最近は生成AIを活用して、コード書いてもらうことができるようになったけど、ブロック線図のSimulinkモデルはまだ作れません。
Simulinkユーザはもどかしい思いをしていると思います。
まだ実用レベルでは無いけれど、生成AIを使って、ちょっと回り道をしてSimulinkモデルを生成してみました。
Simulinkモデル生成までの手順
次の手順で生成しました。
- 生成AIでVerilogコード生成(整数型)
- VerilogコードをSimulinkにインポート(importhdl)
- データ型を整数型から浮動小数点型に変換
SimulinkにはCコードを取り込む機能がありますが、これは隠蔽化された1つのブロックとなり、内部処理を編集できません。
それに対して、VerilogコードをSimulinkにインポートするimporthdlは、Simulink基本ブロックで構成された編集可能なモデルを自動作成してくれます。
データ型を変更したり、処理の一部を編集することができ、バーサタイルに利用できそうです。
Verilog生成プロンプト
IIRフィルタを生成させてみることにしました。
というのも、GPTくんにどんなVerilogコードのリクエストが多いか聞いてみたところ、こんな答えが返ってきました。FIR/IIRフィルタ以外は、あまりSimulink向きではない・・・
✅ よくリクエストされるVerilog回路(生成AI向け)
- ALU(算術論理演算器)
- シリアル通信(UART Tx/Rx)
- I2C / SPI マスター・スレーブ
- FSM(有限状態機械)
- メモリコントローラ
- デジタルフィルタ(FIR / IIR)
- PWM制御器
- 除算器・平方根器
- リングバッファ / FIFO
- クロックドメイン越え回路(CDC)
他方、Simulinkモデル生成のリクエストランキングは(GPTくん、作れないだろうに(笑))
✅ よくリクエストされるSimulinkモデルの例
- PIDコントローラブロック(チューニング付き)
- FIR/IIR デジタルフィルタブロック
1.PWM生成ブロック - リングバッファ / FIFO
- 状態遷移ロジック(Stateflow FSM)
- クロックドメイン越え(CDC同期)
- 除算器(逐次比較法/非同期)
- ADCサンプリング+ホールド処理
・・・・
Simulinkモデルに除算器作るリクエストはしないだろう(笑)
両回答がGPUの中でクロストークしてそうですが・・・
※システムレベルのモデルはいきなり難しそうなので、コンポーネントレベルのモデルでとGPTくんには言い聞かせてます。
生成されたVerilogコード
下記のプロンプトでVerilogコードを生成しました。
ChatGPTとGeminiによって生成されたVerilogコードも貼っておきます。
以下の仕様に基づいて、Verilog-2001に準拠した2次IIRフィルタのコードを生成してください。
【仕様】
- フィルタ構造:Direct Form I(直接形Ⅰ)
- 入力幅:16bit、出力幅:16bit(符号付き)
- 係数:外部入力(b0, b1, b2, a1, a2 各16bit、符号付き固定小数点)
- 入出力:1入力(data_in)、1出力(data_out)
- 飽和処理:なし
- 論理合成可能な構造としてください(SystemVerilog構文は禁止)
- 使用禁止:localparam、浮動小数点、generate文、非同期遅延
【出力形式】
- 完全なVerilogコード(モジュール宣言含む)
- 可能であれば、ブロック図と簡単なコメントも付けてください
module iir_filter_2nd_order (
input wire clk,
input wire reset,
input wire signed [15:0] data_in,
input wire signed [15:0] b0,
input wire signed [15:0] b1,
input wire signed [15:0] b2,
input wire signed [15:0] a1,
input wire signed [15:0] a2,
output reg signed [15:0] data_out
);
// 内部レジスタ(16bit x 2 乗算 → 32bit 結果)
reg signed [15:0] x1, x2;
reg signed [15:0] y1, y2;
wire signed [31:0] mult_b0 = data_in * b0;
wire signed [31:0] mult_b1 = x1 * b1;
wire signed [31:0] mult_b2 = x2 * b2;
wire signed [31:0] mult_a1 = y1 * a1;
wire signed [31:0] mult_a2 = y2 * a2;
wire signed [31:0] acc_input = mult_b0 + mult_b1 + mult_b2;
wire signed [31:0] acc_output = acc_input - mult_a1 - mult_a2;
// 出力の16bitへスケーリング(右シフトで固定小数点換算)
wire signed [15:0] y_next = acc_output[30:15]; // Q1.15 固定小数点のスケーリング例
always @(posedge clk or posedge reset) begin
if (reset) begin
x1 <= 16'sd0;
x2 <= 16'sd0;
y1 <= 16'sd0;
y2 <= 16'sd0;
data_out <= 16'sd0;
end else begin
// 過去値の更新
x2 <= x1;
x1 <= data_in;
y2 <= y1;
y1 <= y_next;
// 出力反映
data_out <= y_next;
end
end
endmodule
/*******************************************************************************
* Module: iir_df1
* Description: 2nd-Order IIR Filter (Direct Form I)
* Language: Verilog-2001
*
* Specifications:
* - Structure: Direct Form I
* - Data Width: 16-bit signed input, 16-bit signed output
* - Coefficients: 16-bit signed external inputs
* - No saturation logic
******************************************************************************/
module iir_df1 (
// System Signals
input clk,
input rst_n,
// Coefficient Inputs (16-bit signed fixed-point)
input [15:0] b0,
input [15:0] b1,
input [15:0] b2,
input [15:0] a1,
input [15:0] a2,
// Data I/O (16-bit signed)
input [15:0] data_in,
output reg [15:0] data_out
);
//------------------------------------------------------------------------------
// Internal Registers
//------------------------------------------------------------------------------
// Delay registers for input x[n] and output y[n]
reg [15:0] x_d1, x_d2; // x[n-1], x[n-2]
reg [15:0] y_d1, y_d2; // y[n-1], y[n-2]
// Pipeline registers to hold intermediate products and sums
// Multiplication results are 32-bit
reg signed [31:0] p_b0_r, p_b1_r, p_b2_r;
reg signed [31:0] p_a1_r, p_a2_r;
// Register for the full-precision result before truncation
// Sum of three 32-bit numbers requires more bits to avoid overflow
reg signed [34:0] y_full_r;
//------------------------------------------------------------------------------
// Combinatorial Logic (Multiplications)
//------------------------------------------------------------------------------
// $signed is crucial for correct signed multiplication
wire signed [31:0] p_b0 = $signed(data_in) * $signed(b0);
wire signed [31:0] p_b1 = $signed(x_d1) * $signed(b1);
wire signed [31:0] p_b2 = $signed(x_d2) * $signed(b2);
wire signed [31:0] p_a1 = $signed(y_d1) * $signed(a1);
wire signed [31:0] p_a2 = $signed(y_d2) * $signed(a2);
//------------------------------------------------------------------------------
// Sequential Logic (Registered operations)
//------------------------------------------------------------------------------
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
// Reset all state elements
x_d1 <= 16'sd0;
x_d2 <= 16'sd0;
y_d1 <= 16'sd0;
y_d2 <= 16'sd0;
p_b0_r <= 32'sd0;
p_b1_r <= 32'sd0;
p_b2_r <= 32'sd0;
p_a1_r <= 32'sd0;
p_a2_r <= 32'sd0;
y_full_r <= 35'sd0;
data_out <= 16'sd0;
end
else begin
// --- Pipeline Stage 1: Update delay lines and register products ---
// Update input delay line
x_d1 <= data_in;
x_d2 <= x_d1;
// Update feedback delay line (uses the previous cycle's output)
y_d1 <= data_out;
y_d2 <= y_d1;
// Register the results of the combinatorial multiplications
p_b0_r <= p_b0;
p_b1_r <= p_b1;
p_b2_r <= p_b2;
p_a1_r <= p_a1;
p_a2_r <= p_a2;
// --- Pipeline Stage 2: Summation and Subtraction ---
// Calculates the full-precision result using the registered products from Stage 1
y_full_r <= (p_b0_r + p_b1_r + p_b2_r) - (p_a1_r + p_a2_r);
// --- Pipeline Stage 3: Truncation and Output ---
// Truncates the full-precision result from Stage 2 and assigns to output
// Note: This assumes a fixed-point format where the upper 16 bits are the desired output.
// For example, if inputs/coeffs are Q1.15, the product is Q2.30.
// Taking [31:16] effectively shifts right by 16, resulting in Q2.14.
// The user must manage the fixed-point scaling.
data_out <= y_full_r[31:16];
end
end
endmodule
VerilogコードをSimulinkモデルに変換するimporthdl
importhdlは、VHDLやVerilogコードをSimulinkにインポートするMATLABコマンドです。
これを使ってAIが生成したVerilogをSimulinkに変換しました。
importhdlによる変換手順
変換手順は以下を実行するだけ。Verilogのパーサーが走り、自動的に変換され、モデルファイルが出来上がります。
>> importhdl('iir_filter_2nd_order.v')
### iir_filter_2nd_order.v を解析中です。
### Top Module name: 'iir_filter_2nd_order'.
### Identified ClkName::clk.
### Identified RstName::reset.
### Hdl インポートの解析が完了しました。
### 未接続のコンポーネントを削除します。
### Creating Target model iir_filter_2nd_order
### モデルの生成 'iir_filter_2nd_order' を開始...
### 最適化関連の変更 (IO、面積、パイプライン) により DUT をレンダリング中...
### Start Layout...
### 処理している階層の場所 ---> 'iir_filter_2nd_order'。
### コンポーネントを配置しています。
### 処理している階層の場所 ---> 'iir_filter_2nd_order/iir_filter_2nd_order'。
### コンポーネントを配置しています。
### Drawing block edges...
### Drawing block edges...
### モデルの生成が完了しました。
### モデル パラメーターの設定中。
### 生成されたモデル ファイル iir_filter_2nd_order.slx。
### importhdl が完了しました。
変換後のモデルの検証と活用
さて、モデルは出来たけど、ホントにちゃんと動くのかよ!ってのが心配なところ。
これがインポートされたモデルの内部構成。それほど複雑なアルゴではないので、見やすいスッキリしたモデルが生成されています。
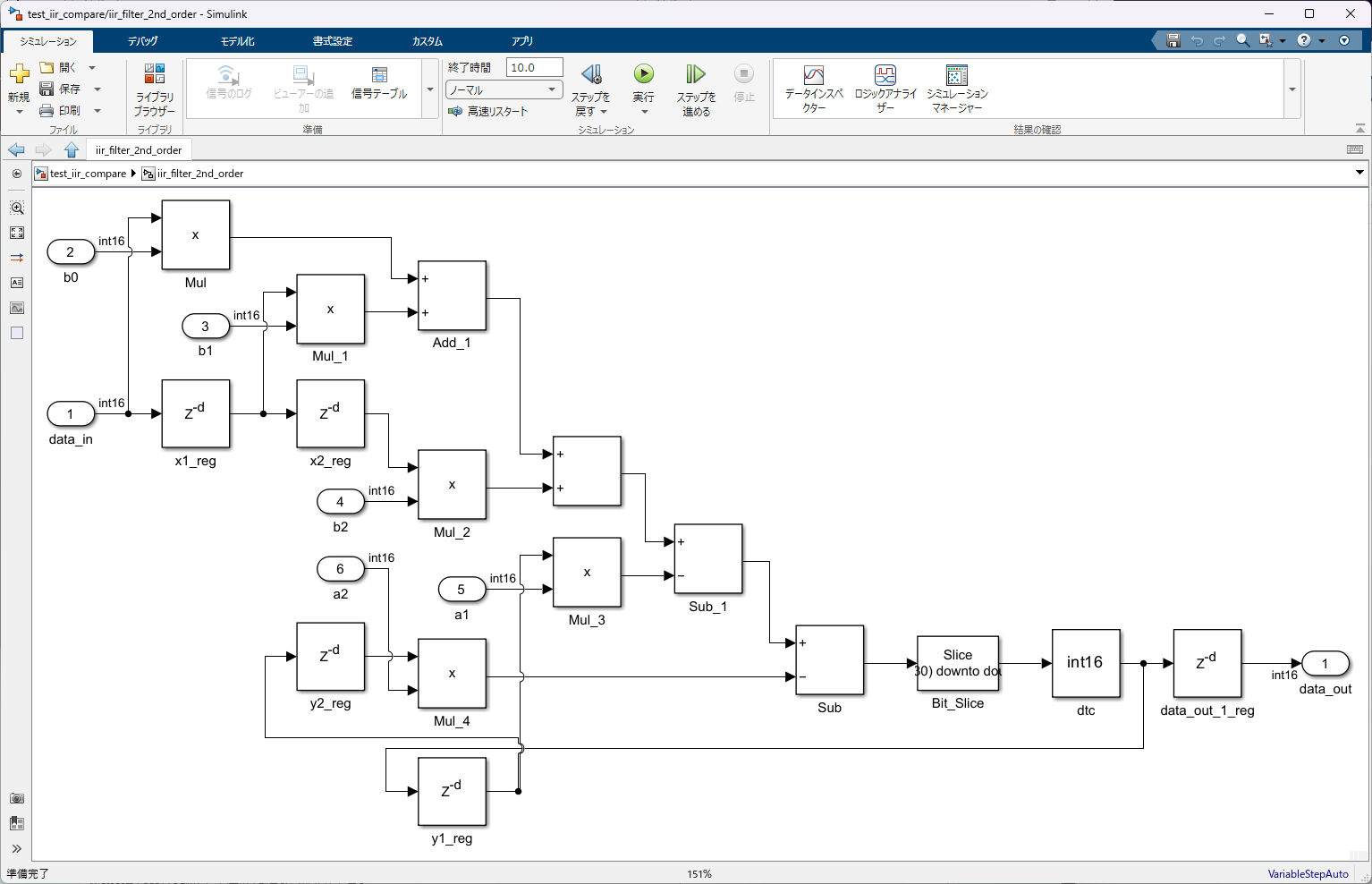
とりえあず、素の状態で動作検証してみました。
サンプリング周波数:1kHz
テストベクタ:10~500Hzのチャープ信号
リファレンス:SimulinkのBiquad(IIR) Filter
データ型:入力 int16、出力 int16
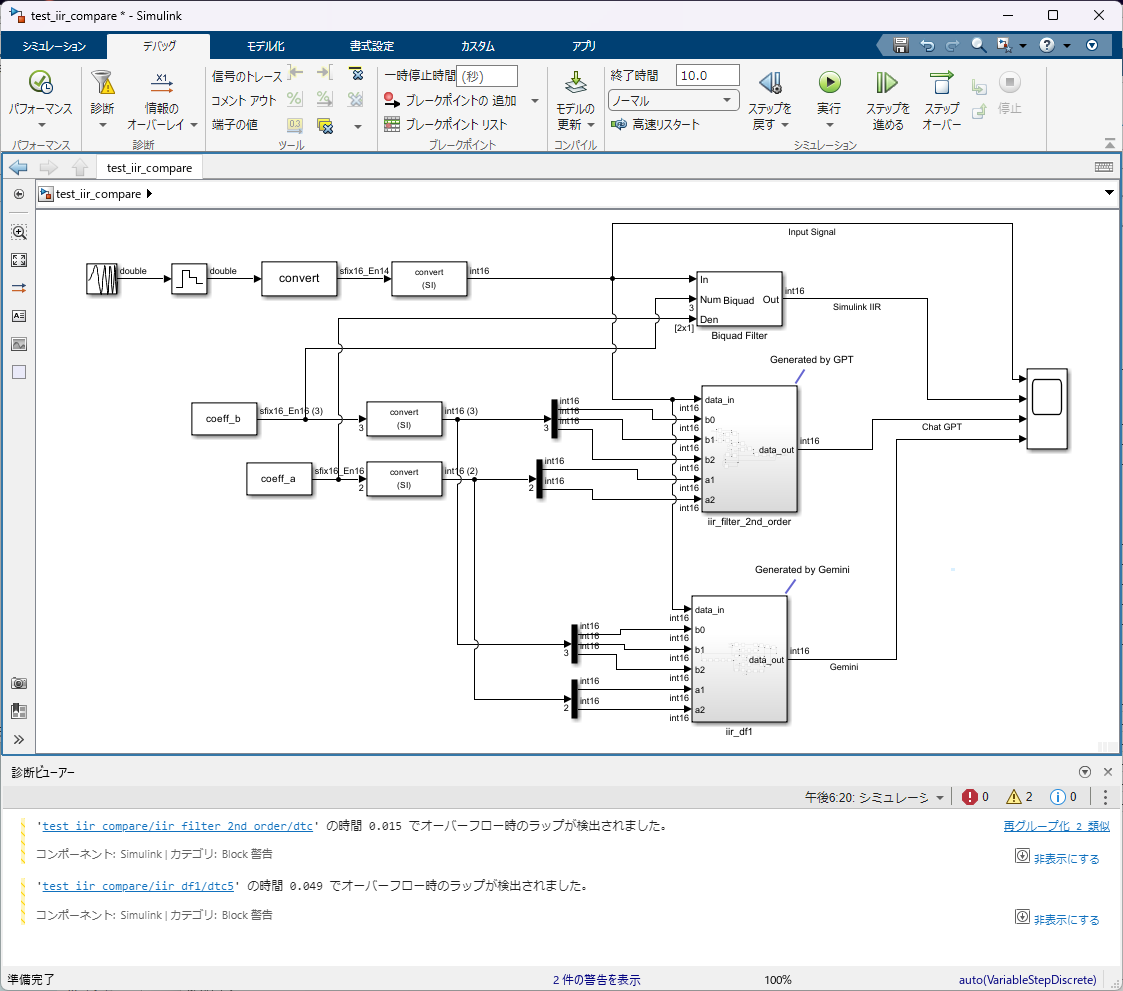
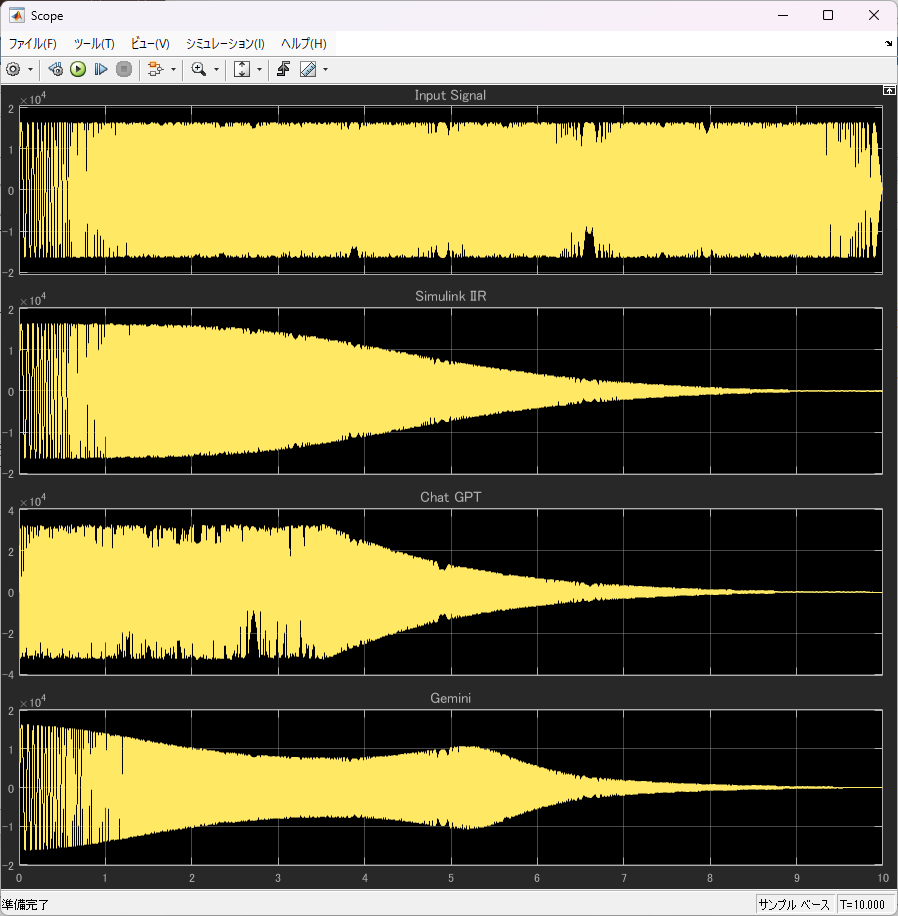
結果は残念ながら三者三様(笑)
データ型の自動変換
元がVerilogということもあって、固定小数点演算でオーバーフローが生じている模様。なので、次のコードを実行して、全ブロックのデータ型を継承に変更しました。(手動でやるのは面倒なので・・・)
%% サブシステムのデータ型を継承に自動変更
blocks = find_system(gcs);
len = length(blocks);
%% 各ブロックのデータ型を継承に変更
for n = 2:len
btype = get_param(blocks{n}, 'BlockType');
if strcmpi(btype, 'Inport')||strcmpi(btype, 'Outport')
try
set_param(blocks{n}, 'OutDataTypeStr', 'Inherit: auto');
end
elseif strcmpi(btype, 'Constant')
try
set_param(blocks{n}, 'OutDataTypeStr', 'Inherit: Inherit via back propagation')
end
else
try
set_param(blocks{n}, 'OutDataTypeStr', 'Inherit: Inherit via internal rule')
end
try
set_param(blocks{n}, 'AccumDataTypeStr', 'Inherit: Inherit via internal rule')
end
end
end
これで入力信号を浮動小数点データ型にすれば、内部演算も浮動小数点になり、オーバーフローが生じることはなくなりますが・・・
残念ながらGeminiはアルゴに間違いがあるようで、結果は依然として異なりました。
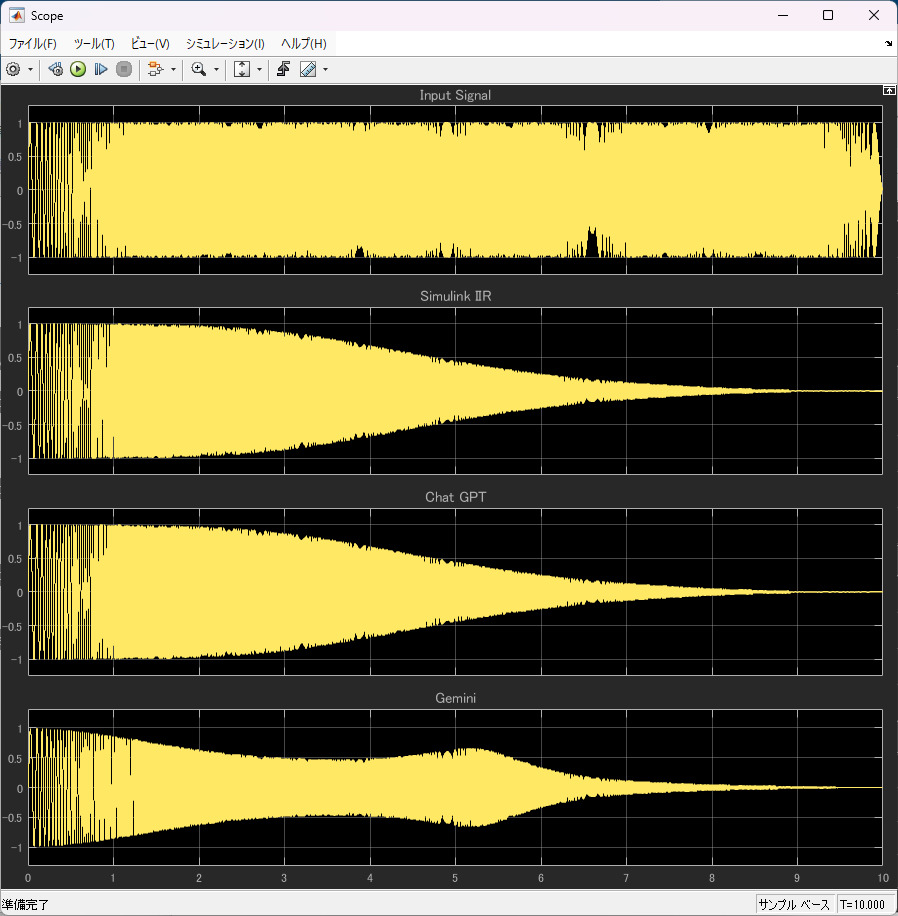
ChatGPTから生成したモデルは、誤差を計算してみましたが、完全にゼロになりました。
実用上の注意点と課題
生成AIでSimulinkモデルを作成できるか、試してみました。
結構イケることがわかって、今後生成AIやimporthdlの改善が進めば、もっと色んなケースに採用できそうな可能性を感じました。
今日現在、importhdlは浮動小数点(いわゆるRealデータ型)のVerilogコードのインポートには、残念ながら対応していないようです。対応すれば、Simulink上でデータ型を変更する必要がなくなって、もっと楽になるのですが。
モデル生成の1つの選択してとして今後使ってみようと思います。
こんなアルゴで試してみて欲しいといったご意見あればお気軽にコメントください。