はじめに
社会保険労務士試験の学習を効率化するという目的でAI学習アプリ「StudyFor-SR(スタディーフォー エスアール)」を開発しましたので、そのメインロジックについてここでお話しできればと思います。
私自身が社労士試験の元受験経験者(過去に合格済み)で、受験生時代に感じた「悩み」と「非効率」を解決したいという思いから、このWebアプリを作りました。
余談ではありますが、リリース当日(2026年3月10日現在)にも関わらず、半日でフリープラン・有料プラン(Standard/Premium)含めて10人以上の方が新規登録してくださり、驚いています。
また、AIを活用した類似の個人アプリ開発に興味がある方の参考になれば幸いです。
本記事では、StudyFor-SRに実装した以下の3つの技術について、実装した方法や苦労した点を共有していきます。
- ハイブリッドRAG(ベクトル検索 + 簡易GraphRAG)
- PageRankの応用(重要度スコア算出)
- ブラック・ショールズモデル(AI合格可能性予測)
StudyFor-SRとは
社労士試験特化のAI学習Webアプリです。
主な機能は以下の通りです。
※ 本記事では、上記で挙げた3つの技術に関連する機能(以下の機能1〜6の太字部分1, 2, 3)を中心に書いていますが、実際には以下のような機能も実装しています。
- 学習機能(問題3,847問 + 法令条文14,267条文 / PageRankの応用)
- AIチューター(ハイブリッドRAG)
- AI合格可能性予測(ブラック・ショールズモデルを暫定的に使用)
- 足切りリスク分析(レーダーチャート、バーチャート)
- 実力スコア(予想得点)の算出
- 弱点克服システム(自動レコメンド)
技術スタック
| カテゴリ | 技術 |
|---|---|
| フロントエンド | Next.js 15.5.9(App Router)、TypeScript、Tailwind CSS |
| バックエンド | Python、Server Actions |
| データベース | Supabase(PostgreSQL + pgvector) |
| LLM | Gemini API(Gemini 2.5 Flash Lite、Gemini 2.5 Flash)、bge-m3(Cloudflare Workers AI) |
| インフラ | Vercel、Cloudflare |
| その他 | Stripe(決済)、Resend(メール配信) |
1. ハイブリッドRAG(ベクトル検索 + 簡易GraphRAG)
なぜハイブリッドRAGを実装したのか
社労士試験は法律に関する国家資格なので、法令条文は複雑で、略称も多いです。
例えば以下のような略称が頻繁に使われます。
- 「労基法」→「労働基準法」
- 「徴収法」→「労働保険の保険料の徴収等に関する法律」
- 「第140条の66の3」のような多段「の」条文番号
そのままAIに質問すると、略称を誤解したり、条文番号を間違えたりします。これでは、受験生が混乱してしまいます。
この問題を解決するため、ハイブリッドRAGを実装しました。
ハイブリッドRAGとは
ハイブリッドRAGは、以下の2つを組み合わせたものです。
- ベクトル検索で、意味的に類似した情報を取得
- 簡易GraphRAGで、構造化したメタデータの引用関係から関連情報を確定的に取得
データ構造
以下のデータをデータベースに格納しています。
- 問題3,847問(過去11年分を一問一答形式に分解、JSON化)
- 法令条文14,267条文(62法令、JSON化)
- 引用関係(各問題のメタデータに根拠条文の情報を構造化して格納)
- ベクトル18,114個(問題 + 条文、bge-m3による1024次元)
※ 参考までに、問題データの実際に整形したJSON抜粋を以下に示します。
{
"id": "54-01_rouki_anei-Q8-B",
"question": "下記に示す事業者が...元方安全衛生管理者を選任しなければならない。",
"answer": "◯",
"explanation": "正しい。労働安全衛生法第15条の2、施行令第7条の2により、建設業で特定元方事業者は、...、20人以上のため選任義務があります。",
"metadata": {
"year": 54,
"subject_key": "01_rouki_anei",
"subject_jp": "労働基準法及び労働安全衛生法",
"law_name": "労働安全衛生法",
"question_num": 8,
"option": "B",
"related_article": "15条,令7条"
}
},
ベクトル検索の実装
Cloudflare Workers AIのbge-m3モデルでEmbeddingを生成し、Supabaseのpgvectorで類似検索を実行しています。
法令条文と過去問のベクトル検索を Promise.all で並列実行し、レスポンス速度を確保しました。
// 1) Embedding生成(Cloudflare Workers AI / bge-m3)
const embeddingResult = await runCloudflareAi<unknown>("@cf/baai/bge-m3", {
text: [query],
});
const embedding = coerceEmbedding(embeddingResult);
// 2) ベクトル検索(法令と過去問を並列で検索)
const queryEmbeddingLiteral = vectorToPgvectorLiteral(embedding);
const [lawsRes, examsRes] = await Promise.all([
supabase.rpc("match_laws", {
query_embedding: queryEmbeddingLiteral,
match_threshold: 0.5,
match_count: 5,
}),
supabase.rpc("match_exams", {
query_embedding: queryEmbeddingLiteral,
match_threshold: 0.5,
match_count: 5,
}),
]);
Supabase側では、pgvectorのコサイン距離で類似検索を行うRPC関数を定義しています。
CREATE OR REPLACE FUNCTION public.match_laws(
query_embedding extensions.vector(1024),
match_threshold double precision,
match_count integer
)
RETURNS TABLE (
id uuid,
category text,
article_number text,
title text,
content text,
explanation text,
metadata jsonb,
similarity double precision
)
LANGUAGE plpgsql
STABLE
AS $$
DECLARE
safe_threshold double precision;
safe_count integer;
BEGIN
-- 入力値の安全化
safe_threshold := LEAST(GREATEST(match_threshold, 0.0), 1.0);
safe_count := GREATEST(match_count, 0);
RETURN QUERY
SELECT
l.id, l.category, l.article_number, l.title,
l.content, l.explanation, l.metadata,
(1.0 - (l.embedding <=> query_embedding))::double precision AS similarity
FROM public.laws AS l
WHERE l.embedding IS NOT NULL
AND (1.0 - (l.embedding <=> query_embedding)) >= safe_threshold
ORDER BY (l.embedding <=> query_embedding) ASC
LIMIT safe_count;
END;
$$;
簡易GraphRAGの実装
ベクトル検索だけでは、意味的に近いが「根拠条文ではない」条文がヒットすることがあります。
そこで、ベクトル検索でヒットした過去問のメタデータから引用されている条文番号と法律名を抽出し、確定的にデータベースから取得する「簡易GraphRAG」を組み合わせました。
// 2.5) GraphRAG(確定検索)
// ベクトル検索で取得した過去問のメタデータから、関連条文番号を抽出
const examTargetNumbers = extractRelatedArticleNumbers(exams);
const targetNumbers = Array.from(
new Set([...preferredTargetNumbers, ...examTargetNumbers])
).slice(0, 30);
// 法律名を展開(略称対応、施行規則・施行令の候補も生成)
const lawNames = Array.from(
new Set(
baseLawNames.flatMap((lawName) =>
expandLawNamesForGraphSearch(lawName, relatedArticle)
)
)
).slice(0, 30);
// 条文番号と法律名の組み合わせで確定検索
if (targetNumbers.length > 0 && lawNames.length > 0) {
const graphRes = await supabase
.from("laws")
.select("id,category,article_number,title,content,explanation,metadata")
.in("article_number", targetNumbers)
.in("title", lawNames)
.limit(10);
}
この仕組みにより、ベクトル検索の「意味的な近さ」と、グラフ構造を利用した「構造的な正確さ」を両立できるように工夫しました。
法令略称の正規化
社労士試験では独特の略称が使われるため、略称辞書と法律名の展開関数を実装しました。以下はその一例です。
労働安全衛生法の施行規則だけ、労働安全衛生法施行規則ではなく「労働安全衛生規則」となっていたりするなど、かなり例外が多くて大変でした…。
// 略称と正式名称の辞書(社労士試験特有)
export const LAW_ABBREVIATIONS: Record<string, string> = {
"徴収": "労働保険の保険料の徴収等に関する法律",
"社審": "社会保険審査官及び社会保険審査会法",
"厚年": "厚生年金保険法",
"国年": "国民年金法",
"労基": "労働基準法",
"労災": "労働者災害補償保険法",
"雇保": "雇用保険法",
"健保": "健康保険法",
};
// 法律名を展開(施行規則・施行令の候補も生成)
export function expandLawNamesForGraphSearch(
lawName: string,
relatedArticleStr?: string
): string[] {
const candidates = new Set<string>();
const name = String(lawName ?? "").trim();
if (name) {
const base = name.replace(/(施行規則|規則|施行令|令)$/, "").trim();
candidates.add(name);
candidates.add(base);
// 「労働安全衛生法」は例外的に「労働安全衛生規則」となる等の特殊処理も実装
candidates.add(`${base}施行規則`);
candidates.add(`${base}施行令`);
}
// related_article から略称を拾って正式名称を追加
const related = String(relatedArticleStr ?? "").trim();
if (related) {
for (const [abbr, fullName] of Object.entries(LAW_ABBREVIATIONS)) {
if (related.includes(abbr)) {
candidates.add(fullName);
candidates.add(`${fullName}施行規則`);
candidates.add(`${fullName}施行令`);
}
}
}
return Array.from(candidates).filter(Boolean);
}
多段「の」条文番号への対応
「第140条の66の3」のような複雑な条文番号をDB形式に変換する関数も実装しました。
// 「第140条の66の3」→ "140_66_3" のようにDB形式へ変換
// 多段「の」(例: 第24条の2の2の2)にも対応
function parseArticleToDbKey(text: string): string | null {
const m = /(?:第)?([0-9]+)条((?:の[0-9]+)*)/.exec(text);
if (m) {
const base = m[1];
const suffixes = m[2]; // "の66の3" or ""
if (!suffixes) return base;
return base + suffixes.replace(/の/g, "_");
}
return null;
}
結果
ハイブリッドRAGを実装した結果、AIチューターの精度が向上しました。
- 条文番号の誤認識がほぼゼロに
- 呼称や略称の誤認識も大幅に減少
- 関連する過去問や条文も一緒に表示されるため、横断的な学習が可能に
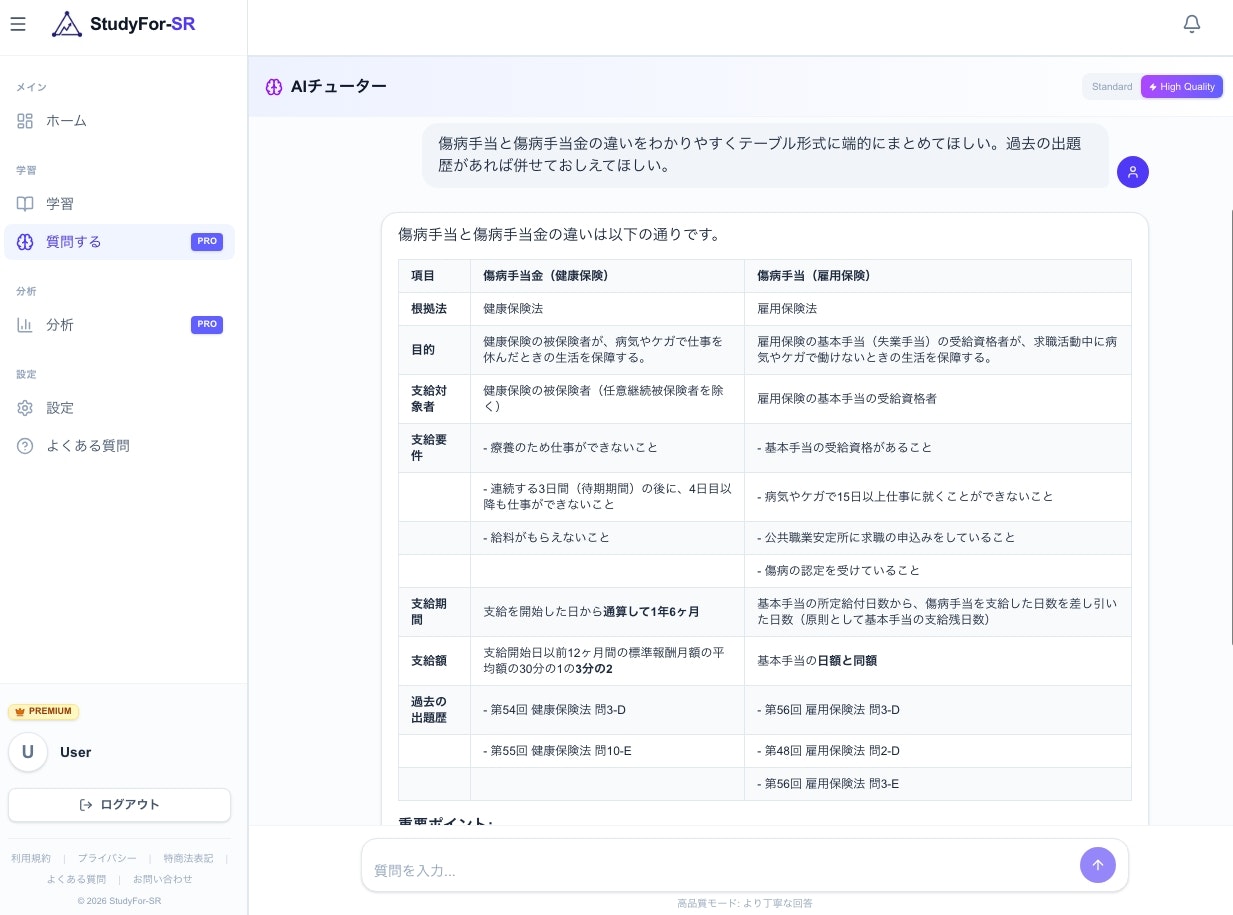
AIチューターの回答例。ベクトル検索で意味的に近い条文を取得し、GraphRAGで確定的に根拠条文を特定
2. PageRankの応用(問題&条文の重要度スコア算出)
なぜPageRankを参考にしたのか
社労士試験の範囲は膨大です。全ての条文を均等に勉強するのはどう考えても非効率です。
重要な条文を優先的に勉強すべきですが、どの条文が出題頻度が高くて重要かを判断するのは難しいです。
そこで、GoogleのPageRankアルゴリズムを参考にして、条文の重要度を客観的に算出することにしました。
PageRankとは
PageRankは、Googleが検索順位を決定するために使っているアルゴリズムです。
ウェブページ間のリンク構造を分析し、重要なページを特定するのに使われます。
オリジナルのPageRankの定式は以下の通りです。あるノード $i$ のPageRankスコア $PR(i)$ は、
$$PR(i) = \frac{1 - \alpha}{N} + \alpha \sum_{j \in B_i} \frac{w_{ji}}{\sum_{k \in O_j} w_{jk}} PR(j)$$
ここで、
- $\alpha$・・・減衰係数(damping factor)。リンクを辿り続ける確率
- $N$・・・グラフ内の全ノード数
- $B_i$・・・ノード $i$ にリンクしている(入次数の)ノード集合
- $O_j$・・・ノード $j$ からリンクされている(出次数の)ノード集合
- $w_{ji}$・・・ノード $j$ からノード $i$ へのエッジの重み
第1項 $\frac{1 - \alpha}{N}$ は「ランダムジャンプ」を表し、15%($\alpha$ = 0.85の場合) の確率でグラフ上のランダムなノードへ遷移します。
第2項は、リンク元ノードのスコアを重みに応じて分配する「投票」にあたります。
これを社労士試験に応用すると、以下のようになります。
- ウェブページが条文
- リンクが引用関係
多くの過去問から引用されている条文は、重要度が高いと判断できます。
また、重要な条文から引用されている過去問も重要と判断できます。
二部グラフの構築
法律条文と試験問題の2種類のノードを持つ二部グラフ(Bipartite Graph)を構築しました。
- 法律条文ノード集合 $L$($|L|$ = 14,267 条文)
- 試験問題ノード集合 $E$($|E|$ = 3,847 問)
グラフ $G = (L \cup E, ; \mathcal{E})$ において、エッジ集合 $\mathcal{E}$ は問題 $e \in E$ が条文 $l \in L$ を引用している場合に $(e, l)$ として張られます。
同じ条文が同一問題内で複数回引用されている場合は、エッジの重み $w_{el}$ として加算します。
$$w_{el} = \text{(問題 } e \text{ が条文 } l \text{ を引用している回数)}$$
この重みにより、頻繁に引用される条文はPageRank計算でより強い投票権を持つようになります。
graph = nx.Graph()
# 法律条文ノードの追加
for law in laws:
node_id = f"law:{law['id']}"
graph.add_node(node_id, kind="law", law_id=law["id"])
# 試験問題ノードの追加
for exam in exams:
node_id = f"exam:{exam['id']}"
graph.add_node(node_id, kind="exam", exam_id=exam["id"])
# 引用関係のエッジを追加(メタデータの related_article を解析)
for exam in exams:
meta = _parse_metadata(exam.get("metadata"))
related_raw = meta.get("related_article")
law_name_value = meta.get("law_name")
# 「規則18条」のような相対参照を「労働安全衛生規則 第18条」に解決
candidate_law_names, target_article = _resolve_target_law_candidates(
base_law_name, ref_str
)
for law_id in found_law_ids:
law_node = law_nodes_by_id.get(law_id)
if law_node:
# 重複引用は重みとして加算(PageRankでより強い投票権になる)
existing = graph.get_edge_data(exam_node, law_node) or {}
weight = float(existing.get("weight", 0.0)) + 1.0
graph.add_edge(exam_node, law_node, weight=weight)
重要度スコアの計算
networkxライブラリを使って、重み付きPageRankを計算しました。
冪乗法(Power Method)により、遷移確率行列 $M$ の最大固有ベクトルを求め、定常状態分布 $\boldsymbol{\pi}$ に収束させています。
具体的には、初期ベクトル $\boldsymbol{\pi}^{(0)} = \frac{1}{N}\mathbf{1}$ から以下の反復を行います。
$$\boldsymbol{\pi}^{(t+1)} = \alpha , M^\top \boldsymbol{\pi}^{(t)} + \frac{1 - \alpha}{N} \mathbf{1}$$
$|\boldsymbol{\pi}^{(t+1)} - \boldsymbol{\pi}^{(t)}|$ が十分小さくなったところで収束と判定し、各ノード $i$ の定常スコア $\pi_i$ が重要度スコアとなります。
# 重み付きPageRankの計算(冪乗法)
# alpha=0.85 → 85%の確率でリンクを辿り、15%でランダムにジャンプ
scores = nx.pagerank(graph, alpha=0.85, weight="weight")
# 計算結果を法律用と問題用に分離
law_scores = {}
exam_scores = {}
for node_id, score in scores.items():
if node_id.startswith("law:"):
law_scores[node_id[len("law:"):]] = score
elif node_id.startswith("exam:"):
exam_scores[node_id[len("exam:"):]] = score
重要度スコアの正規化
PageRankの生スコアは全ノードの総和が $1$ となるように正規化されているため、個々の値は非常に小さくなります(例: $\pi_i \approx 0.002$)。
そこで、全スコアの平均値 $\bar{\pi}$ が $1.0$ になるようにスケーリングしました。
$$\hat{\pi}_i = \frac{\pi_i}{\bar{\pi}}$$
$$\quad \bar{\pi} = \frac{1}{N}\sum_{i=1}^{N} \pi_i$$
# 全スコアの平均値が1.0になるように正規化
if scores:
avg_score = sum(scores.values()) / len(scores)
if avg_score > 0:
for k in scores:
scores[k] = scores[k] / avg_score
これにより、
- $\hat{\pi}_i > 1.0$ の条文は「平均よりも重要」
- $\hat{\pi}_i < 1.0$ は「平均以下」
と判断できるようになりました。
結果
PageRankを実装した結果、以下のような効果がありました。
- 重要な条文と問題が一目で分かるようになった
- 過去問と条文の関係性が可視化され、効率的に学習できるようになった

PageRankの結果例(スコアが高いほど重要な問題)
3. ブラック・ショールズモデル(AI合格可能性予測)
なぜブラック・ショールズモデル(B-Sモデル)を実装したのか
受験生の最大の悩みは「毎日勉強しているけど、本当に合格に近づいているのか分からない」という不安です。
この不安を解消するため、現在の学習ペースから合格確率を予測する機能を実装しました。
しかし、開発初期はユーザーデータがゼロです。機械学習モデルは使えません。
また、計算コストの比較的小さなものを選定する必要があり金融工学のブラック・ショールズモデルを応用することにしました。
ブラック・ショールズモデルとは
ブラック・ショールズモデルは、オプション価格を計算するための数理モデルです。
原資産価格 $S$ が幾何ブラウン運動に従うと仮定します。
$$dS = \mu S , dt + \sigma S , dW$$
ここで $\mu$ はドリフト(期待成長率)、$\sigma$ はボラティリティ(不確実性)、$dW$ はウィーナー過程です。
この確率微分方程式のもとで、将来の不確実性を考慮しつつ現在の価値を算出します。
これを社労士試験の学習に応用すると、以下のようになります。
- 原資産価格 $S$ → 現在の正答率
- 行使価格 $K$ → 合格ライン
- 満期 $T$ → 試験日までの残り日数(年換算)
変数の対応
| B-S変数 | 学習での意味 | 具体例 |
|---|---|---|
| S(原資産価格) | 現在の正答率 | 70% |
| K(行使価格) | 合格ライン | 78% |
| T(満期) | 試験日までの残り日数(年換算) | 166日 / 365 |
| σ(ボラティリティ) | 学習の不確実性 | 0.35 |
| r(リスクフリーレート) | 基礎成長率 | 0.03 |
PASS_LINE(合格ライン)の導出
社労士試験は5肢択一式です。ランダムに解答しても正解する確率は20%あります。
本試験の合格ライン(65%)を取るユーザーの「真の理解度 p」を逆算すると、以下のようになります。
$$E_5 = p + \frac{1-p}{5}$$
合格ライン $E_5 = 0.65$ を代入して真の理解度 $p$ を求めます。
$$0.65 = p + \frac{1-p}{5} = p + 0.2 - 0.2p = 0.8p + 0.2$$
$$0.8p = 0.45 \quad \Rightarrow \quad \boxed{p = 0.5625}$$
つまり、本試験で65%の得点を取るユーザーの真の理解度は 56.25% です。
StudyFor-SRは○×形式(2肢択一)なので、この理解度 $p = 0.5625$ で○×問題を解いた場合の期待正答率は以下の通りです。
$$E_2 = p + \frac{1-p}{2} = 0.5625 + \frac{0.4375}{2} = \boxed{0.78125}$$
したがって、本システムにおける数学的に妥当な合格ラインを PASS_LINE = 0.78(78%) と定義しました。
ブラック・ショールズモデルの実装
合格確率にはリスク中立確率 $N(d_2)$ を採用しています。
これは「現在の学習ペースのまま試験日を迎えたときに、合格ライン以上を取れる確率」として読み替えることができます。
まず $d_1$ と $d_2$ を以下のように定義します。
$$d_1 = \frac{\ln(S/K) + (r + \frac{1}{2}\sigma^2)T}{\sigma\sqrt{T}}$$
$$d_2 = d_1 - \sigma\sqrt{T}$$
ここで、
- $S$・・・現在の正答率
- $K$・・・合格ライン(PASS_LINE = 0.78)
- $T$・・・試験日までの残り日数 / 365(年換算)
- $\sigma = 0.35$・・・学習のボラティリティ
- $r = 0.03$・・・基礎成長率(リスクフリーレート)
合格確率 $P$ は、標準正規分布の累積分布関数 $N(\cdot)$ を用いて、
$$P = N(d_2) = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{d_2} e^{-\frac{x^2}{2}} dx$$
と計算できます。$d_2 > 0$ であれば合格確率は50%を超え、$d_2$ が大きいほど合格確率が高くなるといった仕組みです。
import { erf } from "mathjs";
const SIGMA = 0.35; // ボラティリティ(学習の不確実性)
const RISK_FREE_RATE = 0.03; // リスクフリーレート(基礎成長率)
const STUDY_SESSION_SCORE_EFFECT = 0.0022; // 1日の学習効果量(2時間想定)
// 標準正規分布の累積分布関数
function normalCDF(x: number): number {
return 0.5 * (1 + (erf(x / Math.SQRT2) as number));
}
function calcD1(S: number, K: number, T: number): number {
return (
(Math.log(S / K) + (RISK_FREE_RATE + 0.5 * SIGMA ** 2) * T) /
(SIGMA * Math.sqrt(T))
);
}
function calcD2(d1: number, T: number): number {
return d1 - SIGMA * Math.sqrt(T);
}
export function calculatePassProbability(
input: PassProbabilityInput
): PassProbabilityResult {
const { passLine, daysLeft } = input;
const S = Math.max(input.currentScore, 0.001);
const K = Math.max(passLine, 0.001);
const T = Math.max(daysLeft, 1) / 365;
// 合格確率 = N(d2)(リスク中立確率)
const d1 = calcD1(S, K, T);
const d2 = calcD2(d1, T);
const probability = normalCDF(d2) * 100;
// studyGain(Δ)… 今日の学習目標を達成した場合の確率上昇幅
const sGain = Math.max(S + STUDY_SESSION_SCORE_EFFECT, 0.001);
const d1Gain = calcD1(sGain, K, T);
const d2Gain = calcD2(d1Gain, T);
const studyGain = Math.max(normalCDF(d2Gain) * 100 - probability, 0);
// skipLoss(Θ)… 1日サボった場合の確率減少幅
const TLoss = Math.max(daysLeft - 1, 1) / 365;
const d1Loss = calcD1(S, K, TLoss);
const d2Loss = calcD2(d1Loss, TLoss);
const skipLoss = Math.max(probability - normalCDF(d2Loss) * 100, 0);
return {
probability: Math.min(Math.max(probability, 0), 100),
studyGain: Math.round(studyGain * 100) / 100,
skipLoss: Math.round(skipLoss * 100) / 100,
};
}
Δ(デルタ)とΘ(シータ)の仕組み
ユーザーのモチベーションを維持するため、以下の指標を使いました。
Δ(デルタ) ・・・学習効率みたいなもので、今日の学習目標(約2時間のセッション)を達成すると、合格確率がどれだけ上がるか。
1日の学習効果量を $\delta_s = 0.0022$(2時間想定)とすると、
$$\Delta = N\bigl(d_2(S + \delta_s, K, T)\bigr) - N\bigl(d_2(S, K, T)\bigr)$$
Θ(シータ) ・・・1日サボると、時間の経過により合格確率がどれだけ下がるか。
$$\Theta = N\bigl(d_2(S, K, T)\bigr) - N\bigl(d_2(S, K, T - \tfrac{1}{365})\bigr)$$
ブラック・ショールズモデルの非線形性によって、試験日が近く($T \to 0$)、かつ実力が合格ラインに近い($S \approx K$)ほど $\Delta$ (つまり学習の効率)は大きくなります。
これは $\sigma\sqrt{T}$ が小さくなると $d_2$ の変化に対する $N(d_2)$ の感度が高まるためです。
逆に $\Theta$ (サボったリスクみたいなもの)は試験直前に急増し、「直前期の1日の重み」を数学的な事実としてユーザーへ表示できるようにしています。
結果
ブラック・ショールズモデルを実装した結果、以下の効果がありました。
- 自分の実力の現在地を数値で把握できるようになった
- 「今日勉強すると、確率が上がる」という実感を持てるようになった
- 「サボると確率が下がる」という事実で、時間が経過することの重みを数値で認識できるようになった
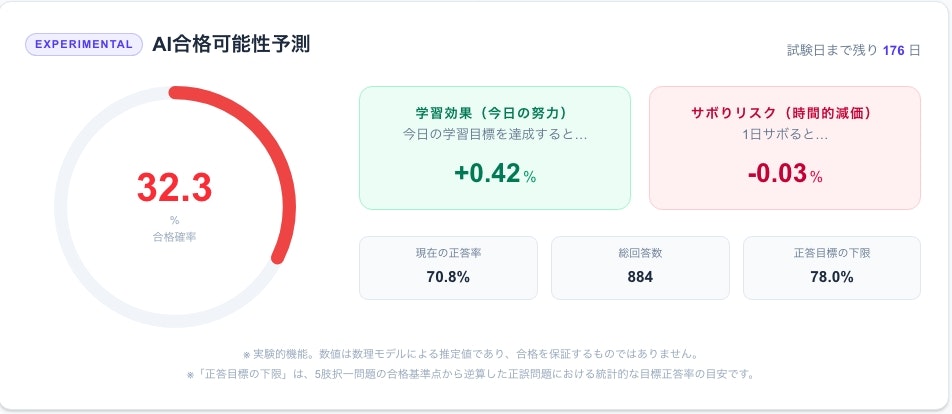
ブラック・ショールズモデルの結果例(合格確率、Δ学習効果とΘサボりリスクを表示)
将来のアップデートに向けてのロードマップ(※未定)
ブラック・ショールズモデルは、少ないデータでも動作するよう、かつ計算コストが低い「暫定版」です。
ユーザーが増えるにつれて、段階的に精度向上を図りたいと思っています。
| Phase | 対象ユーザー数 | モデル | 特徴 |
|---|---|---|---|
| Phase 1(現在) | 0〜30人 | ブラック・ショールズモデル | データゼロでも動作 |
| Phase 2(未定) | 30〜100人 | 忘却曲線 + Logisticモデル | 個人差を考慮 |
| Phase 3(未定) | 100人〜 | 機械学習モデル | 蓄積データから高精度予測 |
苦労した点
1. データの構造化
社労士試験の過去問と法令条文を、全てJSON化する必要がありました。
問題3,847問と条文14,267条文の整形とデータの構造化。これに、全開発時間の7割くらい費やしたと思います。
はっきり言って、苦行以外の何物でもありませんでした…。
特に、条文の構造化は、条文番号の複雑さ(多段「の」など)や、例外の多さなど、何度も言いますがかなり大変でした。
「自分は一体何をやっているんだろう」と何度も自問自答をしたのをはっきりと覚えています。
しかし、この苦行があったからこそ、ハイブリッドRAGやPageRankの実装が可能になったので、やむを得ない部分もあったと思います。
2. ベクトル生成のコスト
18,114個のベクトルデータ(1024次元)を生成する必要がありました。
OpenAIのEmbedding APIを使うとコストが高すぎるため、エンべディングモデルはCloudflare Workers AIのbge-m3を使いました。
幸運にも、無料枠が結構大きかったこともあり、ここでのコスト発生はゼロで乗り切りました。
3. PageRankの計算時間
二部グラフのノード数がそれなりにあるため、PageRankの計算には一回あたり20〜30分位の時間がかかります。
Pythonのnetworkxライブラリを使って、バッチ処理で計算するのでかなり簡素化できたように思います。ライブラリにだいぶ助けられました。
4. B-Sモデルのパラメータ調整
SIGMA(ボラティリティ)やRISK_FREE_RATE(リスクフリーレート)の値を、どう設定するか悩みました。
ここでは詳しく述べませんが試行錯誤の結果、SIGMA = 0.35、RISK_FREE_RATE = 0.03 に落ち着きました。
人間の学習のボラティリティは一般的な0.2よりも高めに設定しています。
セキュリティ対策
ゼロトラスト・アーキテクチャを採用し、以下のセキュリティ対策を実施しました。
- Auth Guard(認証チェック)
- Plan Guard(プラン制限チェック)
- IDOR対策(他人のデータにアクセスできないようにする)
- 型ガード(TypeScriptの型チェック)
- RLS(Row Level Security、Supabase)
さいごに
数ヶ月かかりましたが、なんとか社労士試験AI学習アプリ「StudyFor-SR」をリリースできました。
ハイブリッドRAG、PageRankの応用、ブラック・ショールズモデルを実装し、学習の「不安」と「非効率」をテクノロジーで解決することを課題に据えて、ここまで漕ぎ着けることができました。
もし、資格試験や専門分野で類似のAI学習アプリを作りたい方がいれば、少しでも参考になる部分があればいいなと思っています。
現時点ではβ版なので、随時アップデートしていく予定です。
ここまでお読みいただき、ありがとうございました!