はじめに:論文は査読するのに、コードは放置していないか
私は大学教員として、研究の実験・データ解析、授業資料の作成、学生指導のために、日々コードを書いています。
一方で「コードレビュー」と聞くと、どうしても“企業のソフトウェア開発”の文化で、大学の現場には縁遠いものに感じていました。
でも、ある時ふと思ったのです。
研究者は、論文は査読するのに、解析コードはほぼ無査読のまま「成果」に直結させていないか?
査読は「攻撃」ではなく、成果物の信頼性を上げ、読み手を増やすためのプロセスです。
コードレビューも同じで、研究コード/教育コードを“誰かが再利用できる成果物”に育てるための手段だと捉えると、大学教員こそ恩恵が大きいと感じました。
本稿では、コードレビュー経験がほぼない大学教員が、
- 研究(再現性・引き継ぎ・共同研究)
- 教育(教材品質・学生の成長・評価の公平性)
- 実務(時間がない、レビュー文化がない、心理的ハードルが高い)
という制約の中で、最小コストでコードレビューを始めるための分析と考察をまとめます。
後半では、Google Colabで再現できる「レビュー前後で何が改善するか」の小さな実演も用意しました。
対象読者
- 研究・教育のためにコードを書く大学教員(専任/非常勤問わず)
- 研究室で学生に解析コードを書かせている指導教員
- 「コードは動けばよい」から一歩進めたいが、業務が忙しくて体系立てる余裕がない人
- チーム開発はしていないが、共同研究・引き継ぎ・再現性に困った経験がある人
結論だけ先に:大学教員にとってのコードレビューの価値
コードレビューを“プロダクト品質”の話だけに閉じると、大学の現場には馴染みにくいです。
しかし、大学教員の仕事に翻訳すると、レビューは次の効果を持ちます。
- 研究の再現性を上げる(=研究の信用を守る)
- 引き継ぎを楽にする(=研究室運営のコストを下げる)
- 教育の質を上げる(=教材と指導の再利用性を上げる)
- 学生の成長を加速する(=「読む力」を育てる)
- 自分の未来の時間を守る(=半年後の自分が助かる)
つまり、コードレビューは「時間を取られる儀式」ではなく、時間を取り戻す仕組みになり得ます。
なぜ大学のコードはレビューされにくいのか(自戒込み)
大学の現場には、レビューが根付かない合理的な理由があります。
-
コードが“成果物”ではなく“手段”になりがち
研究は仮説検証が主で、コードは実験装置。短期的には「動けば勝ち」になりやすい。 -
時間が足りない
授業、会議、書類、学生対応、研究費…。レビューの時間は自然には生まれない。 -
心理的安全性が低い
教員—学生、先輩—後輩の非対称性があり、「指摘=人格評価」に感じやすい。 -
評価軸が曖昧
「美しいコード」の定義が共有されていないと、レビューが個人の好みに寄る。 -
レビューの“型”がない
何を見ればよいか分からない → 書けない → 続かない、のループ。
だからこそ、大学でレビューを始めるなら「工学的に完璧」ではなく、現場の制約に合わせた最小構成が必要です。
大学教員がレビューで得をする場面(研究・教育・運営)
1) 再現性:半年後の自分が再現できない問題
- 乱数シードが固定されていない
- 前処理がNotebookの途中に散らばっている
- データパスがローカル依存(
C:\Users\...) - 依存ライブラリのバージョンが残っていない
こうした“研究あるある”は、レビュー観点に入れるだけでかなり減ります。
再現性は科学の根幹なので、レビューは研究倫理にも近い話です。
2) 引き継ぎ:卒論→修論→博論、あるいは共同研究の「暗黙知」問題
- 解析コードが「本人しか分からない」
- ファイル命名やディレクトリ構成が毎回違う
- 実験条件がコード内の“魔法の数値”に埋もれている
レビューは、暗黙知を“テキスト化”する作業でもあります。
「この関数名だと意図が伝わりにくい」「この変数の単位が不明」などは、未来の共同研究者のための査読です。
3) 教育:学生は「書く」より先に「読む」ことで伸びる
学生にとって、コードレビューは他人の思考に触れる授業になります。
教員が毎回フル解説しなくても、PR上のコメントが学習ログとして残り、次年度以降の教材にもなります。
4) リスク管理:個人情報・研究データ・不正確な解析の事故防止
大学のコードには、学生情報・実験協力者情報・未公開データが混ざりやすいです。
レビュー観点に「ログに個人情報を出していないか」「共有してよいデータか」を入れるだけで、事故確率を下げられます。
最小構成で始める:大学版「ミニマム・コードレビュー」設計
ここからは、忙しい大学教員向けにやることを削った提案です。
ポイントは3つだけ
-
レビュー対象を小さくする(PRは小さく)
1PR = 10〜30分で読める量を上限にする。
(大きいPRは、誰も読めません。教員でも。学生でも。AIでも。) -
観点を固定する(チェックリスト)
“毎回違うレビュー”をやめる。
まずは「再現性」「安全性」「読みやすさ」だけでも十分。 -
人格から切り離す(コメントの型)
「あなた」ではなく「コード」に向けて書く。
目的は勝ち負けではなく、成果物の信用を上げること。
研究・教育向けレビュー観点チェックリスト(コピペ可)
最初はこれだけで回せます。
レビューコメントのテンプレも併記します。
| カテゴリ | チェック項目(例) | コメント例(攻撃にならない書き方) |
|---|---|---|
| 再現性 | 乱数シード、環境(依存パッケージ)、入出力が明示されているか | 「再現のため、乱数シードと依存関係(requirements等)を残したいです」 |
| データ | パスが固定/ローカル依存になっていないか、データの前処理が追えるか | 「このパスは環境依存になりそうなので、相対パスか設定ファイル化できると助かります」 |
| 正しさ | 境界値(欠損/外れ値/空配列)で壊れないか | 「欠損が多いときの挙動を確認したいので、空ケースの扱いを明示できますか」 |
| 可読性 | 関数名・変数名が意図を表しているか、単位が分かるか | 「x が何の量か(単位含めて)分かりにくいので名前/コメントで補足したいです」 |
| 保守性 | 1関数が長すぎないか、責務が混ざっていないか | 「前処理と集計が同じ関数にあるので、分けると追いやすくなります」 |
| 教育用途 | 学生が読んで理解できる導線(docstring、図、例)があるか | 「教材として使うなら、入力例と出力例があると学びやすいです」 |
| 安全性/倫理 | 個人情報・秘匿情報がログ/コミットに混ざっていないか | 「共有前提なので、ログに出る情報を一度確認したいです」 |
重要:チェックリストは“すべて満たす”ためではなく、会話の焦点を固定して疲弊を防ぐために使います。
レビューコメントは「査読」っぽく書くと荒れない
研究者は査読で、だいたい次の順で書きます。
- 何が良いか(貢献の確認)
- 目的に対して何が課題か(論点の特定)
- どう直すと良いか(具体案)
- 優先順位(必須/任意)
コードレビューも同じが効きます。
NG例(気持ちは分かるが、相手が萎縮する)
- 「意味不明」
- 「なんでこんな書き方?」
- 「これだとダメ」
代替例(同じ指摘でも、知的に見える)
- 「意図は理解しました。再現性の観点で、ここは設定化すると安全です」
- 「将来の引き継ぎを考えると、ここは関数分割したいです(理由:変更点が局所化するため)」
- 「私の理解が正しければ〜ですが、もし違う意図なら教えてください」
大学の現場では権力差があるので、特に「理解確認フレーズ」を入れると安全です。
AIコードレビューはどう使う?(教員の時間を守りつつ、責任も守る)
AIコードレビュー(例:CodeRabbitのようなサービス)は、大学の現場では次の使い方が合います。
AIに任せやすい(定型・反復)領域
- 命名の一貫性、未使用変数、インデント、import整理
- ありがちなバグ(Noneチェック不足、境界条件)
- ドキュメント不足(関数の説明、引数の意味)
- 「この関数、責務が多くない?」のような構造指摘
人間が責任を持つべき領域(AIは参考まで)
- 研究の妥当性(統計手法、実験計画、前提条件)
- データ倫理・守秘(共有してよい情報か)
- 研究目的に照らした「正しさ」(仕様がない世界の仕様)
- 教育的配慮(学習段階に応じたコードか)
AIはレビューを“代替”するというより、レビューの前処理(下ごしらえ)を自動化してくれる存在、と捉えると健全です。
最後に責任を持つのは人間(=著者・指導者)です。
※学生情報や未公開データが混ざるリポジトリでは、AI連携の可否や設定は必ず慎重に(学内規程・契約・研究倫理に従ってください)。
ミニ実演:レビューで何が変わるか
ここでは「研究室にありがちな1ファイル解析コード」を題材に、レビュー後に
- 複雑度(読みにくさの指標)
- Lint(静的解析の指摘)
がどう変わるかを数値と図で示します。
まずは “レビュー前” の例(before.py)
# before.py(あえて「研究室あるある」に寄せた例)
import json
import os # noqa: F401(未使用にしてlintを出す)
from math import sqrt # noqa: F401(未使用にしてlintを出す)
def analyze_scores(rows):
"""
rows: [{"id": str, "score": number or None}, ...]
"""
result = {"count": 0, "mean": None, "std": None, "hist": {"A": 0, "B": 0, "C": 0, "D": 0}}
xs = []
for r in rows:
if "score" not in r:
continue
x = r["score"]
if x is None:
continue
# 0〜100に丸める(ただし理由の説明なし)
if x < 0:
x = 0
if x > 100:
x = 100
# 研究ノート由来の謎補正(条件分岐が増える)
if x >= 90:
x = x * 1.10
elif x >= 70:
x = x
elif x >= 60:
x = x - 5
else:
x = x - 10
xs.append(x)
# ヒストグラムも同じループで更新(責務が混ざる)
if x >= 90:
result["hist"]["A"] += 1
elif x >= 80:
result["hist"]["B"] += 1
elif x >= 70:
result["hist"]["C"] += 1
else:
result["hist"]["D"] += 1
result["count"] = len(xs)
if len(xs) > 0:
m = sum(xs) / len(xs)
result["mean"] = m
v = 0
for x in xs:
v += (x - m) * (x - m)
result["std"] = (v / len(xs)) ** 0.5
with open("result.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("done") # ログは便利だが、用途が曖昧なままだとノイズになる
return result
次に “レビュー後” の例(after.py)
# after.py(レビューで「責務分割・説明・境界条件」を意識した例)
from __future__ import annotations
import json
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass(frozen=True)
class ScoreRule:
"""スコア補正ルール。研究ノートの前提をコードに残す。"""
clamp_min: float = 0.0
clamp_max: float = 100.0
def adjust(self, raw: float) -> float:
"""研究上の補正(例)。条件の意味をコメントで説明できる形にしておく。"""
x = min(max(raw, self.clamp_min), self.clamp_max)
# 例:90点以上は採点厳密性の補正を入れる(※仮の例)
if x >= 90:
return x * 1.10
if x >= 70:
return x
if x >= 60:
return x - 5
return x - 10
def safe_scores(rows: Iterable[dict], rule: ScoreRule) -> list[float]:
"""欠損や不正値を除去し、補正後スコアを返す。"""
xs: list[float] = []
for r in rows:
raw = r.get("score")
if raw is None:
continue
xs.append(rule.adjust(float(raw)))
return xs
def mean(xs: list[float]) -> Optional[float]:
return (sum(xs) / len(xs)) if xs else None
def std(xs: list[float], m: Optional[float]) -> Optional[float]:
if not xs or m is None:
return None
v = sum((x - m) ** 2 for x in xs) / len(xs)
return v ** 0.5
def grade_hist(xs: list[float]) -> dict[str, int]:
"""A/B/C/D の簡易ヒストグラム。基準は関数に閉じ込める。"""
hist = {"A": 0, "B": 0, "C": 0, "D": 0}
for x in xs:
if x >= 90:
hist["A"] += 1
elif x >= 80:
hist["B"] += 1
elif x >= 70:
hist["C"] += 1
else:
hist["D"] += 1
return hist
def analyze_scores(rows: Iterable[dict], *, rule: ScoreRule = ScoreRule()) -> dict:
xs = safe_scores(rows, rule)
m = mean(xs)
s = std(xs, m)
return {
"count": len(xs),
"mean": m,
"std": s,
"hist": grade_hist(xs),
}
def save_json(obj: dict, path: str = "result.json") -> None:
with open(path, "w", encoding="utf-8") as f:
json.dump(obj, f, ensure_ascii=False, indent=2)
複雑度とLint指摘数の比較
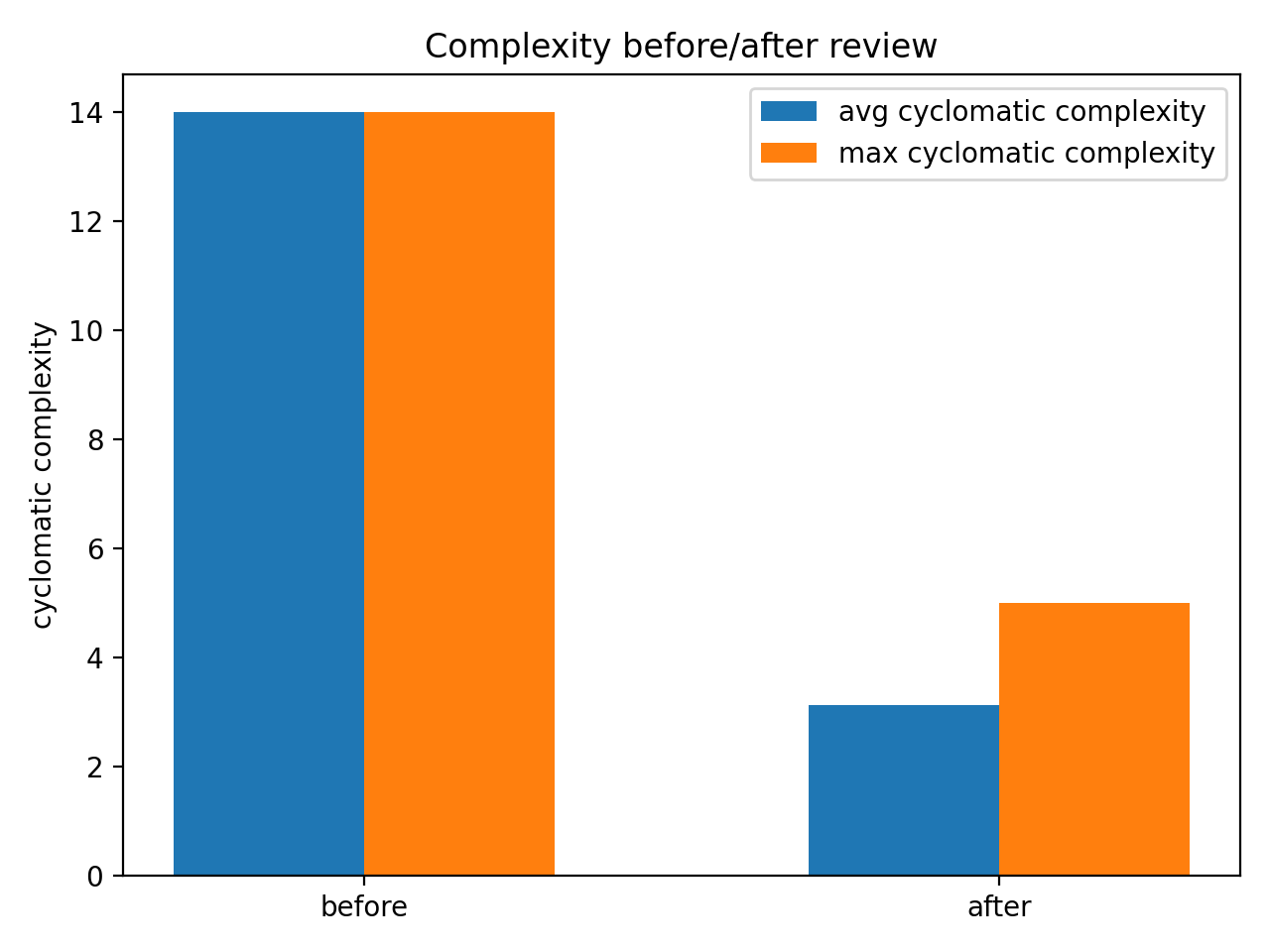

- 今回、Ruffの指摘件数は0→0だった。つまり機械的な規約違反ではなく、構造・説明可能性の改善が主目的だった
- 研究コードでは、Lintよりも“他人が読める/再現できる”が支配的に重要
この実演から分かること(大学の現場に引きつけて解釈)
この例は小さいですが、現場では次の形で効きます。
-
責務分割:前処理・補正・集計・保存が分かれると、修正が局所化する
→ 学生が「ここだけ変えれば良い」と分かる -
意図の固定(ルール化):研究ノートの前提を
ScoreRuleのように閉じ込める
→ 「なぜこの補正?」がコードに残る(将来の査読者=自分を助ける) -
境界条件:欠損・空配列でも壊れにくい
→ 実験データは汚いのが普通なので、研究では特に重要
レビューで狙うのは「美しさ」ではなく、再現性・引き継ぎ・教育効果です。
研究室・授業で回す運用案(無理しない版)
研究室運用(学生がいる前提)
-
週1回、30分だけ“PR読書会”(雑談込み)
- 1人1PR(小さいやつ)を持ち寄る
- 指摘はチェックリストの範囲だけ
-
教員が全部レビューしない
- 学生同士で一次レビュー → 教員は最終確認(再現性・倫理だけ)
- 教員の時間がボトルネックにならない設計が大切
-
レビューは評価ではなく改善
- 成績や査定と結びつけない(萎縮すると終わる)
授業運用(提出物の質を上げたい場合)
- 提出前に「セルフレビュー」チェック(自己点検)を必須化
- ルーブリックに「再現性(実行手順が書けている)」を入れる
- 教員コメントを“PRコメント”形式で残す(翌年の教材資産になる)
これから始める人向け:4週間で導入するロードマップ
-
1週目:セルフレビュー
- 自分のリポジトリで「ブランチ→PR→マージ」を1回だけ回す
- PR本文テンプレを作る(下に例あり)
-
2週目:自動整形&Lintを入れる
- ruff/formatterを入れて“揉めない領域”を機械化
-
3週目:学生 or 同僚とペアレビュー
- 1回だけでいい。「レビューってこの程度で良い」を体験する
-
4週目:AIレビューの併用(任意)
- 人間レビューの前にAIで下ごしらえ
- 機密情報の扱いは必ず慎重に
まとめ:コードレビューは「研究の信用」と「教育の再利用性」を上げる
大学教員がコードレビューを導入する意義は、プロダクト開発と同じではありません。
- 研究:再現性と信頼性を守る
- 教育:読む力を育て、指導ログを資産化する
- 運営:引き継ぎコストと“未来の自分の苦しみ”を減らす
そして、レビューは完璧主義のためではなく、現場の制約下で継続するための型です。
まずは「小さなPR」と「固定した観点」から始めるのが、大学の現場には一番効くと思います。
付録A:研究室向け PR本文テンプレ(コピペ可)
### 目的
- 例:〇〇の解析を再現可能にする / 前処理を関数化する / 教材化する
### 変更点(3行で)
-
-
-
### 再現手順(最短)
- `python ...` または `notebook` の実行順
- 依存関係(必要なら)
### レビューしてほしい観点
- [ ] 再現性(パス/乱数/依存)
- [ ] 境界条件(欠損/空/外れ値)
- [ ] 命名・単位が伝わるか
- [ ] 倫理・秘匿(共有して良い情報のみか)
### 補足
- 背景、研究ノートへのリンク(あるなら)
付録B:最小のレビュー運用ルール(“揉めない”ための宣言)
- 指摘は「人格」ではなく「コード」に向ける
- “必須” と “提案” を分ける(NitはNitと書く)
- レビューは期限を決める(例:48時間以内に一次反応)
- PRは小さく(読めないPRはレビュー不能)
- 自動化できることは自動化(フォーマット論争を終わらせる)
付録C:もしPythonなら(任意)ruff導入の最小例
# pyproject.toml(最小例)
[tool.ruff]
line-length = 100
target-version = "py311"
[tool.ruff.lint]
select = ["E", "F", "I", "B", "UP"]
※研究室の状況に応じて、ルールは徐々に増やすのがおすすめです(最初から厳しくすると続きません)。