Amazon SageMaker Studio の導入と Autopilot について #1の続きです。
前回は、SageMaker Studioの導入と Autopilot によるパイプラインを開始したところまで終わりました。
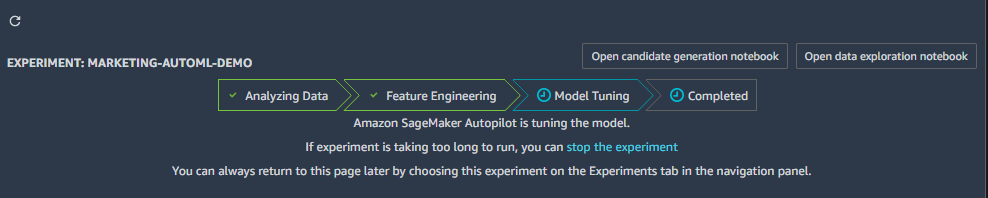
Autopilotのパイプラインは、Analyzing Data → Feature Engineering → Model Tuning → Completed の流れになっています。
Amazon SageMaker Autopilot – 高品質な機械学習モデルをフルコントロールかつ視覚的に自動生成
Amazon SageMaker Studio - Amazon SageMaker AutoPilot (part 2)
part2は、Future Engineeringについての話です。
「Open data exploration notebook」には、データセットに関する情報が書かれています。
1.どのように特徴量を選択するために分析されたのか
2.データセットからAutoMLパイプラインの修正と改善について
We read 39128 rows from the training dataset. The dataset has 21 columns and the column named y is used as the target column. This is identified as a BinaryClassification problem. Here are 2 examples of labels: ['no', 'yes'].
21項目からなる39128個のトレーニングサンプルがあり、「y」が推論対象。これはyesかnoを推論する二項分類の問題です。
Dataset Sample
The following table is a random sample of 10 rows from the training dataset. For ease of presentation, we are only showing 20 of the 21 columns of the dataset.
10個のサンプルを表示しています。21項目中20項目のみ表示しています。
Column Analysis
The AutoML job analyzed the 21 input columns to infer each data type and select the feature processing pipelines for each training algorithm.
AutoML job が21項目を分析します。
Percent of Missing Values
We found 1 of the 21 of the columns contained missing values. The following table shows the 1 columns with the highest percentage of missing values.
1項目について欠損値を見つけたようです。
poutcome が 86.33% 欠損しているそう。
Count Statistics
データがカテゴリカルならone-hot encodingを実施したり、テキストならtf-idfなどを実行するようです。
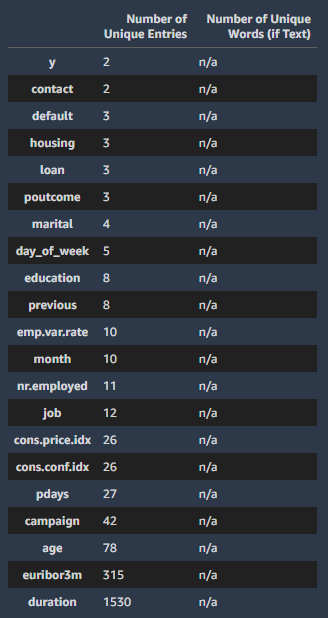
The table below shows 21 of the 21 columns ranked by the number of unique entries.
各項目の独立した値の数を一覧表にしてくれています。
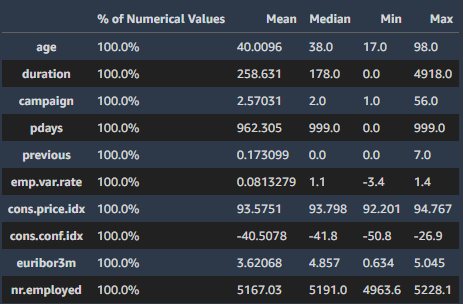
Descriptive Statistics
数値データの場合は、正規化、log、quantile、binningなどにより外れ値やスケールを調整してくれます。
Amazon SageMaker Studio - Amazon SageMaker AutoPilot (part 3)
part3は、Model Tuning の話です。
「Open candidate generation notebook」には、SageMaker Autopilot ジョブの詳細情報(各試行の情報、データ前処理ステップなど)が書かれています。すべてのコードは利用可能な状態で、実験を重ねる際のとっかかりになるらしい。
The dataset has 21 columns and the column named y is used as the target column. This is being treated as a BinaryClassification problem. The dataset also has 2 classes. This notebook will build a BinaryClassification model that maximizes the "ACCURACY" quality metric of the trained models. The "ACCURACY" metric provides the percentage of times the model predicted the correct class.
ACCURACY(正確度)が最大になるように二項分類のモデル作ったそうです。
Sagemaker Setup
SageMakerのセットアップ
- Jupyter: Tested on JupyterLab 1.0.6, jupyter_core 4.5.0 and IPython 6.4.0
- Kernel: conda_python3
- Dependencies required
sagemaker-python-sdk>=v1.43.4
Downloading Generated Candidates
データ変換とAutopilotに関するモジュールをダウンロードします。
SageMaker Autopilot Job and Amazon Simple Storage Service (Amazon S3) Configuration
Autopilot Job と S3の設定を行います。
Candidate Pipelines
Generated Candidates
The SageMaker Autopilot Job has analyzed the dataset and has generated 10 machine learning pipeline(s) that use 2 algorithm(s). Each pipeline contains a set of feature transformers and an algorithm.
2つのアルゴリズムを用いた10個のパイプラインを生成し、分析したそうです。
dpp0-xgboost: This data transformation strategy first transforms 'numeric' features using RobustImputer (converts missing values to nan), 'categorical' features using ThresholdOneHotEncoder. It merges all the generated features and applies RobustStandardScaler. The transformed data will be used to tune a xgboost model. Here is the definition:
10個がそれぞれどのようなパイプラインかの説明が書いてあります。上記は、内1つの例です。
Selected Candidates
SageMakerのtraining jobとバッチ変換を含む特徴エンジニアリングを行います。
Executing the Candidate Pipelines
Run Data Transformation Steps
データ変換を実施します。
Multi Algorithm Hyperparameter Tuning
データ変換されたら、Multi-Algo Tuning jobにより最適な推論モデルを探します。
Model Selection and Deployment
Tuning Job Result Overview
Pandas dataframeを用いて各パイプラインの可視化を行います。
Model Deployment
最後にデプロイします。
Amazon SageMaker Studio - Amazon SageMaker AutoPilot (part 4)
part4は、モデルの比較やデプロイまでの話です。
Autopilotが完了すると、さまざまなモデルができています。
Trialsタブを見ると、トレーニングジョブと精度の一覧が見れます。
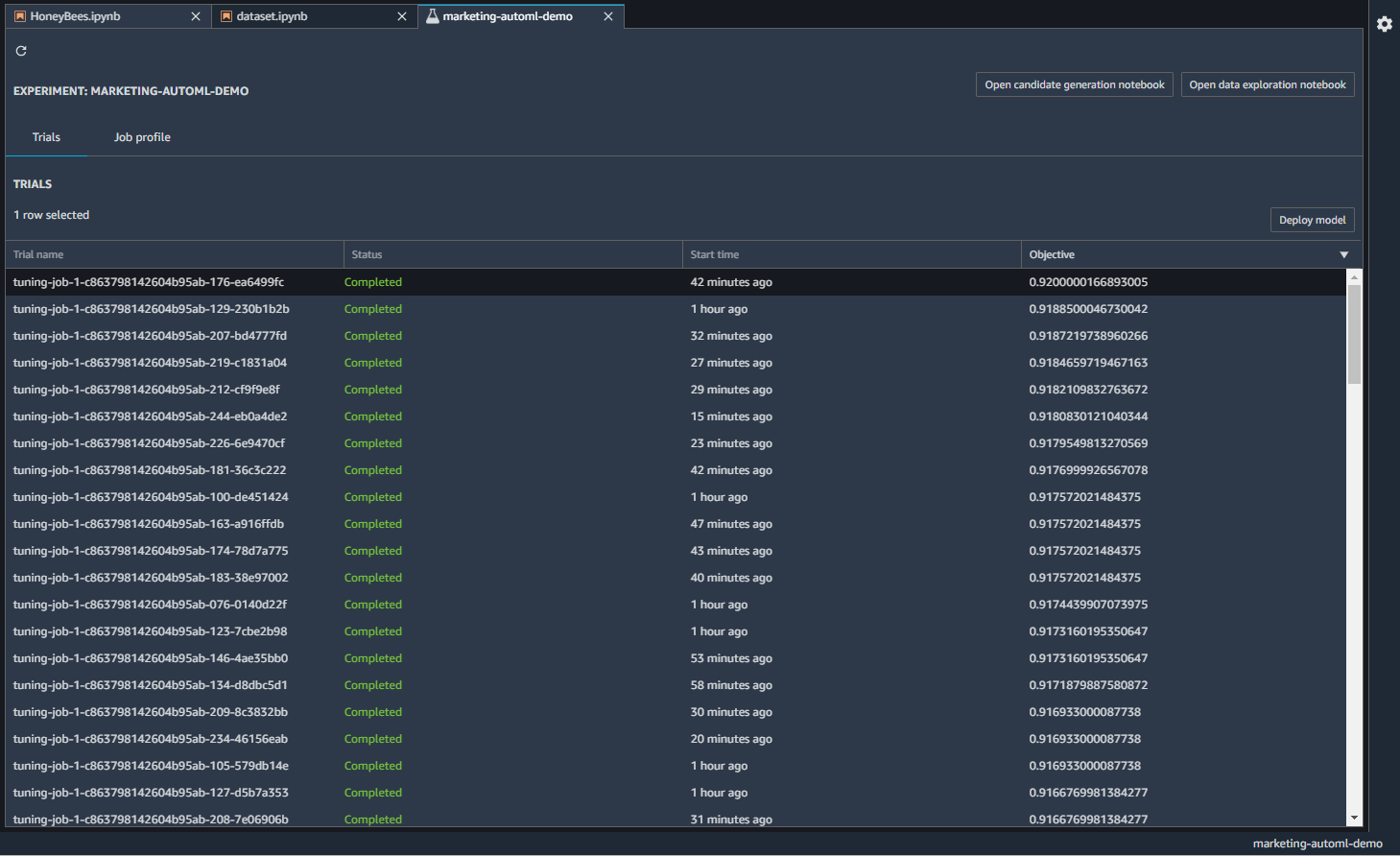
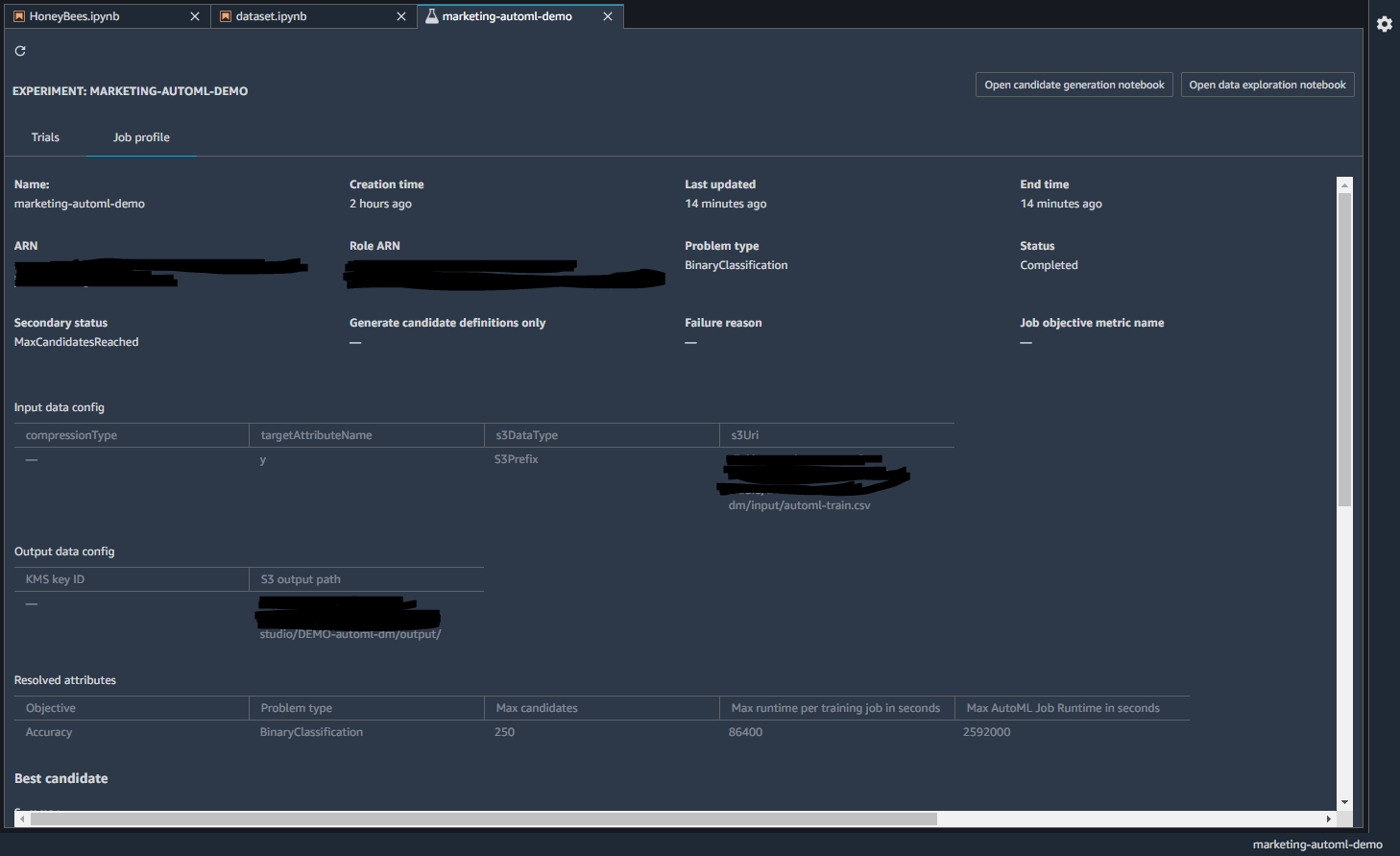
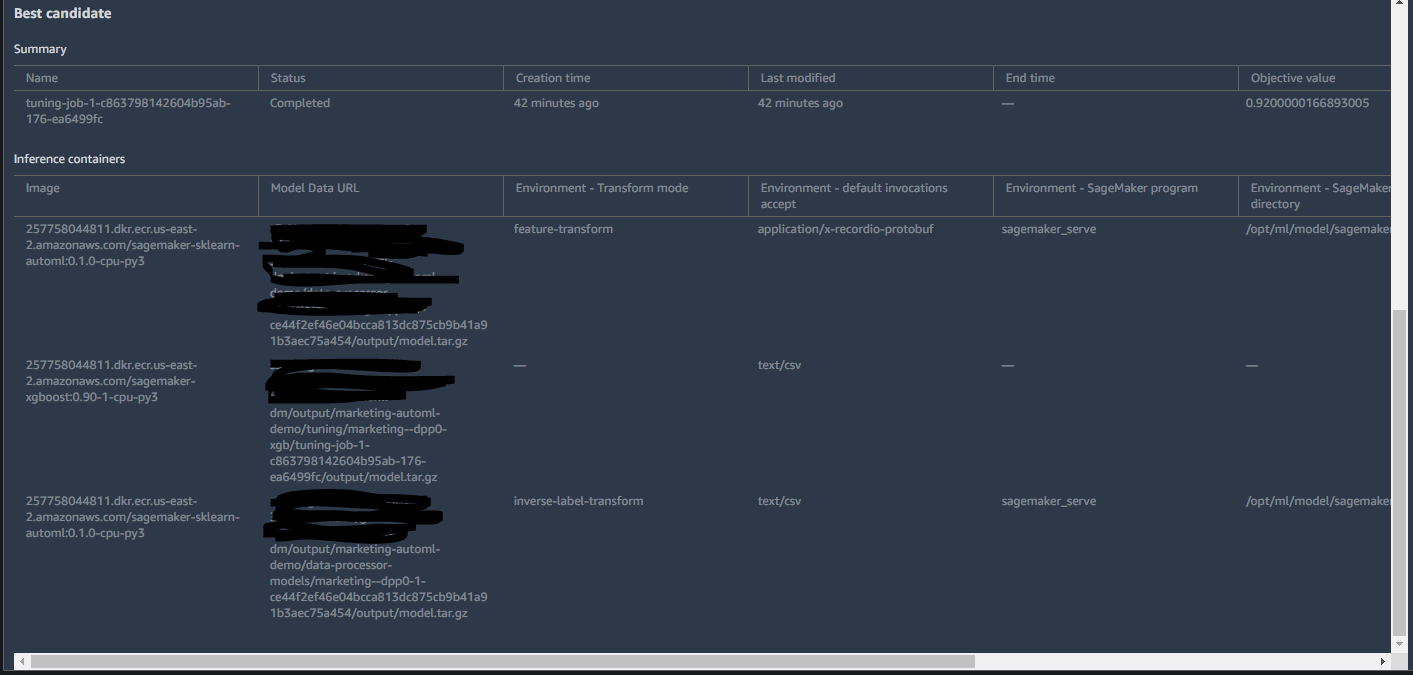
Job Profileでは、学習時間や設定の情報、ベストなモデルの候補が挙げられています。
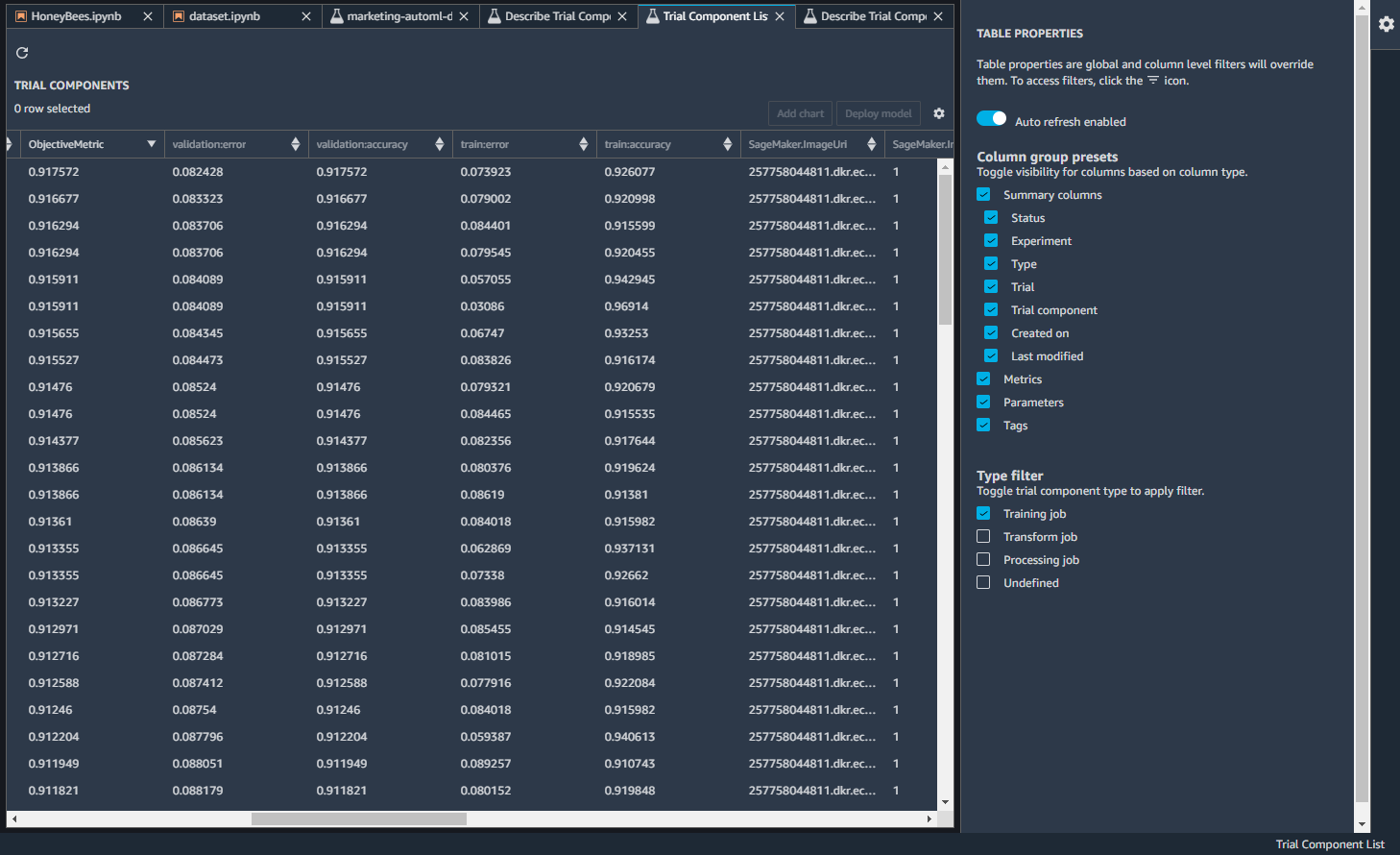
トレーニングジョブを右クリックして、Open in trial component listをクリックすると、詳細の一覧が見れます。
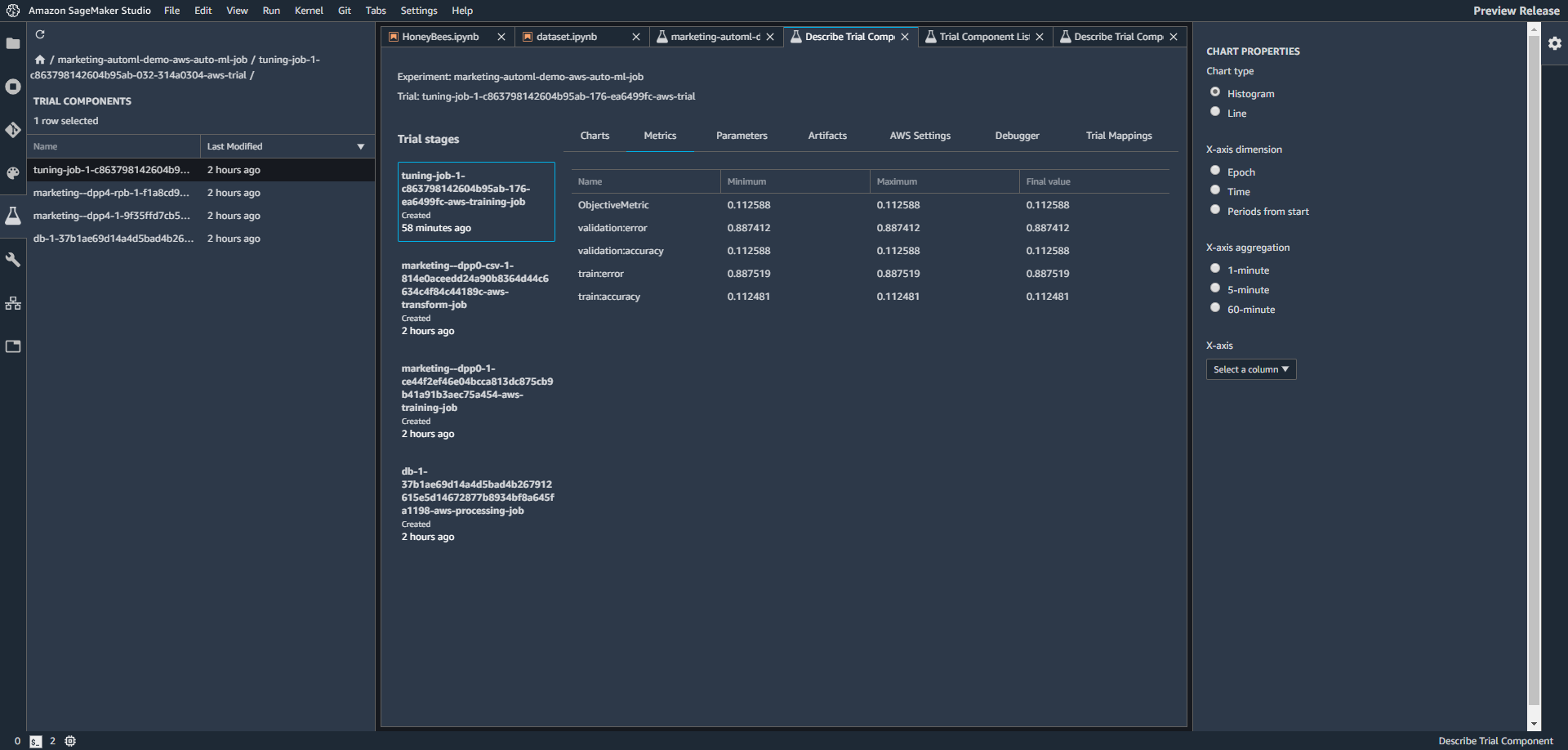
トレーニングジョブを右クリックして、Open in trial detail をクリックすると、ジョブの詳細が見れます。
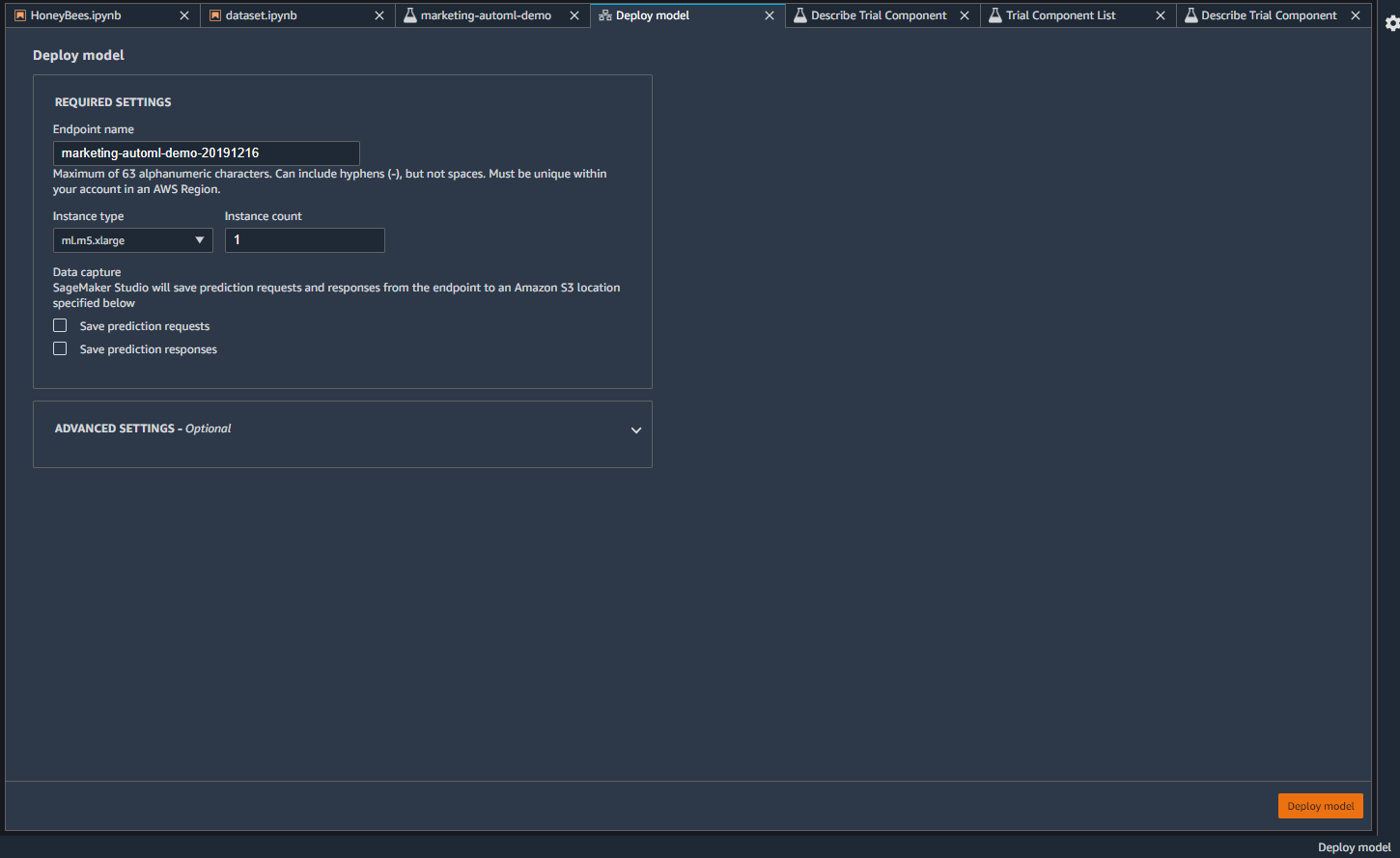
Deploy Modelをクリックすると、エンドポイントが作成されます。
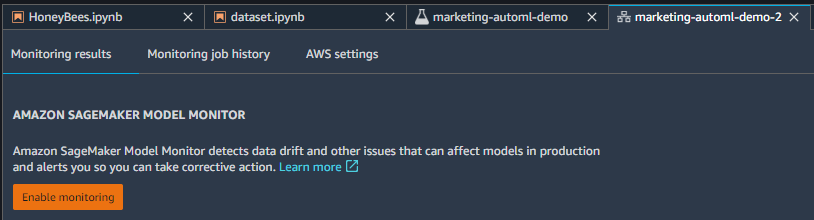
Enable Monitoring をクリックすると、
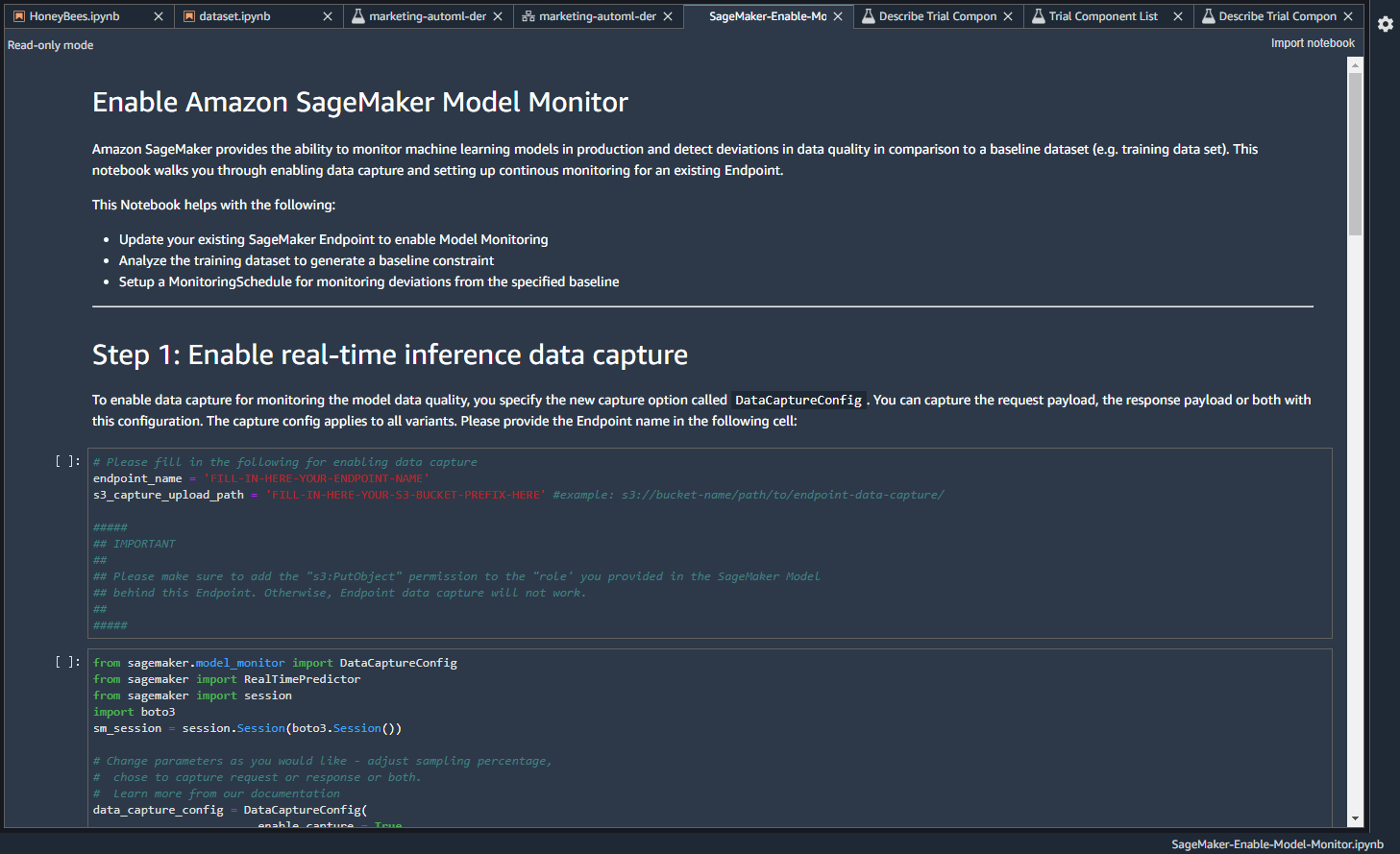
ノートブックを利用して、モデルの監視ができるみたいです。
Amazon SageMaker Experiments – 機械学習モデルの整理、追跡、比較、評価
Amazon SageMaker Model Monitor – 機械学習モデルのためのフルマネージドな自動監視
まとめ
ざっくりとした説明になってしまいましたが、SageMaker Autopilotの続きをやってみました。
SageMaker Autopilotにより、モデルを自動で最適なやつを作ってくれます。さらに、どのようなプロセスでモデルを作っているのかや、モデルの比較や監視までできるようです。