Spectral Normalizationを理解する
自分の理解用にまとめたので記事として残しておきます.もともとスライド資料だったので見にくい点などあるかもしれませんがあしからず.
GANを知っている人向けです.
- GANの目的関数
- Wasserstein GAN
- 基本的な考え方
- スペクトルノルムとは
- Spectral Normalization
GANの目的関数
\begin{eqnarray}
\min_G \max_D L(D,G) &= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log D(x) \right] + \mathbb{E} _ {z \sim p _ z(z)} \left[ \log \left( 1 - D(G(z) \right) \right] \\
&= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log D(x) \right] + \mathbb{E} _ {x \sim p _ g(x)} \left[ \log \left( 1 - D(x) \right) \right]
\end{eqnarray}
- 直感的には,
- Dは本物データに対して1,生成データに対して0を出力
- GはDに本物と出力させるようなデータを生成
- シンプルなBinary Cross Entropyで表すことができる
- 最適な$D=D^\ast$は以下の通り.
$$ D^{\ast}(x) = \frac{ p _ r(x)} { p _ r(x)+p _ {g}(x)} $$
[導出]
GANの目的関数は期待値の部分を書き直せば,
$$ L(G,D) = \int \left( p _ {r} (x) \log(D(x)) + p _ {g}(x) \log(1 - D(x)) \right) dx $$
となる.ここで,$\hat{x}=D(x), A = p _ r(x), B = p _ {g}(x)$とおくと
$$ f(\hat{x}) = A\log \hat{x} + B \log (1- \hat{x}) $$
と$\hat{x}$の関数として書け,これを微分すれば,
$$ \frac{d f(\hat{x})}{d\hat{x}} = \frac{A-(A+B)\hat{x}} {\hat{x} (1- \hat{x})} $$
となる.$L(G,D)$を最大化したいので,右辺$=0$を解くと最適な$\hat{x}=D(x)$は
$$ D^{\ast}(x) = \frac{A}{A+B} = \frac{ p _ r(x)} { p _ r(x)+p _ {g}(x)} $$
KL divergenceとJS divergence
Kullback-Leibler divergence(KL divergence)
2つの確率分布に対して,それらの異なり具合を測るもの.
$$D_{KL}\left(P||Q\right) = \mathbb{E} _ {x \sim P} \left[ \log \frac{P(x)}{Q(x)} \right]$$
$$D_{KL}\left(P||Q\right) \not = D_{KL}\left(Q||P\right)$$
Jensen-Shannon divergence(JS divergence)
2つの確率分布の平均的な確率分布までのKLダイバージェンスの平均.
$M(x) = \frac{P(x) + Q(x)}{2}$として,
$$D_{JS}\left(P, Q\right) = \frac{1}{2}\left(D_{KL}(P||M) + D_{KL}(Q||M)\right)$$
$$D_{JS}\left(P||Q\right) = D_{JS}\left(Q||P\right)$$
D*下でのGANの目的関数
\begin{eqnarray}
L(D,G) &= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log D(x) \right] + \mathbb{E} _ {x \sim p _ g(x)} \left[ \log \left( 1 - D(x) \right) \right] \\
\end{eqnarray}
に$D=D^\ast$を代入すると
\begin{aligned}
L(D^\ast,G) &= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log \frac{ p _ r(x)} { p _ r(x)+p _ {g}(x)} \right] + \mathbb{E} _ {x \sim p _ g(x)} \left[ \log \left( 1 - \frac{ p _ r(x)} { p _ r(x)+p _ {g}(x)} \right) \right] \\
&= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log \frac{ p _ r(x)} { p _ r(x)+p _ {g}(x)} \right] + \mathbb{E} _ {x \sim p _ g(x)} \left[ \log \left( \frac{ p _ g(x)} { p _ r(x)+p _ {g}(x)} \right) \right] \\
&= \mathbb{E} _ {x \sim p _ r(x)} \left[ \log \left(\frac{1}{2}\frac{ p _ r(x)} { \frac{p _ r(x)+p _ {g}(x)}{2}} \right) \right] + \mathbb{E} _ {x \sim p _ g(x)} \left[ \log \left( \frac{1}{2}\frac{ p _ g(x)} { \frac{p _ r(x)+p _ {g}(x)}{2}} \right) \right] \\
&= \log \frac{1}{2} + D_{KL}\left(p_r||\frac{p_r + p_g}{2}\right) + \log \frac{1}{2} + D_{KL}\left(p_g||\frac{p_r + p_g}{2}\right) \\
&= -2\log{2} + 2D_{JS}\left(p_r, p_g\right)
\end{aligned}
$D$が最適であるとき,GANの目的関数は$p_r$と$p_g$の間のJSダイバージェンスを定量化する.
$$L(D^\ast,G) = -2\log{2} + 2D_{JS}\left(p_r, p_g\right)$$
$p_g = p_r$のとき,$G$が最適となるが,最適値周りで勾配消失してしまう.
→学習がうまくいかなくなる.
Wasserstein distance
- Earth Mover's distance(EMD)とも呼ばれる.
- ある確率密度関数を動かしてもう1つの確率密度関数に一致させるときの最小コスト
$$ W(p _ r, p _ g) = \inf _ {\gamma \sim \Pi(p _ r, p _ g)} \mathbb{E} _ {(x,y) \sim \gamma} ||x - y || $$
- 確率密度を土とすると,土の最適な輸送と考えられる.
- $\gamma(x, y)$は$p_r$のある地点$x$から$p_g$のある地点$y$に動かす土の量
- 動かす土の量に距離$||x - y ||$をかけることでコストとする
- [制約] $\sum_{x}\gamma(x, y) = p_g(y)$($y$に動かした土の総量)
- [制約] $\sum_{y}\gamma(x, y) = p_r(x)$($x$から動かした土の総量)
- $\Pi(p _ r, p _ g)$は上の制約を満たすような同時確率分布の集合
- $\inf$は下限であり,Wasserstein distanceを求めること自体が最適化問題となっている.
なぜWasserstein距離か.
以下のような確率密度$P, Q$を考える.
$P$の$x$成分は0に固定,$y$成分は$[0, 1]$の一様分布に従う.
$Q$の$x$成分はパラメータ$\theta$に固定,$y$成分は$[0, 1]$の一様分布に従う.
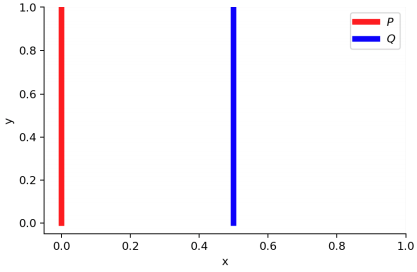
[4]より引用
$\theta \not = 0$のとき,
- $D_{KL}(P||Q) = \mathbb{E} _ {x = 0, y \sim U(0,1)} \left[ \log \frac{P(x, y)}{Q(x, y)} \right] = \inf$
- $D_{KL}(Q||P) = \mathbb{E} _ {x = \theta, y \sim U(0,1)} \left[ \log \frac{Q(x, y)}{P(x, y)} \right] = \inf$
- $D_{JS}(P, Q) = \frac{1}{2}\left(D_{KL}(P||\frac{P + Q}{2}) + D_{KL}(Q||\frac{P + Q}{2})\right) = \log 2$
- $W(P, Q) = |\theta|$
一方,$\theta=0$のとき,$P$と$Q$は完全に重なっていて,
- $D_{KL}(P||Q) = D_{KL}(Q||P) = D_{JS}(P, Q) = 0$
- $W(P, Q) = |\theta| = 0$
KLDは$P, Q$に重なりがない場合に発散,JSDは$\theta=0$で微分不可能.
EMDは$\theta$の変化に対してなめらかで,勾配降下法に適している.
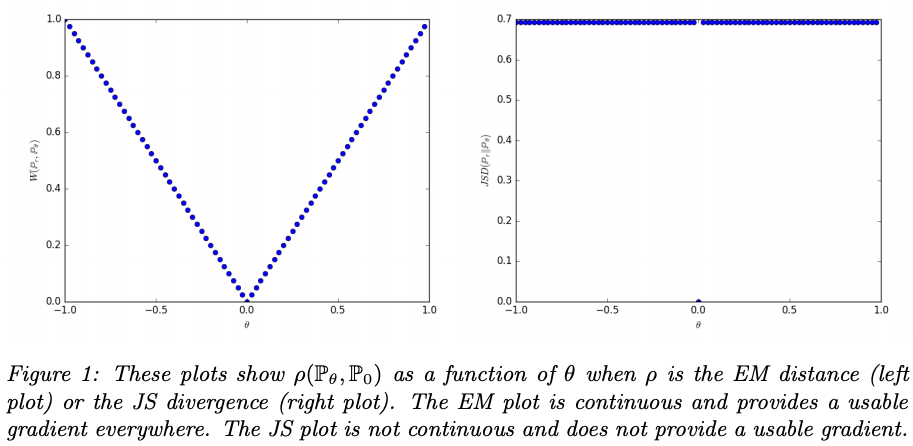
[2]より引用
Wasserstein Loss
-
Wesserstein距離を計算するのは大変
- 確率変数が取りうる事象の数は指数関数的に増大
-
Kantorovich-Rubinstein双対性を使って以下の通り変換可能
$$ W(p _ r, p _ g) = \sup _ {||f|| _ {L} \leq 1} \mathbb{E} _ {x \sim p _ {r}} [f(x)] - \mathbb{E} _ {x \sim p _ {g}} [f(x)] $$ -
[制約] $||f|| _ {L} \leq K$ ($f$はK-リプシッツ連続)
- 関数$f:\mathbb R \mapsto \mathbb R$がK-リプシッツ連続とは
ある定数$K \geq 0$が存在して,すべての$x_1, x_2 \in \mathbb R$に対して
$|f(x _ {1}) - f(x _ {2})| \leq K |x _ {1} - x _ {2}|$であること. - 直感的には,任意の区間で傾きが$K$で抑えられるということ.
- 関数$f:\mathbb R \mapsto \mathbb R$がK-リプシッツ連続とは
$f_{w}$がパラメータ$w$をもつK-リプシッツ関数とする.WGANでは$p_r$と$p_g$間のWasserstein距離を損失とし,Discriminatorは良い$w$を,Generatorは良い$\theta$を求める.
$$ L(p _ {r}, p _ {g}) = W(p _ {r}, p _ {g}) = \max _ {w \in W} \mathbb{E} _ {x \sim p _ {r}} [f _ {w}(x)] - \mathbb{E} _ {z \sim p _ {z}} [f _ {w}(g _ {\theta}(z))] $$
-
Discriminatorの出力はもはや識別結果としての意味を持たないため,出力を$[0, 1]$に押し込める必要はない.
-
ここで重要なのが$f_{w}$のK-リプシッツ性を維持する方法.WGANでは重み$w$を更新したあと,最小値と最大値をclipしている.($[-0.01, 0.01]$)
- ただし,このやり方も力技で,学習が不安定になるそうで,改良型のWGAN-gpではパラメータのclipの代わりに損失関数にペナルティ項を加えることで学習の最適化を達成している.
WGAN-gp
$W(p _ {r}, p _ {g})$における最適関数$f^\ast$が1-リプシッツ連続で,$x \sim p_g$, $y \sim p_r$とすると,$x$から$y$に引いた直線上のすべての点($x_t = (1 - t)x + ty, (0 \leq t \leq 1)$)における勾配が$y$に直接向く.すなわち
$$ p_{(x, y) \sim \pi }\left[\nabla f^\ast(x_t) = \frac{y-x_t}{||y-x_t||}\right] = 1$$
が成り立つ.
WGAN-gpではこの性質を利用して目的関数にGradient Penalty項を追加し,リプシッツ性を維持している.
$$ L = \mathbb E_{\hat x \sim p_g} \left[D( \hat x)\right] - \mathbb E_{x \sim p_r} \left[D(x)\right]
- \lambda \mathbb E_{\tilde x \sim p_{\tilde x}} \left[(||\nabla_{\tilde x}D(\tilde x)||_2 - 1)^2\right]\
\tilde x = \epsilon x + (1-\epsilon)\hat x$$
Spectral Normalization
大事なのはリプシッツ連続であって,他の方法で制約をおけばいいのでは?
元論文[1]に沿って説明
NNによって構成されるDiscriminatorを
$W^1, ..., W^{L+1}$を学習するパラメータ,$a_l$をelementwiseな非線形関数として,
$$
f(x) = W^{L+1}a_{L}(W^{L}a_{L-1}(W^{L-1}a_{L-2}(...a_{l}(W^{1}x)...)))
$$
と考える.SNではそれぞれの層$g: h_{\rm in}\mapsto h_{\rm out}$においてリプシッツ制約を考える.
$g$のリプシッツノルム($g$が取る傾きの上限)は以下の式で与えられる.
$$
||g||_{\rm Lip} = \sup_h \sigma(\nabla g(h))
$$
ここで,
$$
\sigma(A) := \max_{h:h\not = 0}\frac{||Ah||_2}{||h||_2} = \max_{||h||_2 \leq 1}||Ah||_2
$$
は行列$A$のスペクトルノルムである.
スペクトルノルムの意味
行列ノルムの定義
2つのベクトル空間,$\mathbb{K}^m, \mathbb{K}^n$におけるベクトルのノルムが与えられているとき,それらに対応して$m \times n$行列の空間$\mathbb{K}^{m \times n}$上の行列ノルムを与えることができる.例えば,ベクトルの$p$ノルムに対応して,
$$
||A||_p = \max_{x\in \mathbb{K}, x \not = 0}\frac{||Ax||_p}{||x||_p}
$$
が得られる.この行列ノルムは作用素ノルムと呼ばれる.
特に$p=2$かつ,$m=n$,つまり正方行列に対してユーグリッドノルムを考えた場合,これはスペクトルノルムになる.行列$A$のスペクトルノルムとは,$A$の最大の特異値である.
特異値
特異値分解とは
行列$A$を直交行列$U, V$と対角行列$\Sigma$の積に分解すること.
$$
A = U\Sigma V^{\rm T}
$$
$\Sigma$の対角成分を特異値と呼ぶ.
$U = (u_1 \ldots u_n),V = (v_1 \ldots v_n)$ とする.
\begin{aligned}
A &= U\Sigma V^{\rm T}\\
&= (u_1 \ldots u_n)
\left(\begin{array}{ccc}\sigma_1&\ldots&0\\\vdots&\ddots&\vdots\\0&\ldots&\sigma_n\end{array}\right)
\left(\begin{array}{c}v_1^{\rm T}\\\vdots\\v_n^{\rm T}\end{array}\right)
\end{aligned}
より,
$$
A^{\rm T}u_i = \sigma_i v_i\
Av_i = \sigma_i u_i
$$
となる.直感的には,$V$の列ベクトルがなす空間から$U$の列ベクトルがなす空間への写像としてAを考えたとき,$v_i$が対応する$u_i$に写り,その長さを$\sigma_i$倍する,ということになる.
つまり...
行列$A$のスペクトルノルム $=$ $A$の最大特異値 $=$ $A$が作用したときのノルムの比の最大値
層$g(h) = Wh$に対して,
$$
||g||_{\rm Lip} = \sup_h\sigma (\nabla g(h)) = \sup _h \sigma(W) = \sigma(W)
$$
また,
$||g_1 \circ g_2||_{\rm Lip} \leq ||g_1||_{\rm Lip} \cdot ||g_2||_{\rm Lip}$,$||a_l||_{\rm Lip}=1$ より,
\begin{aligned}
||f||_{\rm Lip} \leq ||h_L \mapsto W^{L+1}h\_L||_{\rm Lip}\cdot||a_L||_{\rm Lip}\cdot||h_{L-1} \mapsto W^{L}h_{L-1}||_{\rm Lip}
\dots ||a_1||_{\rm Lip}\cdot||h_0 \mapsto W^{1}h_0||_{\rm Lip} = \prod^{L+1}_{l=1}||h_{l-1} \mapsto W^{l}h_{l-1}||_{\rm Lip} = \prod^{L+1}_{l=1}\sigma(W^l)
\end{aligned}
$D$の各層での重み$W$を以下のようにNormalizeする.
$$
\bar{W}_{\rm SN}(W) := W/\sigma(W)
$$
これにより$D$のリプシッツノルムは1で抑えられる.
参考文献
この記事の内容を作成するにあたって,以下の文献を参考にさせていただきました.
[1]Spectral Normalization
[2]Wasserstein GAN
[3]GANの安定化の有効手法「Spectral Normalization」を実装する
[4]GANからWasserstein GANへ