#まず初めに
株について特に知らないままにとりあえず株価の予想してみたいなと思い行き当りばったりで初めています。今回は株価の予想まで行くことはありません。
「とりあえず、株価をpythonでデータとして取得するところから始めよう」という入門も入門のところから始めようとしております。
###環境
・python3 3.7.3
・pip3 21.1.3
・rasberrypi4
###使用モジュール
・今回はpandas_datareader
・matplotlib
#インストール
モジュールをインストールしなければ何も出来ないということで、とりまpandas-datareaderをインストールします。
pip3 install pandas-datareader
自分で一からhttpのリクエストを送り〜という流れのプログラムを標準ライブラリからプログラムを作るのも楽しいのですが、しかし私は時間を作ることが最近難しいので、こんな簡単なものであれば既存のモジュールを使うのがやっぱり良いですね。
#プログラム
これを利用してpythonのプログラムを書きます。
import pandas_datareader.data as web
#7267は本田の証券コードです。
df = web.DataReader('7267.JP', 'stooq')
「証券コード(銘柄コード)とかの知識が全く無いよ!」という私のお仲間さんがいらっしゃるのでしたら、こちらのサイトを見ることをオススメします!分かりやすかったので。
それからこのプログラムはstooqから株価のデータを取得してきているということなのでしょう。stooqは数少ないのか…は知らないけど、無料で株価を知ることの出来るサイトだそうです。
無料でプログラムを作るのが以上のように簡単で、しかも速いのだとか。気になる人のためにstooqのURLを貼っておきますね。
こうして株価のデータを取ってこれるよ、というだけではあまりにも面白くないので、とりあえず可視化しておきましょうか。
import matplotlib.pyplot as plt
plt.plot(df['High'])
plt.show()

やはりmatplotlibは便利なんですね〜
一応ほんの少しだけ補足です。
pandasとmatplotlibをあまり知らないという人のために、どうしてplt.plot(df.High)だけで時間と株価のデータが出てくるのかということを実践をもって表します。
といってもほんとに事実を突きつけるだけなのですが。
print(df['High'])
Date
2021-06-23 3490.00
2021-06-22 3522.00
2021-06-21 3456.00
2021-06-18 3564.00
2021-06-17 3631.00
2021-06-16 3663.00
2021-06-15 3626.00
2021-06-14 3660.00
2021-06-11 3587.00
2021-06-10 3595.00
2021-06-09 3603.00
2021-06-08 3619.00
2021-06-07 3633.00
2021-06-04 3644.00
2021-06-03 3628.00
2021-06-02 3524.00
2021-06-01 3378.00
2021-05-31 3422.00
2021-05-28 3478.00
2021-05-27 3347.00
2021-05-26 3374.00
...
2016-08-22 2755.36
2016-08-19 2718.61
2016-08-18 2658.26
2016-08-17 2662.62
2016-08-16 2605.31
2016-08-15 2606.61
2016-08-12 2605.75
2016-08-10 2611.02
2016-08-09 2628.49
2016-08-08 2631.99
2016-08-05 2575.12
2016-08-04 2573.37
2016-08-03 2569.87
2016-08-02 2466.20
2016-08-01 2499.88
2016-07-29 2514.74
2016-07-28 2507.30
2016-07-27 2542.73
2016-07-26 2473.63
2016-07-25 2528.32
2016-07-22 2518.69
Name: High, Length: 1218, dtype: float64
というデータになっています。つまり、df['High']とアクセスすることで、二つのデータに同時にアクセスしているのです。
#終わりに
セミの鳴き声が聞こえ始め、夏がもう来てしまったとクーラーの元で感慨に耽る中、いかがお過ごしでしょうか。なんて風にお洒落(?)な終わりをしてみますが、そんな無駄話をしているわけではないでしょう。
今回は株の予測をしてみるために、まずはデータを取得してきてみましたが、これからはそのデータを利用して予測などをしてみましょう。つまりはただ遊びたいだけです。
次回は(多分)機械学習で予測線を作ってみようとします。
#追記
次の日に思いつきで、高値と安値を両方同時に表示してみようと思い、プログラムを動かしてれば、小石に躓く程度躓いちゃったので、一応残しておきます。
#前回のdfをそのままに
plt.plot(df['High'],df['Low'])
このままではおかしな表示になってしまいます。

まぁ何がなんだかわかりませんよね。
これは根本的にアクセスの仕方が間違えているのではと予測しました。
書き直したのが以下のとおりです。
plt.plot(df[['High','Low']])
plt.show()

色分けもされていてわかりやすいですね。赤が安値で緑が高値でしょう。しかしここまで遠くからだと些細な違いが分かりづらいですね。ということでmatplotlibを弄り、範囲を縮めれないか確かめてみます。
plt.rcParams["figure.figsize"]=(,)というメソッドが用意されているみたいなのでそれを利用してみましょう。

さて、何か変わったでしょうか…?と、とりあえず、説明を読んできます。やべぇ、説明書読まずに色々するタイプなのがバレるぜ。
これは表示される時のサイズを変更するというメソッドだったようです。そりゃ保存してみても違いがわからないわけですね。
というか、近づけて見たいというのなら、そもそも余分なデータを削ぐという方法もありますね。それを試してみましょう。
plt.plot(df[['High','Low']].head())
plt.show()
head()は何も指定していなければpandas.DataFrameのデータ先頭5個を取得してくるようになっているそうです。そうして表示してみたのが、以下のものです。
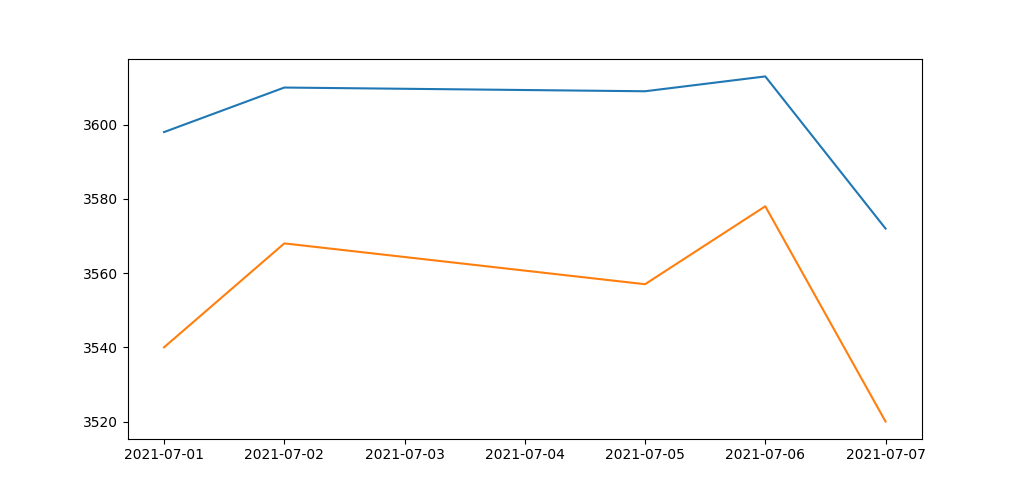
これは…日付ごとの違いが分かりやすくなりましたね。
2021年7月7日は7月6日よりも落ちているというのがわかります。視覚的に見えるようにする、可視化の第一歩の蛇足編はこれにて終了です。
あざしたー