はじめに
こんにちは。
タイトルのとおり、日本語LLMをファインチューニングした自作LoRAモデルを作成し、そのモデルを使ってAITuber(今回はYoutubeを使ったAIVtuber)を Google Colab で動かしてみたので、実際におこなった一連の流れをアウトプットしたいと思います。
内容は慎重に確認して発信していますが、私はエンジニアではないため、つたない部分や至らない点も多いかと思います。どうかご容赦いただければと思います。
独学者の勉強過程のアウトプットの一環程度の認識でご覧いただければ幸いです。また、私のように独学で勉強中の方にとって、少しでも参考になればうれしいです。
思った以上に長くなってしまいそうなので、先にこのシステムの結論を書いておきます。
結論
Google Colabでもごく短時間ならAItuberのLive配信可能だが、以下の理由からあまり実用的ではないと感じた。
- 配信は上手くいったが、3Dモデルのリップシンク(口パク)は失敗した。
原因:環境の問題なのか、設定の問題なのかは原因がつかめておらず不明。 - Google Colabでも可能だが、長時間配信はできない
理由:ランタイムが切れるため、そのたびに最初からコメントを取得して応答しようとする。
AITuber とは何か
あまりAITuberというワードになじみがない方も多いかと思いますので、簡単に説明します。
AITuber(AI + VTuber)とは、AI技術を使って、自動的にコンテンツを生成したり配信するバーチャルYouTuberのことを指すのが一般的です。通常のVTuberが人間の配信者によって操作されているのに対して、AITuberはテキスト生成や音声合成などの技術を組み合わせてチャットへの自動応答(さらに高度なものであればゲーム配信)をしたりしています。YoutubeやTwitchで配信しているNeuro-samaが界隈では有名だと思います。
実装のきっかけ
- LLMに関する学習をしていたので、独自モデルを作成して何かアウトプットできないかと思ったのが最初のきっかけです
- なぜ、Google Colabなのかというと私のローカル環境があまりにも貧弱(メインPCが10年落ち。もちろんGPUなし、いまだにSSDではなくHDD)なので、これしか選択肢がなかったためです
- ローカル環境でAITuberを作成したという記事や情報を見かけることはあったが、Google Colabかつ自作LLMを使って実装したという情報が見つからなかったので、チャレンジしてみようと思ったからです
本記事の内容と対象読者
この記事では、日本語LLMの自作LoRAモデルとテキスト音声合成(TTS)を組み合わせて、YouTube配信のライブチャットに自動で応答するAITuberシステムをGoogle Colabで実装し、実際に配信するまでの過程について、私が取り組んだ過程を共有したいと思っています。
- 基本的なPythonプログラミングに関する知識を持っている方
- 機械学習や深層学習に関して少しでも学んだことがある方
- 自作LLMを使って個人的に遊んでみたい方
- 私のような実務未経験者で興味のおもむくままに学習したことを実装してアウトプットしたい方
- AITuberの実装に興味がある方
専門的で高度な知識は持ち合わせていないので、理論よりも実際に使用したPythonコードや各種ツールとその設定についての内容をお伝えできればと思っています。
また、使用したコードは全て公開しますので、興味のある方はよければ触って遊んでみてください。
ここはこうした方がいいなどのご意見がありましたら、ぜひともアドバイスいただけるとうれしいです。
使用したツールについて
Google colab Pro (A100 & L4)
- 日本語LLMのファインチューニング(A100を使用)
- YouTube Live配信からライブチャットメッセージを取得し、LLMで応答文章を生成し、さらに生成された文章をVTuberの音声として再生(L4を使用)
Hugging Face
- 使用したベースモデル(tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1)
- ベースモデルをFineTunigしたLoRAモデル(yf591/Llama3SW8B_it_v0.1_qlora_FukuyamaBen)
- 広島県の方言(福山弁)を応答生成するように自作データセットを使ってファインチューニングしたモデル
※あとでコードも交えて作成過程を解説します。
- 広島県の方言(福山弁)を応答生成するように自作データセットを使ってファインチューニングしたモデル
VOICEVOX
- 無料で使える中品質なテキスト読み上げ・歌声合成ソフトウェア
VRoid Studio
- 3Dモデル(.vrm形式)の作成に使用
VMagicMirror
- VRMファイルをキーボードとマウスだけで動かせるWindows向けソフトでOBSとの連携に使用
OBS(Open Broadcaster Software®️)
- 映像や音声を統合してライブ配信や録画が行えるPC用の配信ソフト
Google Colabを用いたAITuberシステムの全体像
システム全体像(完全版)

システム全体像(LLMのファインチューニング工程を除いた場合)

日本語LLMのファインチューニング
まずは、以下の工程でAITuberの応答生成の核となるLoRAモデルを作成しました。
Reference
- QLORA:Efficient Finetuning of Quantized LLMs
- 【Llama3】SFTTrainerで簡単ファインチューニング(QLoRA)
- huggingface/TRLのSFTTrainerクラスを使えばLLMのInstruction Tuningのコードがスッキリ書けてとても便利です
- TRL - Transformer Reinforcement Learning
- Google Colabによる Llama3.2 / Qwen2.5 の ファインチューニング・ハンズオン
Llama-3.1-Swallow-8B-Instruct-v0.1のQLoRA ファインチューニング
1. 環境セットアップ(Google Colab pro A100GPUを使用)
- GPUの確認(コード省略)
- Googleドライブのマウント(コード省略)
- 作業ディレクトリの変更(コード省略)
- 基本パラメータの設定
-
model_idは今回使ったベースモデルです(tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1)
model_id = "tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1" # 使用するモデルのID peft_name = "Llama3.1-SW-8B-it-v0.1_A100_1rep_qlora" # ファインチューニング後のモデルを保存する際の名前 output_dir = "output_neftune" # 学習済みモデルの出力ディレクトリ -
2. ライブラリのインストール
- 必要なライブラリのインストール
!pip install peft # PEFT(Parameter-Efficient Fine-Tuning)ライブラリ !pip install transformers==4.43.3 !pip install datasets==2.14.5 !pip install accelerate bitsandbytes evaluate !pip install trl==0.12.0 # TRL(Transformer Reinforcement Learning)ライブラリ,(バージョンを指定) !pip install flash-attn - ライブラリのインポート
import torch # PyTorchライブラリ from torch import cuda, bfloat16 # PyTorchのCUDA, bfloat16関連の機能 from transformers import ( # Transformersライブラリから必要なクラスをインポート AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, HfArgumentParser, TrainingArguments, pipeline, logging ) from datasets import load_dataset # Datasetsライブラリからload_dataset関数をインポート from peft import LoraConfig, PeftModel # PEFTライブラリから必要なクラスをインポート from trl import SFTTrainer # TRLライブラリからSFTTrainerをインポート - Hugging Faceへのログイン
from huggingface_hub import login # Hugging Face Hubのlogin関数をインポート from google.colab import userdata # Google Colabのuserdataモジュールをインポート login(userdata.get('HF_TOKEN')) # Colabのシークレットキーを使用(Hugging FaceのAPIトークンを設定しておく必要があります。)
3. モデルの準備
- 量子化設定
最初は8bit量子化でいこうと思ったのですが、精度ではなく計算速度の向上を優先して4bitまで量子化したものを使用しました。量子化を一言でいうと「モデルを軽量化して、少ないリソースでも動かしやすくするための工夫」的なイメージです。 - モデルとトークナイザーのロード
# 量子化設定 (量子化に関する設定) bnb_config = BitsAndBytesConfig( # 量子化設定用のオブジェクトを作成開始 load_in_4bit=True, # モデルを4ビットで読み込む設定 (メモリ削減) bnb_4bit_use_double_quant=True, # 4ビット量子化で二重量子化を使用 (精度向上) bnb_4bit_quant_type="nf4", # 4ビット量子化のタイプをNF4形式に指定 bnb_4bit_compute_dtype=torch.bfloat16 # 量子化中の計算精度をbfloat16に指定 ) # モデルの設定 (モデル読み込みの設定) model = AutoModelForCausalLM.from_pretrained( # 事前学習済みモデルをロード開始 model_id, # 使用するモデルのID (Hugging Face Hub上の名前など) trust_remote_code=True, # リモート(Hub上)のカスタムコード実行を許可 quantization_config=bnb_config,# 上記で定義した量子化設定を適用 device_map='auto', # モデルをGPU/CPUに自動で割り当て torch_dtype=torch.bfloat16, # モデルの計算時のデータ型をbfloat16に指定 attn_implementation="flash_attention_2" # 高速化技術FlashAttention2 ) # tokenizerの設定 (トークナイザー読み込みの設定) tokenizer = AutoTokenizer.from_pretrained( # 事前学習済みトークナイザーをロード開始 model_id, # 使用するトークナイザーのID (モデルと通常同じ) padding_side="right", # パディング(穴埋め)をシーケンスの右側に行う設定 add_eos_token=True # 文末に終了を示すEOSトークンを自動で追加する設定 ) if tokenizer.pad_token_id is None: # もしパディング用トークンIDが未設定なら tokenizer.pad_token_id = tokenizer.eos_token_id # 終了トークンIDをパディング用IDとして使う
4. モデルの動作確認
- 初期状態での推論テスト
# テスト用のメッセージを作成 (ここからモデルへの入力メッセージを作成) messages = [ # チャット形式のメッセージリストを作成開始 {"role": "system", "content": "あなたは常に日本語で応答する優秀なアシスタントです。"}, # システムメッセージ(AIの役割指示) {"role": "user", "content": "広島県の美味しい食べ物や有名な建造物は何ですか?"}, # ユーザーからの質問メッセージ ] # メッセージリスト作成完了 # 入力メッセージをトークン化し、モデルのデバイスに転送 (ここから入力データをモデル用に変換) input_ids = tokenizer.apply_chat_template( # チャットテンプレートを適用してトークンIDに変換開始 messages, # 変換するメッセージリスト add_generation_prompt=True, # AIの応答を促すプロンプトを追加する設定 return_tensors="pt" # 結果をPyTorchテンソル形式で返す設定 ).to(model.device) # 変換結果をモデルと同じデバイス(GPU等)に移動 # 文章生成を終了するトークンIDを設定 (ここで生成停止の条件を設定) terminators = [ # 生成終了のトリガーとなるトークンIDのリストを作成開始 tokenizer.eos_token_id, # 標準の終了(EOS)トークンID tokenizer.convert_tokens_to_ids("<|eot_id|>") # 特定の終了用トークン文字列をIDに変換して追加 ] # 生成終了トークンIDリスト作成完了 # モデルを使用して文章を生成 (ここから実際に文章を生成) outputs = model.generate( # モデルの`generate`メソッドで文章生成を開始 input_ids, # 生成の元となる入力トークンID max_new_tokens=256, # 生成する新しいトークン数の上限を256に設定 eos_token_id=terminators, # 生成停止のトリガーとなるトークンID(リスト)を指定 do_sample=True, # 次のトークンを確率的にサンプリングする方式を使う temperature=0.8, # サンプリングのランダム性を調整 (低いほど決定的) top_p=0.8, # Top-pサンプリングを使用 (累積確率0.8までの候補から選ぶ) pad_token_id=tokenizer.eos_token_id, # 生成中に使うパディングトークンIDを指定 (EOSと同じ) attention_mask=torch.ones(input_ids.shape, dtype=torch.long).cuda(), # 入力部分全体に注意を向けるマスクを作成しGPUへ ) # 文章生成完了、結果を`outputs`に格納 # 生成されたトークンからレスポンスを抽出 (ここから生成結果の後処理) response = outputs[0][input_ids.shape[-1]:] # 生成結果(outputsの最初の要素)から入力部分を除いた応答部分を抽出 # 生成されたレスポンスを整形して表示 (ここから結果を読みやすく表示) import textwrap # テキストの折り返し用ライブラリをインポート s = tokenizer.decode(response, skip_special_tokens=True) # 応答部分のトークンIDを文字列にデコード (特殊トークンは削除) s_wrap_list = textwrap.wrap(s, 50) # デコードした文字列を50文字ごとに折り返してリスト化 print('\n'.join(s_wrap_list)) # 折り返した文字列リストを改行で繋げて表示
5. データセットの準備
- データセットのロード
- 私はMyDrive上の下記Path内に自作した
Fukuyama_dialect_dataset.json(福山弁のデータセット)を格納しました。 -
参考
-
福山弁は、広島県福山市を中心とした備後地方(広島県と岡山県の県境あたり)で話されている方言です。
-
特徴:
- 「〜じゃ」「〜じゃけぇ」「〜じゃろう」など、「じゃ」を多用。
- 「〜じゃけぇ」は、「〜だから」という意味でよく使う。
-
福山弁の例:
- 「今日は帰らんといけんのんじゃ」:今日は帰らなければならないんだ。
- 「疲れたけぇ、休もうや」:疲れたから、休もうよ。
- 「なにしよんな」:何をしているの?
- 「うち、〇〇君じゃないとだめじゃけぇ」:私は〇〇君じゃないとダメなの。
-
-
福山弁は、広島県福山市を中心とした備後地方(広島県と岡山県の県境あたり)で話されている方言です。
- 私はMyDrive上の下記Path内に自作した
※この学習用データセットの公開予定はないことご了承ください。
# データセットの格納場所のpath
/content/drive/MyDrive/Colab_Notebooks/llm_toolkit_google_colab/Instruction_tuning_QLoRA/dataset/Fukuyama_dialect_dataset.json
# ローカル(MyDrive上)にあるデータセットをロード
dataset = load_dataset("./dataset", split="train") # データセットは、このNotebookが実行されるディレクトリにdatasetという名前のフォルダがある想定
- データセットのフォーマット
# データセットの各要素を、チャット形式のメッセージに変換する関数 def formatting_func(example): messages = [ {'role': "system",'content': "あなたは日本語で回答するアシスタントです"}, {'role': "user",'content': example["instruction"]}, {'role': "assistant",'content': example["output"]} ] return tokenizer.apply_chat_template(messages, tokenize=False) # データセットの各要素を更新する関数 # フォーマットされたテキストを"text"キーに追加し、不要なキーを削除 def update_dataset(example): example["text"] = formatting_func(example) for field in ["index", "category", "instruction", "input", "output"]: example.pop(field, None) return example # データセットを更新 dataset = dataset.map(update_dataset) tokenizer.pad_token_id = tokenizer.eos_token_id
6. QLoRA設定
- 線形層の名前の取得
import bitsandbytes as bnb # モデルのすべての線形層の名前を取得する関数 def find_all_linear_names(model): target_class = bnb.nn.Linear4bit linear_layer_names = set() for name_list, module in model.named_modules(): if isinstance(module, target_class): names = name_list.split('.') layer_name = names[-1] if len(names) > 1 else names[0] linear_layer_names.add(layer_name) if 'lm_head' in linear_layer_names: linear_layer_names.remove('lm_head') return list(linear_layer_names) target_modules = find_all_linear_names(model) # 線形層の名前を取得 print(target_modules) # 線形層の名前を表示 - LoRAの設定
peft_config = LoraConfig( r=8, # LoRAのランク lora_alpha=16, # LoRAのアルファ値 lora_dropout=0.05, # LoRAのドロップアウト率 target_modules = target_modules, # LoRAを適用するモジュール bias="none", # バイアス項を使用しない task_type="CAUSAL_LM", # タスクの種類 modules_to_save=["embed_tokens"], # 学習後に保存するモジュール )
7. 学習設定
- 学習引数の設定
# 学習中の評価、保存、ロギングを行う間隔を設定 eval_steps = 20 save_steps = 20 logging_steps = 20 # 学習引数の設定 training_arguments = TrainingArguments( bf16=True, # bfloat16を使用 per_device_train_batch_size=4, # デバイスごとのバッチサイズ gradient_accumulation_steps=16, # 勾配累積ステップ数 num_train_epochs=1, # 学習エポック数 optim="adamw_torch_fused", # 最適化アルゴリズム learning_rate=2e-4, # 学習率 lr_scheduler_type="cosine", # 学習率スケジューラ weight_decay=0.01, # 重み減衰 warmup_steps=100, # ウォームアップステップ数 group_by_length=True, # 長さでグループ化 report_to="none", # wandbへのレポートを無効化 logging_steps=logging_steps, # ログの記録間隔 eval_steps=eval_steps, # 評価間隔 save_steps=save_steps, # モデルの保存間隔 output_dir=output_dir, # 学習済みモデルの出力ディレクトリ save_total_limit=3, # 保存するモデルの最大数 push_to_hub=False, # Hugging Face Hubへのアップロードを無効化 auto_find_batch_size=True # GPUメモリのオーバーフロー防止(バッチサイズを自動で調整) )
8. ファインチューニング
- SFTTrainerによるファインチューニング
# SFTTrainerの初期化 trainer = SFTTrainer( model=model, # モデル tokenizer=tokenizer, # トークナイザー train_dataset=dataset, # 学習データセット dataset_text_field="text", # データセットのテキストフィールド peft_config=peft_config, # PEFTの設定 args=training_arguments, # 学習引数 max_seq_length=1024, # 最大シーケンス長 packing=True, # パッキングを使用 neftune_noise_alpha=5, # NEFTune設定, NEFTuneノイズアルファ値 )%%time # 学習中に警告を抑制するためにキャッシュを使用しない設定にし、学習後にキャッシュを有効にする。 model.config.use_cache = False trainer.train() model.config.use_cache = True # 学習したQLoRAモデルを保存 trainer.model.save_pretrained(peft_name)
9. LoRAモデルをいったんHugging Faceへアップロード
これで一通りのファインチューニングが終わったのでHugging Faceの自分のアカウントにアップロードしました。
※学習結果はHugging Faceの以下のページに掲載しておりますので興味があればご覧くだい。
yf591/Llama3SW8B_it_v0.1_qlora_FukuyamaBen
DPOや、強化学習のRLHFやPPOなども試みたのですが、VRAMのクラッシュやエラーに見舞われて成功しませんでした。私の知識が足らず適切な設定が出来なかったため、いずれ再チャレンジしたいと思います。
ここまでで、ようやくYoutube Live のチャットへの応答生成に使うLoRAモデルの準備が完了です!
次の工程は3Dモデル(.VRM形式ファイル)の作成です。
3Dモデル(.VRM形式ファイル)の作成
VRoid Studio
3Dキャラクター制作のためのソフトウェアは色々ある中で、私は「VRoid Studio」を
選んでみました。最初はStable Diffusionで画像を生成して、その2D画像をもとにBlenderで3Dモデル生成にもチャレンジしたのですが、時間がかかるのと今回のチャレンジの趣旨から外れると思ったため、3Dモデル作成ではもっともメジャーだと思われるこちらのソフトを使うことにしました。
キャラ設定に凝ってしまうと時間がいくらあっても足りないですが、直感的に操作できて簡単に自分用の3Dモデルを作れました。以下がその手順です。
1. ソフトの起動
起動したら以下のような画面が現れるので画面左上の「新規作成」をクリック

2. ベースの選択
女性 or 男性 のいずれかを選択してクリック

3. 3Dモデルの作成
顔、髪型、体型、衣装などたくさんの種類があり組み合わせて独自の3Dモデルをデザイン

4. 3Dモデルのデザイン完了
画面右上のカメラアイコンの右の↑矢印アイコンをクリックして、VRMエクスポートを選択

5. 3Dモデルのエクスポート
画面右側の青い「エクスポート」ボタンをクリック

6. VRMエクスポート設定
タイトルと作者を入力後、下にスクロールして青い「エクスポート」ボタンをクリック


これで、VRM形式ファイルの3Dモデルの作成が完了です!
3Dモデルの起動
VMagicMirror
3Dモデルを動かすソフトはこれもたくさんありました。VSeeFaceや3teneFREE V4も試しましたが、なんとなく使いやすそうでしっくりきたのがVMagicMirrorだったのでこれを選択しました。
1. VMagicMirror起動
起動するとこのような画面が開くので「PC上のファイルをダウンロード」をクリックして、3Dモデル(.vrm形式)を読み込みの設定に移りました。
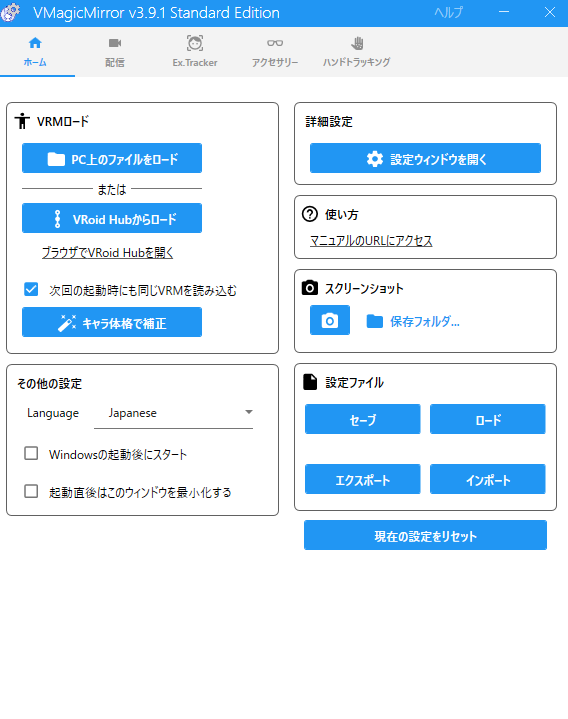
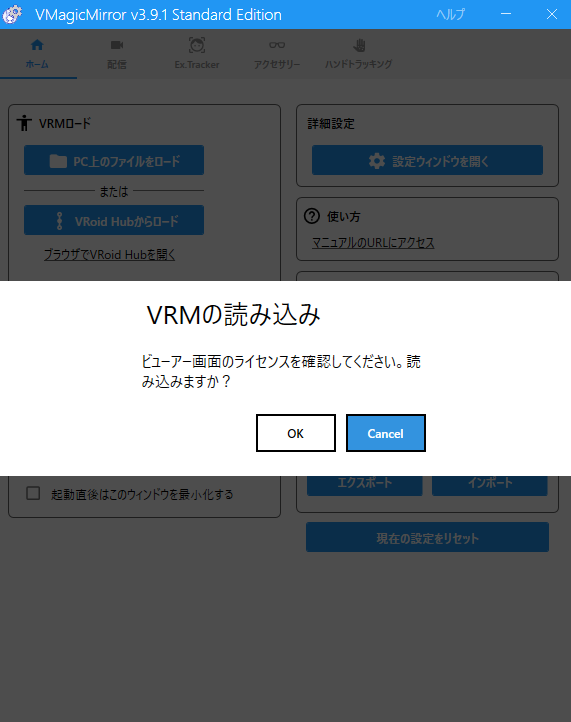
2. VRMの読み込み
「OK」をクリックして読み込み完了です。
3. 各種の設定
ちなみに、私は以下のように設定しました。

ライブ配信のための設定
Youtubeの設定
1. youtubeアカウントからyoutube Studioを開き「ライブ配信を開始」をクリック

2. 配信の作成
左サイドバーの最下段の「管理」をクリック

「タイトル」と「説明」を記入

サムネイル画像を設定して、「いいえ、子ども向けではありません」にチェックを入れて「次へ」をクリック

以下のように設定して、「次へ」をクリック

スケジュールを適当に決めて「完了」をクリック

これでYoutubeの設定は一応完了。
次にGoogle Cloud でYoutube APIキーの作成を行いました。
Youtube API キーの取得
Google Cloudのトップページを開き、新しいプロジェクトを作成したのち、「APIとサービス」をクリックします。そして、左サイドバーからライブラリに移動します。
このライブラリ画面の検索バーで「youtube」と入力して検索
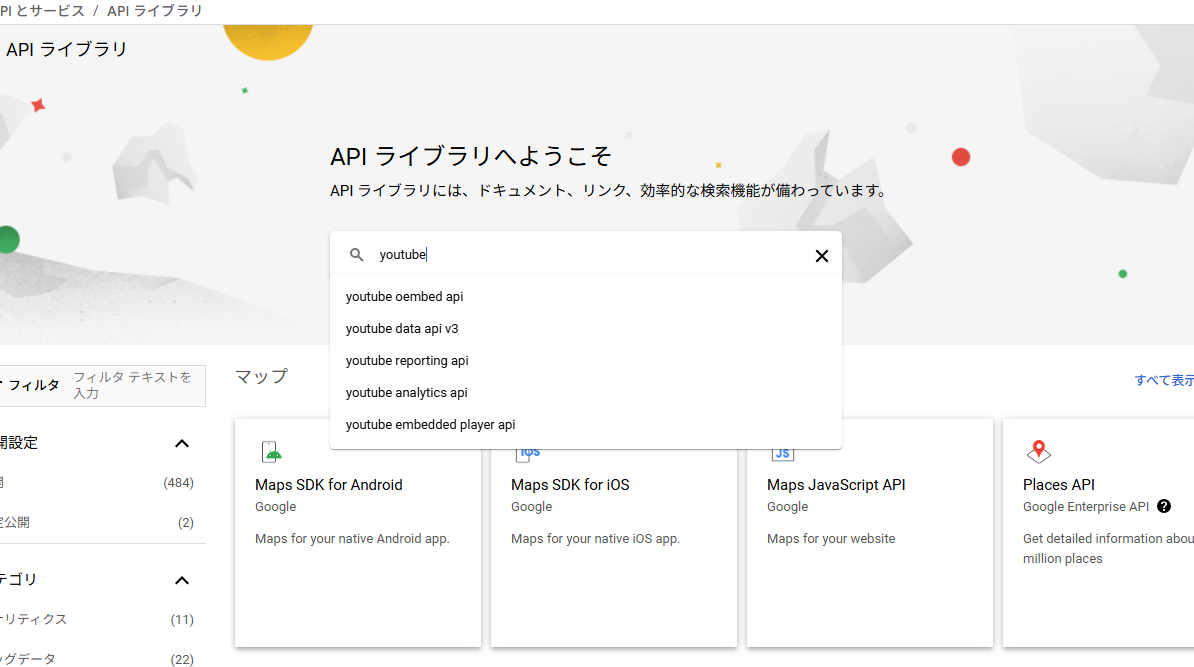
Youtube Data API v3を選択してクリック

有効にしたら「管理」をクリックし、左サイドバーの「認証情報」をクリック
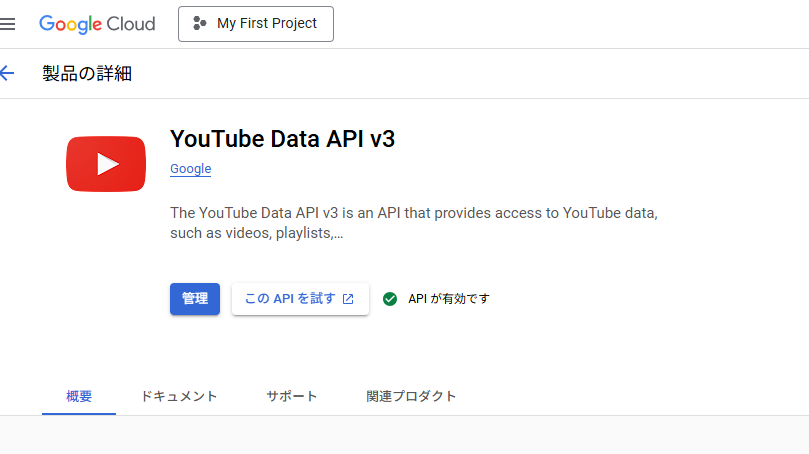
画面真ん中らへんの「+ 認証情報を作成」をクリック

「キーを制限」を選択
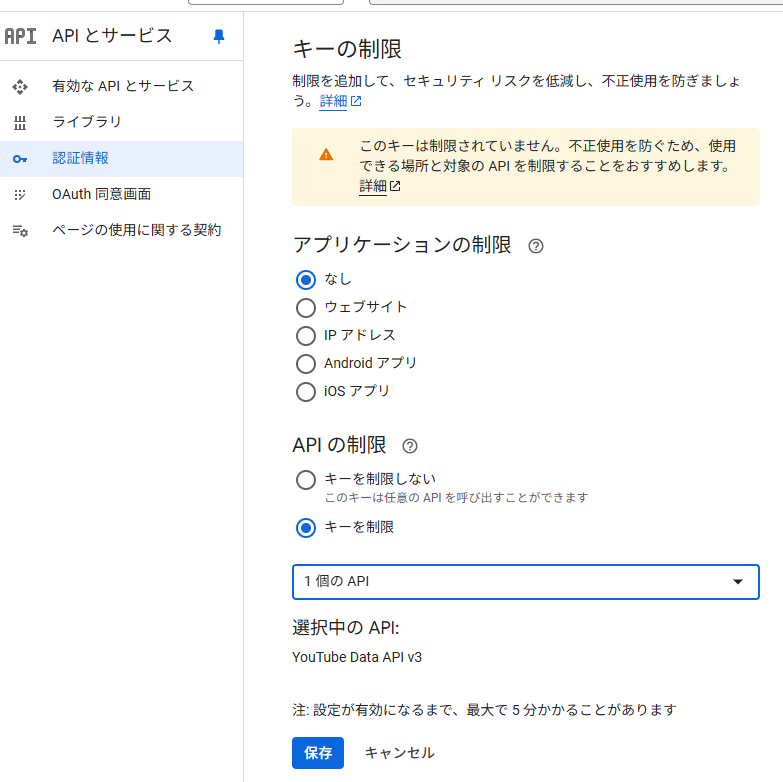
キーを制限のプルダウンから「YouTube Data API v3」を選択し、「保存」ボタンをクリック
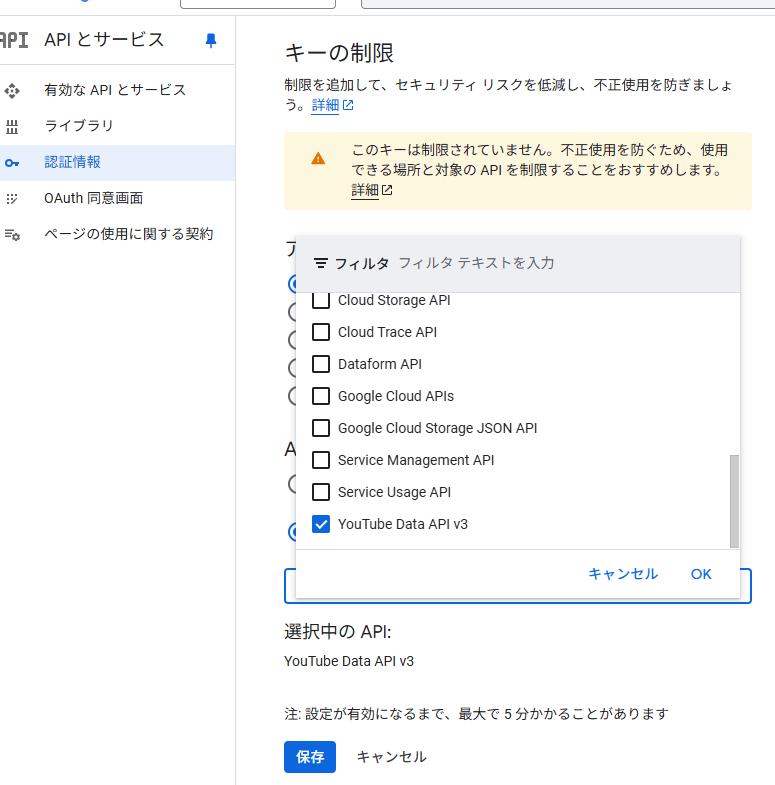
以下のようになったら設定完了

ここまでできたら、あとはOBSで配信の設定をおこないます。
OBS(Open Broadcaster Software®️)
パソコン画面やカメラ映像を、いろいろと組み合わせてYouotubeでライブ配信できる無料ソフトはこれ一択(?)っぽい感じだったのと、高度な設定や使い方はわからないのですが、簡易な設定については、直感的でわかりやすいと感じたため使用することとしました。
1. VMagicMirrorからOBSに3Dモデルの読み込み & 配信背景の設定
まずOBSを起動

ソースの下段左の「+」マークをクリックして「ゲームキャプチャ」を選択
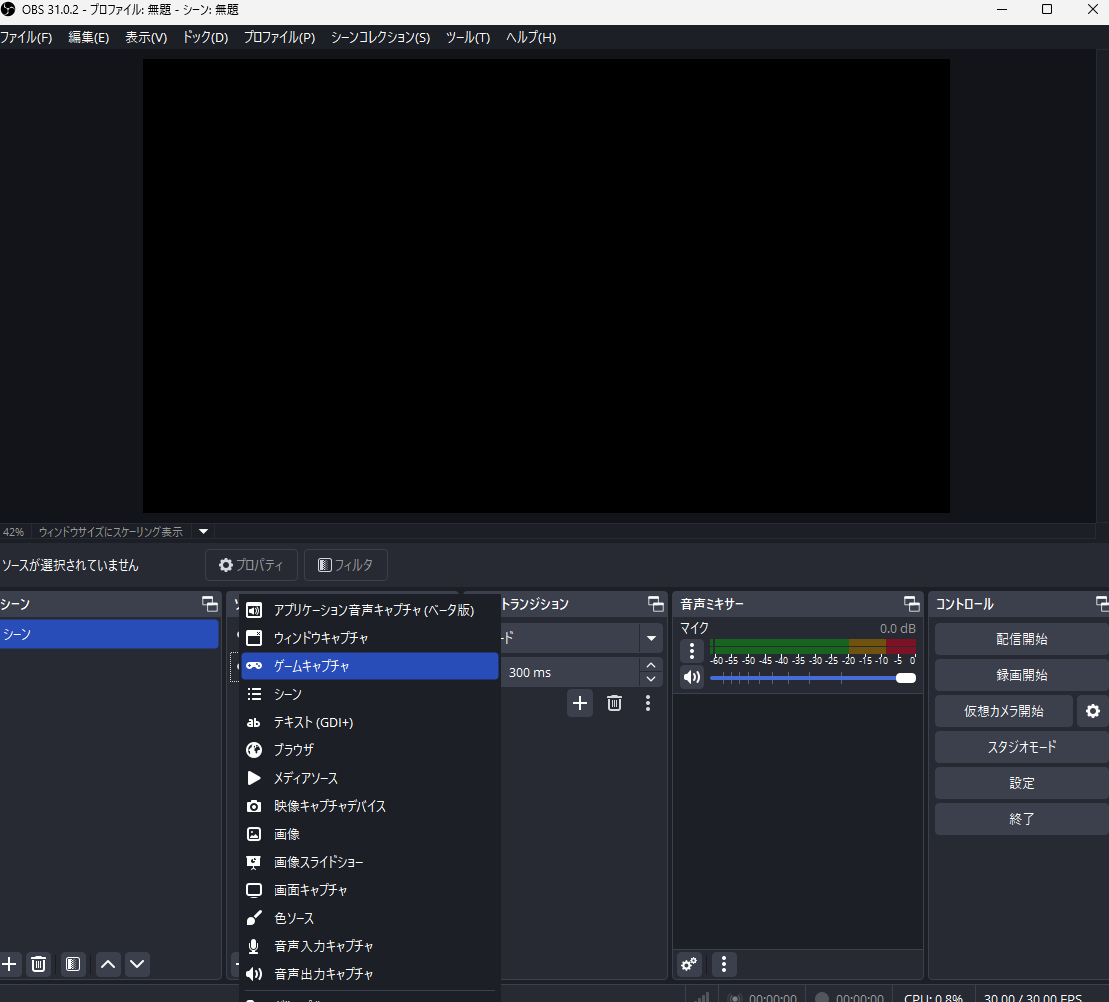
「VMagicMirror」と入力して「OK」をクリック
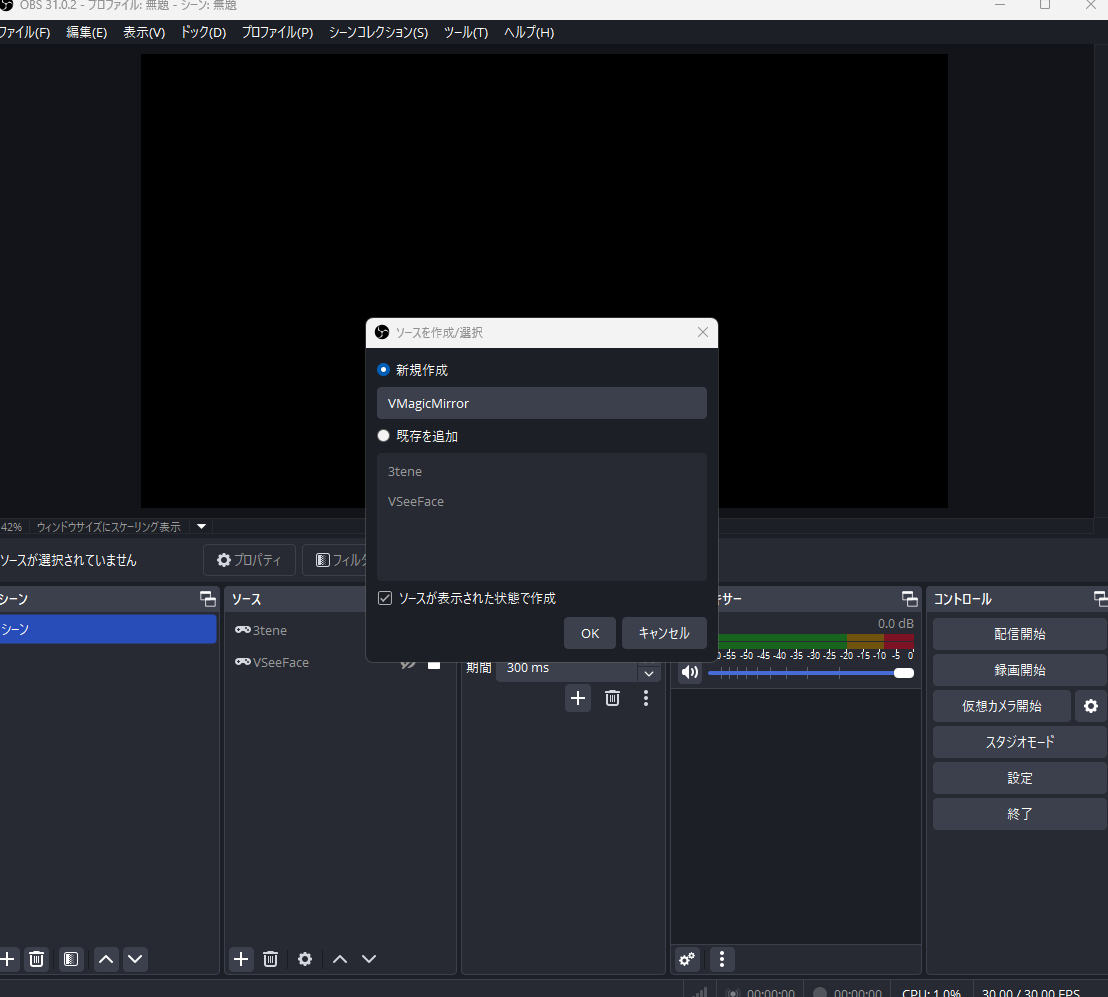
モードは「特定のウインドウをキャプチャ」をプルダウン形式から選択

ウインドウでは「VMagicMirror」をプルダウン形式から選択して、画面右下の「OK」をクリック

ソースの下段左の「+」マークをクリックして「画像」を選択

「背景」と入力して「OK」をクリック

背景画像にしたい画像ファイルを選択して、画面右下の「OK」をクリック

ソースの「VMagicMirror」を「背景」より上部にドラッグ&ドロップで移動させるとキャラが前面にくる

2. 配信の設定
次に、左上の「ファイル」タブから「設定」を選択

左サイドバーの「配信」を選択
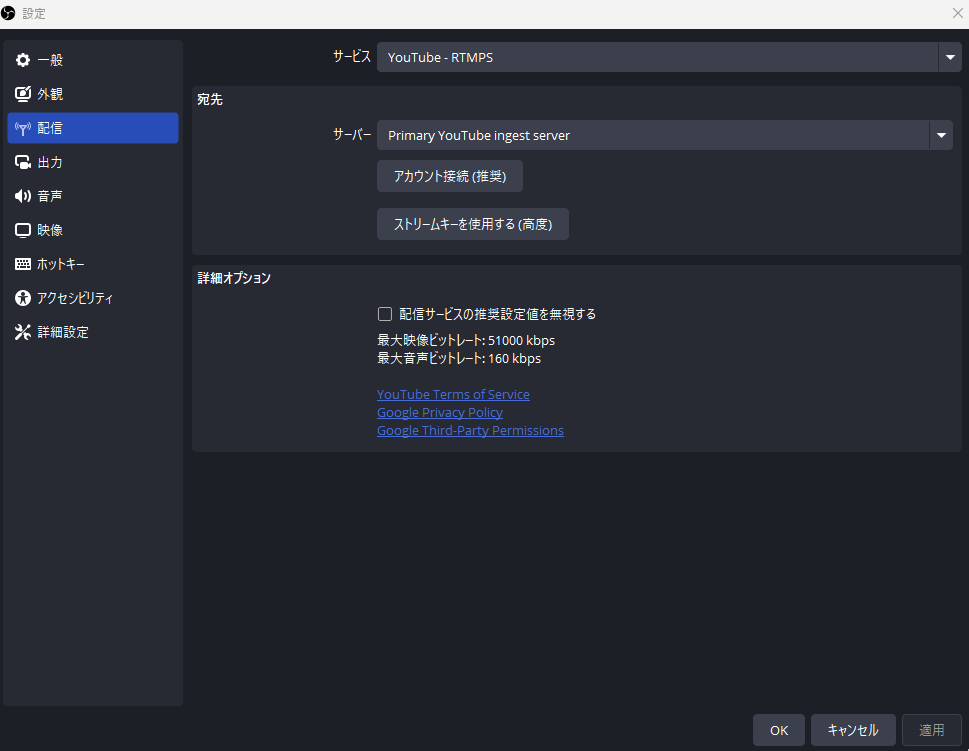
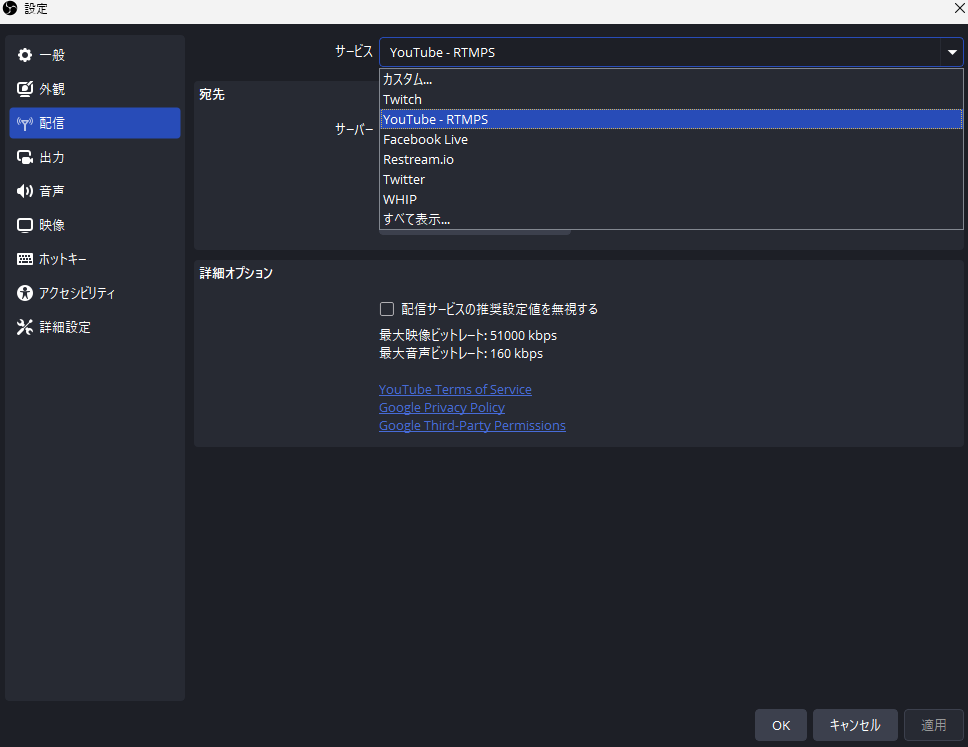
最上段の「サービス」のプルダウンから「YouTube-RTMPS」を選択
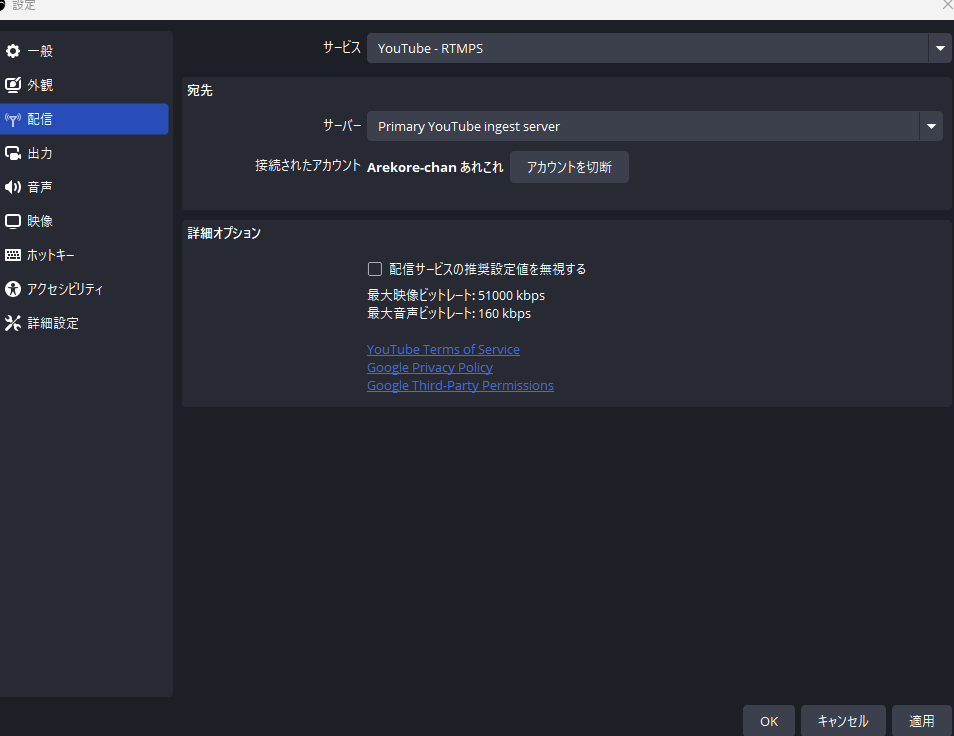
アカウントの接続をクリックして設定を完了されると「接続されたアカウント」にYoutubeアカウントが表示される
画面右下のコントロール上段から2つ目の「配信の管理」をクリック

さきほど作成した「テスト配信」を選択して配信開始
これで以下のような感じでYoutube Live配信が開始されました。

ここまではすべて準備で、これから先が重要な設定となります。
AITuberを起動させるためのシステム設計(Google Colab Pro L4使用)
長々と書いてきましたが、ここまでやってきたことはAITuberでYoutube Live配信をするための下準備でしかないため実質ここからが本番です。
ここでやることはざっくりと以下のとおりです。
- YouTube Data APIを使用して、指定されたYouTube Live配信からライブチャットメッセージを取得します。
- 感情分析モデル(
cardiffnlp/twitter-roberta-base-sentiment-latestを使用)を用いて、各チャットメッセージの感情を分析します。 - チャットメッセージとその感情に基づいて、ファインチューニングしたLLMを使用して応答を生成します。
- ここでは、
Llama-3.1-Swallow-8B-Instruct-v0.1と、このモデルをベースに上記で作成したカスタムqLoRAモデルyf591/Llama3SW8B_it_v0.1_qlora_FukuyamaBenを使用しています。
- ここでは、
- 生成された応答をVOICEVOXを使用して音声に変換します。
- 今回は簡単のためVOICEVOXを使用しました。いつか独自モデルを作ってみたいですがかなりの時間がかかりそうなので私は取り組めていません。
- 生成された音声をVTuberの声として再生します。
※記事の内容も長くなってしまいそうなので、手っ取り早くコードだけ確認したい方は以下のGithubリンクからも確認できますのでよかったらどうぞ。
それでは順番に実装したコードを共有していきたいと思います。
1. 環境セットアップ
1.1 GPUの確認(コード省略)
1.2 Googleドライブのマウント(コード省略)
1.3 作業ディレクトリの変更(コード省略)
1.4 ライブラリのインストール
AITuberに必要なPythonライブラリたちを一気にインストールします。LLMを使うための transformers や pytorch、Google APIを叩く google-api-python-client、音声合成・再生に必要なライブラリなどをここではインストールしました。
後の実装でかなりエラーが出てエラー対応しながら進めたため、必要そうなものをとりあえずインストールした形です。そのため不要なものも含まれるかもしれませんがご了承ください。
from google.colab import output
# --- モジュールのインストールとインポート ---
# Google Colab 環境で必要なライブラリをインストール
!pip install google-api-python-client # Google API クライアントライブラリ
!pip install requests # Web リクエストライブラリ
!pip install transformers # Hugging Face の Transformers ライブラリ
!pip install torch # PyTorch ライブラリ
!pip install sounddevice # 音声再生ライブラリ
!pip install scipy # 科学計算ライブラリ
!pip install soundfile # 音声ファイル操作ライブラリ
!pip install pydub # 音声ファイル操作ライブラリ
!pip install fugashi # 日本語トークナイザー
!pip install ipadic # 日本語辞書
!pip install accelerate # PyTorchの分散学習ライブラリ
!pip install bitsandbytes # 量子化ライブラリ
!pip install peft
!pip install huggingface_hub
# PortAudioライブラリをインストール
!sudo apt-get install portaudio19-dev
# sounddeviceを再インストール
!pip install --force-reinstall sounddevice
# 音声出力設定
from IPython.display import Audio, Javascript, display
def init_audio():
display(Javascript("""
if (!window.audio_context) {
window.audio_context = new (window.AudioContext || window.webkitAudioContext)();
}
"""))
init_audio()
1.5 VOICEVOX環境構築
ずんだもんで有名なVOICEVOXを使用しました。これをColabで動かすための環境を整えます。私はVOICEVOX Coreのライブラリや、音声合成に必要なONNX Runtime、日本語形態素解析のためのOpen Jtalk辞書などをインストール・準備しました。
# --- VOICEVOX 環境構築 ---
# VOCIVOXコアのPythonバインディングセットアップ
!wget https://github.com/VOICEVOX/voicevox_core/releases/download/0.14.3/voicevox_core-0.14.3+cpu-cp38-abi3-linux_x86_64.whl # 一度のみ実行
!pip install voicevox_core-0.14.3+cpu-cp38-abi3-linux_x86_64.whl
# ONNX Runtimeのダウンロード
!wget https://github.com/microsoft/onnxruntime/releases/download/v1.13.1/onnxruntime-linux-x64-1.13.1.tgz # 一度のみ実行
!tar xvzf onnxruntime-linux-x64-1.13.1.tgz # 一度のみ実行
!mv onnxruntime-linux-x64-1.13.1/lib/libonnxruntime.so.1.13.1 ./ # 一度のみ実行
# Open Jtalkの辞書ファイルダウンロード #
!wget http://downloads.sourceforge.net/open-jtalk/open_jtalk_dic_utf_8-1.11.tar.gz # 一度のみ実行
!tar xvzf open_jtalk_dic_utf_8-1.11.tar.gz # 一度のみ実行
!pip install playsound==1.3.0 # playsoundライブラリをバージョン1.3.0でインストール
上記でインストールして整えたVOICEVOX環境から、使用する機能をインポートしておきます。
# VOICEVOX 用
from pathlib import Path
import voicevox_core
from voicevox_core import AccelerationMode, AudioQuery, VoicevoxCore
from playsound import playsound
# --- ここまで VOICEVOX 環境構築 ---
一通りこれでPythonコードでVOICEVOXの機能を呼び出す準備がととのいました。
1.6 その他の準備や設定
今回のAITuberで使ったライブラリを一括でインポートしました。ファイル操作(os)、時間管理(time)、PyTorch(torch)、Hugging Face(transformers)、音声処理(sounddevice, soundfile, pydub)、Webリクエスト(requests)などなど…結構たくさんあります。とりあえず必要そうなものをインポートしました。
import os
import glob
import time
import datetime
import io
from googleapiclient.discovery import build # Google APIクライアントライブラリからbuildをインポート
import time
import torch # PyTorchライブラリ
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig # Hugging Face Transformersライブラリからインポート
from transformers import pipeline
import sounddevice as sd # 音声再生ライブラリ
import soundfile as sf # 音声ファイル操作ライブラリ
import numpy as np
import requests # Webリクエストライブラリ
import threading # スレッドライブラリ
from pydub import AudioSegment
from peft import PeftModel
Hugging Face からモデルをダウンロードして直接使うために、ここでログインしました。
userdata.get('HF_TOKEN') を使って、Colabシークレットに保存しておいたHugging Faceのアクセストークンでログインすれば表にトークンが露出しないので、私はいつもその機能を使っています。
※事前にHugging Face側でトークンを発行し、Colabに HF_TOKEN という名前で登録していますが、今回の記事の趣旨ではないので詳しいやり方はここでは割愛します。
from huggingface_hub import login
from google.colab import userdata
# HuggingFaceログイン
login(userdata.get('HF_TOKEN')) # Colabのシークレットキーを使用
今回使ったLLMのモデルパスを設定しました。応答生成のベースとなる事前学習済みモデル(ここではtokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1)と、自分でファインチューニングしたモデル(LoRAアダプターなど)が保存されているパスを指定します。MyDriveに各モデルをダウンロードしてそのPathを指定してもいけますが、私はHugging Faceから直接ダウンロードして使用できるように設定しました。
※使用する自作モデルがLoRAモデルなので、必ずベースモデルも必要になります!
# ベースLLMモデルのパスを設定
BASE_MODEL_PATH = "tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
# 独自LLMモデル(qLora)のパスを設定
LLM_MODEL_PATH = "yf591/Llama3SW8B_it_v0.1_qlora_FukuyamaBen"
2. APIキーとIDの設定
ここでは、YouTubeのライブ配信からコメントを取得するために必要な「YouTube Data APIキー」と、自分の「チャンネルID」を設定しました。
事前にAPIキーを取得し、チャンネルIDを確認して、それぞれ YOUTUBE_API_KEY と YOUTUBE_CHANNEL_ID という名前でColabのシークレットから読み込むように設定しました。
# --- APIキーとパスの設定 ---
# 環境変数からYouTube Data APIキーを取得
YOUTUBE_API_KEY = userdata.get("YOUTUBE_API_KEY")
# 環境変数から自分のYouTubeチャンネルIDを取得
YOUTUBE_CHANNEL_ID = userdata.get("YOUTUBE_CHANNEL_ID")
3. YouTube Data APIの初期化
次にYouTube Data APIを使うための準備です。まずはGoogle Colabでの認証を実行。それからbuild関数を使ってYouTube APIのバージョン3 (v3) を使うためのサービスオブジェクトを作成しました。これでAPIキーを使ってYouTubeのデータにアクセスできるようになりました。
このあたりの設定については正直、結構大変でした…。もしかしたらgoogle colab認証は不要かもしれませんが、念のため設定した感じです。
# --- YouTube Data API の初期化 ---
# google colab認証用のライブラリ
from google.colab import auth
# google colab認証
auth.authenticate_user()
# YouTube Data API v3 を使用するためのサービスを初期化
youtube = build("youtube", "v3", developerKey=YOUTUBE_API_KEY)
4. LLMの初期化
ここで応答生成に使うLLMのロード準備をしました。
-
量子化設定
まずはモデルを軽量化するための「量子化」の設定を行います。GPUメモリの使用量を節約したいのでBitsAndBytesConfigを使って、モデルを4ビットで読み込む(load_in_4bit=True)設定をしています。 -
ベースモデルとトークナイザーのロード
設定ができたら、AutoModelForCausalLM.from_pretrainedでベースとなるLLMモデルをロード。同時に、文章をモデルが理解できるように「トークナイザー」もここでロードしておきます。
# --- LLM の初期化 ---
# 量子化設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# モデルの設定
# LLMのモデルをロードし、GPUに転送(量子化設定を適用)
base_model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL_PATH,
trust_remote_code=True,
quantization_config=bnb_config, # 量子化
device_map='auto',
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
).to("cuda") # モデルをGPUに転送
# tokenizerの設定
# LLMのトークナイザーをロード(ベースモデルのトークナイザーを使う)
tokenizer = AutoTokenizer.from_pretrained(
BASE_MODEL_PATH,
padding_side="right", # パディングを右側にする
add_eos_token=True # EOSトークンを追加
)
if tokenizer.pad_token_id is None: # パディングトークンがない場合、EOSトークンを設定
tokenizer.pad_token_id = tokenizer.eos_token_id
-
ファインチューニングモデルのロード
ベースモデルの準備ができたら、その上に自分でファインチューニングしたモデル(LoRAアダプター)を読み込みます。これで、自作の応答ができるAITuberモデルがひとまず完成した形です。
# ファインチューニングモデルのロード
model = PeftModel.from_pretrained(base_model, LLM_MODEL_PATH)
5. 感情分析モデルの初期化
ライブチャットのコメントを見てそれが「ポジティブなのか」「ネガティブなのか」を分析するためのモデルをロードしました。もしかしたら感情分析を入れなくても問題ないかもしれないのですが、物は試しにと思ってやってみました。
今回は cardiffnlp/twitter-roberta-base-sentiment-latestというモデルを使っています。(英語メインのモデルみたいですが、ある程度は日本語でも動きました。)
# 感情分析モデルのロード
sentiment_analyzer = pipeline("sentiment-analysis", model="cardiffnlp/twitter-roberta-base-sentiment-latest")
6. VOICEVOXによる音声出力フォルダの設定
まず初めに、VOICEVOXが生成した音声ファイル(.wav)を一時的に保存しておくフォルダのパスを指定しました。
# 音声アウトプットフォルダのパス
OUTPUT_FOLDER = "/content/drive/MyDrive/Colab Notebooks/AITuber_Projects/Audio_Output"
# フォルダが存在しない場合は作成
if not os.path.exists(OUTPUT_FOLDER):
os.makedirs(OUTPUT_FOLDER)
# 処理済みメッセージを記録するセット
processed_messages = set()
7. VOICEVOXによるテキスト音声変換
次にテキストを渡すとVOICEVOXで音声ファイル(.wav)を生成してくれるVOICEVOX関数をつくりました。 引数でテキスト(text)、出力ファイル名(out)、そしてVOICEVOXのどのキャラクター(話者ID)で喋らせるか(SPEAKER_ID)を指定できるようにしました。
# --- VOICEVOX によるテキストから音声変換 ---
def VOICEVOX(text, out='output.wav', SPEAKER_ID=47):
open_jtalk_dict_dir = './open_jtalk_dic_utf_8-1.11' # Open JTalkの辞書ディレクトリを指定
acceleration_mode = AccelerationMode.AUTO # 高速化モードを自動に設定
# VOICEVOX Coreのインスタンスを作成
core = VoicevoxCore(
acceleration_mode=acceleration_mode, open_jtalk_dict_dir=open_jtalk_dict_dir
)
core.load_model(SPEAKER_ID) # 指定した話者IDのモデルを読み込み
audio_query = core.audio_query(text, SPEAKER_ID) # テキストを音声クエリに変換
wav = core.synthesis(audio_query, SPEAKER_ID) # 音声クエリを音声データに変換
out_byte = Path(out) # 出力ファイルパスをPathオブジェクトに変換
out_byte.write_bytes(wav) # 音声データをファイルに書き込み
# pydubを使って音声の長さを取得
sound = AudioSegment.from_file(out, format="wav")
duration_seconds = len(sound) / 1000.0 # ミリ秒を秒に変換
return out, duration_seconds # 出力ファイル名と再生時間を返す
念のため、ちゃんとVOICEVOXがColab上で動くかテストしてみました。
もし、使う際はスピーカーIDでキャラクターを設定できるので試してみてください。ちなみにずんだもんのIDは「3」です。
from IPython.display import Audio
# テスト用のテキスト (適当な文章)
test_text = "これはテスト用の文章です。ちゃんと聞こえるかな?"
# VOICEVOXで音声を生成 (SPEAKER_IDは環境に合わせて変更してください)
output_wav, _ = VOICEVOX(test_text, out='test.wav', SPEAKER_ID=3)
# 音声を再生
Audio(output_wav, autoplay=True)
話者一覧(参考)VOICEVOX
以下に話者IDの一覧も作成したのでよかったら参考にしてください。
| 話者 | ノーマル | あまあま | ツンツン | セクシー | ささやき | ヒソヒソ | その他 |
|---|---|---|---|---|---|---|---|
| 四国めたん | 2 | 0 | 6 | 4 | 36 | 37 | |
| ずんだもん | 3 | 1 | 7 | 5 | 22 | 38 | ヘロヘロ: 75 なみだめ: 76 |
| 春日部つむぎ | 8 | ||||||
| 雨晴はう | 10 | ||||||
| 波音リツ | 9 | クイーン: 65 | |||||
| 玄野武宏 | 11 | 喜び: 39 ツンギレ: 40 悲しみ: 41 |
|||||
| 白上虎太郎 | 12 | わーい: 32 びくびく: 33 おこ: 34 びえーん: 35 |
|||||
| 青山龍星 | 13 | 86 | 熱血: 81 不機嫌: 82 喜び: 83 しっとり: 84 かなしみ: 85 |
||||
| 冥鳴ひまり | 14 | ||||||
| 九州そら | 16 | 15 | 18 | 17 | 19 | ||
| もち子さん | 20 | セクシー/あん子: 66 泣き: 77 怒り: 78 喜び: 79 のんびり: 80 |
|||||
| 剣崎雌雄 | 21 | ||||||
| WhiteCUL | 23 | たのしい: 24 かなしい: 25 びえーん: 26 |
|||||
| 後鬼 | 27 | ぬいぐるみver.: 28 人間(怒り)ver.: 87 鬼ver.: 88 |
|||||
| No.7 | 29 | アナウンス: 30 読み聞かせ: 31 |
|||||
| ちび式じい | 42 | ||||||
| 櫻歌ミコ | 43 | 第二形態: 44 ロリ: 45 |
|||||
| 小夜/SAYO | 46 | ||||||
| ナースロボ_タイプT | 47 | 楽々: 48 恐怖: 49 内緒話: 50 |
|||||
| †聖騎士 紅桜† | 51 | ||||||
| 雀松朱司 | 52 | ||||||
| 麒ヶ島宗麟 | 53 | ||||||
| 春歌ナナ | 54 | ||||||
| 猫使アル | 55 | おちつき: 56 うきうき: 57 |
|||||
| 猫使ビィ | 58 | おちつき: 59 人見知り: 60 |
|||||
| 中国うさぎ | 61 | おどろき: 62 こわがり: 63 へろへろ: 64 |
|||||
| 栗田まろん | 67 | ||||||
| あいえるたん | 68 | ||||||
| 満別花丸 | 69 | 元気: 70 ささやき: 71 ぶりっ子: 72 ボーイ: 73 |
|||||
| 琴詠ニア | 74 | ||||||
| Voidoll | 89 | ||||||
| ぞん子 | 90 | 低血圧: 91 覚醒: 92 実況風: 93 |
|||||
| 中部つるぎ | 94 | 96 | 怒り: 95 おどおど: 97 絶望と敗北: 98 |
8. 関数定義
8.1 ライブチャットID取得関数
YouTubeのライブ配信動画IDから、リアルタイムにコメントを取得するために必要な「ライブチャットID」を取得するための関数を作りました。配信が開始されていないとライブチャットID取得できないのでそこは注意が必要です。そのため、テストでYoutubeライブを接続した状態で試行錯誤が必要でした。
# --- ライブチャットIDを取得する関数 ---
def get_live_chat_id(youtube_video_id, youtube_data_api_key):
params = {
'part': 'liveStreamingDetails',
'id': youtube_video_id,
'key': youtube_data_api_key
}
response = requests.get(
'https://youtube.googleapis.com/youtube/v3/videos', params=params)
json_data = response.json()
if len(json_data['items']) == 0:
return ""
live_chat_id = json_data['items'][0]['liveStreamingDetails']['activeLiveChatId']
return live_chat_id
8.2 チャットメッセージ取得関数
ここでは上で取得したライブチャットIDを使って、実際にチャットメッセージの一覧を取得する関数を定義しました。YouTube Data APIの liveChat/messages エンドポイントにライブチャットIDとAPIキーを指定してリクエストすると、コメントした人のYoutubeのIDやコメントの内容がJSON形式で返ってくるような設定にしました。 一度に取得する最大のコメント件数も指定できますが、私は最大200で設定してみました。
# --- チャットメッセージを取得する関数 ---
def get_live_chat_messages(live_chat_id, api_key):
params = {
'liveChatId': live_chat_id,
'part': 'id,snippet,authorDetails',
'maxResults': 200, # 最大200まで指定可能
'key': api_key
}
response = requests.get(
'https://youtube.googleapis.com/youtube/v3/liveChat/messages', params=params)
return response.json()
8.3 感情分析関数
チャットの内容を受け取って、その感情を分析する関数を作成しました。
先ほど「5. 感情分析モデルの初期化」でロードしたsentiment_analyzer (Hugging Faceのpipeline)を使って感情分析をしてくれて、チャットコメントへの応答をその感情に合わせて変えるみたいな仕組みを想定してみました。ここの設定が正しいかどうかはあまり自信がありません。
# --- 感情分析を行う関数 ---
def analyze_sentiment(text):
# 日本語感情分析モデルで感情を分析
result = sentiment_analyzer(text)
# 結果を返す
return result[0] # 結果はリストで返ってくるので最初の要素だけを返す
8.4 応答生成関数
ここはその名の通りAITuberの応答を生成する中心部分です!
まず、ユーザーからのコメントと、その感情分析結果を受け取ります。私は感情結果やキャラクター設定(ツンデレ設定にしてみました)をしたプロンプトを作成しました。次に、そのプロンプトをトークナイザーで数値に変換してLLMが応答を生成できるように調整しました。パラメータをいじって生成されるテキストの長さとかも調整してみました。最後に、生成された数値トークン列を人間が読めるテキストに戻して返すようにしました。
念のため、どのチャットコメントに対する応答か分かるように、チャットコメントを拾う際はそのコメントを読み上げてから応答するような仕組みにしてみました。
# --- LLMで応答を生成する関数 ---
def generate_response(text, sentiment):
# 感情分析の結果に基づいてプロンプトを調整
emotion_text = f"ユーザーの感情は{sentiment['label']}です。"
# ツンデレのキャラクター設定を追加
character_setting = (
"あなたはツンデレで可愛い女の子です。ユーザーをご主人様と呼び、忠実でありながらも、少し反抗的な態度を取ります。"
"ご主人様との会話を楽しんでいますが、素直に感情を表現するのが苦手です。"
"時々、ご主人様をからかうような発言をしますが、それは愛情表現の一つです。"
)
# プロンプトの作成
prompt = (
f"{character_setting}\n"
f"{emotion_text} ご主人様(ユーザー)が、{text}と言いました。\n"
f"ご主人様のコメント「{text}」を繰り返してから、それに対する返答を続けてください。\n"
)
# 推論の実行
input_text = f"ユーザー: {prompt}\nシステム: "
input_ids = tokenizer.encode(
input_text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.encode("<|eot_id|>", add_special_tokens=False)[0],
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
response = outputs[0][input_ids.shape[-1]:]
response_text = tokenizer.decode(response, skip_special_tokens=True)
# 応答テキストから、読み上げ部分と応答部分を抽出
reading_part = text
response_part = response_text.replace(f"{text} ", "", 1) # 最初の読み上げ部分を削除
# 最終的な応答テキストを返す
final_response_text = f"{reading_part} {response_part}"
return final_response_text
8.5 チャットメッセージ処理関数
ここでは、YouTubeから取得したそれぞれのチャットメッセージを処理するために一連の流れをまとめた関数を作成しました。コメントに応答して処理が済んだならもう用はないのでスキップ。未処理ならIDを記録してコメント本文と投稿者名をログに出力。感情分析をして、その結果もログに出力。そしてLLMで応答を生成して、その応答内容を VOICEVOXを使って音声化するみたいな基本的な流れをここで書いています。
# --- 各チャットメッセージを処理する関数 ---
def process_chat_message(item):
# チャットメッセージのIDとテキストを取得
message_id = item['id']
chat_text = item['snippet']['displayMessage']
# チャット送信者の名前を取得
author_name = item['authorDetails']['displayName']
# 既に処理済みのメッセージであればスキップ
if message_id in processed_messages:
return
# 処理済みメッセージとして記録
processed_messages.add(message_id)
# ログにメッセージと送信者名を表示
print(f"{author_name}: {chat_text}")
# 感情分析を実行
sentiment = analyze_sentiment(chat_text)
# 感情分析の結果を表示
print(f"感情分析結果: {sentiment}")
# LLMを使って応答を生成
response_text = generate_response(chat_text, sentiment)
# 生成された応答を表示
print(f"応答: {response_text}")
# VOICEVOXを使って応答を音声に変換 (出力先を音声アウトプットフォルダに変更)
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
output_wav = os.path.join(OUTPUT_FOLDER, f"output_{timestamp}.wav")
output_wav, duration_seconds = VOICEVOX(response_text, out=output_wav)
# 戻り値のサイズを表示
print(f"VOICEVOX output size: {os.path.getsize(output_wav)}")
# Audioオブジェクトで再生
audio = Audio(output_wav, autoplay=True)
display(audio)
# 推定再生時間だけ待機
print(f"Waiting for {duration_seconds} seconds...")
time.sleep(duration_seconds)
# 再生後に音声ファイルを削除
os.remove(output_wav)
print(f"Deleted: {output_wav}")
8.6 チャットループ関数
次にAITuberのメインループとなる関数を作成しました。
まず、ライブチャットIDを取得して、無限ループを開始します。当たり前のことなのですが、ループの中でYouTube APIから定期的に新しいチャットメッセージを取得してを一つずつチャットメッセージを処理していく仕様にしています。実はこれが結構難しくて、上手く設定しないと応答中に次に応答をはじめたりして、上手く制御するのが大変でした。頑張ってみたのですが、結局完全には不具合の解消はできませんでした...。コード上は問題ないと思っていたのですが、その通りの挙動をしてくれなかったのでそこは私の能力不足です。勉強します!
# --- チャットメッセージを取得し処理するループ関数 ---
def chat_loop(video_id, api_key):
# ライブチャットIDを取得
live_chat_id = get_live_chat_id(video_id, api_key)
if not live_chat_id:
print("ライブチャットIDが見つかりません。")
return
print(f"ライブチャットID: {live_chat_id}")
next_page_token = None
while True:
try:
params = {
'liveChatId': live_chat_id,
'part': 'id,snippet,authorDetails',
'maxResults': 200,
'key': api_key,
'pageToken': next_page_token,
}
response = requests.get(
'https://youtube.googleapis.com/youtube/v3/liveChat/messages', params=params)
response_json = response.json()
# 取得したメッセージを表示
for item in response_json.get('items', []):
process_chat_message(item)
# 次のページを取得するためのトークンを取得
next_page_token = response_json.get('nextPageToken')
# ポーリング間隔を取得 (ミリ秒単位)
polling_interval_millis = response_json.get('pollingIntervalMillis', 5000)
# ポーリング間隔を秒単位に変換して待機
time.sleep(polling_interval_millis / 1000)
except Exception as e:
print(f"エラーが発生しました: {e}")
time.sleep(60) # エラーが発生した場合は60秒待機
8.7 メイン関数
ようやく、プログラム全体を動かすためのmain関数の作成までたどり着きました。
ここでは、まずColabのシークレットからYouTube Data APIキーを読み込みます。次に、video_id (YouTubeライブ配信のID) ですが、Colabを使用しているため「#@param」を使ってUI上に直接入力できるような設定にしました。最後に、chat_loop関数を呼び出してAITuberのコメント取得&応答ループを開始します!
def main():
# 環境変数読み込み
YOUTUBE_DATA_API_KEY = userdata.get("YOUTUBE_API_KEY")
video_id = "ここにYoutube LIVE IDを入力" #@param {type:"string"}
api_key = YOUTUBE_DATA_API_KEY
# チャットループを開始
chat_loop(video_id, api_key)
9. 実行
ようやくAITuberが起動して、YouTube Liveのコメントに反応できるようになりました!
if __name__ == "__main__":
main()
まとめ & 学んだこと
冒頭でも書きましたが、結論としては「Google Colabでもごく短時間ならAItuberのLive配信は可能だが、以下の理由からあまり実用的ではない」でした。
- 配信は上手くいったが、3Dモデルのリップシンク(口パク)は失敗した。
原因:環境の問題なのか、設定の問題なのかは原因がつかめておらず不明。 - Google Colabでも可能だが、長時間配信はできない
理由:ランタイムが切れるため、そのたびに最初からコメントを取得して応答しようとする。
今回はひと通り、一から自分の環境でもYoutubeライブ配信のできるAItuberを作成してみようという、単純な好奇心から作成に至りましたが、想像以上に連携の必要な設定が多くビックリしました。
本来であればAItuberのライブ配信にはGPUを用いたローカル環境が適していることや、自作のLLMではなくOpenAIなどが提供しているAPIを用いた方が圧倒的に効率的で最適解なのは誰の目から見ても明らかだったように思います。
ただ、取り組んでみてメリットもありました。
学んだことを単発的にアウトプットするだけでは、システムがどのような連携で動いているのかを想像することすらできなかったと思います。今回試したシステムでは少なくとも以下の技術連携が必要でした。
- Google Cplab(日本語モデルのファインチューニング)
- Google Colab(AiTuberを起動させるためのシステム設計)
- Google Drive
- ローカルに保存しているファイル
- Hugging Face
- Youtube, Youtube API, Live Chat ID
- VOICEVOX
- VMagicmirror
- VRoidStudio
- OBS
そのため、この技術連携を正常に作動させるにはどのような順序で、どのような設定で連携させるべきなのかを考えた上で、常に最適解を模索しつつ自問自答しながら構築できたことはとても勉強になったと感じています。
最後になりますが、さすがにここまで読んでくださった方はいないかなと思いつつ、もし本記事を最後まで読んでくださった方がいるならば「ここまで目を通していただきありがとうございました。」とお伝えして締めくくりたいと思います。
Reference
- QLORA:Efficient Finetuning of Quantized LLMs
- 【Llama3】SFTTrainerで簡単ファインチューニング(QLoRA)
- huggingface/TRLのSFTTrainerクラスを使えばLLMのInstruction Tuningのコードがスッキリ書けてとても便利です
- TRL - Transformer Reinforcement Learning
- Google Colabによる Llama3.2 / Qwen2.5 の ファインチューニング・ハンズオン
- AITuberを作ってみよう!サプーが引退の危機?!〜 Pythonを使って自動で喋るVTuber 〜