初めに
- pandasを初めて触る方向けに、基本的なデータの読み込み方から、必要なデータの抽出方法までを公開データを用いて解説して行きます。なので、データの準備は不要です。自分もデータ分析を始めたばかりで結構躓いたので、これから勉強を始める方の助けになれると嬉しく思います。
モジュールをインポート
- Pandasは、データを簡単に取り扱う為のデータ操作ツール
- Plotly Expressは、いくつかの公開データセットにアクセスするための便利な関数を提供
import pandas as pd
import plotly.express as px
ファイルの読み込み
- 今回はアイリスの花の公開データ読み込みます
- px.data.iris()でアイリスデータセットの公開データを読み込めます
df = px.data.iris()
- 補足:通常のcsvファイル読み込む方法。今回は公開データなので使わないです。pd.read_csvは、pandasライブラリを使用してCSVファイルを読み込むための関数です。
file_path = 'ファイルパス.csv'
df = pd.read_csv(file_path)
中身データ
- 'sepal_length': がく片の長さ 'sepal_width': がく片の幅 'petal_length': 花びらの長さ
- 'petal_width': 花びらの幅 'species': アヤメの種類 'species_id': アヤメの種類を表すID
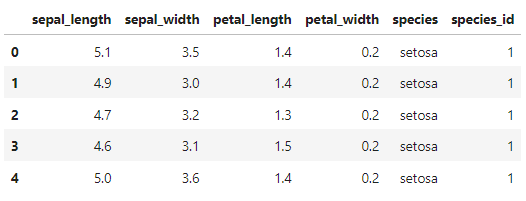
# .head()関数は、pandasデータフレームの先頭の行を表示するための関数。デフォルトでは、先頭から5行を表示。
df.head()
# データフレームの行数と列数を返す
df.shape
#結果
(150, 6)
150行と6列のカラムが入っています。つまり、データ数が150でヘッダーが6列あるデータということです。
カラム名を取得
# カラム(列)のラベルを取得
df.columns
カラム名を取得できます。
結果
Index(['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species',
'species_id'],
dtype='object')
次はデータの指定方法です。
df['カラム名']で指定できます
df['sepal_length']
0 5.1
1 4.9
2 4.7
3 4.6
4 5.0
...
145 6.7
146 6.3
147 6.5
148 6.2
149 5.9
Name: sepal_length, Length: 150, dtype: float64
複数のデータを指定
複数のデータの場合は[]を増やして、df[['カラム名', 'カラム名']]です。データ数を増やす場合は,を増やして書いていけば大丈夫です。
df[['sepal_length', 'sepal_width']]
結果

条件によるデータ抽出の仕方
df[df['カラム名'] 条件]
df[df['petal_length'] == 1.4]
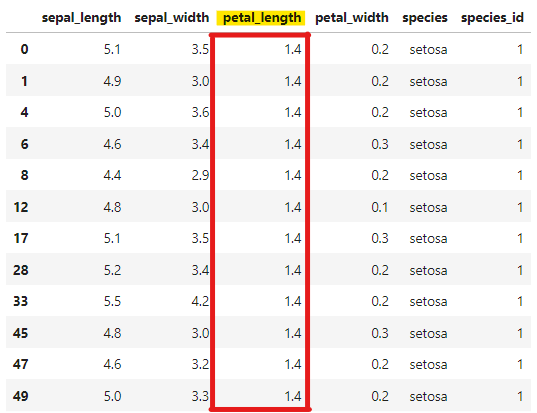
petal_lengthが1.4のデータが抽出できていることが分かります。
複数の条件でデータを抽出
df[(条件1) & (条件2)]
df[(df['petal_length'] == 1.4) & (df['petal_width'] == 0.2)]
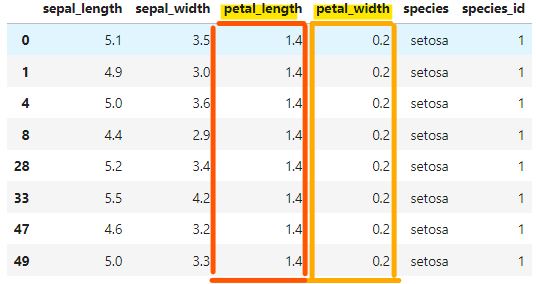
「petal_lengthが1.4」で「petal_widthが0.2」なデータを取得することができました。
condition1 = df['petal_length'] == 1.4
condition2 = df['petal_width'] == 0.2
df[condition1 & condition2]
こういう書き方もできます
条件によるデータ抽出の仕方その2(queryメソッド)
- .query()メソッドは、pandasデータフレーム(DataFrame)に対して条件を指定して行をフィルタリングするために使用
- .query()メソッドを使用することで、条件を直接文字列として指定することができます。
df.query('petal_length >= 1.4')

petal_lengthが1.4以上のデータを抽出することができました。
複数の条件でデータを取得その2(queryメソッド)
df.query('(条件) & (条件)')
df.query('(petal_length >= 1.4) & (petal_width >= 0.2)')
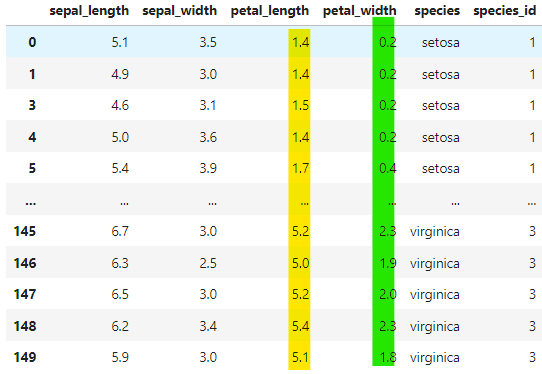
petal_lengthが1.4以上かつpetal_widthが0.2以上のデータが取得できました。
参考
ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門
データサイエンスのための実践Pandas
ChatGPTへの質問
終わりに
今回はデータの読み込み方から、必要なデータの抽出方法をご紹介しました。
次回は時系列データの扱い方をまとめようと思います。