はじめに
AI がコードを書くようになっても、そのコードを高速・安定に動かす土台はハードウェアです。
先日、ローカル環境で生成 AI を試したところ、推論が遅すぎて実用にはいろいろな工夫が必要そうでした。モデル選定も重要ですが、GPU や周辺インフラの整備が不可欠だと痛感した瞬間です。場合によっては、別サーバーへ処理を切り出す構成のほうが合理的かもしれません。
そんな時も、基礎を押さえておけば コストの無駄を削り、性能を引き出し、障害に強いシステム を自らデザインすることができます。
あまり需要はないかもですが、アプリ開発者や DX 推進担当、そして AI を活用する非エンジニアの方々に向けて、今こそ知っておきたいハードウェアの基本をわかりやすく整理してみました。
1. なぜ AI 時代にハードウェア知識が必要なのか
「AI=クラウドにお任せ」では決してありません。モデルサイズの肥大化と GPU 高騰で、リソース選定ひとつの差が 月数十万円規模 のコスト差を生むケースも珍しくありません。
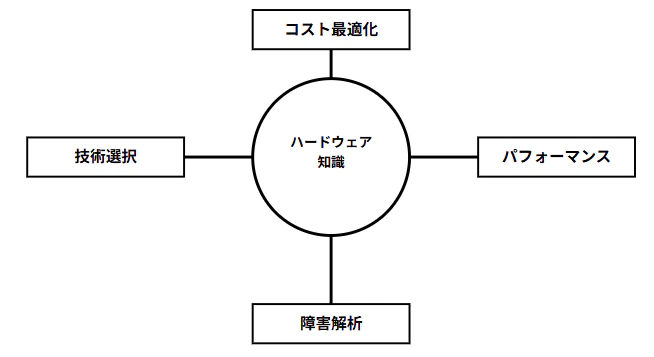
具体的にどんな場面で役立つのかを整理すると、次のとおりです。
| 目的 | 典型シナリオ | 得られる効果 |
|---|---|---|
| コスト最適化 | GPU インスタンスのサイズ選定 | 月額課金を 30〜70% 削減 |
| パフォーマンス向上 | LLM 推論レイテンシ改善 | 応答速度を 10〜50 倍短縮 |
| 障害解析 | 推論が途中で落ちる原因特定 | ダウンタイム短縮・SLA 向上 |
| 技術選択 | 新サービスの HW 要件評価 | 将来のリスク回避・ROI 向上 |
2. CPU — コンピュータの頭脳
CPU は依然として OS や推論前後処理を回す中心的存在です。マルチコア数・クロック・命令セット を押さえるだけで、多くのボトルネックを事前に避けられます。
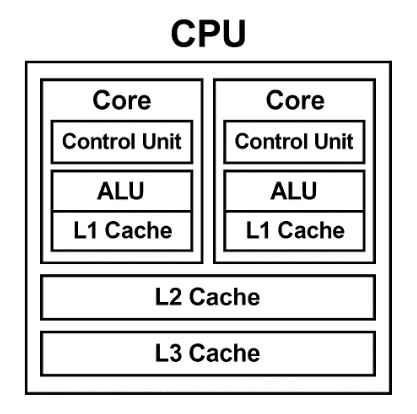
超ざっくり言うと
「少人数で難しい問題を順番に解くスペシャリスト」
-
主な役割:プログラム実行、制御、軽量推論
-
最近の注目点:Sapphire Rapids 世代で AMX (AI Matrix Extensions) が追加。HBM 付き Xeon Max はメモリ帯域 1 TB/s 超。
-
選び方
- コア数:並列バッチ処理やコンテナ高密度配置に効く
- クロック:レイテンシ重視なら依然重要
- アーキテクチャ:x86 (Intel/AMD) / Arm (Apple M‑series, Ampere) をワークロードとエコシステムで選択
3. GPU — AI 計算の主役
GPU は「大量の単純計算を同時にこなす」並列計算特化プロセッサ。Transformer Engine や FP8/INT8 量子化対応で、2022 年比で 最大 6× の効率化が進みました。
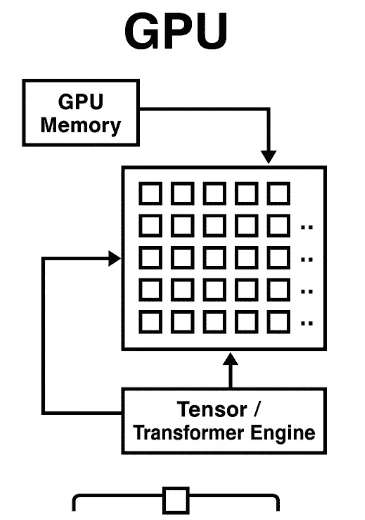
超ざっくり言うと
「大人数で単純作業を瞬時に終わらせる作業ライン」
| 世代 / 製品 | 用途 | メモ備考 |
|---|---|---|
| RTX Ada (Pro) | 開発・デスクトップ検証 | 最大 48 GB / FP8 対応 |
| H100 (Hopper) | 本番学習・推論 | 80 GB HBM3 / NVLink 4 |
| B100 (Blackwell, 2025 H2) | 次世代本番 | 192 GB HBM3e / 双方向 1.8 TB/s |
| AMD MI300X | コスト効率重視 | 192 GB HBM3 / ROCm 6 |
4. メモリ (RAM) — データの作業机
モデルとバッチを一度に広げられる “机” が広いほど、GPU を遊ばせずに済みます。大規模 LLM 推論では 64 GB 以上 が現実的な下限になりつつあります。
超ざっくり言うと
「机が狭いと資料を片付けながら作業する羽目になる」
- 速度:ナノ秒単位でランダムアクセス
- 最近の動向:DDR5‑6400 / LPDDR5X‑8533 が主流。HBM3 は GPU 側に直結し帯域 3 TB/s 超。
- 不足のサイン:スワップ多発、OOM エラー、システム全体のカクつき
5. ストレージ — データの永続倉庫
読み込み遅延は学習全体を引き延ばします。PCIe Gen5 NVMe SSD が普及し、連続読込 14 GB/s・ランダム 4K 300 万 IOPS を達成。

※参考速度(GB/s)
超ざっくり言うと
「倉庫の搬出口が狭いとトラックが行列する」
| 種別 | 速度 (参考) | 主な用途 |
|---|---|---|
| NVMe Gen5 | 14 GB/s | LLM 学習, 高速推論 |
| NVMe Gen4 | 7 GB/s | 一般開発, 中規模学習 |
| SATA SSD | 0.5 GB/s | OS, ログ |
| HDD | 0.2 GB/s | コールドデータ, バックアップ |
6-1. クラウド
クラウドは「必要な時だけ借りるホテル」。ただし長期滞在すると割高になることもあります。
| プロバイダー | 汎用 | 計算最適化 | メモリ最適化 | GPU 特化 |
|---|---|---|---|---|
| AWS | m7i | c7gn (Graviton 3E) | r7i | p5 (8 × H100) |
| Azure | Dv5 | Fsv2 | Ev5 | ND H100 v5 |
| GCP | n2 | c3 | m3 | a3 (H100) |
節約テクニック
- スポット / 先渡し予約 : 最大 90 % OFF(中断リスク要管理)
- モデル分割ロード : 推論時に必要層のみロード
- オートスケーリング : アイドル GPU を自動停止
6‑2. オンプレ
オンプレは「持ち家」。初期投資は大きいものの、長期・高負荷なら月額換算は安くなることも。
- 初期費用:GPU, 冷却, 分電
- 運用コスト:電力 1 kW あたり月約 20,000 円 (日本平均)
- 制約:ラック搭載重量, 空調, 消防法
7. よくあるトラブルと第一次診断
「遅い・落ちる」は 4 リソースを順に見るだけで 7 割解決します。
8. これからのトレンド予想
今後 1〜2 年:エッジ AI が当たり前に
スマホやノート PC に AI 専用 SoC が内蔵され、翻訳や画像認識がオフラインでも一瞬で実行できるようになります。
代表例は Snapdragon X Elite や Apple M4 です。
3〜5 年後:クラウドは専用 AI チップへ
クラウド側では AWS Trainium 2 や Intel Gaudi‑3 など、GPU より効率の良い “AI 専用エンジン” が主流になります。 学習コストが下がり、推論もさらに高速化される見込みです。
5〜10 年後:量子・光コンピューティングが実験から実務へ?
量子ビットや光を使った計算技術が、暗号解析や組合せ最適化など一部ニッチ分野で PoC から小規模実利用に移る可能性があります。ただし一般的なアプリで広く使われるには、もう少し時間がかかりそうです。
おわりに
AI ワークロードはハードウェア性能の「足し算」ではなく 「掛け算」 で効いてきます。ボトルネックを 1 か所でも放置すると全体が鈍るため、基礎を押さえてバランスの良い構成を選ぶことが大切です。
AIでの開発があたりまえになって選択肢も日々増えています。
今後は、AIを "速く・安く・安全に" 動かすことがますます必要になりそうです。
初心者におすすめの記事