この記事でやること
次元削減について説明するとき、よく次のような言い方をします。
次元削減は、なるべく大事な情報を残しながら、不要な情報を捨てる処理です。
ただ、この「情報を捨てる」とは、具体的に何を捨てているのでしょうか?
この記事では、ダミーデータを作りながら、次元削減で何が残り、何が失われるのかを初心者向けに説明します。
Google Colabでそのまま実行できるコードも載せます。
先に結論
次元削減で「情報を捨てる」とは、ざっくり言うと次のことです。
元のデータを完全には復元できなくなること
もう少し言い換えると、
低次元の表現だけを見ても、元のデータの細かい違いを区別できなくなること
です。
特にPCAのような手法では、多くの場合、
データのばらつきが小さい方向の情報
を捨てます。
ただし、注意点があります。
ばらつきが小さい情報 = 不要な情報
とは限りません。
あとで、ばらつきは小さいけれど分類には重要な情報をPCAが捨ててしまう例も見ます。
用語の整理
まず、次元削減に出てくる基本用語を整理します。
| 用語 | 意味 |
|---|---|
| データ点 | 1つのサンプル。例えば1人のユーザー、1件のログ、1枚の画像など |
| 特徴量 | データ点を表す数値。例えば身長、体重、購入回数など |
| 次元 | 特徴量の数 |
| 次元削減 | 特徴量の数を減らすこと |
| 復元 | 低次元にしたデータから、元の高次元データを近似的に戻すこと |
例えば、次のようなデータがあるとします。
| 人 | 身長 | 体重 | 年齢 |
|---|---|---|---|
| Aさん | 170 | 65 | 25 |
| Bさん | 160 | 50 | 30 |
この場合、特徴量は「身長」「体重」「年齢」の3つなので、これは3次元データです。
ここから「身長」「体重」「年齢」をうまくまとめて、例えば2つの値で表せるようにするのが次元削減です。
なぜ次元を減らすと情報が失われるのか
一番大事なのは、次元削減は多くの場合、多対一の変換になるということです。
例えば、2次元の点 (x1, x2) を、次のように1次元の値 z に変換するとします。
z = x1 + x2
すると、次のような点はすべて同じ z になります。
| 元の2次元データ | 変換後の1次元データ |
|---|---|
(1, 3) |
4 |
(2, 2) |
4 |
(3, 1) |
4 |
変換後の z = 4 だけを見ても、元が (1, 3) だったのか、(2, 2) だったのか、(3, 1) だったのかは分かりません。
つまり、元の点同士の違いを区別するための情報が消えたということです。
これが「情報を捨てる」の基本的な意味です。
PCAで見る「捨てる情報」
ここからはPCAを使って、より具体的に見ていきます。
PCAは日本語では主成分分析と呼ばれます。
とてもざっくり言うと、PCAは次のような手法です。
データがよく広がっている方向を探し、その方向を優先的に残す
例えば、2次元の点が斜め方向に細長く分布しているなら、PCAはだいたい次のように考えます。
- 斜め方向の位置はよく変化しているので、重要そう
- 斜め線からの細かいズレは小さいので、捨ててもよさそう
この「斜め方向の位置」を残し、「斜め線からのズレ」を捨てるのが、今回見る2次元から1次元へのPCAです。
Google Colabで実行する準備
以下のコードはGoogle Colabでそのまま実行できます。
ダミーデータを作る
今回は、2つの特徴量 feature 1 と feature 2 を持つダミーデータを作ります。
ポイントは、データの大部分が斜め方向に並ぶようにすることです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
plt.rcParams["figure.dpi"] = 120
# =========================
# 1. 斜め方向に伸びた2次元データを作る
# =========================
rng = np.random.default_rng(42)
n = 120
z = np.linspace(-3, 3, n) # 本当は1つの値でほぼ説明できる「芯」
noise = rng.normal(0, 0.45, n) # 芯からの小さなズレ
x1 = z + noise * 0.5
x2 = z - noise * 0.5
X = np.c_[x1, x2]
# =========================
# 2. PCAで2次元の軸を調べる
# =========================
pca = PCA(n_components=2)
Z_all = pca.fit_transform(X)
mean = pca.mean_
pc1, pc2 = pca.components_
explained = pca.explained_variance_ratio_
# =========================
# 3. 2次元 -> 1次元 -> 2次元に戻す
# =========================
pca_1d = PCA(n_components=1)
Z_1d = pca_1d.fit_transform(X)
X_reconstructed = pca_1d.inverse_transform(Z_1d)
residual = X - X_reconstructed
mse_0d = np.mean(np.sum((X - X.mean(axis=0)) ** 2, axis=1))
mse_1d = np.mean(np.sum(residual ** 2, axis=1))
mse_2d = 0.0
print(f"PC1の寄与率: {explained[0]:.3f}")
print(f"PC2の寄与率: {explained[1]:.3f}")
print(f"0次元(平均との差だけ)MSE: {mse_0d:.4f}")
print(f"1次元(PC1だけ)MSE: {mse_1d:.4f}")
print(f"2次元(元の次元数)MSE: {mse_2d:.4f}")
以下の出力が出ます。
PC1の寄与率: 0.990
PC2の寄与率: 0.010
0次元(平均との差だけ)MSE: 6.1627
1次元(PC1だけ)MSE: 0.0609
2次元(元の次元数)MSE: 0.0000
PC1 は第1主成分、PC2 は第2主成分です。
この例では、PC1だけでデータのばらつきの約99%を説明できています。
つまり、2次元データではあるものの、実質的にはかなり1次元に近いデータです。
図1:元データとPCAの軸
次のコードで、元データとPCAが見つけた軸を描画します。
def draw_pca_axis(ax, center, component, length, label, linestyle="-"):
start = center - component * length
end = center + component * length
ax.plot(
[start[0], end[0]],
[start[1], end[1]],
linestyle=linestyle,
linewidth=2,
label=label
)
# 図1: 元データとPCAの軸
fig, ax = plt.subplots(figsize=(6, 6))
ax.scatter(X[:, 0], X[:, 1], alpha=0.7, label="original data")
draw_pca_axis(ax, mean, pc1, 3.4, "PC1: kept direction")
draw_pca_axis(ax, mean, pc2, 1.2, "PC2: discarded direction", linestyle="--")
ax.set_aspect("equal", adjustable="box")
ax.set_xlabel("feature 1")
ax.set_ylabel("feature 2")
ax.set_title("Fig.1 Original data and PCA axes")
ax.legend()
ax.grid(True)
fig.savefig("fig1_pca_axes.png", dpi=160, bbox_inches="tight")
plt.show()
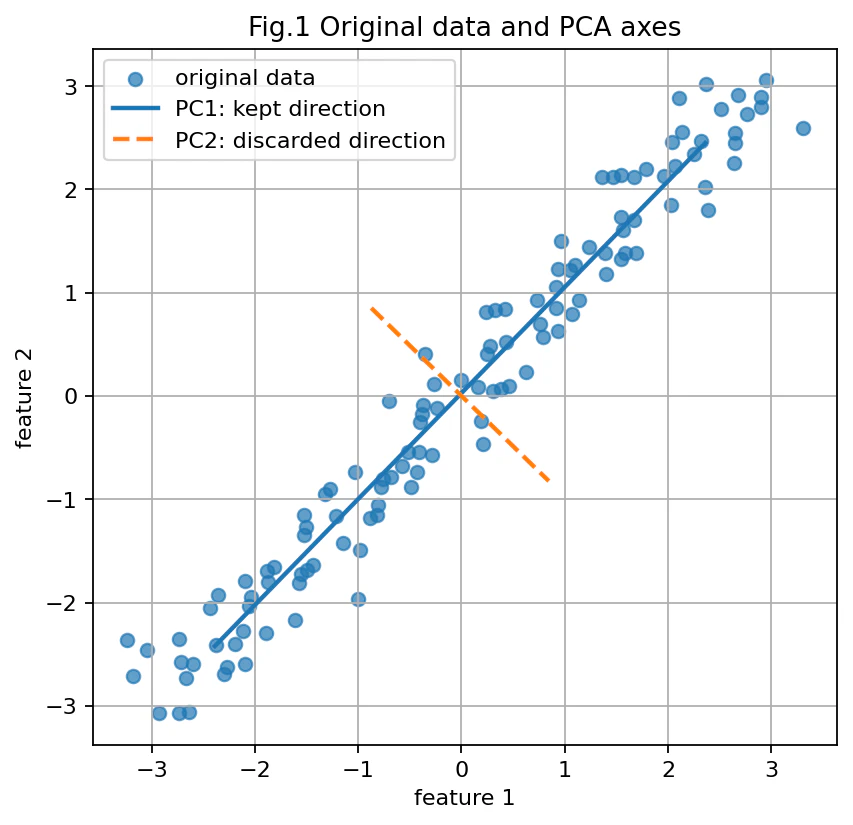
図を見ると、データは左下から右上に向かって細長く分布しています。
PCAは、この細長い方向を PC1 として見つけます。
今回、2次元から1次元に削減する場合は、PC1 方向だけを残します。
一方、PC2 は PC1 に直交する方向です。
この PC2 方向の情報が、1次元化するときに捨てられます。
「捨てる情報」はどこに見えるのか
次に、2次元データをPCAで1次元にしてから、もう一度2次元に戻してみます。
このとき、元の点と復元後の点は完全には一致しません。
その差分が、まさに「捨てられた情報」です。
# 図2: 1次元にしたあと復元した点と、復元できなかった差分
fig, ax = plt.subplots(figsize=(6, 6))
ax.scatter(X[:, 0], X[:, 1], alpha=0.35, label="original")
ax.scatter(
X_reconstructed[:, 0],
X_reconstructed[:, 1],
alpha=0.8,
label="1D -> reconstructed"
)
idx = np.arange(0, n, 8)
for j, i in enumerate(idx):
ax.plot(
[X_reconstructed[i, 0], X[i, 0]],
[X_reconstructed[i, 1], X[i, 1]],
linewidth=1,
alpha=0.8,
label="discarded residual" if j == 0 else None
)
ax.set_aspect("equal", adjustable="box")
ax.set_xlabel("feature 1")
ax.set_ylabel("feature 2")
ax.set_title("Fig.2 Discarded part = reconstruction residual")
ax.legend()
ax.grid(True)
fig.savefig("fig2_reconstruction_residual.png", dpi=160, bbox_inches="tight")
plt.show()
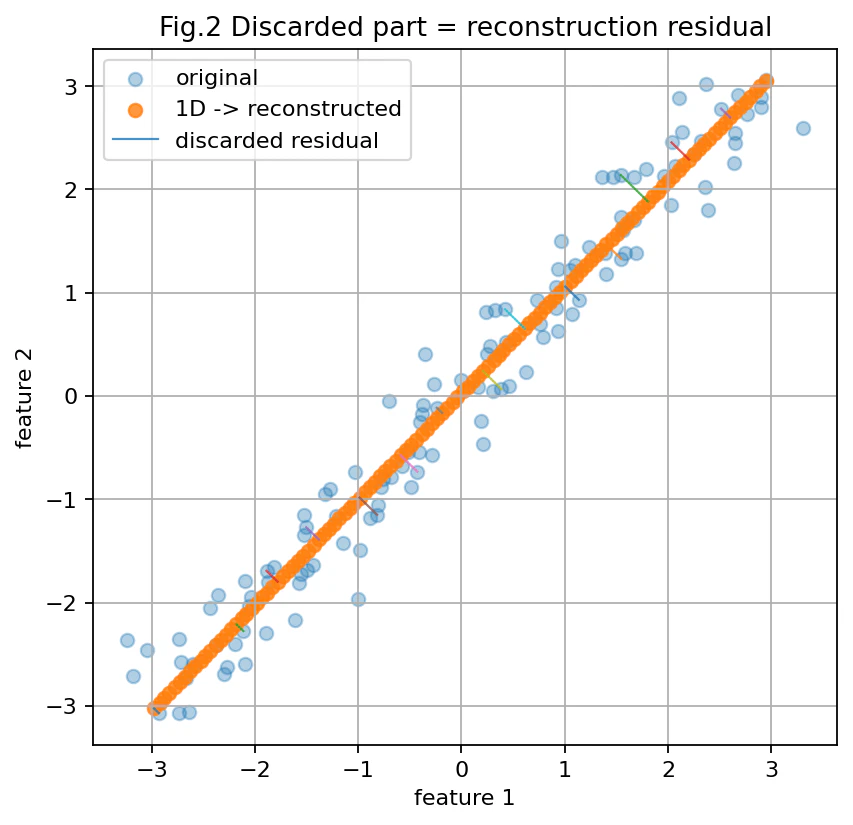
オレンジ色の点が、1次元に削減したあとに2次元へ復元した点です。
復元後の点は、ほぼ一直線上に並びます。
一方、元の青い点は、その直線から少しズレています。
このズレが、1次元化によって消えた部分です。
式で書くと、次のようなイメージです。
元のデータ = 復元されたデータ + 復元できなかった差分
この「復元できなかった差分」が、次元削減で捨てられた情報です。
今回の例では、次のように考えると分かりやすいです。
| 観点 | 残った情報 | 捨てられた情報 |
|---|---|---|
| 直感的な意味 | 斜め方向の位置 | 斜め線からの細かいズレ |
| PCAでの名前 | PC1方向の情報 | PC2方向の情報 |
| このデータでの意味 | データの大きな変化 | 小さなノイズっぽい変化 |
図3:次元を減らすほど復元誤差は大きくなる
次に、残す次元数と復元誤差の関係を見ます。
ここでは、次の3パターンを比べます。
| 残す次元数 | 意味 |
|---|---|
| 0次元 | 全データを平均との差だけで表す |
| 1次元 | PC1だけを残す |
| 2次元 | 元の次元を全部残す |
# 図3: 残す次元数と復元誤差
dims = ["0 dim\n(mean only)", "1 dim\n(PC1)", "2 dims\n(original)"]
mse_values = [mse_0d, mse_1d, mse_2d]
fig, ax = plt.subplots(figsize=(6, 4))
ax.bar(dims, mse_values)
ax.set_ylabel("mean squared reconstruction error")
ax.set_title("Fig.3 Fewer dimensions, larger reconstruction error")
ax.grid(axis="y")
offset = max(mse_values) * 0.02
for pos, value in enumerate(mse_values):
ax.text(pos, value + offset, f"{value:.4f}", ha="center")
fig.savefig("fig3_reconstruction_error.png", dpi=160, bbox_inches="tight")
plt.show()
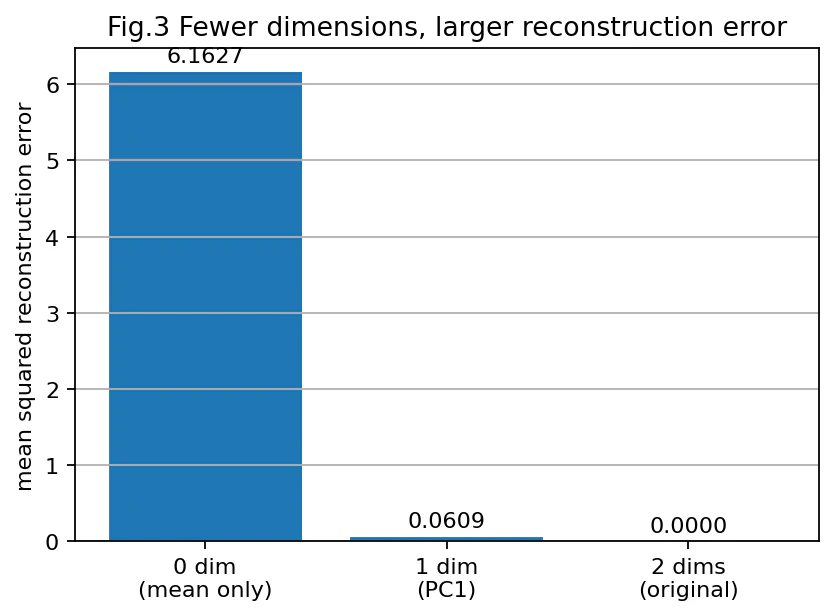
結果を見ると、0次元にすると復元誤差が大きくなります。
一方、1次元だけ残しても、復元誤差はかなり小さいです。
これは、今回のデータがほぼ斜め方向の1本の線で説明できるからです。
そして2次元を全部残せば、当然ながら元のデータをそのまま表せるので、復元誤差は0になります。
厳密には数値計算の丸め誤差はありますが、考え方としては「全部残せば捨てる情報はない」です。
ここまでのまとめ
ここまでの例では、PCAによる2次元から1次元への削減を見ました。
このとき、PCAが残したのは、
データが大きく変化している方向の位置
でした。
逆に、PCAが捨てたのは、
その方向から外れた細かいズレ
でした。
つまり、「情報を捨てる」とは、
低次元の値だけでは復元できない差分を消すこと
です。
注意:PCAが捨てる情報は本当に不要なのか?
ここまでの例では、捨てられた情報はノイズっぽいものでした。
しかし、これはいつも正しいとは限りません。
PCAは基本的に、ラベルや目的変数を見ません。
つまり、PCAは次のようなことを知りません。
- 何を分類したいのか
- 何を予測したいのか
- どの特徴が業務上重要なのか
- どの少数派パターンを見逃してはいけないのか
PCAが見るのは、主にデータのばらつきです。
そのため、ばらつきは小さいけれど、目的には重要な情報を捨ててしまうことがあります。
これをダミーデータで見てみます。
ばらつきは小さいが、分類には重要な情報の例
次のデータを作ります。
-
feature 1は大きくばらつくが、クラス分類にはあまり役に立たない -
feature 2はばらつきが小さいが、クラス分類にはとても役に立つ
rng = np.random.default_rng(7)
n = 400
label = rng.integers(0, 2, size=n)
# feature 1: 分散は大きいが、ラベルとは関係が薄い
large_irrelevant = rng.normal(0, 3.0, size=n)
# feature 2: 分散は小さいが、ラベルをかなりよく分ける
small_task_signal = (label * 2 - 1) * 0.25 + rng.normal(0, 0.08, size=n)
X_task = np.c_[large_irrelevant, small_task_signal]
pca_task = PCA(n_components=1)
Z_task = pca_task.fit_transform(X_task)
corr_feature2 = np.corrcoef(X_task[:, 1], label)[0, 1]
corr_pca_score = np.corrcoef(Z_task.ravel(), label)[0, 1]
print(f"1次元PCAの寄与率: {pca_task.explained_variance_ratio_[0]:.3f}")
print(f"元のfeature 2とラベルの相関: {corr_feature2:.3f}")
print(f"PCA 1D scoreとラベルの相関の絶対値: {abs(corr_pca_score):.3f}")
以下の出力となります。
1次元PCAの寄与率: 0.992
元のfeature 2とラベルの相関: 0.955
PCA 1D scoreとラベルの相関の絶対値: 0.013
1次元PCAは、データのばらつきの約99.2%を説明しています。
一見、とてもよさそうです。
しかし、PCA後の1次元スコアとラベルの相関はほぼ0です。
つまり、分類に必要な情報はほとんど残っていません。
図4:元の2次元ではクラスが分かれている
まず、元の2次元データを見ます。
# 図4: 元の2次元では、縦方向の小さな違いでクラスが分かれている
fig, ax = plt.subplots(figsize=(7, 4))
for cls, name in [(0, "class 0"), (1, "class 1")]:
ax.scatter(
X_task[label == cls, 0],
X_task[label == cls, 1],
alpha=0.6,
label=name
)
ax.set_xlabel("feature 1: large variance but not useful for class")
ax.set_ylabel("feature 2: small variance but useful for class")
ax.set_title("Fig.4 Small-variance direction can be task-relevant")
ax.legend()
ax.grid(True)
fig.savefig("fig4_task_relevant_small_variance.png", dpi=160, bbox_inches="tight")
plt.show()
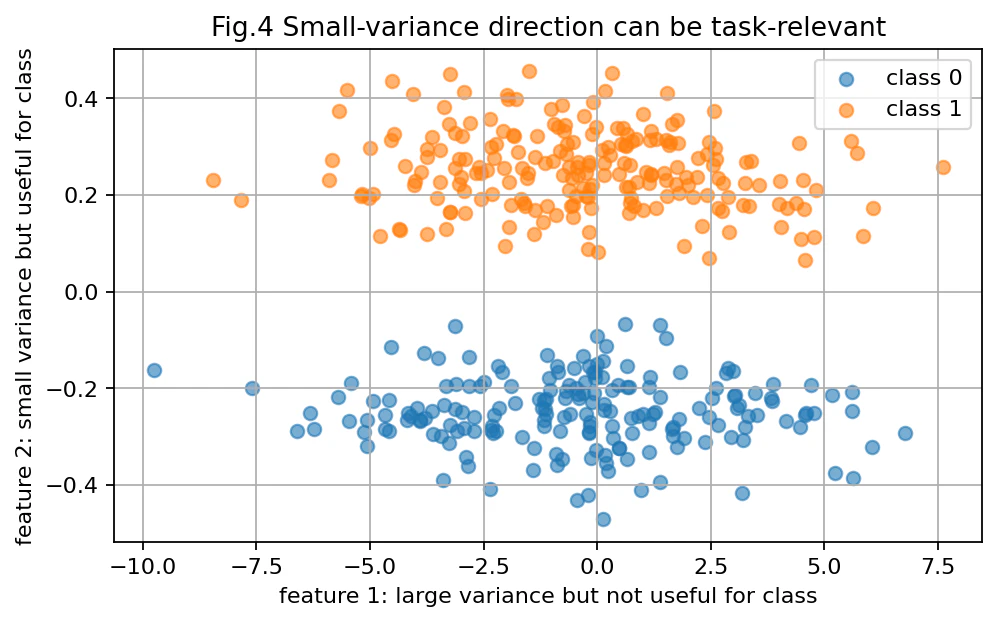
図を見ると、横方向の feature 1 は大きくばらついています。
しかし、クラスを分けているのは縦方向の feature 2 です。
feature 2 のばらつきは小さいですが、分類にはとても重要です。
図5:PCAで1次元にするとクラス情報が消える
次に、PCAで1次元にした結果を見ます。
# 図5: PCAで1次元にすると、クラス情報はほとんど残らない
fig, ax = plt.subplots(figsize=(7, 3))
jitter_rng = np.random.default_rng(0)
jitter = jitter_rng.normal(0, 0.025, size=n)
for cls, name in [(0, "class 0"), (1, "class 1")]:
ax.scatter(
Z_task[label == cls, 0],
jitter[label == cls],
alpha=0.6,
label=name
)
ax.set_xlabel("PCA 1D score")
ax.set_yticks([])
ax.set_title("Fig.5 After PCA to 1D, class information is mostly discarded")
ax.legend()
ax.grid(True, axis="x")
fig.savefig("fig5_pca_score_loses_label.png", dpi=160, bbox_inches="tight")
plt.show()
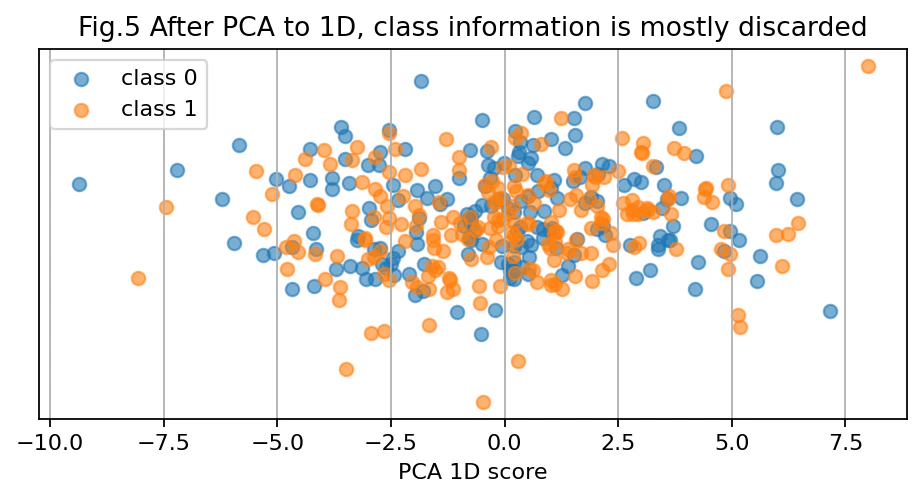
PCA後の1次元スコアでは、class 0 と class 1 がかなり混ざっています。
これは、PCAが大きくばらつく feature 1 を重視し、ばらつきの小さい feature 2 をほとんど捨てたためです。
この例から分かる重要なことは次の通りです。
PCAにとって重要な情報と、タスクにとって重要な情報は同じとは限らない
「情報を捨てる」をもう少し正確に言う
次元削減で捨てられる情報は、文脈によって少し意味が変わります。
代表的には、次の3つです。
1. 復元に必要な情報
低次元にしたあと、元のデータを完全には戻せなくなります。
このとき失われた差分が、復元の観点での「捨てた情報」です。
今回の図2で見た、元の点と復元後の点のズレがこれです。
2. 点同士を区別するための情報
次元削減後に、別々の点が同じような値になることがあります。
その場合、低次元の値だけでは、それらの点を区別しにくくなります。
これは、次のような状況です。
元は違う点だった
でも低次元ではほぼ同じ値になった
だから元の違いが分からなくなった
これも、捨てられた情報です。
3. タスクに必要な情報
分類、回帰、異常検知などの目的がある場合、その目的に必要な情報が残っているかが重要です。
PCAは教師なしの次元削減なので、基本的にはラベルを見ません。
そのため、分類に重要な情報を捨てる可能性があります。
図4と図5の例がまさにそれです。
実務で確認したいこと
次元削減を使うときは、次の観点で確認するとよいです。
復元誤差を見る
元データをどれくらい復元できるかを確認します。
PCAなら、inverse_transform を使うことで、低次元表現から元の次元へ戻した近似データを作れます。
復元誤差が大きい場合、かなり多くの情報を捨てている可能性があります。
寄与率を見る
PCAでは、寄与率を見ることで、各主成分がどれくらいのばらつきを説明しているか分かります。
例えば、
PC1の寄与率: 0.990
PC2の寄与率: 0.010
なら、PC1だけでばらつきの約99%を説明していることになります。
ただし、寄与率が高いからといって、タスクに必要な情報が残っているとは限りません。
下流タスクの性能を見る
分類や予測が目的なら、最終的にはそのタスクの性能を見る必要があります。
例えば、次元削減前後で以下を比較します。
- 分類精度
- F1スコア
- AUC
- RMSE
- MAE
- 異常検知の見逃し率
特に、少数派クラスや異常値を扱う場合は注意が必要です。
少数派クラスの特徴は、全体のばらつきとしては小さく見えることがあるからです。
標準化を検討する
PCAでは、特徴量のスケールが大きいものが強く影響します。
例えば、ある特徴量が「円単位」、別の特徴量が「割合」だと、数値のスケールが大きい特徴量が主成分を支配することがあります。
実データでは、PCAの前に標準化を検討することが多いです。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 例
# X_scaled = StandardScaler().fit_transform(X)
# Z = PCA(n_components=2).fit_transform(X_scaled)
ただし、標準化すれば常に正解というわけでもありません。
「元のスケールに意味があるのか」「すべての特徴量を同じ重みで扱いたいのか」を考える必要があります。
まとめ
次元削減で「情報を捨てる」とは、単に列を減らすことではありません。
本質的には、次のことです。
低次元の表現だけでは、元のデータを完全には復元できなくなること
または、
元のデータにあった細かい違いを区別できなくなること
PCAの場合は、多くの場合、
ばらつきが大きい方向を残し、ばらつきが小さい方向を捨てる
と考えると分かりやすいです。
ただし、
ばらつきが小さい = 不要
とは限りません。
分類や予測などの目的がある場合は、次元削減後にその目的に必要な情報が残っているかを必ず確認する必要があります。
次元削減は「不要な情報を消す魔法」ではなく、情報を圧縮する方法です。
圧縮する以上、何かは失われます。
だからこそ、
- 何を残したいのか
- 何を捨ててもよいのか
- 捨てたことで困る情報はないのか
を考えながら使うことが大切です。