はじめに
これやっていきまーす
開発環境
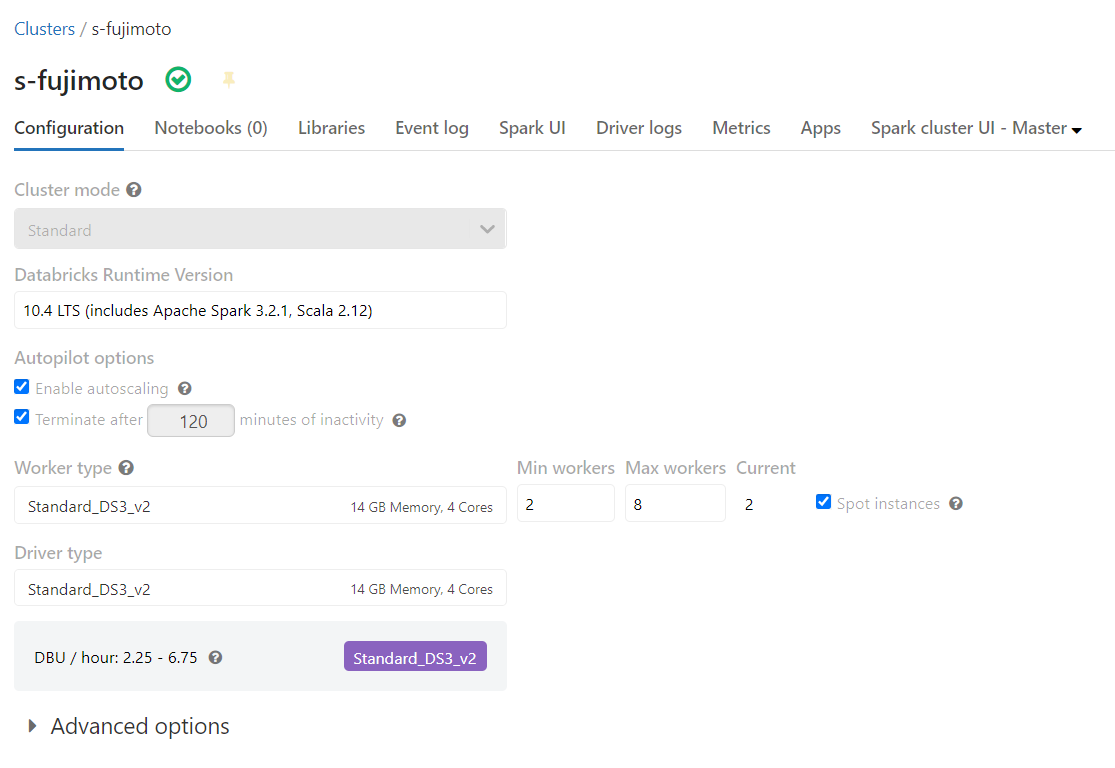
実装
1.ライブラリをインストール
%pip install tensorflow
2.ライブラリをインポート
import pandas as pd
from PIL import Image
import numpy as np
import io
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from pyspark.sql.functions import col, pandas_udf, PandasUDFType
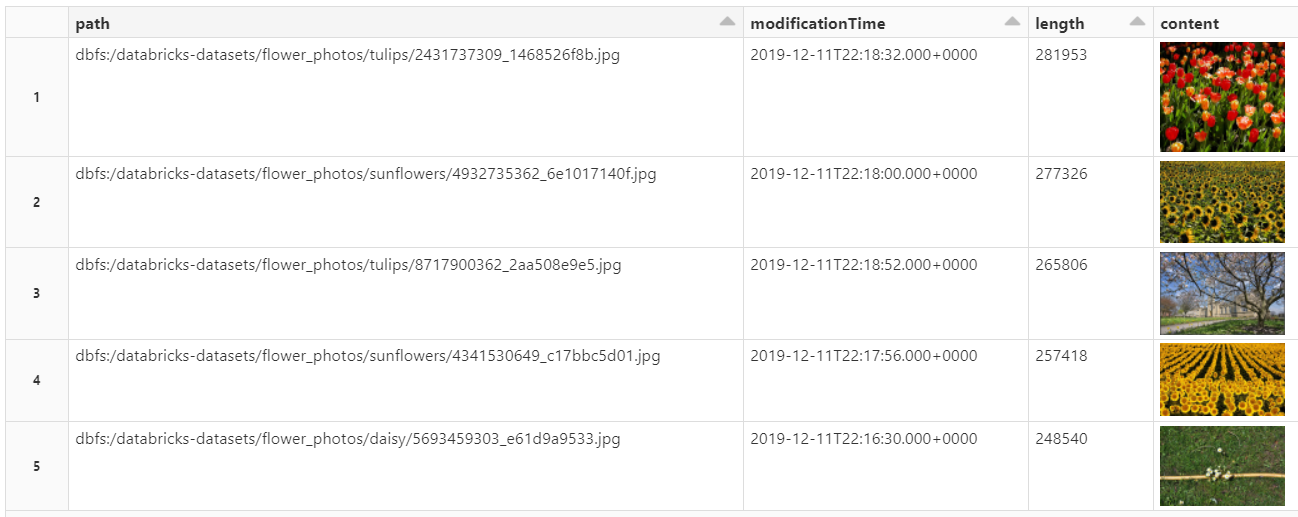
3.flowers datasetを表示
%fs ls /databricks-datasets/flower_photos

4.flowers datasetの読み込み
images = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("/databricks-datasets/flower_photos")
display(images.limit(5))
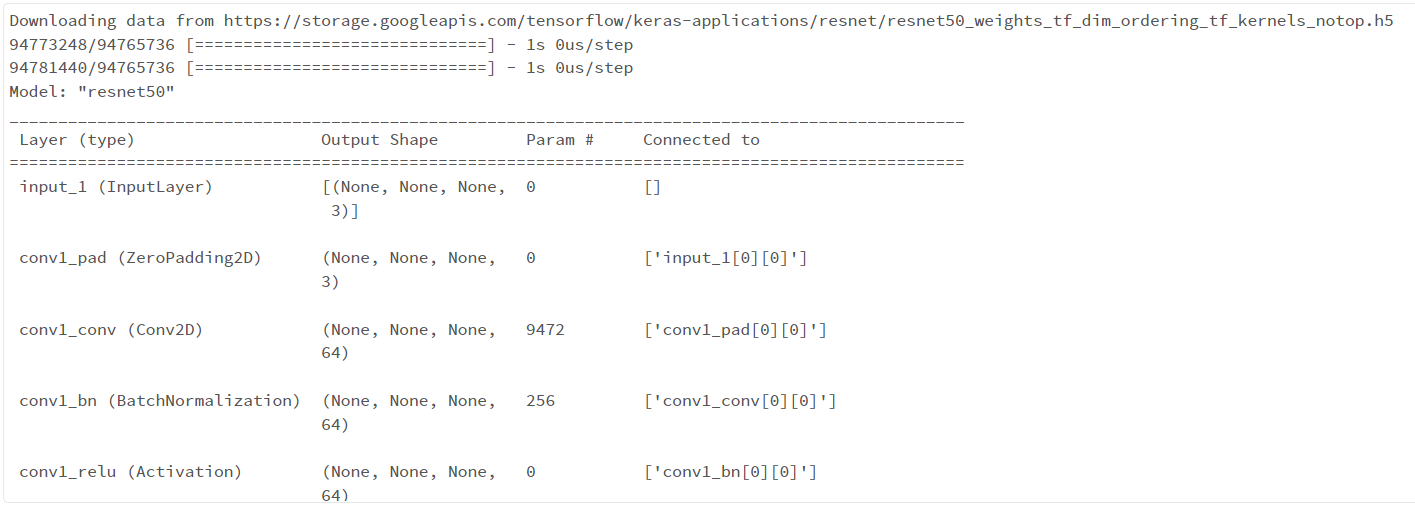
5.モデルの準備(ResNet50)
model = ResNet50(include_top=False)
model.summary() # verify that the top layer is removed
bc_model_weights = sc.broadcast(model.get_weights())
def model_fn():
"""
Returns a ResNet50 model with top layer removed and broadcasted pretrained weights.
"""
model = ResNet50(weights=None, include_top=False)
model.set_weights(bc_model_weights.value)
return model
6.特徴量化
def preprocess(content):
"""
Preprocesses raw image bytes for prediction.
"""
img = Image.open(io.BytesIO(content)).resize([224, 224])
arr = img_to_array(img)
return preprocess_input(arr)
def featurize_series(model, content_series):
"""
Featurize a pd.Series of raw images using the input model.
:return: a pd.Series of image features
"""
input = np.stack(content_series.map(preprocess))
preds = model.predict(input)
# For some layers, output features will be multi-dimensional tensors.
# We flatten the feature tensors to vectors for easier storage in Spark DataFrames.
output = [p.flatten() for p in preds]
return pd.Series(output)
@pandas_udf('array<float>', PandasUDFType.SCALAR_ITER)
def featurize_udf(content_series_iter):
'''
This method is a Scalar Iterator pandas UDF wrapping our featurization function.
The decorator specifies that this returns a Spark DataFrame column of type ArrayType(FloatType).
:param content_series_iter: This argument is an iterator over batches of data, where each batch
is a pandas Series of image data.
'''
# With Scalar Iterator pandas UDFs, we can load the model once and then re-use it
# for multiple data batches. This amortizes the overhead of loading big models.
model = model_fn()
for content_series in content_series_iter:
yield featurize_series(model, content_series)
/databricks/spark/python/pyspark/sql/pandas/functions.py:386: UserWarning: In Python 3.6+ and Spark 3.0+, it is preferred to specify type hints for pandas UDF instead of specifying pandas UDF type which will be deprecated in the future releases. See SPARK-28264 for more details.
warnings.warn(
# Pandas UDFs on large records (e.g., very large images) can run into Out Of Memory (OOM) errors.
# If you hit such errors in the cell below, try reducing the Arrow batch size via `maxRecordsPerBatch`.
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "1024")
# We can now run featurization on our entire Spark DataFrame.
# NOTE: This can take a long time (about 10 minutes) since it applies a large model to the full dataset.
features_df = images.repartition(16).select(col("path"), featurize_udf("content").alias("features"))
features_df.write.mode("overwrite").parquet("dbfs:/ml/tmp/flower_photos_features")
7.この特徴量を用いて、新しいモデルを作って花の分類とかやってみよう。logistic regressionのサンプルとか見てね。
お疲れ様でした。