この記事は、身の回りの困りごとを楽しく解決! by Works Human Intelligence Advent Calendar 2025 4日目の記事です。
LinuxコマンドはDX化の基本です。
Linuxコマンドなんて仕事で使わないよ…と思っていても、最近は使う場面が確実に増えています。DX化で「社内チャットボットを作りたい」「RAGで社内文書を検索したい」となると、結局サーバを立てることになる。AWS/Azure/GCPでインスタンスを作ったら、待っているのは Linux のターミナル画面です。
初心者でも困らないように、図解付きで「LLM運用って何をするの?」がイメージできるようにまとめてみました。
小規模な検証(PoC)なら Linux をほとんど触らずに構築する方法もあります。しかし、企業で本格的に LLM や RAG を運用し始める段階では、Linux 環境はほぼ必須になります。
はじめに
LLMを「使うだけ」なら不要ですが、「動かす側」になりたいなら Linux コマンドは避けて通れません。
ChatGPT や Claude のWeb UIを触るだけなら不要ですが、自分でモデルをファインチューニングしたり、推論APIを立てたり、vLLM/TGI を運用したりするには、どうしても Linux の基本操作が必要になります。
この記事では、LLM 開発・運用で ほぼ絶対に使う30個のLinuxコマンド を、実際のユースケースとともにわかりやすくまとめました。
この記事の対象者
Linux 初心者〜中級者で、これから LLM をサーバで動かしたい人向けです。
LLM運用の全体像をざっくり掴もう
「LLMを動かしたい!」と思ったとき、実はやることって意外と多いんですよね。
モデルをダウンロードして、環境作って、学習or推論して、ログ見て、デプロイして、運用して…。ひとつひとつは難しくないけど、全体の流れを把握しておくと迷子になりにくいです。
ということで、まずは全体フローをざっくり図にしてみました!

典型的なLLMプロジェクトのフォルダ構成
LLM 開発では「実際のプロジェクトがどんな構成になっているか」が見えていないと、Linux コマンドの学習もイメージしづらいものです。
そこでまずは、もっとも一般的なLLMプロジェクトのフォルダ構成はこんな感じです..

もちろんプロジェクトによって構成は変わりますが、
models / data / logs / scripts の4つはほぼ必ず出てきます。
この後の Linux コマンドの章では、
上記フォルダを前提に操作例が登場するので、ここで軽く把握しておくとスムーズです。
(1)ファイル・ディレクトリ操作系
大量のモデルファイル、データセット、ログファイルを扱うLLM開発の基本中の基本です。
GPT系やLlama系のモデルは数GB〜数百GBにもなります。これらを効率的に管理するには、まずファイル操作の基本を押さえる必要があります。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 1 | pwd |
カレントディレクトリを表示 | 「今どこのプロジェクト配下にいるか」迷子防止 |
| 2 | ls |
ファイル/ディレクトリ一覧 | モデル重み(.safetensors, .gguf)やログの存在確認 |
| 3 | cd |
ディレクトリ移動 |
cd ~/projects/llm-api でAPIサーバのディレクトリへ |
| 4 | mkdir |
ディレクトリ作成 |
mkdir models logs でモデルとログ保存場所を作る |
| 5 | rm |
ファイル削除 | 失敗したチェックポイントや巨大ログの掃除(※rm -rf は本番サーバで慎重に!) |
| 6 | cp |
コピー | 学習済みモデルを別サーバに持っていく前のバックアップ |
| 7 | mv |
移動/リネーム |
mv model-latest.bin model-2025-11-22.bin で版管理 |
| 8 | find |
条件でファイル検索 |
find . -name "*.log" でログを一気に探す |
| 9 | du |
ディスク使用量を確認 |
du -sh models/ でモデル群のサイズ確認(重いモデルの整理判断に必須) |
| 10 | df |
ファイルシステム空き容量 | 「このGPUマシン、ディスクまだ足りる?」の確認 |
Tips
モデルファイルは巨大なので、du -sh * で各ディレクトリのサイズを確認してから削除するクセをつけるとよいです。
(2)中身を見る・ログを追う・検索する系
学習ログやエラーメッセージの調査は、LLM開発の大半の時間を占めます。
特に学習中の損失値の推移や、CUDA Out of Memoryエラーの原因特定など、ログ解析スキルは必須です。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 11 | cat |
ファイルの中身を一気に表示 | 設定ファイル .env や config.yaml を確認 |
| 12 | less |
ページ送りで閲覧 |
less train.log で長い学習ログをゆっくり読む |
| 13 | head |
先頭数行だけ表示 |
head -n 20 dataset.csv でデータの雰囲気を掴む |
| 14 | tail |
末尾数行・追尾表示 |
tail -f app.log で推論APIのログをリアルタイム監視 |
| 15 | grep |
文字列検索 |
grep -r "CUDA out of memory" logs/ でエラー箇所特定 |
モダン環境のおすすめ
-
grep→rg(ripgrep):爆速検索 -
cat→bat:シンタックスハイライト付き表示 -
less→lnav:ログ専用ビューア
(3)プロセス・リソース・GPU監視系
GPU メモリの枯渇は日常茶飯事。学習・推論どちらでも最も多いトラブルです。
「なぜかGPUが使えない」「学習が急に止まった」といったトラブルの9割は、リソース周りの問題です。これらのコマンドで原因を素早く特定できます。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 16 | ps |
プロセス一覧 | 「どのPythonがGPUを食ってるのか?」を確認 |
| 17 | top |
CPU/メモリの利用状況 | 学習中にCPU/メモリが張り付いてないかをチェック |
| 18 | free |
メモリ使用量を確認 | OOM(メモリ不足)っぽいときに即チェック |
| 19 | nvidia-smi |
GPU使用状況 / メモリ / プロセス確認 | どのプロセスがどのGPUをどれだけ使っているか確認 |
| 20 | watch |
コマンドの定期実行 |
watch -n 1 nvidia-smi でGPU使用率を1秒ごとにモニタ |
nvidia-smi の 例..

あるある
nvidia-smi で「GPU Memory-Usage: 47998MiB / 48000MiB」を見て絶望する瞬間。バッチサイズを下げましょう。
(4)ネットワーク & リモート操作系
モデルのダウンロード、API連携、GPUサーバへの接続。ネットワーク操作は必須スキル。
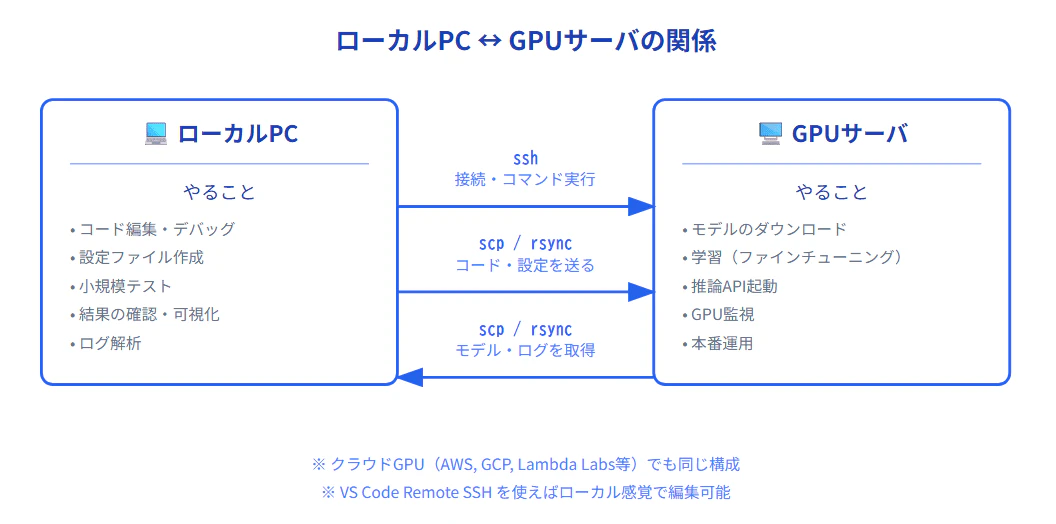
HuggingFaceからモデルを取得したり、クラウドGPUインスタンスで作業したり、LLM開発はネットワーク越しの作業が多いです。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 21 | curl |
HTTPリクエスト送信 | 自前の LLM API に対してテストリクエストを送る |
| 22 | wget |
ファイルをHTTP/HTTPSで取得 | HuggingFaceやGitHubの簡単なモデル/重みをダウンロード |
| 23 | ssh |
リモートサーバにログイン | GPU サーバやクラウド上の学習用VMに接続 |
| 24 | scp |
サーバ間でファイルコピー | ローカルPC ↔ GPUサーバ間でモデルやログを転送 |
追加で覚えると便利
- 大容量ファイル転送には
rsync -avzが高速 & 再開可能で非常に便利です。 - 実際の Hugging Face モデルは、
git lfsやhuggingface-cliで取得するケースも多いです。
(5)圧縮・アーカイブ・配布系
数十GBのモデルファイルを効率的に管理・共有するための必須スキル。
チーム開発やモデル配布時には、効率的な圧縮・展開が重要になります。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 25 | tar |
アーカイブ(.tar, .tar.gz) |
tar czf model.tar.gz models/ でモデル一式を固める |
| 26 | unzip |
zip解凍 | 配布されたデータセットやモデルZIPを展開 |
よく使うパターン
- 圧縮:
tar czf archive.tar.gz target_dir/(大量ファイルを一つにまとめる時に最も使われる方法) - 展開:
tar xzf archive.tar.gz
(6)Python & パッケージ管理・LLMコード実行系
PyTorch、Transformers、vLLM... Python環境構築はLLM開発の第一歩。
LLMのほとんどはPythonで動きます。環境管理を怠ると「動かないコード」の沼にハマります。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 27 | python |
Python実行 |
python train.py や python -m venv venv など |
| 28 | pip |
Pythonパッケージ管理 |
pip install torch transformers vllm など |
ベストプラクティス
- 必ず仮想環境を使う:
python -m venv venv - pip は
python -m pipで実行(Python バージョンの混乱を防ぐ)
(7)コンテナ・バージョン管理系(LLM運用の心臓部)
本番環境でLLMを動かすなら、Dockerとgitは避けて通れない。
再現性のある環境構築と、コードの履歴管理。この2つがLLM開発をプロフェッショナルなレベルに引き上げます。
| 番号 | コマンド | 何をするか | LLM文脈での具体例 |
|---|---|---|---|
| 29 | docker |
コンテナ操作(build/run/logsなど) | LLM API や TGI / vLLM をコンテナで動かす・デプロイする |
| 30 | git |
ソースコードのバージョン管理 | プロンプトテンプレ・設定・推論APIコードの管理 |
Docker活用例
docker run --gpus all -p 8000:8000 vllm/vllm-openai:latest \
--model meta-llama/Llama-2-7b-chat-hf
# ※ NVIDIA Container Toolkit がインストールされている前提です
実践!LLMワークフローをコマンドで追体験
これらのコマンドを実際のワークフローに当てはめてみるとよりイメージができます。

1. 環境準備
LLM を動かす最初のステップは「GPU サーバへ入る」「コードを取得する」「Python 環境を作る」ことです。どのプロジェクトでも必ず行う基本セットアップをまとめています。
ssh gpu-server # GPUサーバに接続
git clone https://github.com/xxx/llm-api # コードをクローン
python -m venv venv && source venv/bin/activate
pip install -r requirements.txt # 依存パッケージインストール
2. モデル配置
次に、LLM の「中身」であるモデルファイルを配置します。
大規模モデルは数GB〜数十GBあるため、ダウンロード → 展開 → サイズ確認の流れが基本です。
wget https://huggingface.co/model.tar.gz # モデルダウンロード(例)
tar xzf model.tar.gz # 展開
du -sh models/ # サイズ確認
※ wget の例は最小構成のイメージです。
実際の Hugging Face モデルは git lfs や huggingface-cli download を使うのが一般的です。
3. 動作確認
API を起動し、ログを見つつ、実際にリクエストを送って動作するかチェックします。
ここが最初の「動いた!」を確認できる瞬間です。
python main.py & # APIサーバ起動
tail -f logs/app.log # ログ監視
curl -X POST http://localhost:8000/v1/chat \
-H "Content-Type: application/json" \
-d '{"model":"my-llm","messages":[{"role":"user","content":"Hello"}]}'
# エンドポイントテスト(シンプルなチャットリクエスト)
4. トラブルシューティング
動かしていると必ずトラブルが起きます。
GPUが足りない、エラーが出る、CPUメモリが枯れる…など、原因を特定するための三種の神器です。
nvidia-smi # GPU状態確認
grep -r "CUDA out of memory" logs/ # エラー調査
top # CPU/メモリ監視
5. 運用・メンテナンス
最後は「安定して動かし続ける」ための作業です。
ディスクの空き容量確認、ログ掃除、コンテナの状態確認など、運用フェーズで必ず必要になります。
df -h # ディスク容量確認
find . -name "*.log" -mtime +7 -delete # 古いログ削除
docker logs llm-container # コンテナログ確認
まとめ
この30個のコマンドは、LLM開発・運用の最低限のサバイバルキットです。
最初は覚えることが多く感じるかもしれませんが、実際にLLMを触っていれば自然と身につきます。特に nvidia-smi と tail -f は、きっと毎日使うことになるかも(笑)。
次のステップとして、これらのコマンドを組み合わせた シェルスクリプトや Dockerfile を書けるようになると、作業効率と環境の再現性が飛躍的に向上します。
参考サイト
Linux / 基本コマンド
- https://www.gnu.org/software/coreutils/
- https://www.gnu.org/software/findutils/
- https://www.gnu.org/software/grep/
GPU / NVIDIA
Python & LLM Framework
- https://www.python.org/
- https://pytorch.org/
- https://huggingface.co/docs/transformers
- https://docs.vllm.ai/