初めに
この記事は「政府の統計データをe-Stat APIとPythonを使って取得する方法」の続きになります。
前回の記事で取得した政府統計データをpandasのデータフレイムに変換し、分析しやすい形に整えるのが目的です。また、データによっては微調整が必要なのでなるべく自分で調整ができるように解説を加えてます。
前回の記事の簡単な内容まとめ
政府統計データを取得するにはAPIキーと統計表IDが必要になります。
そこで、APIキーの取得 / 統計表IDの取得 / 統計データ取得方法をまとめています。
具体例:
「都道府県別人口の割合-総人口」の北海道データだけを取得しました。
「都道府県別人口の割合-総人口」の統計表ID:0003448233
北海道の単一コードは:01000
コードの完成形
今回は統計表IDと北海道の単一コードを使って都道府県別人口の割合の北海道データを指定し、pandasのデータフレイムに変換します。
まず、指定したデータを取得し、pandasのデータフレイムに変換するコードの完成形です。
順を追って解説していきます。
import requests
import pandas as pd
APP_ID = "APIキーを入れてね"
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
params = {
"appId": APP_ID,
"statsDataId": "0003448233",
"cdArea": "01000",
"lang": "J" # 日本語を指定
}
response = requests.get(API_URL, params=params)
data = response.json()
# 統計データからデータ部取得
values = data['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']
# JSONからDataFrameを作成
df = pd.DataFrame(values)
# メタ情報取得
meta_info = data['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']
# 統計データのカテゴリ要素をID(数字の羅列)から、意味のある名称に変更する
for class_obj in meta_info:
# メタ情報の「@id」の先頭に'@'を付与した文字列が、統計データの列名と対応している
column_name = '@' + class_obj['@id']
# 統計データの列名を「@code」から「@name」に置換するディクショナリを作成
id_to_name_dict = {}
if isinstance(class_obj['CLASS'], list):
for obj in class_obj['CLASS']:
id_to_name_dict[obj['@code']] = obj['@name']
else:
id_to_name_dict[class_obj['CLASS']['@code']] = class_obj['CLASS']['@name']
# ディクショナリを用いて、指定した列の要素を置換
df[column_name] = df[column_name].replace(id_to_name_dict)
# 統計データの列名を変換するためのディクショナリを作成
col_replace_dict = {'@unit': '単位', '$': '値'}
for class_obj in meta_info:
org_col = '@' + class_obj['@id']
new_col = class_obj['@name']
col_replace_dict[org_col] = new_col
# ディクショナリに従って、列名を置換する
new_columns = []
for col in df.columns:
if col in col_replace_dict:
new_columns.append(col_replace_dict[col])
else:
new_columns.append(col)
df.columns = new_columns
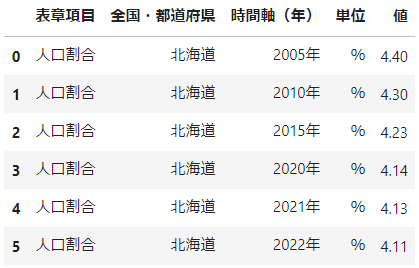
このコードは
・統計データを指定し取得する(前回解説済み)
・地域取得データをpandasに変換
・中身のデータを置き換える
・カラム名を置き換える
の4つの要素で出来ています。
一つずつ解説をして行きます。
「都道府県別人口の割合」の北海道データを取得
「都道府県別人口の割合」の北海道データを指定し、取得していきます。
statsDataIdに「都道府県別人口の割合-総人口」の統計表ID:0003448233
cdAreaに北海道の単一コード:01000
を指定することで、「都道府県別人口の割合」の北海道が指定できます。
北海道単一コードの確認の仕方や、データの取得の仕方は前回の記事に詳しく書いてあります。
import requests
APP_ID = "APIキーを入れてね"
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
params = {
"appId": APP_ID,
"statsDataId": "0003448233",# 統計表ID
"cdArea": "01000", # 北海道ID
"lang": "J" # 日本語を指定
}
response = requests.get(API_URL, params=params)
# Process the response
data = response.json()

「都道府県別人口の割合」の北海道データを指定し、取得することができました。。
VALUEに入っている値が目的の人口の割合データです。中身が@codeに置き換えられている為、修正する必要があります。
地域取得データをpandasに変換
# 統計データからデータ部取得
values = data['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']
# JSONからDataFrameを作成
df = pd.DataFrame(values)
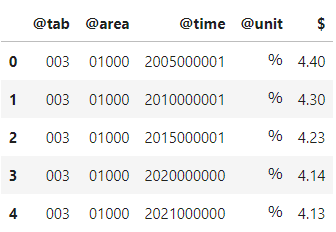
VALUEに入っている値を抽出しデータフレイムに変換することができました。
このままでは、意味がわからないので日本語に変換していきます。
解説 : valuesの指定の仕方
今回の統計データの構造はdata['response']['body']['data']['value']でvalueデータにアクセスしました。
例えば、以下のデータ構造でHello, World!にアクセスするには
data = {
"response": {
"body": {
"data": {
"value": "Hello, World!"
}
}
}
}
data['response']['body']['data']['value']
このように指定することで、valueの値にアクセスすることができます。
中身のデータを日本語に置き換える
一番最後の行[df = pd.DataFrame(values)]の後に追加して実行してください。
もし、わからない場合は最初に完成形を載せていますので、そちらを参考にしてください。
# メタ情報取得
meta_info = data['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']
# 統計データのカテゴリ要素をID(数字の羅列)から、意味のある名称に変更する
for class_obj in meta_info:
# メタ情報の「@id」の先頭に'@'を付与した文字列が、統計データの列名と対応している
column_name = '@' + class_obj['@id']
# 統計データの列名を「@code」から「@name」に置換するディクショナリを作成
id_to_name_dict = {}
if isinstance(class_obj['CLASS'], list):
for obj in class_obj['CLASS']:
id_to_name_dict[obj['@code']] = obj['@name']
else:
id_to_name_dict[class_obj['CLASS']['@code']] = class_obj['CLASS']['@name']
# ディクショナリを用いて、指定した列の要素を置換
df[column_name] = df[column_name].replace(id_to_name_dict)
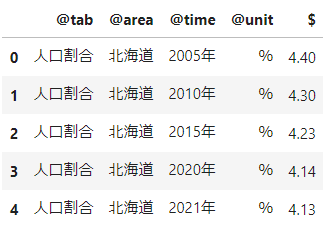
データの中身を日本語に置き換えることができました。
解説
このコードはさっくり言うと、統計データの列名を「@code」から「@name」に置換するための辞書を作成し、データフレームの指定した列の要素を置換しています。ちょっと分かりづらいと思うので、上から順に解説していきます。
# メタ情報取得
meta_info = data['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']
の['CLASS_OBJ']が何を指しているのかはデータを確認する必要があります。
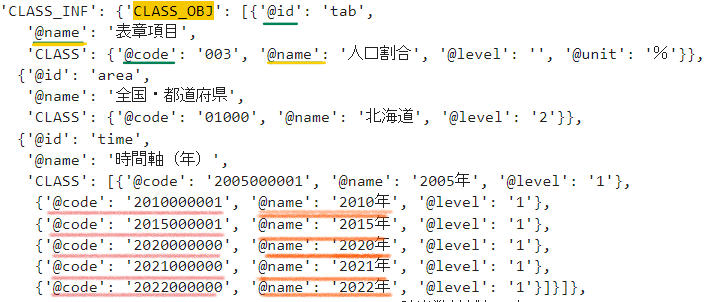
@idと@name , @codeと@nameが対応関係になっていることが分かります。
先ほど取得したvalueの値には@idと@codeが入っている為、これを@nameに置き換えることで日本語に変換することができます。
# 統計データのカテゴリ要素をID(数字の羅列)から、意味のある名称に変更する
for class_obj in meta_info:
# メタ情報の「@id」の先頭に'@'を付与した文字列が、統計データの列名と対応している
column_name = '@' + class_obj['@id']
どうして@を先頭に足すのか?疑問に思うと思います。自分も結構混乱しました。

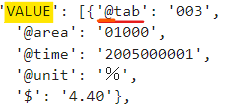
class_obj['@id']で取得した値はtabですが、VALUEには@tabで値が入っています。なので、先頭に'@'を付与することで統計データの列名と対応させることができます。もっと詳しくいうと、class_objの方には@nameの値が入っている為、対応させることでVALUEに入っているidの値を@nameに変換する準備ができます。
# 統計データの列名を「@code」から「@name」に置換するディクショナリを作成
id_to_name_dict = {}
if isinstance(class_obj['CLASS'], list):
for obj in class_obj['CLASS']:
id_to_name_dict[obj['@code']] = obj['@name']
else:
id_to_name_dict[class_obj['CLASS']['@code']] = class_obj['CLASS']['@name']
# ディクショナリを用いて、指定した列の要素を置換
df[column_name] = df[column_name].replace(id_to_name_dict)
ざっくり言うとこのコードは '@code' をキーとして、対応する '@name' を値とするディクショナリを作成し、データフレームの指定した列 column_name の要素をreplace() メソッドを使い置換しています。
もっと詳しく見るにはclass_obj['CLASS']が何を指しているかを確認する必要があります。
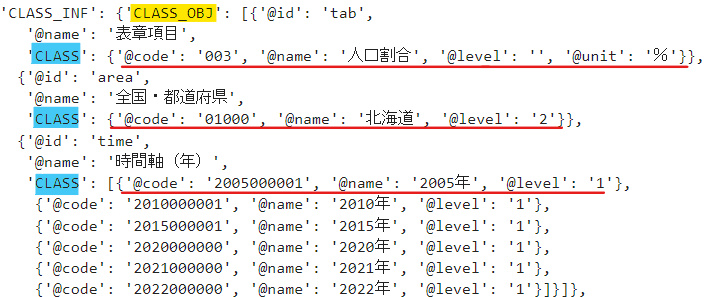
CLASSには各要素の@codeと@nameが入っています。
次はisinstance()についてです。
isinstance()は、オブジェクトが指定されたクラスのインスタンスであるかどうかを判定するための関数です。
例えば、isinstance(obj, int)とすると、objがintクラスのインスタンスであればTrueを返します。
isinstance(class_obj['CLASS'], list)は、class_obj['CLASS']がlistクラスのインスタンスであるかどうかを判定しています。class_obj['CLASS']がリストであればTrueを返し、それ以外の場合はFalseを返します。
このような判定を行う目的は、統計データのメタ情報には要素が1つだけ存在する場合と複数存在する場合があり、それぞれの場合で処理を分けるためです。リストの場合は複数の要素があるため、forループを使って各要素にアクセスする必要があります。一方、リストではない場合は単一の要素が存在するため、直接その要素にアクセスすることができます。
今回の場合で言うとif文の処理で、
リストの場合にforループを使って各要素にアクセスし、
単一の要素のとき直接その要素にアクセスしてます。
カラム名を意味のある名称に置き換える
次は、カラム名を日本語に変更していきます。
下のコードを最後に追加して実行してください。
# 統計データの列名を変換するためのディクショナリを作成
col_replace_dict = {'@unit': '単位', '$': '値'}
for class_obj in meta_info:
org_col = '@' + class_obj['@id']
new_col = class_obj['@name']
col_replace_dict[org_col] = new_col
# ディクショナリに従って、列名を置換する
new_columns = []
for col in df.columns:
if col in col_replace_dict:
new_columns.append(col_replace_dict[col])
else:
new_columns.append(col)
df.columns = new_columns
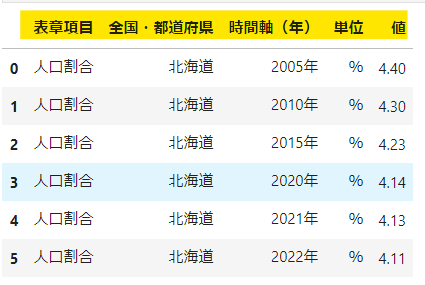
黄色い線を引いたカラム名を変更することができました。
解説
col_replace_dictに{'@unit': '単位', '$': '値'}
の辞書を作成します。なぜ、空の辞書ではなく'@unit': '単位', '$': '値'を先に入れているかというと、meta_infoの中に@unitと$の情報が入っていないからです。
# メタ情報取得
meta_info = data['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']
混乱すると思うので、meta_infoとはCLASS_OBJの中身のことです。
この中に@unitと$の情報が入っていない為、先に指定しています。
コードを実行した後のcol_replace_dictの中身を確認していきます。
{'@unit': '単位',
'$': '値',
'@tab': '表章項目',
'@area': '全国・都道府県',
'@time': '時間軸(年)'}
このように対応してキーとVALUEが入っています。
for class_obj in meta_info:
org_col = '@' + class_obj['@id']
new_col = class_obj['@name']
col_replace_dict[org_col] = new_col
org_colにidをnew_colにnameを入れ辞書を作成しています。
# ディクショナリに従って、列名を置換する
new_columns = []
for col in df.columns:
if col in col_replace_dict:
new_columns.append(col_replace_dict[col])
else:
new_columns.append(col)
df.columns = new_columns
pandasはdf.columnsでカラム名を取得できます。
この時dfのカラム名は@tab,@area,@time,@unit,$になっています。
このカラム名と辞書のキーを対応させて、意味のあるカラム名に変更しています
参考
どこにでもいる30代SEの学習ブログ
Pythonでe-Stat APIを使う
e-Stat APIをGoogle Colab (Python) からアクセスする
e-Stat API仕様
ChatGPTへの質問
終わりに
説明が分かりにくい部分もあったと思いますが政府の統計データをpythonで取得しpandasのデータフレイムに変換するのは大変だったので、少しでもこの記事がお役に立てると嬉しいです。