初めに
SIGNATEに初めて挑戦される方向けに、【練習問題】天秤のバランス分類を用いてファイルの読み込みの仕方から提出方法までを解説して行きます。自分も最近Intermediateに昇格したばかりの初心者なのですが、学習を始める方の手助けになればと思います。
余談ですが、天秤のバランス分類は初めて挑んだ問題なので少し思い入れがあります笑
利用規約の確認

練習問題であれば情報交換が可能ということで記事を書いていますが、規約に違反する場合は削除します。
天秤のバランス分類問題の確認
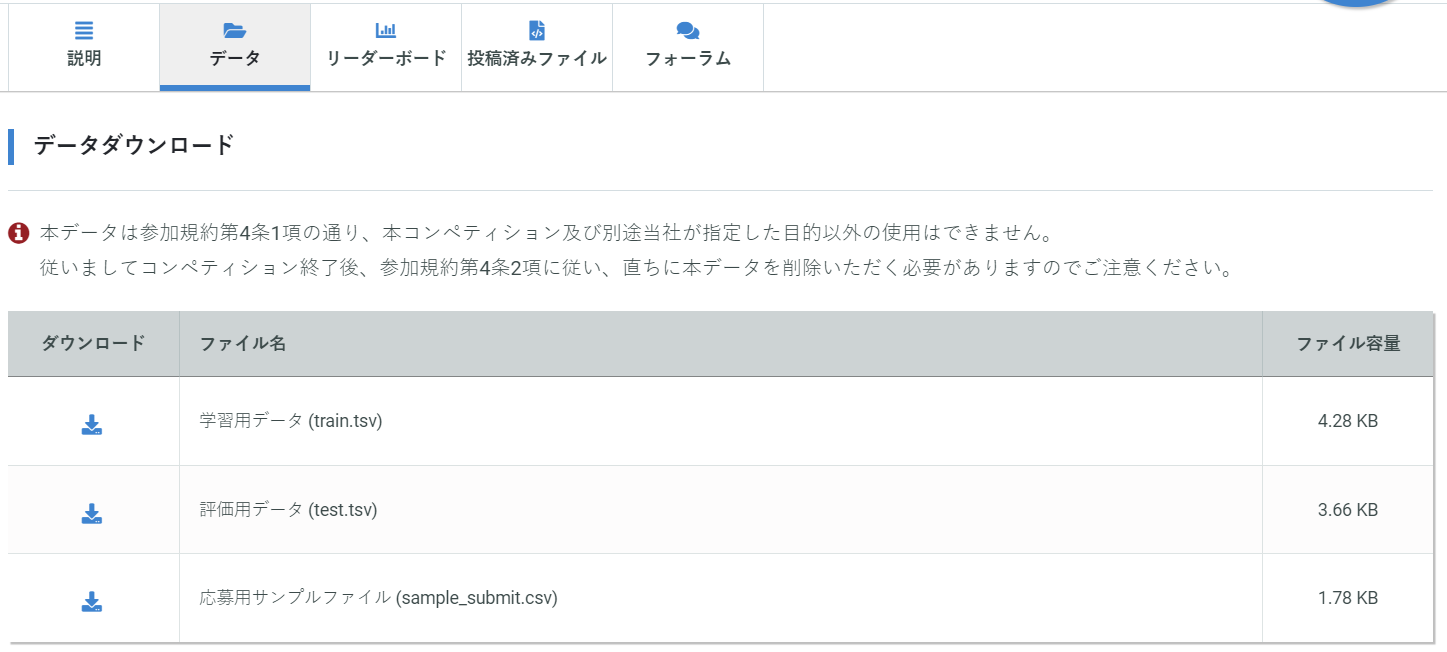
データは公式サイトからダウンロードしてください。
SIGNATE公式サイト
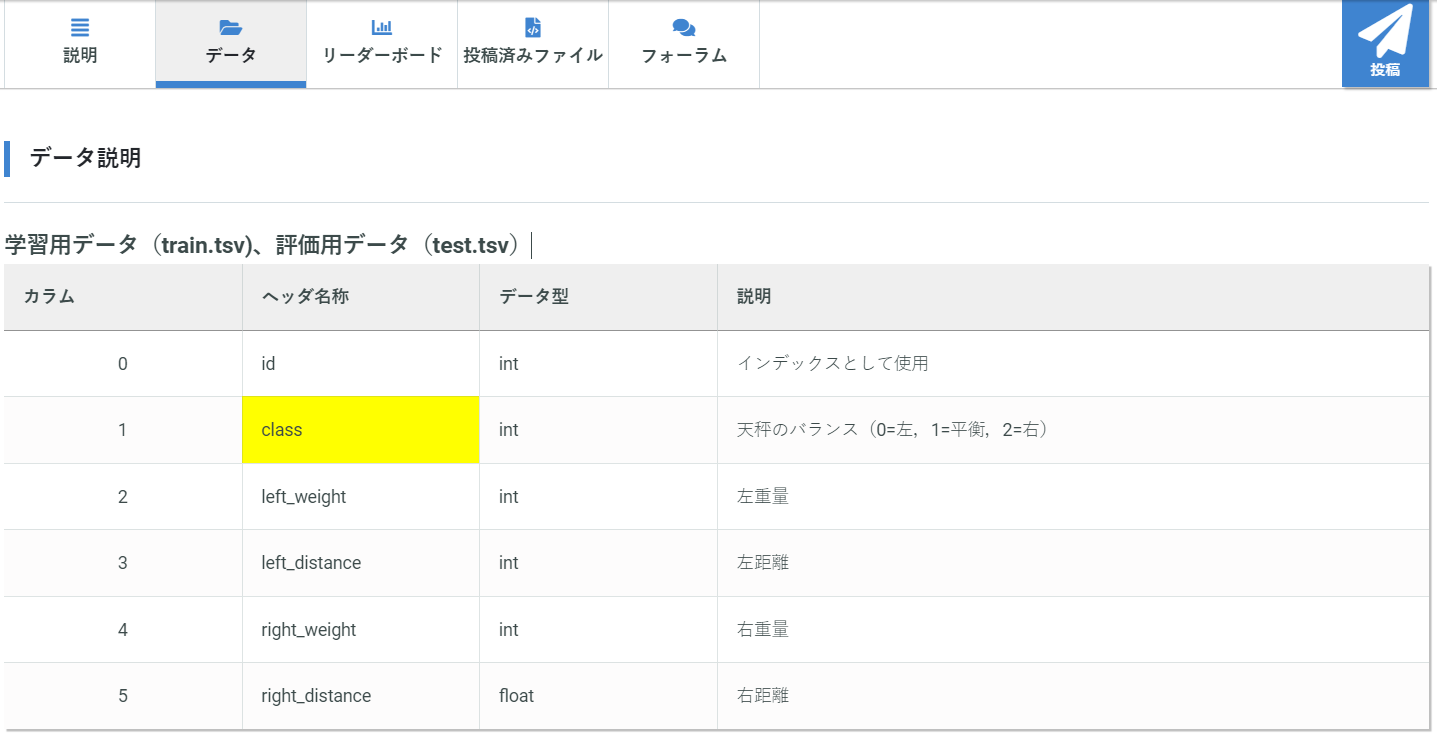
データの中身はこのようになっており、学習用データと評価用データにわかれています。
この学習用データを使って、黄色い部分のclass(天秤の傾き)を予想するモデルを構築するのが今回の練習問題です。
モジュールをインポート
- Pandasは、データを簡単に取り扱う為のデータ操作ツール
- sklearn.linear_model.LinearRegressionは線形回帰モデルです
import pandas as pd
from sklearn.linear_model import LinearRegression as LR
今回は線形回帰モデル使っていきます。
線形回帰モデルは特徴量と目標変数との間の線形な関係を仮定し、最適な回帰係数を求めることで、予測モデルを構築します。特徴量と目標変数についてはデータ確認の所で説明していますので、今はわからなくて大丈夫です。
ファイルの読み込み
train = pd.read_csv("train.tsv",sep='\t')
test = pd.read_csv("test.tsv",sep='\t')
sample = pd.read_csv("sample_submit.csv", header=None)
補足 どうしてsep='\t'を指定するのか
sepパラメータは、フィールド(列)を区切るための文字列を指定します。
tsvデータはタブ区切りのデータなのでsep='\t'を指定することでデータが読み込めます。
pd.read_csv関数は、CSVファイル(カンマ区切りのテキストファイル)を読み込むための関数です。
デフォルトでは、sep=','が設定されており、カンマがフィールドの区切り文字として使用されます。
CSVデータの読み込みは下の記事に書いています。
pandasのデータの読み込みからデータの抽出まで
簡単なデータ確認
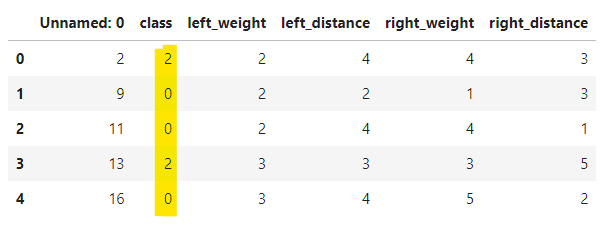
train.head()
test.head()
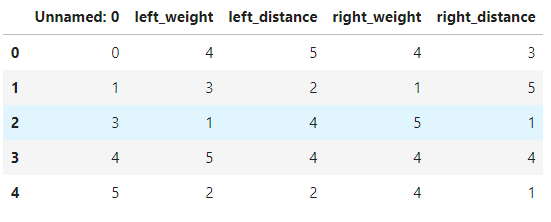
- Unnamed: 0はデータidのことなので気にしなくて大丈夫です。
- classは天秤のバランス(0=左,1=平衡,2=右)のことです。
trainデータにはclassがありますが、testデータには入ってないことがわかります。
この場合、classは目的変数といいます。
他のleft_weightなどの説明変数(特徴量)から、目的変数を予想していくモデルを構築していきます。
補足
例えば、住宅価格を予測する場合
説明変数:部屋の広さ、地理的な位置、築年数など
目的変数:住宅価格が目的変数になります
特徴量の作成
天秤の傾きはざっくり言うと
おもりの重さ×支点からおもりを吊るした点までの距離の大小で決まります
【小学4年生の理科】てんびんの問題を計算してみよう!
train["left_point"] = train["left_weight"]*train["left_distance"]
train["right_point"] = train["right_weight"]*train["right_distance"]
test["left_point"] = test["left_weight"]*test["left_distance"]
test["right_point"] = test["right_weight"]*test["right_distance"]
重さ×距離を新しくleft_point・right_pointとして作成しました。
train["result_point"] = train.apply(lambda row: 0 if row["left_point"] > row["right_point"] else (1 if row["left_point"] == row["right_point"] else 2), axis=1)
test["result_point"] = test.apply(lambda row: 0 if row["left_point"] > row["right_point"] else (1 if row["left_point"] == row["right_point"] else 2), axis=1)
このコードでは
left_point > right_point なら 0
left_point == right_point なら 1
それ以外(left_point < right_point) なら 2
にしています。
train.head()
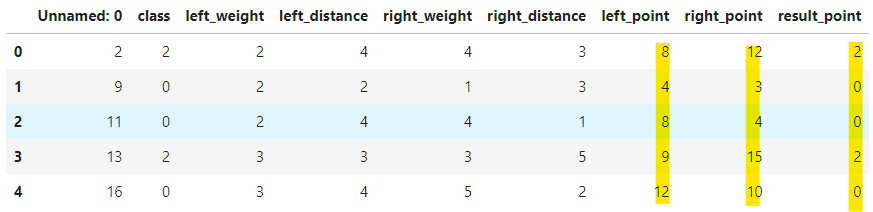
新しく特徴量を作成することができました。
説明変数の取り出し
今回は説明変数"result_point"を代入しています。
trainX = train["result_point"]
testX = test["result_point"]
trainX = trainX.values.reshape(-1,1)
testX = testX.values.reshape(-1,1)
.values.reshape(-1,1)の説明
線形回帰モデルは2次元の形式データを期待しているので1次元のデータを2次元の形状に変換する操作です。
trainXは1つの説明変数を持つため、単回帰の一般的な形式になります。単回帰では、1つの説明変数と1つの目的変数の関係をモデル化するため、1列の特徴量を持つ2次元の配列が使用されます。
したがって、trainX = train["result_point"].values.reshape(-1,1)は、単回帰(線形回帰の特殊な場合)における特徴量の形式を表しています。
目的変数の取り出し
目的変数classをyに代入しています。
y = train["class"]
線形回帰(単回帰)
model1 = LR()で線形回帰モデルのインスタンスを作成することができます。このインスタンスを使用して、モデルの学習や予測を行うことができます。
model1 = LR()
fit関数を使って単回帰モデルを作成します。
.fit(説明変数,目的変数)
model1.fit(trainX,y)
predict関数を使って予想します。
pred = model1.predict(testX)
pred

学習済みの線形回帰モデル(model1)を使用して、テストデータセット(testX)に対する予測を行う操作です。predには予測結果が入っています。

今回の予想結果の提出にはint型、0,1,2の整数にする必要があります。
単回帰モデルで予想した為、predには整数値で入ってません。それを整数に変換していきます。
import math
pred_clean = []
for item in pred:
if item <= 0:
item = math.ceil(item)
elif item < 1.5:
item = math.floor(item)
elif 1.5 <= item < 2:
item = math.ceil(item)
else:
item = math.floor(item)
pred_clean.append(item)
print(pred_clean)
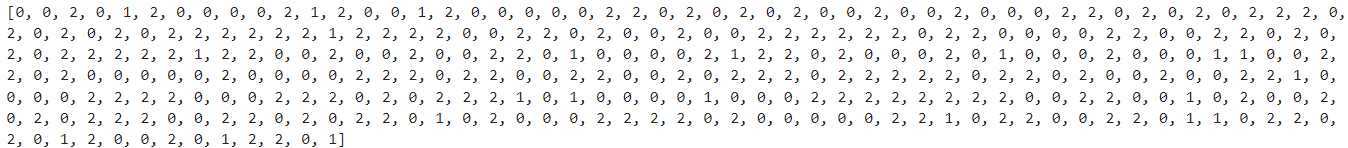
整数値に変換することができました。

この処理は分類問題を回帰モデルで行ったため必要でしたが、決定木などの分類モデルを使用すると指定した分類の仕方で結果が出る為不要です。
予測結果の提出
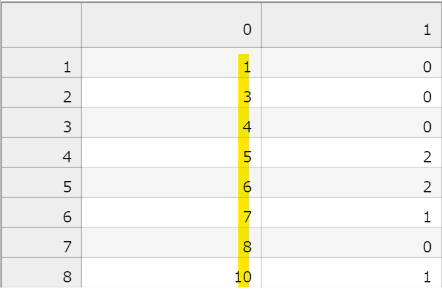
これはsampleファイルの中身です。
これはtestファイルの中身です。
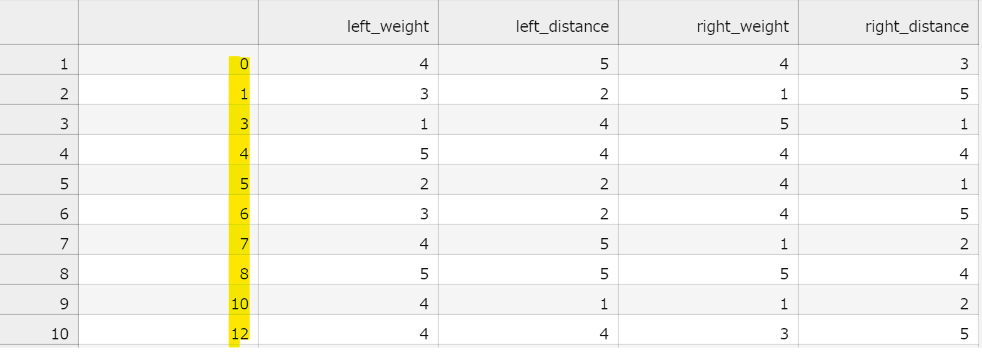
黄色いマーカーの場所を見るとsampleファイルとtestファイルの中身が同じことが分かります。
この黄色いマーカーを引いた場所はidです。sampleファイルはidと予測結果でできています。
pred = model1.predict(testX)で予測した結果をsampleファイルに入れて提出します。
sample[0]がidでsample[1]が予測結果の入れる場所です。idはそのままで予測結果を代入します。
sample[1] = pred_clean
sample.head()
※pred_cleanはpredを整数に変換した後の変数です。
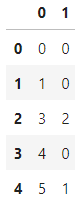
代入することができました。
次は結果をcsvデータに保存していきます。
sample.to_csv("submit.csv",index=None,header=None)
index=None,header=Noneを指定してindexとheaderを無しで保存します。
投稿を押してsubmit.csvを提出します。
提出が終わり少しすると評価が返ってきます。
参考
ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門
データサイエンスのための実践Pandas
pandasのデータの読み込みからデータの抽出まで
SIGNATE公式サイト
ChatGPTへの質問
もっと詳しく知りたい方は
UdemyにSIGNATEが出している【ゼロから始めるデータ分析】とSIGNATEの公式サイトにあるLearning問題がわかりやすく入門におすすめです。Udemyは頻繁にセールをやっているのでタイミングを見るとお得に買えると思います。宣伝みたいですが回し者ではないです笑
終わりに
今回はSIGNATEの【練習問題】天秤のバランス分類を用いてファイルの読み込みの仕方から提出方法までをご紹介しました。
次回は統計検定2級の勉強を整理してpythonと絡めながらご紹介しようと思います。