はじめに
前回の投稿で、日経225の値幅を60%の精度で予測できたら、年率48%の利益が得られるという戯言を吐いた。
そこで、Qiitaで情報収集。
まずは、以下の記事に注目。
https://qiita.com/akiraak/items/b27a5616a94cd64a8653
Accuracy =72%ってあるやん。
これを追試する。
使っている技術はTensorFlow。くだんの記事はTensorFlowを使ったコードを詳細に解説していて、ソースコードも公開されている。当方の理解はちんぷんかんぷんだが、さわって試してみることはできる。ただ、2017年の記事なので、いろいろ変わっていて動かすには苦労した。
元記事のスキーム
前日まで過去3日分の各市場(FTSE, GDAXI, HSI, N225, SSEC等)の値動きを説明変数、当日のSP500の引値を教師データとしてTensorflowで機械学習を行い、当日のSP500の前日比の符号を予測する予測器を構築し、その性能を評価している。ただし、詳細な原理とかは頭悪いんで理解できていない。
その結果が、Accuracy=70%台。
これは期待が持てる。
今回のスキーム
予測対象は1358日経レバ2倍とし、説明変数も微修正。
説明変数には、前日までのNIKKEI225、各国のインデックスだけでなく円ドルも含める。
教師ラベル:当日の1358日経レバ2倍の値幅(引け値-寄値)が上昇または下落
説明変数:
DOW30, NASDAQ_COMP, S&P500, FTSE_MIB, DAX, CAC40, HANG_SENG, usdjpy, NIKKEI225 各指標の過去3日分の終値(9×3=27次元)
モデルは元ソースのまま
入力層:[27, 50], stddev=0.0001
隠れ層1:[50, 25], stddev=0.0001
隠れ層2:[25, 2], stddev=0.0001
出力層:[2]
実験結果
学習期間 = 2014-10-30 〜 2017-10-31
評価期間 = 2017-11-22 〜 2020-07-09
学習回数:12000回
学習データによる精度の推移
1000 0.5241935
2000 0.55241936
3000 0.5510753
4000 0.5591398
5000 0.5645161
6000 0.56989247
7000 0.57123655
8000 0.56989247
9000 0.56182796
10000 0.5577957
11000 0.5591398
12000 0.56182796
評価期間での精度
評価数 = 673
上昇, 正解 = 127
下落, 正解 = 216
上昇, 不正解 = 130
下落, 不正解 = 200
Accuracy = 0.5096582466567607
損益シミュレーション(バックテスト)
上昇予想の場合:1358上場日経2倍
下落予想の場合:1357日経ダブルインバース
10,000,000円分を寄り付きで購入し、引けで売却する
2017-11-22 〜 2020-07-09まで、この方法を繰り返した場合の損益
-1,551,671円
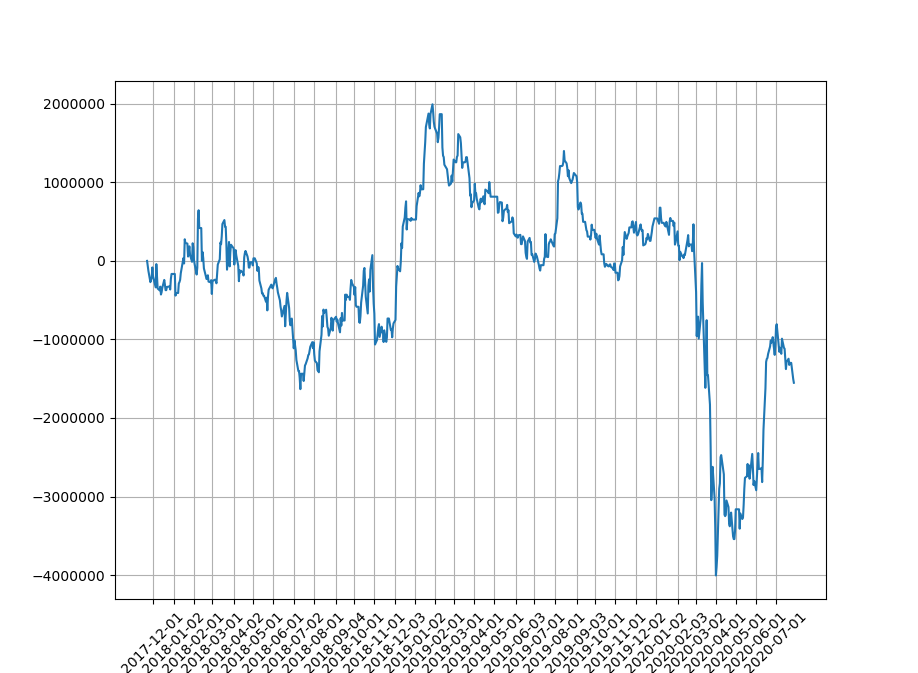
月別損益
2017年11月: -83249円
2017年12月: -83258円
2018年1月: 341621円
2018年2月: -595994円
2018年3月: 626082円
2018年4月: -222331円
2018年5月: -332350円
2018年6月: -384622円
2018年7月: -375612円
2018年8月: 355649円
2018年9月: 472170円
2018年10月: -262912円
2018年11月: -251190円
2018年12月: 1321959円
2019年1月: 1181772円
2019年2月: -545563円
2019年3月: -427964円
2019年4月: 82859円
2019年5月: -465943円
2019年6月: -265452円
2019年7月: 96485円
2019年8月: 936343円
2019年9月: -723723円
2019年10月: -432153円
2019年11月: 396537円
2019年12月: 181781円
2020年1月: -303620円
2020年2月: -109976円
2020年3月: -3523718円
2020年4月: -35221円
2020年5月: 630419円
2020年6月: 1731269円
結果の考察
学習はできているようだけど、取り置きした評価データでの精度は、サイコロを振ったのと同レベル。当然ながら、バックテストの結果も全くダメ。
予測と全く逆の売買をすると損益は若干プラスになるようだが。。。
前日までの各国市場のインデックスから当日のNIKKEI225の寄り値を予測することは、先人たちの結果はAccuracy=0.7以上いけそうということだったが、寄り値を予測したところであまりご利益は無い。
単に寄る前に板を見たらわかることで、予測する必要すらない。
今回のスキームのように値幅を予測するということは、寄り値とその先の引値を予測しなければならない訳で、このAccuracyが0.5096ということは、そんな予測はできないということになる。当然といえば当然。寄った先は所詮ランダムウォーク。
2017/12から2020/2までは、まさにサイコロ振って売買したが如く収支トントン。
2020/2から2020/3で損失を大きくしているが、これは新型コロナ蔓延以前の平穏な状態を学習させた予測器を使用したため、コロナ渦で大きく予測を外したということが言えるのではないだろうか。
累積損益のグラフを眺めると、全期間が全くランダムではなく、いいとき(予測が当たるとき)と悪いときがまとまって存在するように見える。
同じ収支トントンでも累積損益グラフがAのような場合と、今回のようなBのような場合とでは、予測器の質が異なるように思う。BよりもAのほうが質がいい。今回の予測器は質が悪い!


今回の予測器で、たまたま2018/12から運用を開始したとすると、最初の数か月は大儲け状態となり、「俺って天才!」と浮かれてしまい、その後の判断を誤り大やけどを負うことになってしまう。
損益に大きな周期が出るような予測器Bはダメな予測器であり、小刻みにプラスを積み重ねるような予測器Cを作ることを新たな目標にするということで、今回は締めくくる。

まとめ
- 代表市場のインデックスの過去3日の引値を、翌日の日経平均の
値幅の符号を教師ラベルとして機械学習させてみたが、Accuracyが0.5096しかなく、
うまくいかなかった。 - 質の良い予測器はどんなものかの考察ができ、目標ができた。
「Yahoo! Finance.東京株式市場見通しの真贋 」につづく