国会議事録検索とは
サイトはこちら http://kokkai.ndl.go.jp/
第1回(昭和22年5月)以降の国会会議録を検索することができるシステムです。
検索できる内容として
- 発言内容(and検索かor検索)
- 会議名
- 発言者
- 所属会派(政党)単位の発言
- 肩書き(役職)
- 日付
を指定して検索することができます。
APIを使って取得するために
この検索システムにはAPIが用意されており、そこからテキスト形式で取得することが可能です。
こちらにマニュアルがあります。 http://kokkai.ndl.go.jp/api.html
Pythonでの取得の方法について書いていきます。筆者の環境は python3.6.7です。
まずはAPIの仕様からまとめます。
取得単位の指定
APIで取得する場合、以下の二通りの方法で取得できます。
- 発言単位 http://kokkai.ndl.go.jp/api/1.0/speech?{検索条件}
- 会議単位 http://kokkai.ndl.go.jp/api/1.0/meeting?{検索条件}
いずれかを指定して取得できます。それぞれ発言者単位の場合は1度に最大100件、会議単位の場合は最大5件まで取得できます。今回は主に発言者単位で取得する方法を書きます。
検索時のパラメーター
議事録を検索する際に以下のパラメーターを指定することができます。
| 項番 | 必須区分 | パラメータ名 | 複数指定 | 備考 |
|:--|:--|:--|:--|:--|:--|:--|
| 開始位置 | 任意 | startRecord | 不可 | 省略時のデフォルト値「1」 |
| 一回の最大取得件数 | 任意 | maximumRecords | 不可 | 省略時のデフォルト値は発言単位では「30」会議単位では「2」 |
| 院名 | 選択必須 | nameOfHouse | 不可 | 衆議院、参議院、両院、両院協議会のいずれかを指定可能 指定しない場合は全院で検索 |
| 会議名 |選択必須 | nameOfMeeting | 可(OR検索) | 部分一致検索 |
| 検索語 | 選択必須 |any | 可(AND検索) | 部分一致検索 |
| 発言者名 | 選択必須 |speaker | 可(OR検索) | 部分一致検索 |
| 開会日付/始点 | 選択必須 |from | 不可 | YYYY-MM-DD で指定 | 省略時のデフォルト値は「0000-01-01」 |
| 開会日付/終点 | 選択必須 |until | 不可 | YYYY-MM-DD で指定 |省略時のデフォルト値は「9999-12-31」 |
それぞれコメント
・ 開始位置
開始位置は基本的に「1」でいいかと思います
・ 一回の最大取得件数
発言単位だと100件、会議単位だと5件が最大値です。
・ 院名
完全一致なので注意が必要です。
・ 会議名
会議名を指定できます。スペースで区切って複数指定可能です。
・ 検索語
指定した語句が含まれる発言だけを取得します。APIではAND検索のみ対応しています。
・ 発言者名
発言者を指定できます。人物名は最初にggっとくのが無難かと思いますが一応部分一致対応です。
・ 開会日付の始点
検索をスタートさせる日付を指定できます。西暦で、かつ一桁の場合は0が必須です。例:2019-01-01
・ 開会日付の終点
検索のエンドポイントを指定します。表記方法は始点と一緒です。
また、表に「選択必須」としている項目ですが
院名から日付までのいずれかは必ず指定しないとエラーを返されますのでご注意ください
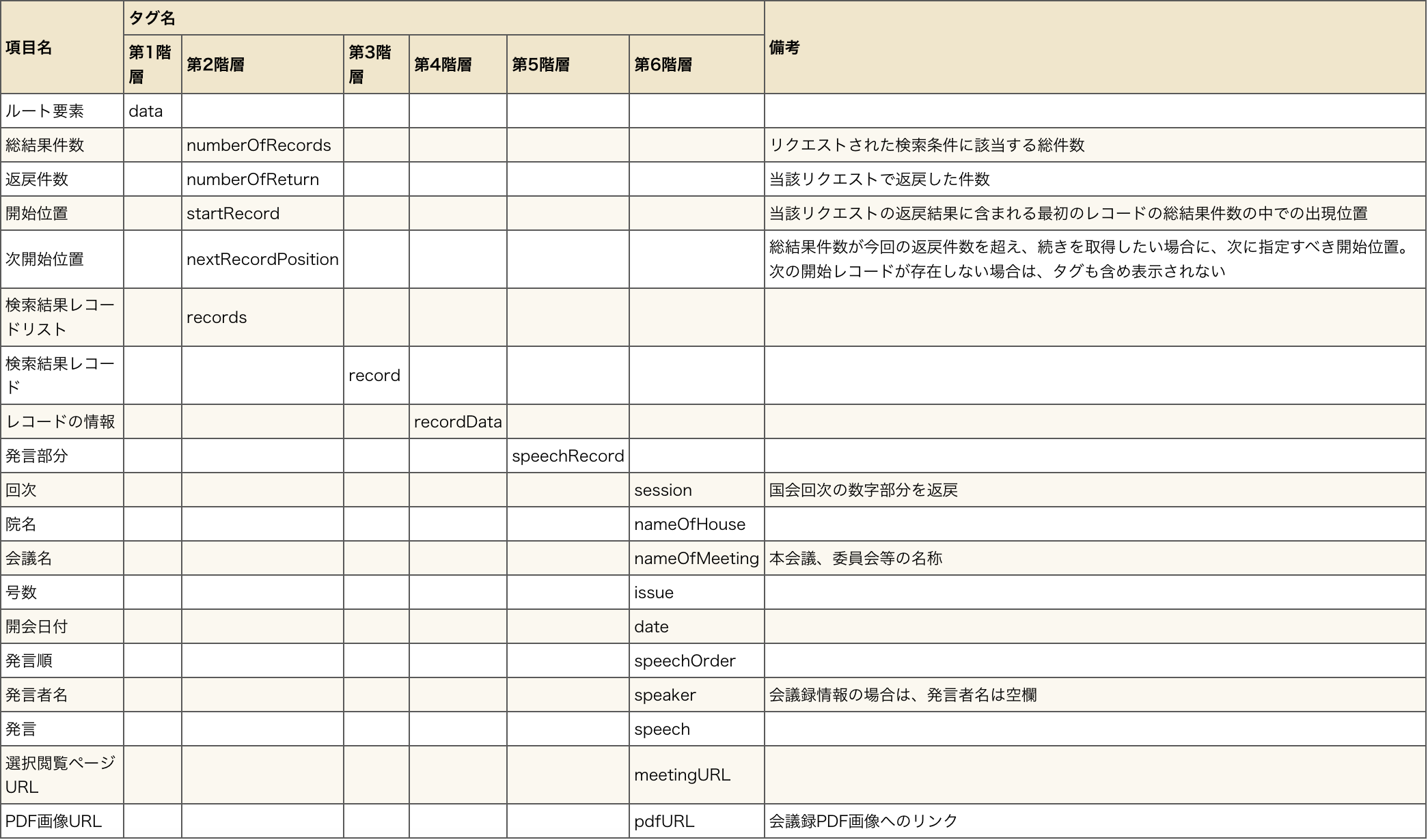
返戻タグ
検索を投げて帰ってくるデータのタグ一覧を表にした。。。かったんですけどあまりにも長いのでスクショで勘弁してください(めんどかった)
なお、実際に取得する際に思うのですが・・・
めっちゃ冗長になります
見ていただければわかると思うので貼ります。
・発言者単位で取得した場合
・会議単位で取得した場合
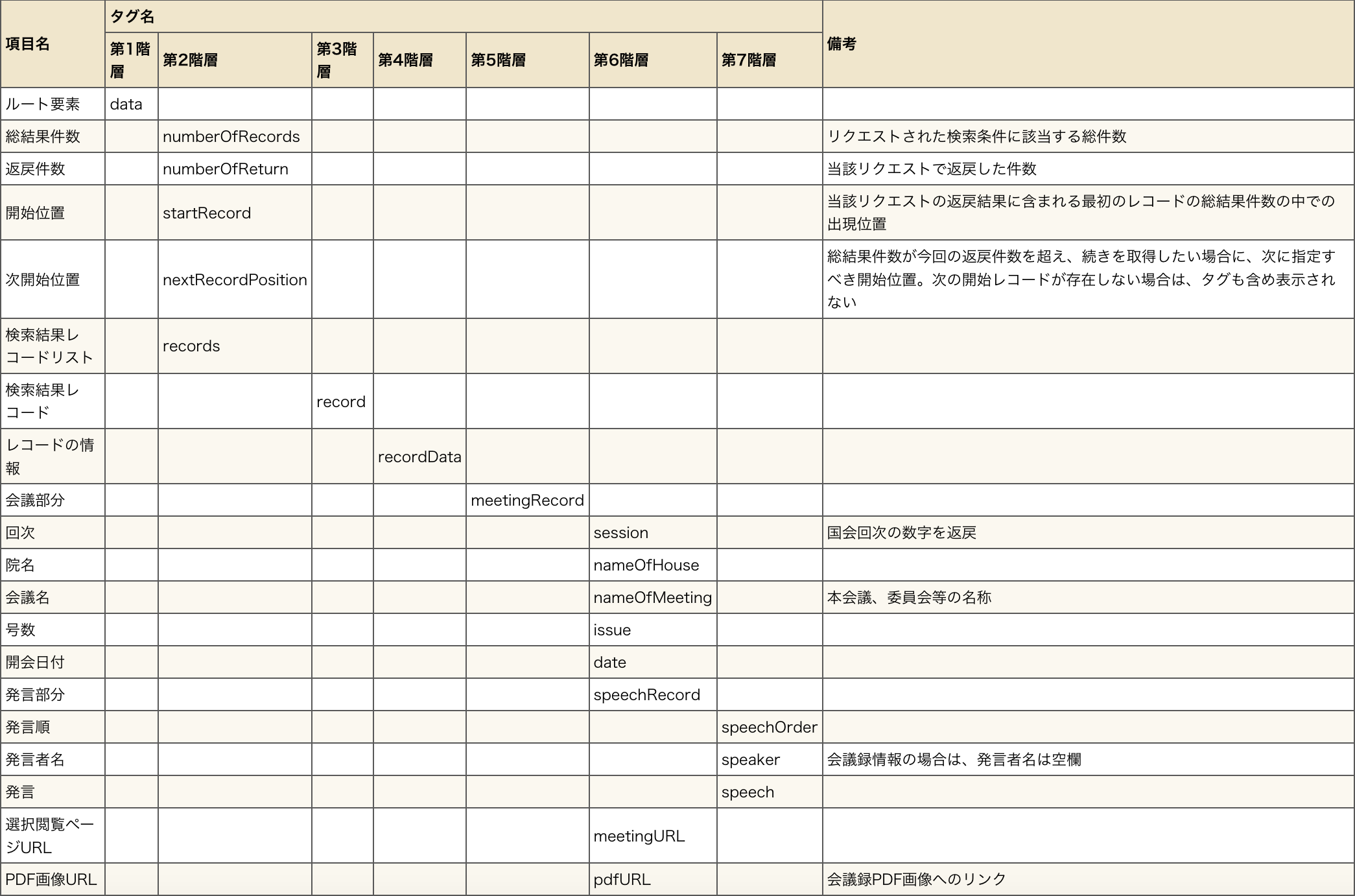
発言者単位で取得できたら、タグの間にmeeting挟む感じですかね(遠い目
pythonでAPIを叩いてみよう
前置きはこれくらいにして、早速コードを作っていきます。
語彙力不足で説明し辛いのでデモコードを出してそれを解説したいと思います。
コードへのツッコミは随時お待ちしていますのでコメントお願いしますm(_ _)m
デモコード
※追記
議事録の先頭にある発言者名が役職+名前だったり名前(役職)だったりマチマチなのを統一して名前のみにする様にしました。
import urllib, untangle, urllib.parse, os, sys
def scrape(path):
start = '1'
i = 0
Reco = ""
day = ""
chairs = ["大島理森","赤松広隆","伊達忠一","郡司彰","山崎正昭","輿石東","川端達夫","金子原二郎","向大野新治","冨岡勉","石田昌宏","郷原悟"] #議長リスト
if os.path.exists(path):
a = int(input("ファイルあるけど上書きする?:yes(0) or no(1):"))
if a:
print("しゅーりょー")
sys.exit()
else:
with open(path,'w') as f:
f.write("")
while True:
keyword = '麻生太郎'
startdate = '2018-01-01'
#enddate = '2019-12-31'
maxreco = '100'
meeting = '本会議'
search = '財務'
url = 'http://kokkai.ndl.go.jp/api/1.0/speech?'+urllib.parse.quote('startRecord=' + start
+ '&maximumRecords=' + maxreco
+ '&speaker=' + keyword
+ '&any=' + search
+ '&nameOfMeeting=' + meeting)
+ '&from=' + startdate)
#+ '&until=' + enddate)
obj = untangle.parse(url)
art = obj.data.numberOfRecords.cdata
for record in obj.data.records.record:
name = record.recordData.speechRecord.speaker.cdata
if name == '' or name in chairs: #発言者なしor議長の場合はパス
pass
else:
speechreco = record.recordData.speechRecord
if not day == speechreco.date.cdata:
Reco += speechreco.date.cdata + "\n"
day = speechreco.date.cdata
reco_line = speechreco.speech.cdata
if reco_line.find('○') == 0: #名前の置き換え
sep = re.search(pattern,reco_line)
name = '○' + name
reco_line = reco_line.replace(sep.group(1),name)
Reco += reco_line
Reco += '\n'
if not i%500: #500件超えるならここでカキコ
with open(path, 'a') as f:
f.write(Reco)
Reco = ""
try:
start = obj.data.nextRecordPosition.cdata
except AttributeError:
print("おわり")
break
i += 100
print("{0}件中{1}件目".format(art,i))
return Reco
if __name__ == '__main__':
path = sys.argv[1]
r = scrape(path)
with open(path, 'a') as f: #残りをかきこ
f.write(r)
こんな感じで使えます。途中経過も簡単に出力されるようにしています。
python demo_scrape.py 保存するファイル
日付ごとにデータを分けたかったので日付データを先頭に入れるようにしています。
2010-01-01
○麻生太郎 〜〜〜...
各パラメータから情報を取得する
デモコードを上から順に簡単に解説
冒頭の変数とか
start = '1'
i = 0
Reco = ""
day = ""
chairs = ["大島理森","赤松広隆","伊達忠一","郡司彰","山崎正昭","輿石東","川端達夫","金子原二郎","向大野新治","冨岡勉","石田昌宏"] #議長リスト
if os.path.exists(path):
a = int(input("ファイルあるけど上書きする?:yes(0) or no(1):"))
if a:
print("しゅーりょー")
sys.exit()
else:
with open(path,'w') as f:
f.write("")
この辺は議長の発言を取り除くためにリスト化して、かつ保存指定した名前のファイルがあれば警告してくれるだけですハイ
また、startにstrで「1」を入れているのはパラメーターの開始位置を指定しています。
本題はここから
検索条件の指定
keyword = '麻生太郎'
startdate = '2018-01-01'
# enddate = '2019-12-31'
maxreco = '100'
meeting = '本会議'
search = '財務'
url = 'http://kokkai.ndl.go.jp/api/1.0/speech?'+urllib.parse.quote( \
'startRecord=' + start
+ '&maximumRecords=' + maxreco
+ '&speaker=' + keyword
+ '&any=' + search
+ '&nameOfMeeting=' + meeting
+ '&from=' + startdate)
# + '&until=' + enddate)
検索時のパラメーター に詳細をまとめてますのでそちらで確認してください。
urlには発言者単位で取得するためにhttp://kokkai.ndl.go.jp/api/1.0/speech? を使用。GETで取得するのでURLに指定したいパラメータを足していきます。日本語にコーディングするためにurllib.parse.quoteを使用しています。
デモコードで指定しているパラメーターは、上から順に
- 麻生太郎の発言のみ取得
- 2018年1月1日から取得
- 一度に100件取得(最大値)
- 本会議での発言のみ取得
- 発言の中に”財務”がある発言のみ取得
以上を指定しています。開始位置から最新のものまで取得したいので取得する日付の終点は指定していません。
返戻されたデータのロード
obj = untangle.parse(url)
art = obj.data.numberOfRecords.cdata
untangle.parseで返戻されてきたXMLデータをまとめます。もし指定した条件が間違っていたり、条件にヒットした件数(会議単位)が1000件を超える場合はエラーがここで帰ってきます。
変数artにはヒットした件数(ここでは発言単位)を取得しています。
data.numberOfRecords.cdataの部分ですが返戻タグ の表より、"返戻件数"を指定しています。最後にcdataを忘れずに
次に発言データ等を取得していきます。
for record in obj.data.records.record:
name = record.recordData.speechRecord.speaker.cdata
if name == '' or name in chairs:#発言者なしor議長の場合はパス
pass
data.records.recordで検索結果を取得して、一件ずつ処理するようにしています。
変数nameに発言者名を入れています。今回の場合は"麻生太郎"を指定しているのでここでは必ず"麻生太郎"が入ります。発言者を指定していない場合、ここで議長や発言者データのない会議録情報などを取り除いています。
else:
speechreco = record.recordData.speechRecord
if not day == speechreco.date.cdata:
Reco += speechreco.date.cdata + "\n"
day = speechreco.date.cdata
reco_line = speechreco.speech.cdata
if reco_line.find('○') == 0: #名前の置き換え
sep = re.search(pattern,reco_line)
name = '○' + name
reco_line = reco_line.replace(sep.group(1),name)
Reco += reco_line
Reco += '\n'
タグが長いので変数speechrecoで省略しています。中のif文ですが、デモコードでは発言の先頭に日付データを入れていますので、その処理を書いています。変数dayに日付データを入れ、もし同日の発言であればそのまま追記し、日付が違えば先頭に追加するようにしています。
変数Recoに発言データを入れています。
追記
発言者名を役職名+名前の形ではなく、フルネームに置き換える様にしています。理由は発言者が麻生さんの場合、麻生財務大臣と財務大臣(麻生太郎)の様に形式がマチマチだったからです。
if not i%500: #500件超えるならここでカキコ
with open(path, 'a') as f:
f.write(Reco)
Reco = ""
複数件あった場合、変数に全部貯めておくと重くなりそうだったので500件ごとに書き込むようにしています。冒頭でファイルの有無を聞くのは複数回書き込むために追加書き込みの'a'を使用したいがためですハイ
try:
start = obj.data.nextRecordPosition.cdata
except AttributeError:
print("おわり")
break
i += 100
print("{0}件中{1}件目".format(art,i))
返戻タグ の"次開始位置"の項目の備考より総結果件数が今回の返戻件数を超え、続きを取得したい場合に、次に指定すべき開始位置。次の開始レコードが存在しない場合は、タグも含め表示されないとあります。
処理をwhile文で回しているのもこのためです。また、なぜtry文なのかというと、備考にもあるように次の開始レコードがない場合はタグすら無くなるわけです。つまりエラー吐かれたら次はないよ→終わり⭐︎ です。その下のprint文は途中経過の出力です。プログラムが動いているのか確認が取れないと不安になりますよね(よね!)
with open(path, 'a') as f: #残りをかきこ
f.write(r)
100件ごとに区切っていますので端数分が出ることがあるので最後に追記して終了です。お疲れ様でした。
最後に
タグ長すぎ