると、よく Perplexity という指標が出てきます。
日本語では「困惑度」と訳されることもありますが、最初に見ると少し分かりにくい指標です。
この記事では、Perplexityを次のように直感的に理解することを目指します。
Perplexityが低い
= モデルが「次に来る正解トークン」に高い確率を置けている
= 次に何が来るかについて、あまり迷っていない
ここでいうPerplexityは、AI検索サービスの名前ではなく、言語モデルの評価指標としてのPerplexityです。
この記事では、実データではなくダミーデータを使って、初心者にも分かりやすい形で確認します。
Perplexityを一言でいうと
Perplexityは、ざっくり言うと
モデルが次の単語・トークンを当てるとき、平均してどれくらい迷っているか
を表す指標です。
たとえば、ある文の続きを予測するときに、モデルが正解トークンに高い確率を付けていれば、Perplexityは低くなります。
逆に、正解トークンに低い確率しか付けられていない場合、Perplexityは高くなります。
まずは数式を確認する
言語モデルは、文をトークン列として見ます。
たとえば、
今日 は いい 天気 です 。
という文があったとします。
モデルはそれぞれの位置で、
「今日」の次は「は」っぽい
「今日は」の次は「いい」っぽい
「今日はいい」の次は「天気」っぽい
...
というように、次のトークンに確率を割り当てます。
Perplexityは次のように定義されます。
Perplexity = exp(平均Negative Log Likelihood)
もう少し式っぽく書くと、
PPL = exp( - 1/N * Σ log p(正解トークン) )
ここで重要なのは、Perplexityは 正解トークンに付けた確率 を見ているという点です。
直感:Perplexityは「平均何択で迷っているか」に近い
もし、すべての時点で正解トークンに同じ確率 p を付けているなら、Perplexityはかなり単純になります。
Perplexity = 1 / p
たとえば、
| 正解トークンに付けた確率 | Perplexity |
|---|---|
| 0.8 | 1.25 |
| 0.5 | 2.0 |
| 0.25 | 4.0 |
| 0.1 | 10.0 |
となります。
つまり、正解に0.5くらいの確率を付けられるなら、直感的には「2択くらいで迷っている」感じです。
正解に0.1しか付けられないなら、「10択くらいで迷っている」感じです。
ただし、これはあくまで直感です。実際の言語モデルでは語彙数も大きく、確率分布も均等ではありません。そのため、Perplexityを厳密に「候補数」として読むのは危険です。
それでも、
Perplexityが低いほど、モデルは正解に自信を持てている
という理解はかなり役に立ちます。
ダミーデータで確認する
ここでは、3つの架空のモデルを用意します。
- Good model
- OK model
- Poor model
各モデルが、次に来る正解トークンにどれくらいの確率を付けたか、というダミーデータを作ります。
実際の言語モデルでは、語彙全体に対して確率分布を出します。
しかしこの記事では分かりやすさを優先して、正解トークンに付けた確率だけを記録します。
Google Colabで実行するコード
以下のコードをGoogle Colabで実行してください。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
# 画像の保存先
OUT_DIR = Path("perplexity_figures")
OUT_DIR.mkdir(exist_ok=True)
# ダミーデータ
# 各モデルが「正解トークン」に付けた確率を表す
toy = pd.DataFrame({
"position": list(range(1, 9)),
"context": [
"今日",
"今日は",
"今日はいい",
"今日はいい天気",
"今日はいい天気です",
"猫",
"猫が",
"猫がソファで",
],
"target_token": ["は", "いい", "天気", "です", "。", "が", "ソファで", "寝ています"],
"Good model": [0.70, 0.65, 0.80, 0.74, 0.90, 0.85, 0.78, 0.82],
"OK model": [0.35, 0.30, 0.45, 0.40, 0.55, 0.50, 0.38, 0.42],
"Poor model": [0.10, 0.08, 0.15, 0.12, 0.20, 0.18, 0.11, 0.13],
})
model_cols = ["Good model", "OK model", "Poor model"]
# Perplexityなどを計算
rows = []
for model in model_cols:
probs = toy[model].to_numpy()
# Negative Log Likelihood の平均
avg_nll = -np.log(probs).mean()
# Perplexity
ppl = np.exp(avg_nll)
# 正解トークン確率の幾何平均
# Perplexity = 1 / 幾何平均確率
geom_mean_prob = np.exp(np.log(probs).mean())
# 参考:算術平均
avg_prob = probs.mean()
# 参考:1トークンあたりの平均bit数
avg_bits = avg_nll / np.log(2)
rows.append({
"model": model,
"arithmetic_mean_correct_prob": avg_prob,
"geometric_mean_correct_prob": geom_mean_prob,
"avg_NLL_nats": avg_nll,
"avg_bits_per_token": avg_bits,
"perplexity": ppl,
})
summary = pd.DataFrame(rows)
# 見やすく丸めて表示
display_df = summary.copy()
for col in display_df.columns[1:]:
display_df[col] = display_df[col].round(3)
print("Toy data")
display(toy)
print("Summary")
display(display_df)
# 図1:各ステップで正解トークンに付けた確率
ax = toy.set_index("position")[model_cols].plot(kind="bar", figsize=(10, 4), rot=0)
ax.set_title("Probability assigned to the correct next token")
ax.set_xlabel("prediction step")
ax.set_ylabel("probability")
ax.set_ylim(0, 1.0)
ax.legend(title="model")
plt.tight_layout()
plt.savefig(OUT_DIR / "fig1_correct_probability_by_step.png", dpi=200, bbox_inches="tight")
plt.show()
# 図2:モデルごとのPerplexity
plot_summary = summary.set_index("model").loc[model_cols]
ax = plot_summary["perplexity"].plot(kind="bar", figsize=(7, 4), rot=0)
ax.set_title("Perplexity of each dummy model (lower is better)")
ax.set_xlabel("model")
ax.set_ylabel("perplexity")
ax.set_ylim(0, max(plot_summary["perplexity"]) * 1.2)
for i, value in enumerate(plot_summary["perplexity"]):
ax.text(i, value + 0.15, f"{value:.2f}", ha="center", va="bottom")
plt.tight_layout()
plt.savefig(OUT_DIR / "fig2_perplexity_by_model.png", dpi=200, bbox_inches="tight")
plt.show()
# 図3:正解確率pとPerplexityの関係
p_grid = np.linspace(0.05, 0.95, 200)
ppl_grid = 1 / p_grid
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(p_grid, ppl_grid)
ax.set_title("If every correct token has probability p, perplexity = 1 / p")
ax.set_xlabel("probability assigned to the correct token: p")
ax.set_ylabel("perplexity")
ax.set_ylim(0, 21)
ax.grid(True, alpha=0.3)
for p in [0.1, 0.25, 0.5, 0.8]:
ax.scatter([p], [1/p])
ax.text(p, 1/p + 0.8, f"p={p:.2f}\nPPL={1/p:.1f}", ha="center", va="bottom")
plt.tight_layout()
plt.savefig(OUT_DIR / "fig3_probability_vs_perplexity.png", dpi=200, bbox_inches="tight")
plt.show()
# 図4:学習データと検証データのPerplexity
# 学習データでは下がり続けるが、検証データでは途中から悪化する例
epochs = np.arange(1, 11)
train_ppl = np.array([9.0, 6.6, 5.0, 4.0, 3.4, 2.9, 2.5, 2.1, 1.8, 1.6])
valid_ppl = np.array([9.2, 7.1, 5.5, 4.6, 4.0, 3.8, 3.9, 4.2, 4.7, 5.3])
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(epochs, train_ppl, marker="o", label="train")
ax.plot(epochs, valid_ppl, marker="o", label="validation")
ax.set_title("Training vs validation perplexity")
ax.set_xlabel("epoch")
ax.set_ylabel("perplexity")
ax.set_xticks(epochs)
ax.grid(True, alpha=0.3)
ax.legend()
best_epoch = epochs[np.argmin(valid_ppl)]
best_value = valid_ppl.min()
ax.scatter([best_epoch], [best_value], s=80)
ax.text(best_epoch, best_value + 0.4, f"best validation\nepoch {best_epoch}", ha="center")
plt.tight_layout()
plt.savefig(OUT_DIR / "fig4_train_validation_perplexity.png", dpi=200, bbox_inches="tight")
plt.show()
print("Saved figures:")
for path in OUT_DIR.glob("*.png"):
print(path)
実行結果の見方
今回のダミーデータでは次の結果になります。
| model | 正解確率の幾何平均 | 平均NLL | 平均bits/token | Perplexity |
|---|---|---|---|---|
| Good model | 0.776 | 0.253 | 0.365 | 1.288 |
| OK model | 0.412 | 0.887 | 1.279 | 2.427 |
| Poor model | 0.128 | 2.052 | 2.961 | 7.785 |
ここで見るべきなのは、Perplexityが低いモデルほど、正解トークンに高い確率を付けられているという点です。
Good modelは、正解トークンにかなり高い確率を置けています。
そのため、Perplexityは約1.29と低くなっています。
一方、Poor modelは正解トークンに低い確率しか置けていません。
そのため、Perplexityは約7.78と高くなっています。
図1:正解トークンに付けた確率を見る
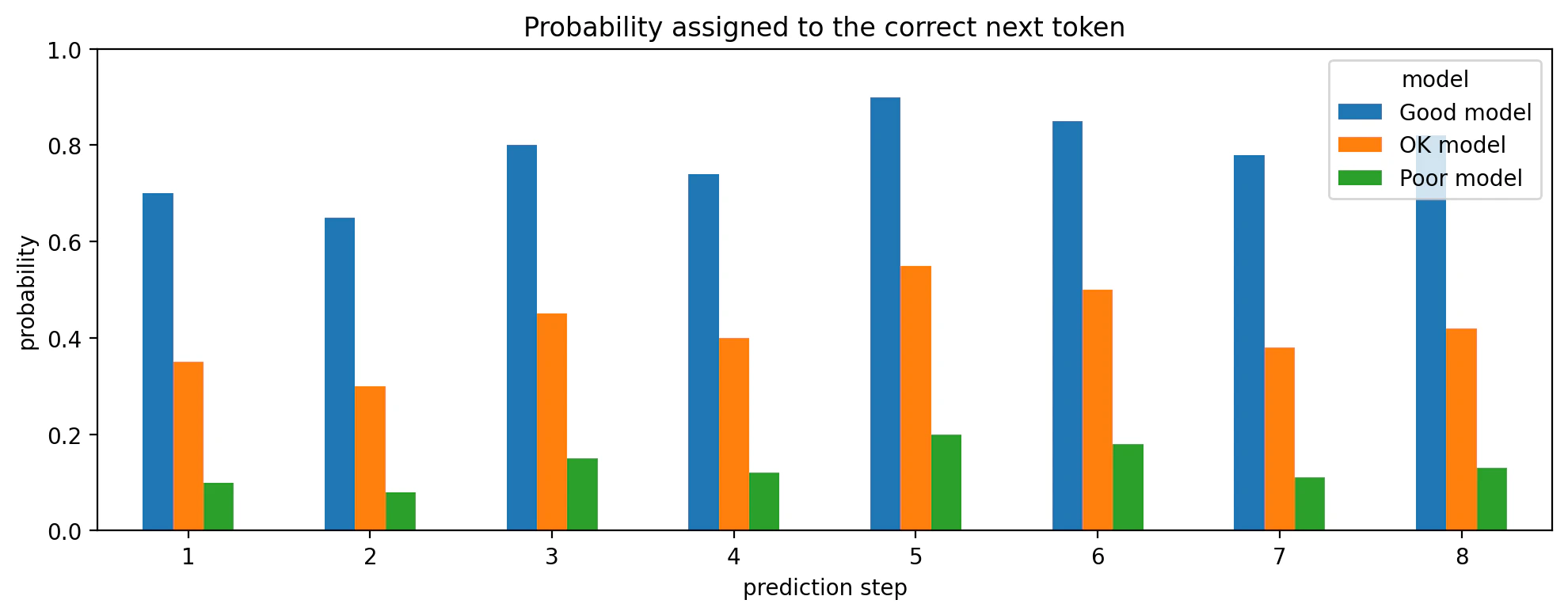
図1では、各予測ステップで、モデルが正解トークンに付けた確率を比較しています。
Good modelは、どのステップでも正解トークンに高い確率を付けています。
OK modelはそこそこです。
Poor modelは、正解トークンにかなり低い確率しか付けていません。
ここから分かるのは、Perplexityの低さは単に謎のスコアではなく、かなり素直に
正解にどれだけ高い確率を置けたか
を反映しているということです。
図2:Perplexityを比較する
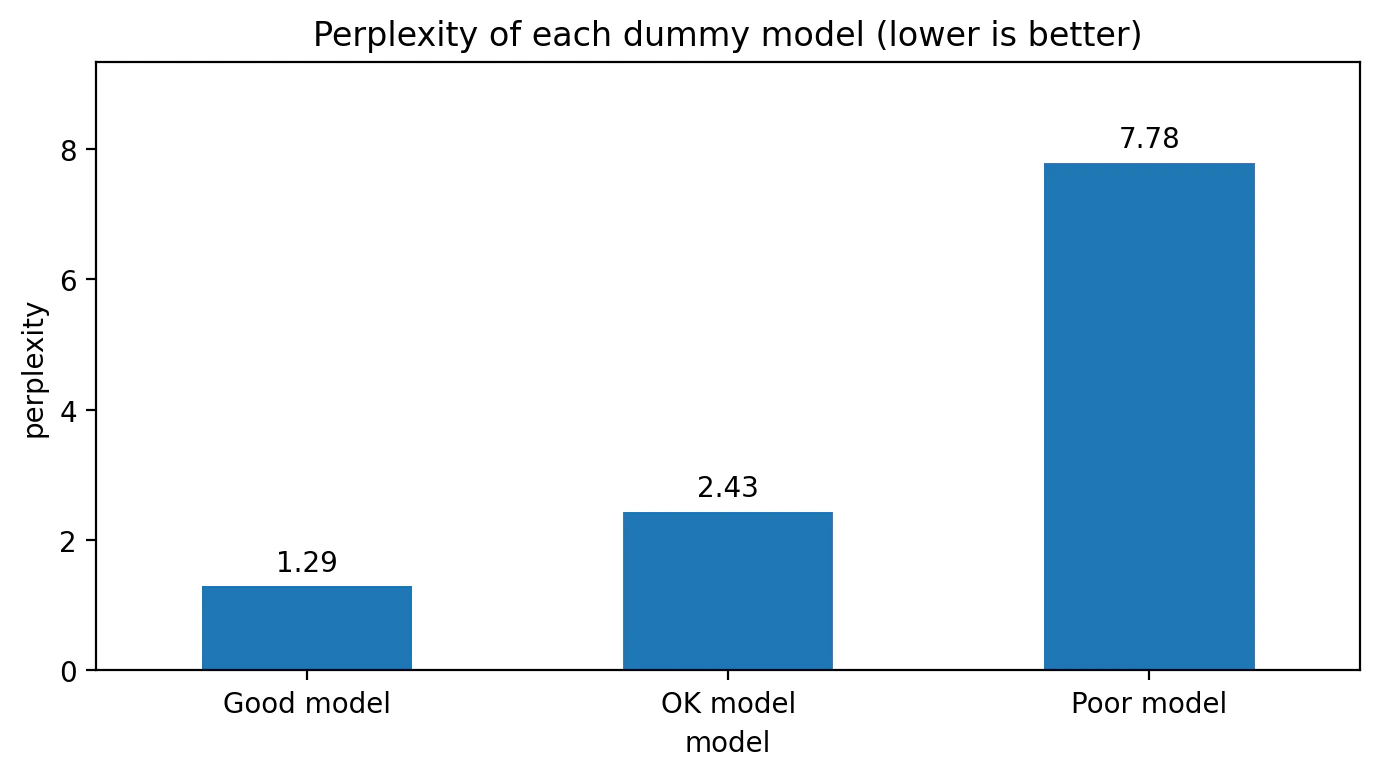
図2では、3つのモデルのPerplexityを比較しています。
結果は次のようになりました。
Good model : 1.29
OK model : 2.43
Poor model : 7.78
Perplexityは 低いほど良い 指標です。
Good modelは、平均的には「1.3択くらいで迷っている」ような状態に近いです。
OK modelは「2.4択くらいで迷っている」ような状態です。
Poor modelは「7.8択くらいで迷っている」ような状態です。
もちろん、実際の言語モデルが本当にその候補数だけを見ているわけではありません。
しかし、直感としてはかなり分かりやすい読み方です。
図3:正解確率が上がるとPerplexityは下がる
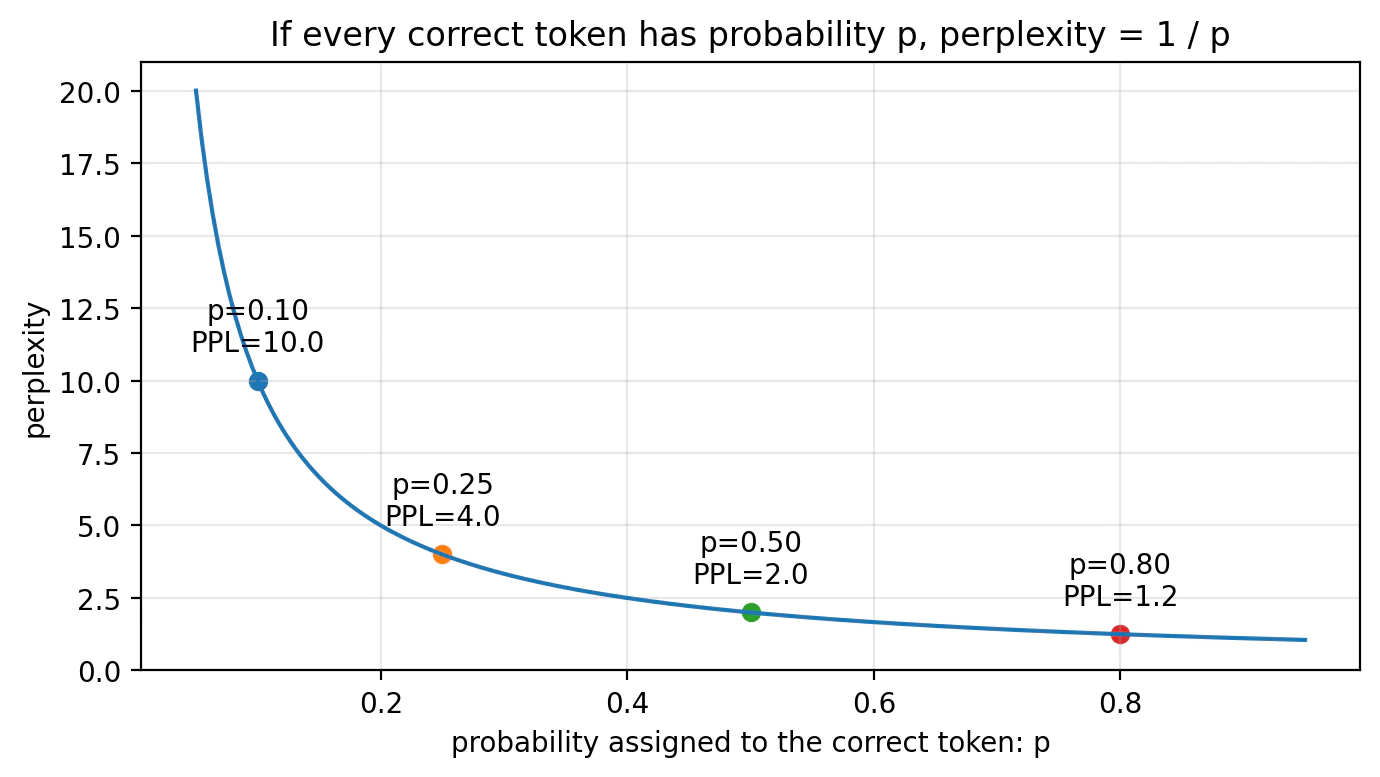
図3では、すべての正解トークンに同じ確率 p を付けたと仮定して、Perplexityとの関係を描いています。
この場合、
Perplexity = 1 / p
です。
たとえば、
p = 0.10 のとき Perplexity = 10.0
p = 0.25 のとき Perplexity = 4.0
p = 0.50 のとき Perplexity = 2.0
p = 0.80 のとき Perplexity = 1.25
となります。
この図を見ると、Perplexityが低いということは、正解トークンにかなり高い確率を置けていることだと分かります。
では、Perplexityが低いと何が嬉しいのか?
ここからが本題です。
Perplexityが低いと、何が嬉しいのでしょうか。
1. 次のトークン予測がうまい
Perplexityが低いということは、モデルが正解トークンに高い確率を付けられているということです。
つまり、文章の続きを予測するタスクにおいて、モデルがより自然な候補を上位に置けている可能性が高いです。
文章補完や予測変換のような用途では、これはかなり嬉しいことです。
たとえば、
今日はいい
という文脈に対して、
天気
に高い確率を置けるモデルは、自然な続きを予測できています。
一方で、
唐揚げ
宇宙船
会議
のようなトークンにばかり高い確率を置いてしまうモデルは、この文脈ではあまり良いモデルとは言えません。
2. モデルが文章のパターンをよく学習している
Perplexityが低いモデルは、学習したデータの中にある言語的なパターンをよく捉えている可能性があります。
たとえば、
猫がソファで
という文脈では、
寝ています
くつろいでいます
丸くなっています
のような続きが自然です。
このような自然な続きを高く評価できるモデルは、文章の構造や語の共起関係をある程度学習できていると考えられます。
3. 圧縮の観点でも嬉しい
Perplexityは、情報量や圧縮とも関係があります。
モデルが正解トークンを高い確率で予測できるなら、そのトークンを表すのに必要な情報量は少なくなります。
今回の表を見ると、Good modelは平均 0.365 bits/token、Poor modelは平均 2.961 bits/token です。
つまり、Good modelのほうが、同じトークン列をより少ない情報量で表せる、という見方ができます。
直感的には、
よく予測できるものは、短く説明できる
ということです。
4. モデル比較に使いやすい
Perplexityは、モデル同士を比較するときによく使われます。
たとえば、同じデータセット、同じトークナイザ、同じ評価条件で、次のような結果が出たとします。
| モデル | Validation Perplexity |
|---|---|
| Model A | 25 |
| Model B | 18 |
| Model C | 12 |
この条件では、Model Cが最も低いPerplexityなので、少なくとも「次トークン予測」という観点では良いモデルだと考えられます。
ただし、ここで重要なのは 同じ条件で比較すること です。
データセットやトークナイザが違うと、Perplexityを単純に比較するのは危険です。
5. 学習の進み具合を確認できる
Perplexityは、学習中のモデルを監視するためにも使えます。
図4:Train Perplexityだけを見てはいけない
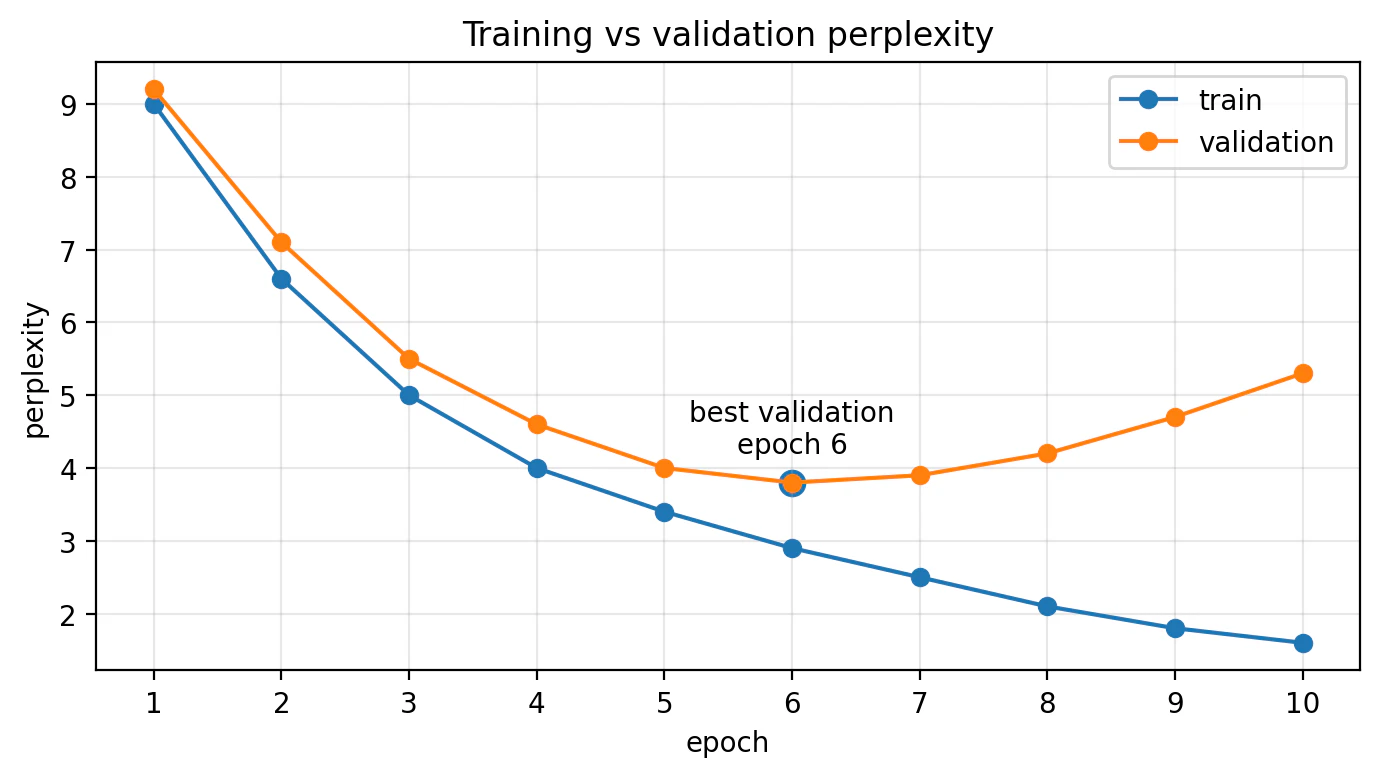
図4では、学習データと検証データのPerplexityを描いています。
Train Perplexityは下がり続けています。
しかし、Validation Perplexityは途中まで下がったあと、再び上がっています。
これは、モデルが学習データに過剰に適合している、つまり 過学習 している可能性を示しています。
この例では、Validation Perplexityが最も低いのはepoch 6です。
つまり、
学習データでのPerplexityが低ければ低いほど良い
とは限りません。
実際には、未知のデータに対する性能を見るために、Validation PerplexityやTest Perplexityを見ることが重要です。
Perplexityを見るときの注意点
Perplexityは便利な指標ですが、万能ではありません。
注意点1:トークナイザが違うと比較しにくい
Perplexityは「トークン」単位で計算されます。
そのため、トークナイザが違うと、同じ文章でもトークン数が変わります。
たとえば、あるトークナイザでは
こんにちは
が1トークンかもしれません。
別のトークナイザでは、
こん
にち
は
のように複数トークンに分かれるかもしれません。
この場合、Perplexityをそのまま比較するのは危険です。
注意点2:低Perplexityでも、良い回答とは限らない
Perplexityは、主に「次のトークンをどれだけ予測できたか」を測る指標です。
しかし、実際にLLMを使うときには、他にも重要な要素があります。
- 事実に基づいているか
- 指示に従っているか
- 安全な回答か
- 読みやすい文章か
- ユーザーの意図に合っているか
Perplexityが低くても、これらが必ず良いとは限りません。
たとえば、学習データにありがちな文章をなめらかに出すことは得意でも、質問に正確に答えるのは苦手かもしれません。
注意点3:データ漏洩があると不自然に低くなる
評価データが学習データに混ざっていると、Perplexityは不自然に低くなります。
これは、モデルが本当に汎化しているのではなく、評価データを覚えてしまっている可能性があるからです。
そのため、Perplexityを見るときは、評価データが適切に分離されているかも重要です。
まとめ
Perplexityは、言語モデルが次のトークンをどれくらいうまく予測できているかを見るための指標です。
この記事のポイントは次の通りです。
- Perplexityは低いほど良い
- 正解トークンに高い確率を付けられるとPerplexityは下がる
- 直感的には「平均何択で迷っているか」に近い
- モデル比較や学習状況の確認に使える
- ただし、トークナイザやデータセットが違う場合は単純比較できない
- Perplexityが低くても、指示追従性や安全性や事実性が高いとは限らない
Perplexityは、LLMのすべてを説明する指標ではありません。
しかし、
モデルが文章の続きをどれだけ自然に予測できているか
を理解するための、とても重要な入口になる指標です。