分類モデルを学び始めると、かなり早い段階で 交差エントロピー(cross entropy) が出てきます。
でも、「式は見たことあるけど、なぜこれが“誤差”として自然なのかはまだ腹落ちしていない」という人は多いはずです。
この記事では、ダミーデータとGoogle Colabで追試できる最小コードを使って、交差エントロピーが自然な理由を、図と数式で整理します。
TL;DR
- 交差エントロピーは、真のクラスにどれだけ確率を置けたかを見る損失です。
- one-hotラベルの分類では、交差エントロピーは
$$
-\log(\text{真のクラスに割り当てた確率})
$$
になります。 - つまり、自信満々で外した予測を強く罰し、自信を持って当てた予測をしっかり評価できます。
- Accuracy(正解率)は「当たったか外れたか」しか見ませんが、交差エントロピーは確率の質まで見ます。
- さらに、
$$
\text{Cross Entropy} = \text{Entropy} + \text{KL Divergence}
$$
なので、交差エントロピーを最小化することは、予測分布を真の分布に近づけることと自然につながります。
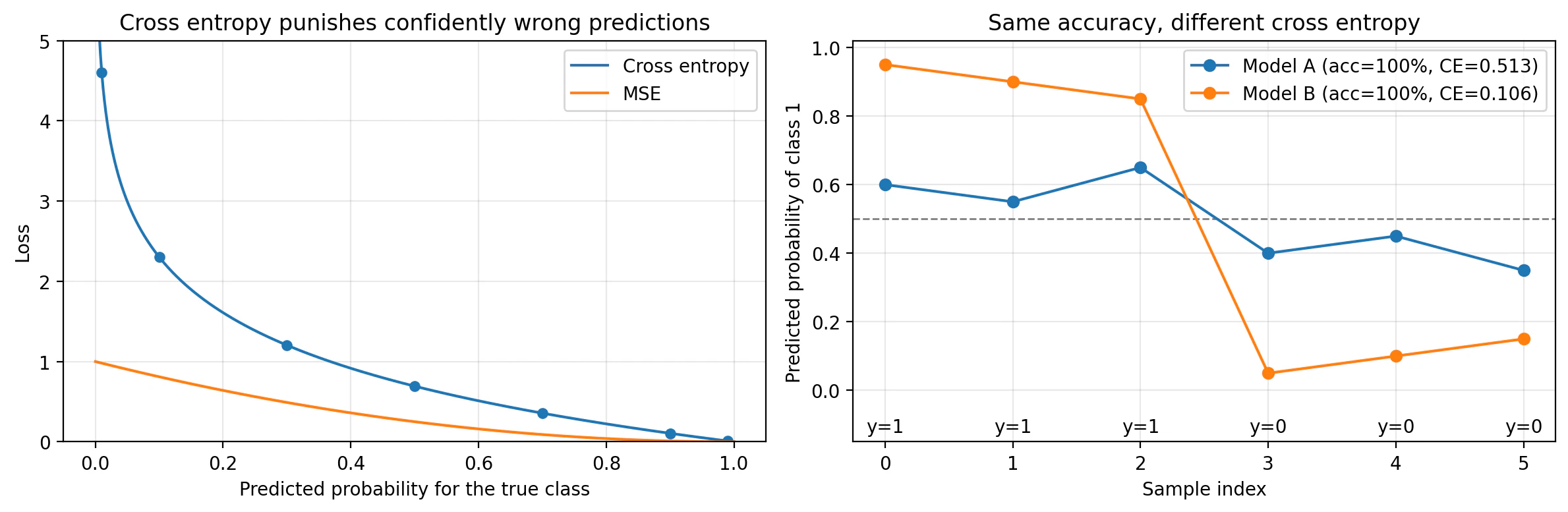
図1: 直感図(CE vs MSE、同じAccuracyでもCEは違う)
左が「交差エントロピーは自信満々の誤答を強く罰する」、右が「同じAccuracyでもCEは違う」という結果を意味する図。
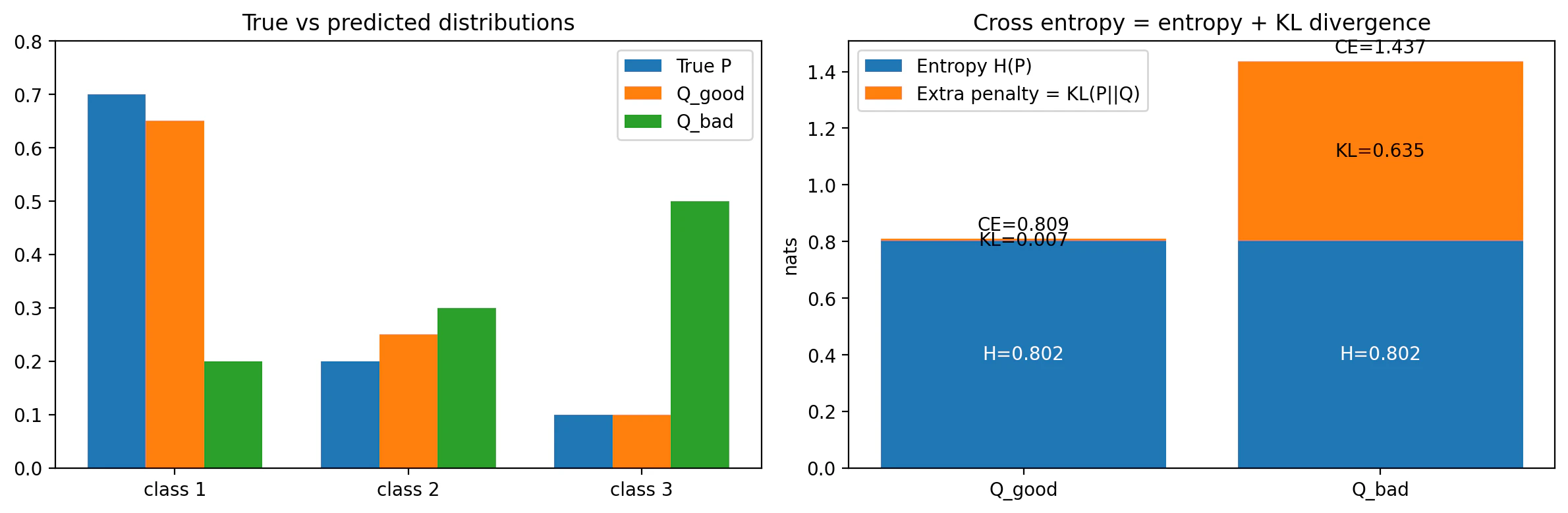
図2: CE = H + KL
まず最小で動かす
Google Colab用コード(1セル)
import numpy as np
import matplotlib.pyplot as plt
# -----------------------------
# 1) 交差エントロピーとMSEの比較(真のラベル y=1)
# -----------------------------
p_true = np.linspace(1e-4, 0.9999, 1000) # 「真のクラス」に割り当てた予測確率
cross_entropy = -np.log(p_true) # one-hotラベルなら CE = -log(p_true)
mse = (1 - p_true) ** 2 # 比較用(確率そのものの二乗誤差)
# 代表点
sample_ps = np.array([0.99, 0.90, 0.70, 0.50, 0.30, 0.10, 0.01])
sample_ce = -np.log(sample_ps)
sample_mse = (1 - sample_ps) ** 2
# -----------------------------
# 2) 同じAccuracyでも CE は違う、を確認するダミーデータ
# -----------------------------
# 真のラベル(6サンプルの2値分類)
y = np.array([1, 1, 1, 0, 0, 0])
# Model A: すべて正解だが自信は弱い
probs_A = np.array([0.60, 0.55, 0.65, 0.40, 0.45, 0.35])
# Model B: すべて正解で自信も強い
probs_B = np.array([0.95, 0.90, 0.85, 0.05, 0.10, 0.15])
def binary_ce(y, p, eps=1e-12):
p = np.clip(p, eps, 1 - eps)
return -np.mean(y * np.log(p) + (1 - y) * np.log(1 - p))
acc_A = np.mean((probs_A >= 0.5) == y)
acc_B = np.mean((probs_B >= 0.5) == y)
ce_A = binary_ce(y, probs_A)
ce_B = binary_ce(y, probs_B)
print("=== same accuracy, different CE ===")
print(f"Model A accuracy = {acc_A:.0%}, CE = {ce_A:.3f}")
print(f"Model B accuracy = {acc_B:.0%}, CE = {ce_B:.3f}")
# -----------------------------
# 3) 交差エントロピー = エントロピー + KL の確認
# -----------------------------
P = np.array([0.70, 0.20, 0.10]) # 真の分布
Q_good = np.array([0.65, 0.25, 0.10])
Q_bad = np.array([0.20, 0.30, 0.50])
def entropy(p, eps=1e-12):
p = np.clip(np.asarray(p, dtype=float), eps, 1.0)
p = p / p.sum()
return float(-np.sum(p * np.log(p)))
def kl_div(p, q, eps=1e-12):
p = np.clip(np.asarray(p, dtype=float), eps, 1.0)
q = np.clip(np.asarray(q, dtype=float), eps, 1.0)
p = p / p.sum()
q = q / q.sum()
return float(np.sum(p * np.log(p / q)))
def cross_entropy_dist(p, q, eps=1e-12):
p = np.clip(np.asarray(p, dtype=float), eps, 1.0)
q = np.clip(np.asarray(q, dtype=float), eps, 1.0)
p = p / p.sum()
q = q / q.sum()
return float(-np.sum(p * np.log(q)))
H_P = entropy(P)
KL_good = kl_div(P, Q_good)
KL_bad = kl_div(P, Q_bad)
CE_good = cross_entropy_dist(P, Q_good)
CE_bad = cross_entropy_dist(P, Q_bad)
print("\n=== CE = H + KL ===")
print(f"H(P) = {H_P:.3f}")
print(f"CE(P, Q_good) = {CE_good:.3f}")
print(f"H(P)+KL(P||Q_good)= {H_P + KL_good:.3f}")
print(f"CE(P, Q_bad) = {CE_bad:.3f}")
print(f"H(P)+KL(P||Q_bad) = {H_P + KL_bad:.3f}")
# -----------------------------
# 図1: 直感図(CE vs MSE、同じAccuracyでもCEは違う)
# -----------------------------
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
ax = axes[0]
ax.plot(p_true, cross_entropy, label="Cross entropy")
ax.plot(p_true, mse, label="MSE")
ax.scatter(sample_ps, sample_ce, s=25)
ax.set_xlabel("Predicted probability for the true class")
ax.set_ylabel("Loss")
ax.set_title("Cross entropy punishes confidently wrong predictions")
ax.set_ylim(0, 5)
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
x = np.arange(len(y))
ax.axhline(0.5, color="gray", linestyle="--", linewidth=1)
ax.plot(x, probs_A, marker="o", label=f"Model A (acc={acc_A:.0%}, CE={ce_A:.3f})")
ax.plot(x, probs_B, marker="o", label=f"Model B (acc={acc_B:.0%}, CE={ce_B:.3f})")
for i, yi in enumerate(y):
ax.text(i, -0.08, f"y={yi}", ha="center", va="top")
ax.set_ylim(-0.15, 1.02)
ax.set_xlabel("Sample index")
ax.set_ylabel("Predicted probability of class 1")
ax.set_title("Same accuracy, different cross entropy")
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("fig1_cross_entropy_intuition.png", dpi=200, bbox_inches="tight")
plt.show()
# -----------------------------
# 図2: CE = H + KL
# -----------------------------
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
ax = axes[0]
labels = ["class 1", "class 2", "class 3"]
x = np.arange(3)
w = 0.25
ax.bar(x - w, P, width=w, label="True P")
ax.bar(x, Q_good, width=w, label="Q_good")
ax.bar(x + w, Q_bad, width=w, label="Q_bad")
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.set_ylim(0, 0.8)
ax.set_title("True vs predicted distributions")
ax.legend()
ax = axes[1]
bars = ["Q_good", "Q_bad"]
Hs = [H_P, H_P]
KLs = [KL_good, KL_bad]
CEs = [CE_good, CE_bad]
ax.bar(bars, Hs, label="Entropy H(P)")
ax.bar(bars, KLs, bottom=Hs, label="Extra penalty = KL(P||Q)")
for i, (h, k, ce_val) in enumerate(zip(Hs, KLs, CEs)):
ax.text(i, h / 2, f"H={h:.3f}", ha="center", va="center", color="white")
ax.text(i, h + k / 2, f"KL={k:.3f}", ha="center", va="center")
ax.text(i, ce_val + 0.03, f"CE={ce_val:.3f}", ha="center")
ax.set_ylabel("nats")
ax.set_title("Cross entropy = entropy + KL divergence")
ax.legend()
plt.tight_layout()
plt.savefig("fig2_ce_equals_entropy_plus_kl.png", dpi=200, bbox_inches="tight")
plt.show()
print("\nSaved: fig1_cross_entropy_intuition.png, fig2_ce_equals_entropy_plus_kl.png")
実行すると、上記の二つの図と以下の出力が得られます。
=== same accuracy, different CE ===
Model A accuracy = 100%, CE = 0.513
Model B accuracy = 100%, CE = 0.106
=== CE = H + KL ===
H(P) = 0.802
CE(P, Q_good) = 0.809
H(P)+KL(P||Q_good)= 0.809
CE(P, Q_bad) = 1.437
H(P)+KL(P||Q_bad) = 1.437
そもそも交差エントロピーとは何か
まず、離散的な確率分布 $P=(p_1,\dots,p_K)$ と $Q=(q_1,\dots,q_K)$ に対して、交差エントロピーは
$$
H(P, Q) = - \sum_{i=1}^{K} p_i \log q_i
$$
で定義されます。
ここでのイメージはこうです。
- $P$ :本当の分布(真実)
- $Q$ :モデルが出した予測分布
つまり交差エントロピーは、
真実は $P$ なのに、モデルが $Q$ だと思っているときの“損”
と読むことができます。
分類でよく見る形は、もっとシンプル
分類タスクでは、正解ラベルが one-hot になっていることが多いです。
例えば3クラス分類で、正解が class 2 なら
$$
y = (0,1,0)
$$
です。
このとき交差エントロピーは
$$
-\sum_i y_i \log \hat{p}_i
$$
ですが、one-hot なので 1 が立っている成分だけが残ります。
つまり、
$$
\mathrm{CE} = -\log(\text{真のクラスに割り当てた確率})
$$
になります。
これがまず、かなり直感的です。
- 真のクラスに 0.99 を置けた → 損失はとても小さい
- 真のクラスに 0.50 しか置けない → 損失はそこそこ大きい
- 真のクラスに 0.01 しか置けない → 損失はかなり大きい
なぜ“誤差”として自然なのか その1
真のクラスにどれだけ確率を置けたかを、そのまま測っているから
交差エントロピーは one-hot ラベルなら
$$
-\log p_{\text{true}}
$$
です。
つまり、「正解クラスにどれだけ確率を置けたか」を、そのまま損失にしています。
例えば真のクラス確率 $p_{\text{true}}$ が次のとき、損失はこうなります。
| 真のクラスに置いた確率 | 交差エントロピー |
|---|---|
| 0.99 | 0.010 |
| 0.90 | 0.105 |
| 0.70 | 0.357 |
| 0.50 | 0.693 |
| 0.10 | 2.303 |
| 0.01 | 4.605 |
この表を見ると、交差エントロピーが
- 当たっているうえに自信がある予測をしっかり褒める
- 外しているうえに自信がある予測を強く罰する
ようになっているのが分かります。
なぜ“誤差”として自然なのか その2
「自信満々の誤答」を強く罰したいから
図1の左側では、真のラベルが y=1 のとき、予測確率 $p$ に対する損失を
- 交差エントロピー
- MSE
で比較しています。
図1: 直感図(CE vs MSE、同じAccuracyでもCEは違う)
交差エントロピーは
$$
-\log p
$$
なので、$p \to 0$ に近づくと急激に大きくなります。
これは直感的にも自然です。
なぜなら、モデルが「このクラスはほぼありえない」と言っていたのに、それが実際には正解だったなら、かなり強く反省してほしいからです。
一方で MSE は
$$
(1-p)^2
$$
なので、確かに外したら増えますが、交差エントロピーほどは強く罰しません。
分類で「確率」を出しているモデルに対しては、
ただの距離よりも、“どれだけありえないと言ってしまったか” を見る方が自然です。
なぜ“誤差”として自然なのか その3
Accuracyでは見えない“確率の質”が見えるから
図1の右側では、2つのモデルを比べています。
図1: 直感図(CE vs MSE、同じAccuracyでもCEは違う)
- Model A: 全部正解だが、自信は弱い
- Model B: 全部正解で、自信も強い
どちらも Accuracy は 100% です。
でも交差エントロピーは
- Model A:
CE = 0.513 - Model B:
CE = 0.106
となって、Model B の方が良いと判断します。
これはかなり自然です。
なぜなら、分類モデルは「当てる」だけでなく、「どれくらい確からしいか」を出しているからです。
Accuracy は最終的な正誤しか見ません。
でも交差エントロピーは、予測確率そのものの良し悪しを見ます。
なぜ“誤差”として自然なのか その4
交差エントロピーは「エントロピー + KLダイバージェンス」だから
ここで、前回のKLダイバージェンスの記事ともつながります。
交差エントロピーは
$$
H(P,Q) = H(P) + D_{\mathrm{KL}}(P|Q)
$$
と分解できます。
- $H(P)$ :真の分布そのものが持つ不確かさ
- $D_{\mathrm{KL}}(P|Q)$ :真の分布 $P$ を、予測分布 $Q$ で近似したときのズレ
つまり交差エントロピーは、
「真実そのものの難しさ」 + 「モデルが余計に払っている損」
です。
図2の右側では、これを積み上げ棒グラフで見せています。
図2: CE = H + KL
-
Q_goodは真の分布Pに近い
→ KL が小さい
→ CE も小さい -
Q_badはPからズレている
→ KL が大きい
→ CE も大きい
ここがとても大事です。
学習の観点で見ると
モデルを学習するとき、真の分布 $P$ は固定です。
つまり $H(P)$ は定数です。
すると、交差エントロピーを最小化することは
$$
D_{\mathrm{KL}}(P|Q)
$$
を最小化することと同じになります。
つまり交差エントロピーは、
「予測分布を真の分布へ近づける」 という目的に、かなり自然に対応した誤差なのです。
尤度から見ても自然
交差エントロピー = 負の対数尤度
分類でモデルが出す確率を使うと、交差エントロピーは 負の対数尤度(negative log-likelihood) と一致します。
例えば2値分類で、各サンプル $i$ の予測確率を $p_i$、正解ラベルを $y_i \in {0,1}$ とすると、尤度は
$$
L = \prod_i p_i^{y_i}(1-p_i)^{1-y_i}
$$
です。
両辺の対数を取ってマイナスをつけ、平均すると
$$
-\frac{1}{N}\log L =
-\frac{1}{N}\sum_i \left(
y_i \log p_i + (1-y_i)\log(1-p_i)
\right)
$$
となります。これはそのまま、2値分類の交差エントロピーです。
つまり交差エントロピーを最小化することは、
「このデータが観測されやすいように、モデルの確率を調整する」
ことと一致します。
これもまた、「分類で使う誤差」としてかなり自然です。
MSEはダメなのか?
ダメとまでは言いません。
ただ、クラス確率を出す分類問題では、交差エントロピーの方が自然なことが多いです。
理由を一言で言うと、
- MSE:値のズレを見る
- 交差エントロピー:確率分布としてのズレを見る
からです。
特に分類では、「0か1か」だけではなく、その予測確率にどれだけ意味があるかが重要になります。
その意味で、交差エントロピーは分類と相性が良いです。
実務でどう読むと迷いにくいか
分類で Softmax や Sigmoid を使っているなら、交差エントロピーは
- 正解クラスに十分な確率を置けているか
- 自信満々で外していないか
- 予測分布が真の分布に近づいているか
を見る損失だと理解しておくと、かなり扱いやすくなります。
ざっくり使い分け
-
回帰
→ MSE / MAE など -
分類(確率を出す)
→ 交差エントロピー -
クラス不均衡が強い分類
→ 重み付き交差エントロピー、Focal Loss なども検討
チェックリスト
-
one-hotラベルのとき、交差エントロピーが
-log(真のクラス確率)になると説明できる - 交差エントロピーが「自信満々の誤答」を強く罰する理由を説明できる
- Accuracy が同じでも CE が違うことを説明できる
-
CE = H + KLの式の意味を説明できる - 交差エントロピー最小化が「真の分布に近づけること」とつながると理解している
- 負の対数尤度と交差エントロピーの関係を説明できる
次にやると理解が深まること
このあと Colab で次の3つを試すと、理解がさらに深まります。
-
Model A と Model B の一部をわざと誤答にする
→ 自信満々の誤答がどれだけ CE を悪化させるかがよく分かります。 -
Q_goodとQ_badを自分で変える
→CE = H + KLの見え方がさらに腹落ちします。 -
PyTorch の
CrossEntropyLossを触る
→ 現実のモデル学習で、この話がどう使われるかとつながります。
よくある落とし穴
1. Accuracyが高ければ十分だと思ってしまう
Accuracy は最終的な正誤しか見ません。
確率の質を見たいなら、交差エントロピーのような損失が必要です。
2. 交差エントロピーが低ければ、しきい値運用まで自動で決まると思ってしまう
交差エントロピーは確率分布の学習には向いていますが、実際の意思決定のしきい値までは決めてくれません。
しきい値設計は別の話です。
3. log(0) をそのまま計算してしまう
理論的には、真のクラスに 0 を割り当てると損失は無限大です。
実装では数値安定性のために clip や専用関数を使うのが普通です。
4. 交差エントロピーが低い = 完全に校正された確率、だと思ってしまう
交差エントロピーは良い損失ですが、確率の校正(calibration)とは別の軸です。
「0.9と出たら本当に90%当たるのか」は、また別途見る価値があります。
まとめ
交差エントロピーが“誤差”として自然なのは、主に次の4つの理由です。
- 真のクラスに置いた確率を、そのまま損失にしている
- 自信満々の誤答を強く罰できる
- Accuracyでは見えない確率の質を見られる
CE = H + KLなので、真の分布に近づける目的と自然につながる- 負の対数尤度と一致し、確率モデルの学習としても自然
分類モデルが確率を出す以上、「当たったか外れたか」だけでは足りません。
どれくらい確からしく当てたかを見るために、交差エントロピーはかなり自然な選択です。