世間ではsbtはSimple Build Toolの略だという噂もありますが,ぶっちゃけ全然simpleじゃないです笑1
今回は試しにsbt-gcsというsbtのpluginを自作してみたので,これをベースに(私の思う)sbtのややこしい部分を解説しつつ,sbt pluginの開発から公開までの手順を紹介しようと思います!
こんな人にオヌヌメ
- sbtのpluginを作って見たい人!
- sbtを使ったことはあるが次のコードがようわからんっていう人
gcsUrls in gcsDelete := Seq(
"gs://bucket_name/path/to/object/to/delete.json"
)
前提
とりあえず筆者の環境は以下の通りでした.
- sbt 1.1.0
- Scala 2.12.4
はじめに
sbtは全然simpleではありませんが,ドキュメントはかなりしっかりしています.
公式ドキュメント厨の方は,ここ2つを読めば基本プラグイン開発には困らないはずです!
Plugin開発
sbt pluginの開発に当たって最低限必要なのは,以下のみです.
順に説明していきます.
- build.sbtで
sbtPlugin := trueを設定 - keyの定義
- AutoPluginを継承したobjectを実装
1. build.sbtの設定
ここは特筆すべきところはないです.
sbtPlugin := true を設定しておきましょう.
自分は以下のように書きました.
lazy val root = (project in file("."))
.settings(
name := "sbt-greet",
organization := "com.github.saint1991",
version := "0.1.0",
scalaVersion := "2.12.4",
sbtPlugin := true,
sbtVersion := "1.1.0"
)
2. keyの定義
これがsbtの基礎でありながらも,Simpleならざるものにしている要因でしょう.便利な機能なんですけどね...
ここではsbtの各種keyについて説明したいと思います.
sbtにおけるkeyはMapのkeyと近いものではあるのですが,大きく違うのはkey毎にscopeという概念をもっていることです.なので,keyとscopeの組み合わせで初めて値が定まります.
簡単な例を以下に示します.
// keyの定義
val whom = SettingKey[String]("whom", "the name of person whom greet")
val greet = TaskKey[Unit]("greet", "greet to a person")
// greetというtaskのscopeにおけるwhomの値を"saint1991"に設定
whom in greet := "saint1991"
Keyについて
まずkeyについてですが,sbtでは
| key | description |
|---|---|
| SettingKey | projectがロードされる際に一度だけ評価される |
| TaskKey | 実行毎に毎回評価される |
| InputKey | コマンドラインから入力をとる以外はTaskKeyと同様 |
の3つがあります.
基本的には何らかの処理をsbtのtaskとして実装したい場合はTaskKey,
CLIから何か引数を渡して処理を変えたい場合はInputKeyを使います.
SettingKeyは上記2つのタスク内で利用する設定値を定義するのに使います.
これがPluginを利用する側のbuild.sbtにおける設定項目になります.
多くの場合はSettingKey + TaskKeyの組み合わせで実装できるでしょう.
Scopeについて
こちらがややこしいのですが,sbtの各keyにはscopeの概念があります.
すなわち,同じkeyでも,scopeによって異なる値を持つことが可能です.
scopeにはざっくり言うと以下のようなものがあり,この粒度ごとに違う設定を持つことができるようになっています2.
- Build全体
- サブプロジェクト毎
- Task毎
ちなみに関係を図にすると下の図のようになるはずです.(やや自信なし)
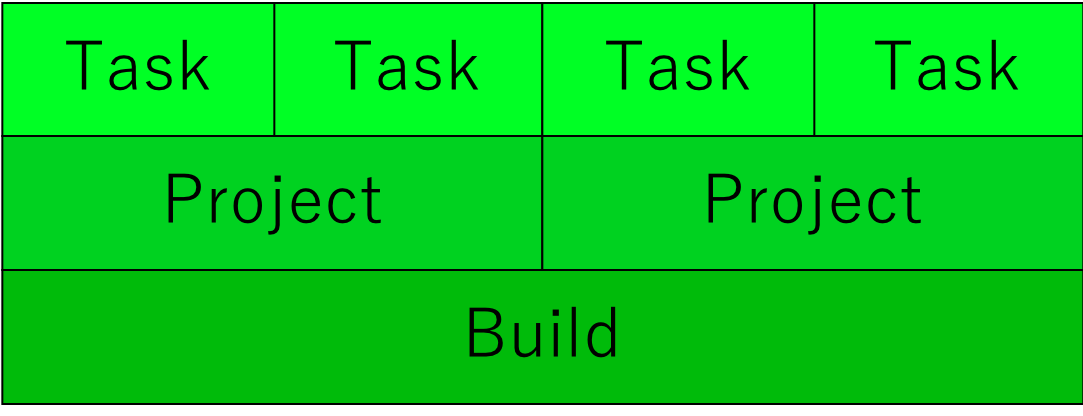
上の方が細かい粒度になりますが,その粒度のscopeに設定値がない場合は一つずつ大きいscopeにフォールバックします.つまりTaskを実行する際は,まずそのTaskのscopeにおける設定値が使われますが,それが未設定の場合,Project, Buildのscopeの値が順に探索され,最初に見つかった値が使われます.
keyを特定のscopeに関連づける場合,下記のようにinメソッドを使います.
// task scope
whom in greet := "saint1991"
// project scope
whom in ThisProject := "saint1991"
// build scope
whom in ThisBuild : = "saint1991"
// 省略されている場合は設定を記述している場所に合わせて自動でscopeが決まる
// topレベルだとbuild scope
whom := "saint1991"
// subprojectの設定に書くとproject scope
lazy val root = (project in file("."))
.settings(
whom := "saint1991"
)
これらを踏まえると,最初のこの例は,gcsDeleteというTaskのscopeにおけるgcsUrlsの値を設定しているコードだったということがお分かりいただけたのではないでしょうか.
gcsUrls in gcsDelete := Seq(
"gs://bucket_name/path/to/object/to/delete.json"
)
taskの定義
これらを踏まえて,標準出力に Hello $whom を出力するTaskを定義してみます.
val whom = SettingKey[String]("whom", "the name of person whom greet")
val greet = TaskKey[Unit]("greet", "greet to a person")
greet := Def.task {
val name = (whom in greet).value // greetタスクに関連づけられたnameの値を取得
println(s"Hello $name")
}.value
上記はとても簡単な例ですが,自作Pluginを作る場合も基本は同じです.
各種Keyを定義し,TaskKey, InputKeyの中身を実装していくだけです.
ちなみに上記ではgreetというタスクが作られるので,次のように起動できます.
結局sbtコマンドも特定のkeyを評価しているだけです.
$ sbt greet
Hello saint1991
3. AutoPluginを継承したobjectを実装
このAutoPluginがsbtプラグインの実体です.sbtにどのようにロードするかをここで規定します.
コードは下記のようになります. 下記では少し端折っていますがこちらのコードはgistにも上げてあります.
package com.github.saint1991
import sbt._
import sbt.Keys._
object SamplePlugin extends AutoPlugin {
// (1) autoImport内のフィールドはobjectはimportしなくても読み込まれる
object autoImport {
val whom = SettingKey[String]("whom", "the name of person whom greet")
val greet = TaskKey[Unit]("greet", "greet to a person")
}
import autoImport._
// (2) どういう条件でPluginがロードされるかを規定する
// allRequirementsにしておくと依存Plugin(今回はない)が全て読まれていれば勝手にロードされるようになる
override def trigger = allRequirements
// (3) settingsにいちいち記述するのは面倒なので,Pluginがロードされたらprojectに勝手にkeyが定義されるようにしている
override def projectSettings: Seq[Def.Setting[_]] = super.projectSettings ++ Seq(
whom in greet := "saint1991",
greet := Def.task {
println(s"Hello ${(whom in greet).value}")
}.value
)
}
コード中にもコメントで記載してありますが,簡単にポイントを説明しておくと
まず(1)について,keyはautoImportという名前のobjectに定義するとよいです.
autoImport中のフィールド(ここではwhomとgreetというkey)は,Plugin利用側のbuild.sbtでimport文なしで参照することができます3.
(2)(3)がAutoPluginのメソッドで,Pluginとしての機能を規定します.
(2)のtriggerメソッドでは,どのような条件下でこのPluginを有効にするかを規定します.
allRequirementsを設定しておくと,依存するPlugin (上記のサンプルだと特にないですが)が有効な場合に,このPluginも自動で有効化されるようになります.
(3)が利用側のbuild.sbt内で規定される各種設定項目にあたるものですが,ここではprojectSettingsに各種keyの実装が追加されるようにoverrideしてあります.
このようにしておくことで,Pluginが読み込まれた際に,利用側のbuild.sbtにこれらの実装が自動で追加されるようになります.
ここまででsbt pluginをつくるのに十分な知識がおそらく身についたはずです.
より具体的な実装を知りたい場合は,ぜひこちらのsbt-gcsのリポジトリを参考にしてみてください!
Pluginを公開する
出来上がったPluginはやっぱり公開して使ってもらいたいですよね!
sbtは親切なのでこの辺りもしっかりドキュメントがあります.
1. Bintrayにrepositoryを作成
基本的にsbt pluginはBintrayでホストしているようです.
なのでPluginをリリースする際はこちらにpublishするのが良さそうです.
上記のドキュメント通りに操作していくだけですが,まずはサインアップしましょう!
次にAdd New Repositoryを選択し, sbt-pluginsというGeneric repositoryを作成します4.
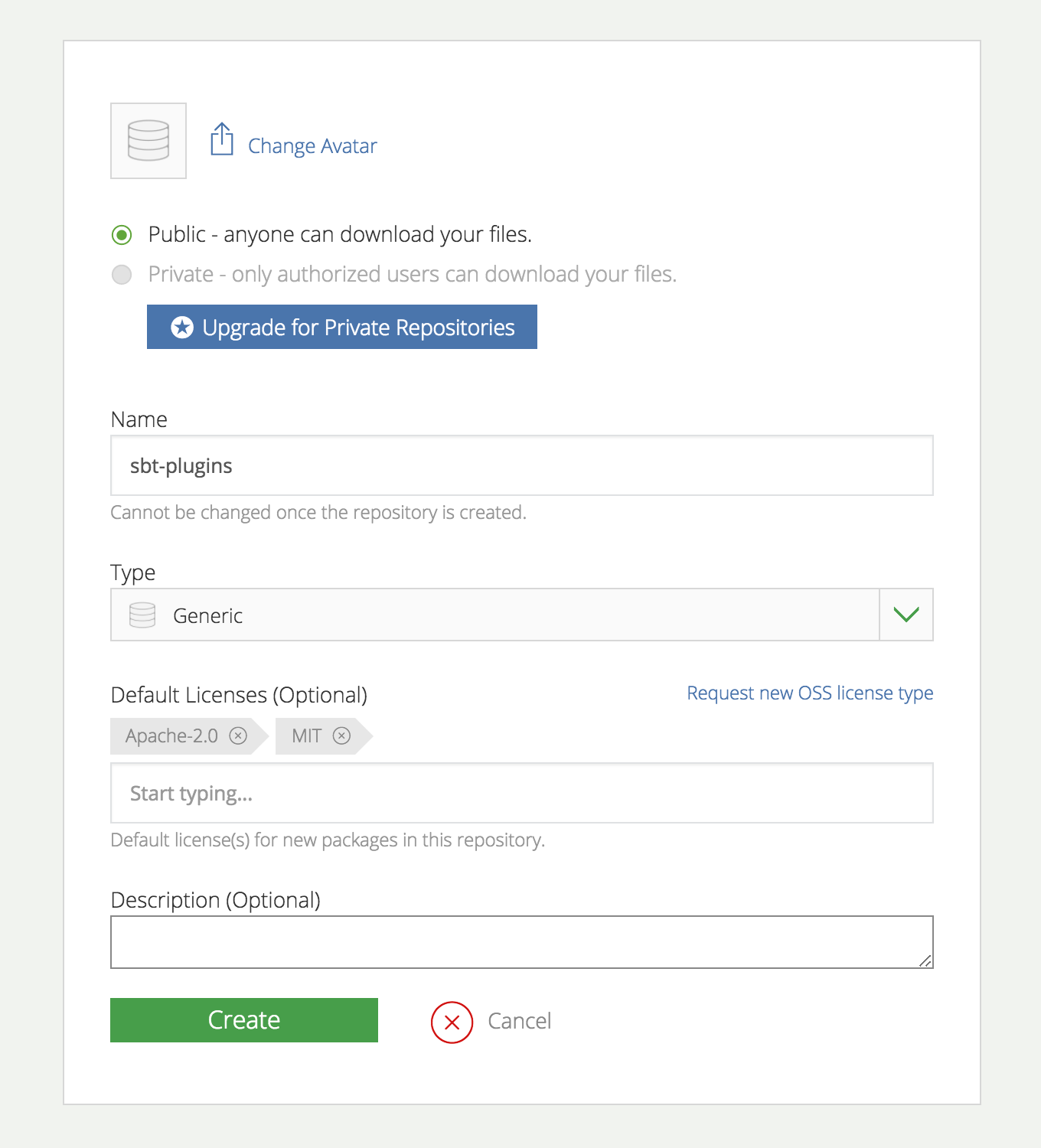
これでPluginの置き場はできたので,あとはPublishするだけです.
2. リリース
次に1.で作ったRepositoryにPluginをPublishしてリリースします.
ここでは次の2つのsbt pluginを使うと良さそうです.
| name | description |
|---|---|
| sbt-bintray | BintrayにjarをPublishするためのPlugin |
| sbt-git (Optional) | Gitと連携してLibraryのバージョン管理を楽にしてくれる神Plugin |
自分はこんな風に書いてます.
addSbtPlugin("org.foundweekends" % "sbt-bintray" % "0.5.2")
addSbtPlugin("com.typesafe.sbt" % "sbt-git" % "0.9.3") |
2番目のsbt-gitは厳密には必要ないのですが,LibraryのversionにGitのcommit hashやtagを使ってくれるようになるので,Pluginのバージョン管理に非常に便利です!
自分はリリース時にGitでtagを打ってpublishするという運用にしています.
sbt-sonatypeを使って先ほど作成したBintray repositoryにpublishするために,build.sbtに下記を追加します.下記では部分的にしか記載していませんが,全容を見たい場合はこちらを参照してください.
settings(
publishMavenStyle := false,
startYear := Some(2018),
licenses += ("Apache-2.0", new URL("http://www.apache.org/licenses/LICENSE-2.0")), // Licenseは適宜選んでください
bintrayRepository := "sbt-plugins", // ここに1.で作成したrepository名を入れる
bintrayOrganization in bintray := None // こちらは1でorganizationを指定して作った場合のみ
)
次にbintrayChangeCredentialsタスクでBintrayのクレデンシャル情報を設定します.
$ sbt bintrayChangeCredentials
Enter bintray username: saint1991
Enter bintray API key (under https://bintray.com/profile/edit): ********************************
ユーザ名とAPI Keyが必要です. API Keyはこちらから確認できます.
ここまで設定が終われば準備は完了です. Publishしましょう!
$ sbt publish
これでリリース完了です!
sbt公式Pluginにする (おまけ)
ここまでで,世界中のユーザから使ってもらえる状態にはなっていますが,今のままだと使ってもらう際に下記のように自身のrepositoryをresolverに追加してもらう必要があり,ユーザからすると若干めんどうです...
resolvers += Resolver.bintrayIvyRepo("saint1991", "sbt-plugins") // Bintrayユーザ名, repository名
sbt公式のPluginにすることで,sbtのデフォルトresolverに設定されているrepositoryに関連づけることができるため,上記の設定なしでPluginを使うことができるようになります.
こちらにsbt pluginの公式organizationがあるので,自分の作ったPluginを追加してもらえるように申請します.
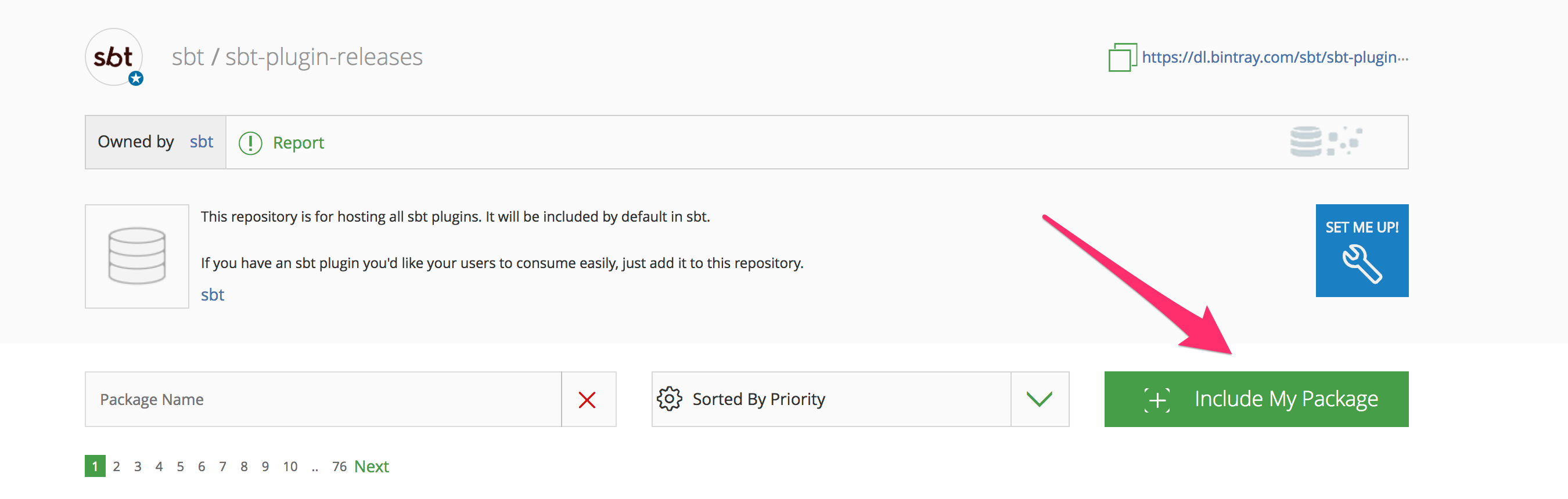
ここで作成したPluginの名前を入力し,下記のようにPluginの概要を記載し申請を出します.
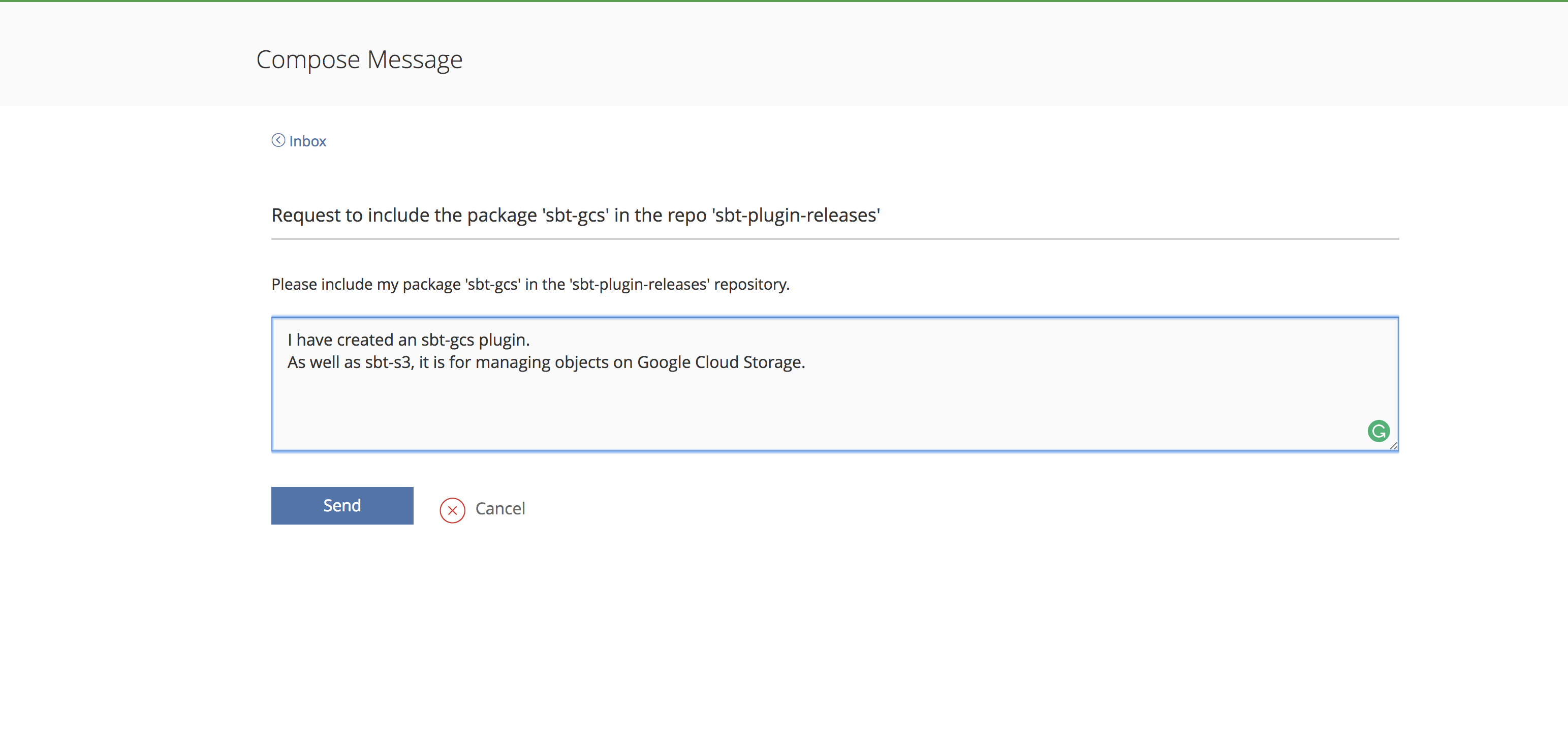
これを送信すれば,メンテナーのレビューを経てsbtの公式organizationに取り込まれ,resolverの追加設定なしでPluginを使えるようになります!
Pluginを周知する (おまけ2)
ベストプラクティスに記載されている通り下記をやっておきましょう!
- Twitterで周知する,
- 公式リファレンスに載っける.
1. Twitterで周知する.
@scala_sbtにメンションをつけてツイートします.自分はこんな感じにしました.
https://twitter.com/saintech1991/status/961633397251612673
公式リファレンスに載っける
こちらを編集してPRを出しましょう!
最後に
sbt pluginの作り方からリリースまでを紹介しました!
Scala/sbt界隈は強い人がたくさんいらっしゃるので間違っていればすぐ指摘が入るでしょう笑
マサカリぶん投げお待ちしております.すぐ直します.
sbt-gcsもScala×sbt×GCPというニッチな需要にお応えできる一品になっています5.
ぜひ使ってやってください. PRもお待ちしております!
-
あくまで個人の感想です ↩
-
厳密にはConfigurationという別軸のscopeも持つことができますが,ここでは紹介しません.詳細はこちらを参照.おそらくConfigurationの出番はそこまで多くはないはずです. ↩
-
通常なら
import com.github.saint1991.autoImport._を書かないとwhomやgreetがbuild.sbtで参照できないところですが,autoImportに書いておくとこれが不要になります. ↩ -
厳密には名前はなんでもいいようです. ↩
-
自分たちはDataProcでSparkMLをぶん回すために,sbt-assemblyで作ったfatJarをpublishするのに使っています.多分用途はそれぐらいしかないでしょう笑 ↩