国会の発言データを使って出現単語をカウントしてみる
様々な記事の単語をカウントするプログラムを作ってみた
と
国会議事録検索システムのAPIを使って議事録を取得してみる
を組み合わせてやっていきます。
議事録の取得
まず議事録を取ってきましょう。
今回は2018年の安倍総理の発言を取得します。パラメータは以下の通り。
- 発言者:安倍晋三
- 取得日付の始点:2018年01月01日
- 取得日付の終点;2018年12月31日
これで2018年に安倍総理の発言を記録にある限り取得できます。
取得したファイルはこちら
3MBほどありますね。まずはこれを使っていきます。
単語をカウントしてみる
内容的にはWikipediaの記事の単語をカウントしてみたとあまり変わりません。
様々な記事の単語をカウントするプログラムを作ってみたのプログラムをそのまま使ってみます。
プログラムの使い方はこちら
python count_word.py -i (inputするファイル) -o (結果出力ファイル)
先ほど取得したファイルをそのまま入れて動かしてみます。
分かりやすいように品詞を名詞の一般形と固有名詞に絞ってカウントします。
結果のグラフはこちら
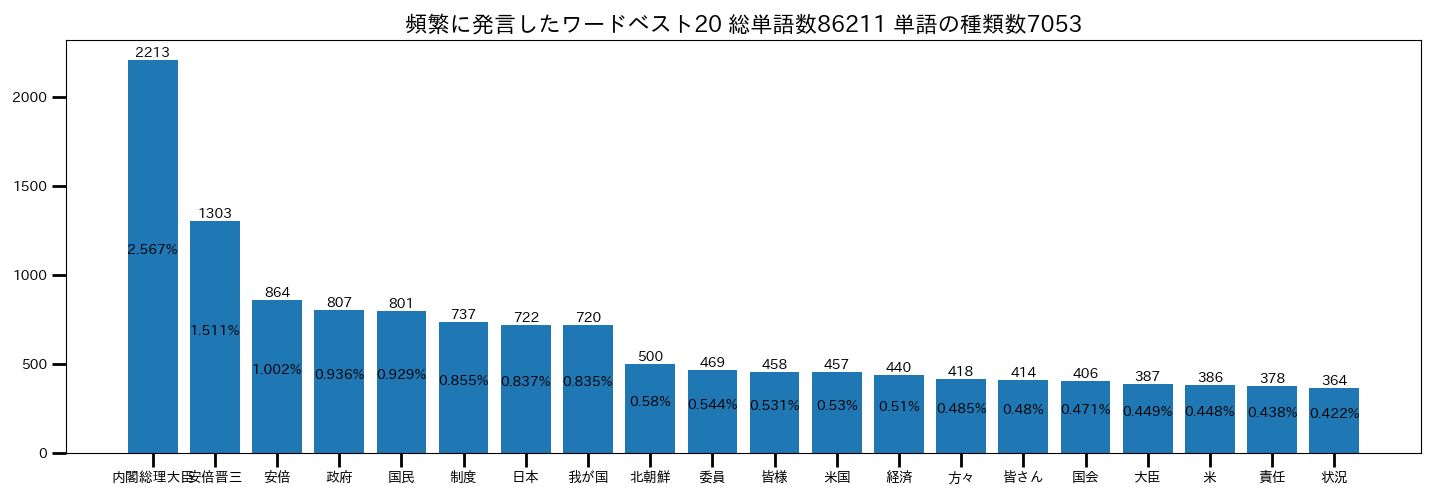
内閣総理大臣と安倍晋三が多いですね。。。
それもそのはず、議事録の発言データはこんな感じになってます。
○内閣総理大臣(安倍晋三君) 出入国管理及び難民認定法は、....
発言の最初に役職と名前があるんですねぇ、そりゃ一番数値がでかくなりますわ
てことで最初の役職+名前を取り除きます。
発言者の名前と役職を取り除く
分かち書きした後に取り除こうとも考えたのですが、発言で「内閣総理大臣として〜」みたいな発言もある可能性があるため、mecabを通す前に処理したいと思います。
前処理段階で、以下の処理を追加しました。
pattern = "(.*) (.*)" #全角スペースで分ける
if line.find('○',0,10) == 0: #○から名前なのでここで取り除く
sep = re.search(pattern,line)
line = line.replace(sep.group(1),"")
力技ですけどとりあえずこれでいいはずです。
これを適用して再度カウントしてみます。
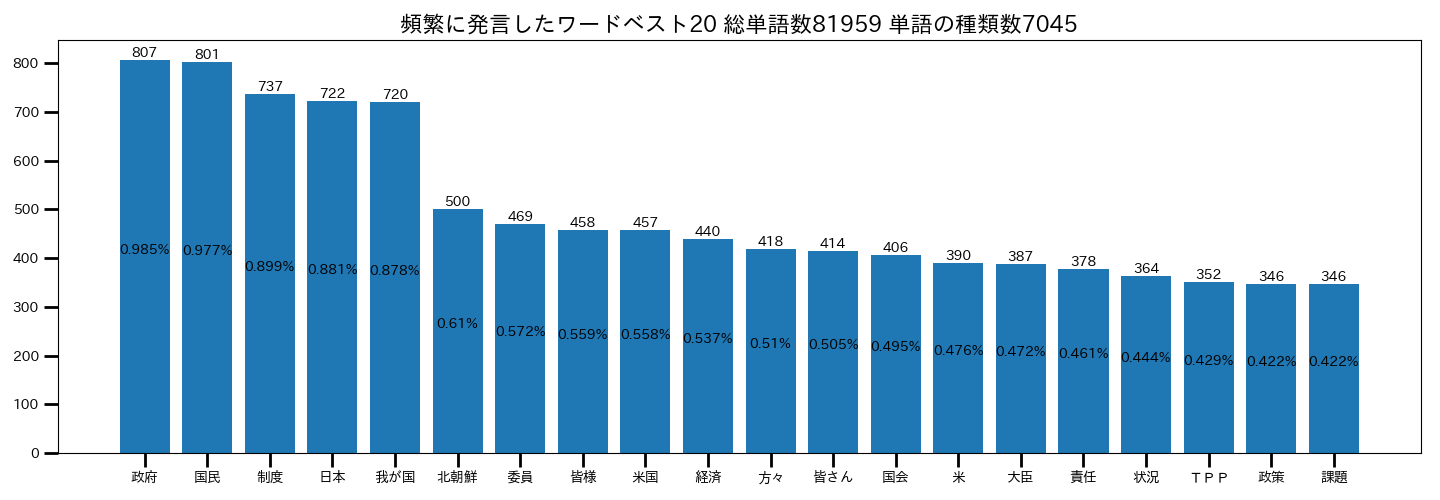
スッキリしましたね。それっぽい結果になりました。
結果の感想
やはり、内閣総理大臣。「国民」や「日本」「わが国」などの発言が上位にありますね。
その次に「北朝鮮」と出てきたのは確かになぁと思わせる単語ですね。「責任」も割と高い頻度で使われている事も分かりました。
総合的にへぇと思わせる結果になりました(自己満足
品詞の条件を変えて再度実行してみる
割といい感じの結果が出たので色々条件を変えて実行してみます。
先ほどでは名詞・一般形or固有名詞で絞ってみましたが、今度は品詞の条件を変えて実行してみます。
・全ての品詞をカウント
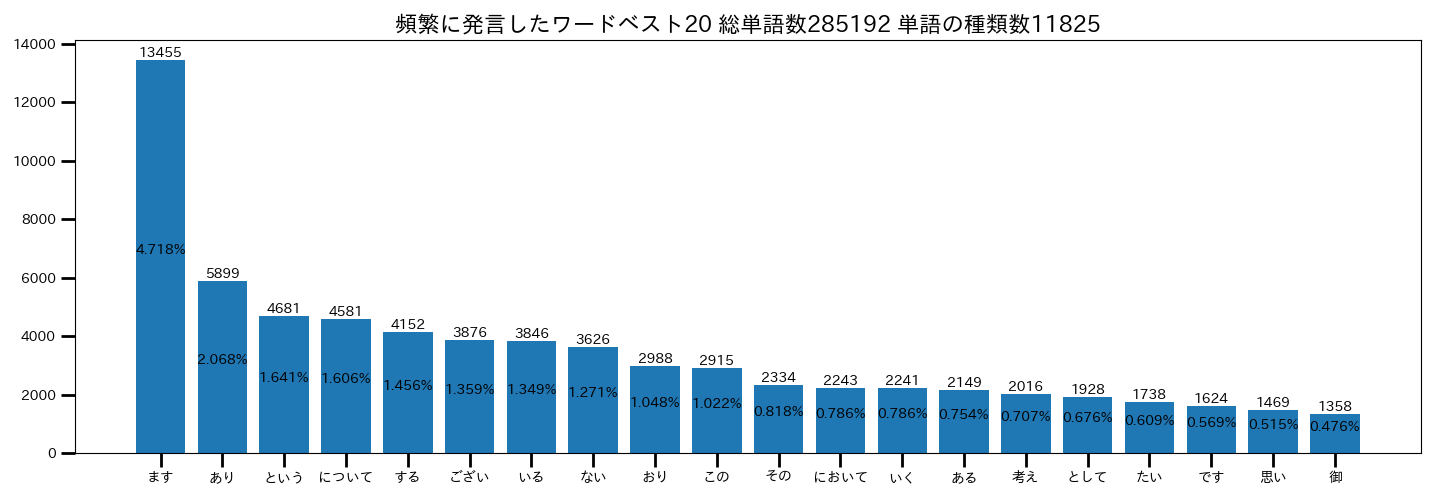
まぁそうなるよね
・名詞と形容詞をカウント
改悪された感がありますね・・・
あと、記号が入っていると思ったらこれ漢数字の0でした。mecabだと漢数字はまとまりで認識してくれないようです。
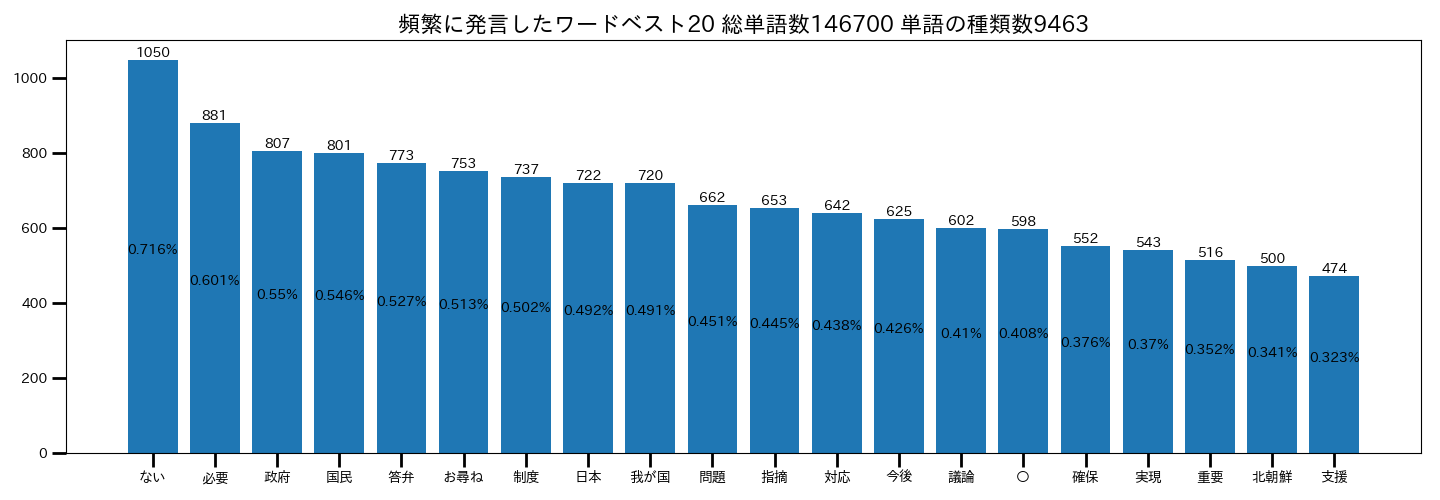
・漢数字以外の名詞全て
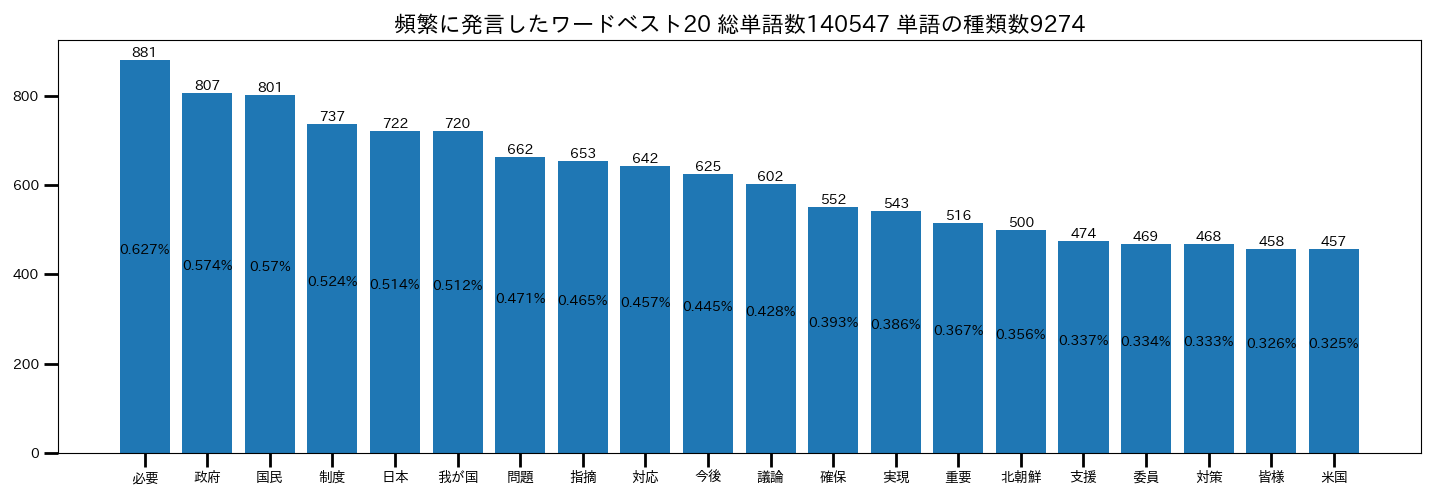
上位の単語が変わりましたね。先ほどよりもより連想しやすい単語が増えたように見受けられます。
絞り込むのは大枠の方が良いようです。
どの品詞に絞れば良策か
上記で一番見やすい結果だったのが
- 名詞+一般形or名詞+固有名詞
- 数字以外の名詞全部
でした。
個人的な見解としては、固有名詞等に絞った方がより分かりやすい単語が出てきていると考えました。
最後に
形態素解析&カウントだけでも比較できそうな結果になってくれました。
次は年別の発言などもまとめてみようと思います。