はじめに
掲題の件、探してみると色々な記事が出てきて、
IN句よりEXISTS句が速いといわれている理由
IN句とEXISTS句とJOINどれが速いのか
IN句の処理順序
EXISTS句の処理順序
それぞれに関する記事は出てくるんですが、それらをまるっと総じて説明しているものが少なかったので、自分の頭の整理も含めて、ここで纏めておこうと思います。
記載内容で誤りなどあれば、コメントで教えていただけるとありがたいです。
筆者について
IT歴4年目のエンジニアです。
今回使うDBとデータ
DB
PostgreSQLです。バージョンは15.2です。
C:\Users\sskno>psql --version
psql (PostgreSQL) 15.2
データ
テストデータを1から作るのは面倒なのでPostgreSqlで用意してくれてるサンプルデータを使います。
PostgreSQLチュートリアルからダウンロードしてPostgreSQLのpg_restoreコマンドでリストアできます。
上記のダウンロードページにER図がありますが、今回はrentalテーブルとcustomerテーブルを使って確認を進めていきます。

レコード数はそれぞれ下記のような感じ
dvdrental=# select count(*) from customer;
count
-------
599
(1 行)
dvdrental=# select count(*) from rental;
count
-------
16044
(1 行)
使用するSQL
今回はMary Smithさんのレンタル履歴を取得するようなケースを想定してSQLを作ってみます。
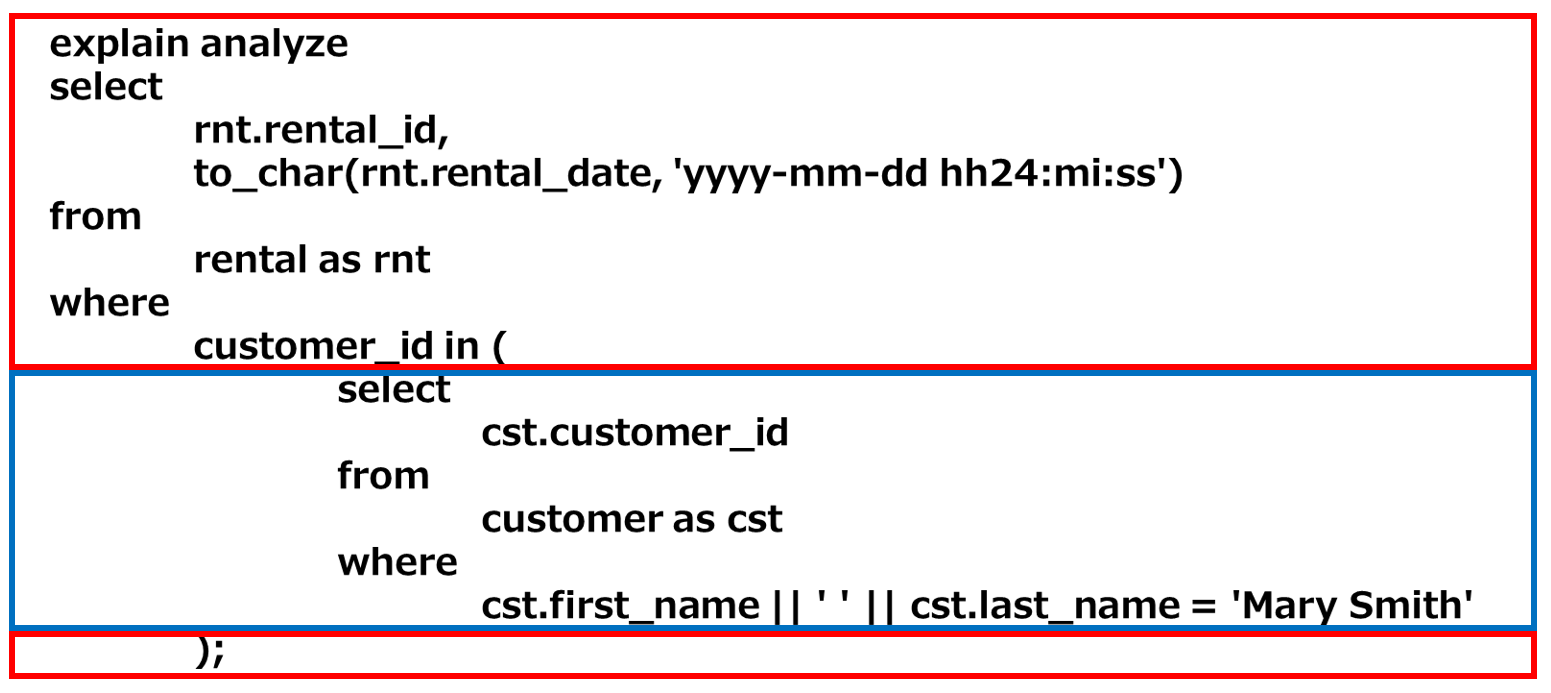
INを使用したSQL
explain analyze
select
rnt.rental_id,
to_char(rnt.rental_date, 'yyyy-mm-dd hh24:mi:ss')
from
rental as rnt
where
customer_id in (
select
cst.customer_id
from
customer as cst
where
cst.first_name || ' ' || cst.last_name = 'Mary Smith'
);
EXISTSを使用したSQL
select
rnt.rental_id,
to_char(rnt.rental_date, 'yyyy-mm-dd hh24:mi:ss')
from
rental as rnt
where
exists (
select
*
from
customer as cst
where
cst.customer_id = rnt.customer_id
and cst.first_name || ' ' || cst.last_name = 'Mary Smith'
);
「いやいや、サブクエリはSELECT 1じゃなきゃ」と思われるかもしれませんが、「SELECT *」の方が速いもしくは同等なのでSELECT *を使ってます。(Oracleの古いバージョンとかだとSELECT 1の方が速かったらしいですけど、僕も最近知りました)
JOINを使ったSQL
select
rnt.rental_id,
to_char(rnt.rental_date, 'yyyy-mm-dd hh24:mi:ss')
from
rental as rnt
INNER JOIN customer as cst on cst.customer_id = rnt.customer_id
where
cst.first_name || ' ' || cst.last_name = 'Mary Smith';
INとEXISTSの処理順序と一般的にINよりEXISTSを使った方が速いといわれる所以
いままでの案件で
「INよりEXISTSの方が速いから、SQL書き換えて」
と言われてきました。
1年目の時とかは何も考えず「そうなんだ」ってことで、言われるがまま書き換えてましたが、だんだん「プランナもアホじゃないから、そんなSQLの書き方ごときで速度変わらないのでは?」とか「個人的に可読性が良くないからEXISTSあんまり使いたくないんだよな」という思いが強まっていきました。
INの処理順序
原則的?な解釈でいくとINを使ったクエリの処理順序は
- 青枠のサブクエリ部分を実行し取得した結果をメモリ等に保持
- 赤枠のメイン部分を実行して1で取得した内容と突合
となります。
INが遅いといわれる理由はいくつかあるそうですが
- メインクエリのテーブルをフルスキャンしてしまうため
- サブクエリの結果からは統計情報やインデックスなどメタな情報が落ちるため(当然の挙動ですが)
- メインのクエリ部分でインデックスが使えないため
あたりが理由らしい
EXISTSの処理順序
原則的な解釈でいくとEXISTSを使ったクエリの処理順序は
- 青枠の青枠のメインクエリ部分を実行
- 青枠で取得した各行に対して赤枠の相関サブクエリを実行
となります。

EXISTSがINより速いといわれる理由は
- 相関サブクエリ側のカラムにインデックスがあれば一意にレコードを特定できるため
- 条件に合致するレコードが取得できた時点で走査を打ち切るため
あたりが理由らしい
なんで「らしいらしい」言ってるか
自分の目で原則的に言われているような実行計画を見たことがなく、ずっと「INが遅いといわれる理由は~らしい」とか「EXITSTがが速い理由は~らしい」とか言ってます。
僕がIT業界に入ったときにはプランナがお利口になってて、上記のような実行計画を組んでいるのを見たことがないんですよね。実際、検索してたらOracleだと9とかだいぶ前のバージョンじゃないとそんな実行計画は見れないそう。
実行計画と処理時間を見てみる
実行計画がすべてということで、実際に実行計画を見てみます。
dvdrentalのデータを投入し、統計情報を収集ます。
そのあと、IN、EXISTS、JOINそれぞれのパターンでキャッシュをクリアしたバージョンとキャッシュ乗ったバージョンでexplain analyzeを実行します。
INの場合
キャッシュなし
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=1.136..5.220 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.045..2.754 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.300..0.303 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.034..0.290 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 13.996 ms
Execution Time: 5.295 ms
(10 行)
キャッシュあり
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=0.254..3.000 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.014..1.098 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.202..0.203 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.017..0.197 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 0.529 ms
Execution Time: 3.040 ms
(10 行)
EXISTSの場合
キャッシュなし
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=0.510..4.490 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.037..2.642 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.244..0.246 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.031..0.235 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 12.067 ms
Execution Time: 4.548 ms
キャッシュあり
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=0.202..2.724 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.011..1.081 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.162..0.163 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.012..0.158 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 0.428 ms
Execution Time: 2.756 ms
JOINの場合
キャッシュなし
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=1.048..5.189 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.039..2.751 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.244..0.248 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.030..0.240 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 13.009 ms
Execution Time: 5.250 ms
(10 行)
キャッシュあり
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Hash Join (cost=19.52..372.58 rows=80 width=36) (actual time=0.195..3.483 rows=32 loops=1)
Hash Cond: (rnt.customer_id = cst.customer_id)
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.011..1.366 rows=16044 loops=1)
-> Hash (cost=19.48..19.48 rows=3 width=4) (actual time=0.158..0.158 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.011..0.154 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 0.395 ms
Execution Time: 3.517 ms
実際の実行計画を見てみて
すべて実行計画同じですね。
全てのパターンのSQLが
- サブクエリを実行して結果をメモリに保持
- メインのクエリとHash Join
という実行計画に変わりました。
SQLだけを見てこのクエリは遅いとか速いとか語らず、結局は実行計画がすべてなので実行計画を見るようにしましょう。
とはいえ、統計情報で実行計画は変わってきますので、いくらリライトしてくれるとはいえ、あまりリスクをはらんだめちゃくちゃなSQLを書くのはさすがにやめた方がいいと思いますが。
ちなみにソースがぱっと見つけられなかったはずですが、Oracleに関してはINを使おうが、EXISTSを使おうが速度に差はないとOracleが明言していたと思います。
言いたかったこと
where句で左辺には演算子を使わないとかlikeは先頭一致させるとかその程度であればSQLだけ見て判断でもいいですが、基本的には実行計画がすべてなので実行計画を見るようにしましょう。
原則的な考え方に乗っ取ってSQLの速度を判断するのであれば、こちらの記事に記載の考え方に賛成で、サブクエリ側でレコードを大きく絞り込めるのであればIN、メインのクエリ側で絞り込みが効くならEXISTSという使い方が良さそうです。
注意点
当記事には注意点があります。
まずDBはPostgreSQLであるということ。
特にMySQLの場合にはINとEXISTSの処理速度には明確に差が出てきます。
次に今回検証したのはSELECT文かつNOTではないということ。
SELECT文以外もしくはNOT IN、NOT EXISTSの時の挙動は異なる可能性があります。
3つめに今回検証したSQLはかなり単純なSQLです。複雑なSQLの場合はまた実行計画に違いが出るかもしれません。
おまけ(頑張って問題の実行計画をださせようとしてみた)
今回、INとEXISTSは同じ実行計画を組みましたが、どうしたらそれぞれが別の実行計画を組んで、INは問題になるような遅い実行計画、EXISTSはSubPlanを何度も実行するような想定している実行計画が組まれるのか探ってみました。
途中経過は省略しますが、下記の通りノードを制限しまくりましたが、INとEXISTSは同じ実行計画を組み続けました。
(PostgreSQLは下記のコマンドを実行することでノードを制限できます。)
-- hash join 封じ
dvdrental=# set enable_hashjoin to off;
-- nested loop 封じ
dvdrental=# set enable_nestloop to off;
-- merge join 封じ
dvdrental=# set enable_mergejoin to off;
-- index scan封じ
dvdrental=# set enable_indexscan to off;
-- bitmap scan封じ
dvdrental=# set enable_bitmapscan to off;
で、出てきた実行計画なんですが、、
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000001051.50 rows=80 width=36) (actual time=0.273..6.109 rows=32 loops=1)
Join Filter: (rnt.customer_id = cst.customer_id)
Rows Removed by Join Filter: 16012
-> Seq Scan on rental rnt (cost=0.00..310.44 rows=16044 width=14) (actual time=0.021..1.172 rows=16044 loops=1)
-> Materialize (cost=0.00..19.50 rows=3 width=4) (actual time=0.000..0.000 rows=1 loops=16044)
-> Seq Scan on customer cst (cost=0.00..19.48 rows=3 width=4) (actual time=0.016..0.201 rows=1 loops=1)
Filter: ((((first_name)::text || ' '::text) || (last_name)::text) = 'Mary Smith'::text)
Rows Removed by Filter: 598
Planning Time: 0.326 ms
Execution Time: 6.157 ms
(10 行)
コストのでかさがとんでもないですね。
しかもノードを制限しているにも関わらず、Nested Loopが使われているということはPostgreSQL側で「Nested Loopを使わないと実行計画が組めない」と判断したということですね。
どう頑張ってもINやEXISTSに対して結合の実行計画を立てるということですね。