12月最初の記事ということで、まずGrafanaの製品についてカテゴライズし、利用イメージも交えながら解説していきます。
クラウドネイティブ化が進み、アプリケーションがマイクロサービスとしてKubernetes上にデプロイされるのが当たり前になった今、従来の監視ツールだけではシステム全体を見通すことが難しくなっています。そこで脚光を浴びるのが、オブザーバビリティ(可観測性)です。
Grafanaは、2013年に最初のコミットが行われたOSSツールであり、オブザーバビリティ(可観測性)に必要なツール群を生み出し、オブザーバビリティプラットフォーム分野の『2025 Gartner Magic Quadrant』でも高い評価を得ています。
Grafanaをベースにしたオブザーバビリティの全体像は以下のようになります。
オブザーバビリティを適切に行うために必要なことが多くあることがわかります。
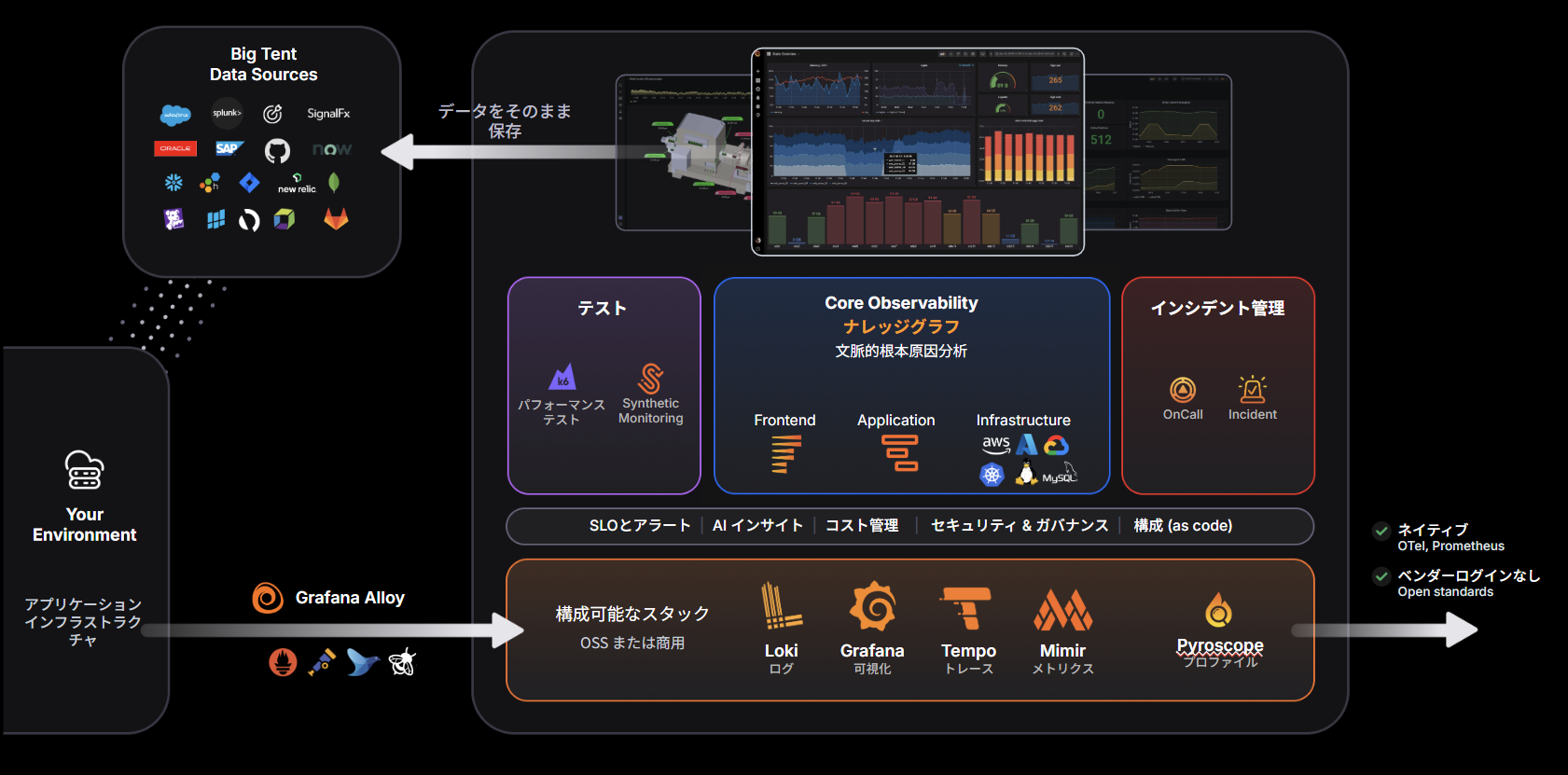
オブザーバビリティは、稼働しているシステムなどを可観測するだけでなく、リリースする前から計画的にツールを利用し、公開して監視し、システムの状態を検知し、インシデント対応を行うという流れを作ることがポイントです。
OSS(オープンソース・ソフトウェア)版を中心に、Grafanaツール群を紹介します。Kubernetes環境でのリアルなユースケースと共に、一気に解説していきます!
すべての中心、司令塔的な役割:可視化 (Visualization)

システムの「今」を映し出す、オブザーバビリティのフロントエンドです。
- 役割: データの統合・可視化ダッシュボード
- 概要: あらゆる場所にあるデータ(クラウド、DB、ログなど)を繋ぎ、一つの画面にグラフやメーターとして表示するツールです。データ自体は保存せず、「見せる」ことに特化しています。
- Kubernetes時代のユースケース: EKS/GKEクラスターの大型モニターに、全マイクロサービスのリアルタイムリソース使用率(CPU, Memory)と、API Gatewayのレイテンシを一元表示。チーム全員がクラスター全体の健全性を瞬時に把握します。
オブザーバビリティの4本柱:バックエンド (Backend)
集めたデータを種類ごとに最適な形で保存し、分析するためのデータ保管を行う4つのツールがあります。
 (ログ)
(ログ)
- 役割: テキストログの超軽量検索エンジン
- 概要: サーバーが出力するログを保存します。全文検索インデックスを作らない独自技術により、圧倒的な低コスト・省メモリで動作し、エラー調査に強さを発揮します。
- Kubernetes時代のユースケース: 特定のDeploymentからデプロイされた「決済マイクロサービス」でエラーが急増。Lokiのラベルクエリ(例:{namespace="prod", app="payment-service"})で絞り込み、大量のPodログの中から「400 Bad Request」を含むログだけを瞬時に抽出。特定のヘッダーが原因であることを特定します。
 (メトリクス)
(メトリクス)
- 役割: 数値データの長期保存・大規模分析
- 概要: CPU使用率やメモリ量といった「数値の推移」を長期間保存。Prometheusと互換性があり、データ量が増えても無限に拡張できる設計です。Prometheusの長期保存(Remote Write)と水平スケーリングを実現します。
- Kubernetes時代のユースケース: 季節イベントに向けてトラフィックが過去最高を記録。「現在のサービスPod数」と「去年の同イベント時のPod数とリソース使用率」を重ねて比較し、Horizontal Pod Autoscaler (HPA)の閾値を適切に設定し、スケールアウトの準備を行います。
 (トレース)
(トレース)
- 役割: リクエストの追跡(分散トレーシング)
- 概要: 1つのリクエストが、裏側でどのサービスを経由したかを一本の線(ウォーターフォール図)として可視化します。ボトルネックの発見に使います。
- Kubernetes時代のユースケース: 「検索APIのレイテンシが閾値を超えた」とアラートが発生。Tempoで該当リクエストを追跡したところ、「商品DBを操作する別のNamespaceのマイクロサービスの応答に遅延が発生している」ことが判明。サービス間連携の問題を即座に可視化します。
 (プロファイル)
(プロファイル)
- 役割: コードレベルのパフォーマンス分析
-
概要: プログラムのどの関数(コードの行)がCPUやメモリを無駄に消費しているかを分析します。
※ Grafana PhlareとPyroscopeは統合され、現在は『Grafana Pyroscope』として提供されています。 - Kubernetes時代のユースケース: 特定のDeploymentでデプロイしたPodのCPU使用率が異常に高い。Pyroscopeでプログラムのホットパスを分析すると、「キャッシュ更新処理の関数」が非効率な再帰ループを繰り返していることを発見し、Kubernetesのリソース制限(Limit)を調整する前に、アプリケーションコードの根本的な無駄を排除します。
これら4つの柱を組み合わせることで、過去の傾向分析からリアルタイムのトラブルシューティングまで、あらゆる角度からシステムの健康状態を解き明かす最強の土台が完成します。
データの配達を担う作業員:収集と計装 (Collection & Instrumentation)
あらゆるシステムからデータを吸い上げて、4つの柱にデータを運ぶ配達人的な役割を行う重要なツールになります。

- 役割: OpenTelemetry Collector互換の統合データ収集エージェント
- 概要: 各サーバーに常駐し、ログ・メトリクス・トレースをまとめて収集して、LokiやMimirへ配達するツールです。データのフィルタリングや加工も行います。
- Kubernetes時代のユースケース: 新たに立ち上げたKubernetesクラスターのすべてのNodeとPodにDaemonSetとしてAlloyをデプロイ。設定ファイル一つで、クラスター内の全リソース使用状況とアプリケーションログを自動的に収集・送信し、監視漏れを防ぎます。

- 役割: eBPFを使った自動監視(ゼロコード計装)
- 概要: アプリケーションのコードを一切書き換えることなく、OSレベルから通信をキャプチャし、自動的にデータを計測します。
- Kubernetes時代のユースケース: 開発者が退職し、コードがブラックボックス化している「古い認証マイクロサービス」がある。Beylaを導入し、PodのYAMLやDockerイメージなどアプリケーションコードを書き換えることなく、外側から「API処理にかかっている時間」を正確に可視化します。

- 役割: フロントエンド(Webブラウザ)監視
- 概要: ユーザーのブラウザ側で起きているエラーや表示速度を計測するWeb SDKです。「ユーザー体験」を直接監視します。
- Kubernetes時代のユースケース: 新バージョンをカナリアリリースした直後、サーバーログにエラーはないが売上が伸びない。Faroを見ると、「特定のスマホ機種のユーザーで、新機能のJavaScriptエラーにより画面の表示が崩れ、重要なボタンが押せない状態になっていた」 ことがわかりました。
サーバー内部はAlloyとBeylaで、ユーザー体験はFaroが監視を担います。この「内と外」からの収集体制によりシステムの死角をなくし、あらゆるトラブルの予兆を逃さず捉えることが可能になります。
事前演習と緊急対応:運用と品質 (Operations & QA)
システムの事前演習を適切に行うことで、公開する前にシステムの状態を最適化することができます。公開後に問題が発生した際に迅速な対応を可能とします。

- 役割: 負荷テスト・パフォーマンス試験
- 概要: 大量のアクセスをシミュレーションし、システムがどこまで耐えられるかをテストします。開発者がJavaScriptでテストシナリオを記述しやすいのが特徴です。
- Kubernetes時代のユースケース: GitOpsによるデプロイのPull Requestに対して、k6を使った負荷テストをCI/CDパイプラインに組み込み、「昨年の3倍のアクセス」を想定したテストをステージング環境で実行。サービス応答時間に問題がないことを検証してから、マージして本番クラスターへデプロイします。

- 役割: インシデント管理・連絡網制御
- 概要: アラート発生時に、シフト表に基づいて担当者に通知(Slack、電話など)を行い、対応状況を管理します。
- Kubernetes時代のユースケース: 大晦日の深夜2時、Prometheusから「データベースPodの再起動ループ」というアラートが発生。OnCallが「年末年始特別シフト」に基づいて、当番エンジニアの携帯電話を鳴らし、5分以内に応答がなければ、自動的に技術責任者へエスカレーション電話をかけます。
k6による事前の負荷テスト(事前検証)と、OnCallによる確実な「緊急対応」。この備えがあれば、不測の事態にも動じない強靭な運営体制が整い、チームは自信を持って本番の商戦を迎えることができます。
Grafanaツール群を利用したオブザーバビリティサイクル
すべてのツールを組み合わせることで、以下のような最強の運営体制が実現し、顧客満足度の最大化、売上および利益の最大化を実現することができます。
-
【準備(シフトレフト)】
デプロイ前に k6 で負荷テストをパスさせ、Pyroscope でコードの無駄を排除。Mimir の過去データからトラフィック予測を立て、HPA設定を最適化します。 -
【監視】
Alloy や Beyla でクラスターとマイクロサービス全体からデータを収集し、Grafana のダッシュボードで健全性を全社共有。 -
【検知】
ユーザー体験の異変を Faro で、サーバー側の異常を Loki と Tempo で即座に特定し、問題のPodやTrace IDまで掘り下げます。 -
【対応】
夜間や休日のトラブルは OnCall が確実に担当者を呼び出し、「止まらない、高速なマイクロサービス群」の運営を実現します。
このサイクルこそが、Grafanaを利用して構築できる、現代のオブザーバビリティ・エコシステムの全体像です。
それぞれのツールをECサイトでのわかりやすい例で説明しました。
まずはGrafanaによる可視化から始めて、徐々にこのサイクルを作り上げていくことで、常に最適な運営を実現し、顧客に最適なサービスを展開することができます。
Grafanaを使ってみようかなと思われた方は、サインアップするだけですぐに使えるGrafana Cloudを利用すれば簡単に試すことができます。
本記事がGrafana製品群の理解、最適なオブザーバビリティツールの導入、そして最適なサイクル実現の一助となれば幸いです。