経緯
「弊社のエンジニアであればSQLの軽いチューニングはできて当然」というレジェンドエンジニアのKさんの言葉を受け下記の本を読みましたのでそのアウトプット&共有ができればと。
筆者について
最近、仕事用の服につなぎを購入しためんどくさがりエンジニア。
当社は私服勤務OKなんですが、服を選ぶのが面倒なのでつなぎを買いました。
ただアメリカから輸入したものなので、足が長すぎて今は裾上げ中です。
SQLをカリカリにチューニングみたいな経験はないので、誤りがあれば教えてください。
当記事の内容
SQL実践入門──高速でわかりやすいクエリの書き方 の第6章に即した内容になります。
テーマは 結合 です
可読性の高いSQLという記事タイトルの割に今回はあまりSQLを改善するような内容ではないです。。。
結合アルゴリズム
だいたいのDBMSは以下の3つを基本的にサポートしてます。
1. Nested Loops
2. Hash
3. Sort Merge
Nested Loops
処理順序
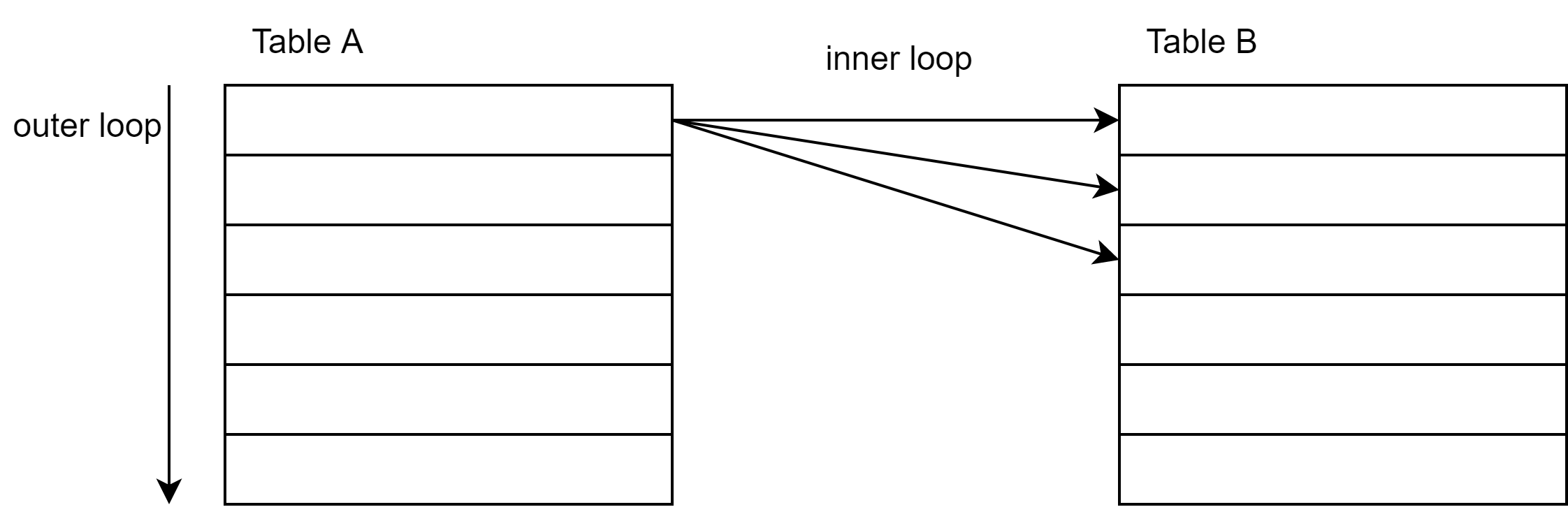
1. 駆動表(Table A)を1行ずつループ。
2. 駆動表の1行に対して内部表を1行ずつループして、結合条件に合致すれば結果を返却。
3. 1,2を駆動表の全行に対して繰り返す。
特徴
- 処理時間は行数に比例する。(駆動表の行数×内部表の行数)
- 1つのステップで処理する行数が少なく、メモリの消費量が他の結合アルゴリズムに比べると少ない。
- (どのDBMSでサポートしてる。)
Nested Loopsでパフォーマンス改善するためには
SQLのパフォーマンスを改善する際のキーワードとして 駆動表を小さくする というのがありますが、これはNested Loopsの性能において非常に大きな意味を持つキーワードになります。
駆動表の処理順序から考えると結局、駆動表と内部表の行数の掛け算なので、駆動表の方が小さくてもパフォーマンスに影響はなさそうですが、実際は、、、
駆動表を小さくする に加えて 内部表の結合キー列にインデックスが付与されている という暗黙の前提があれば、Nested Loopsの性能は大きく改善されます。
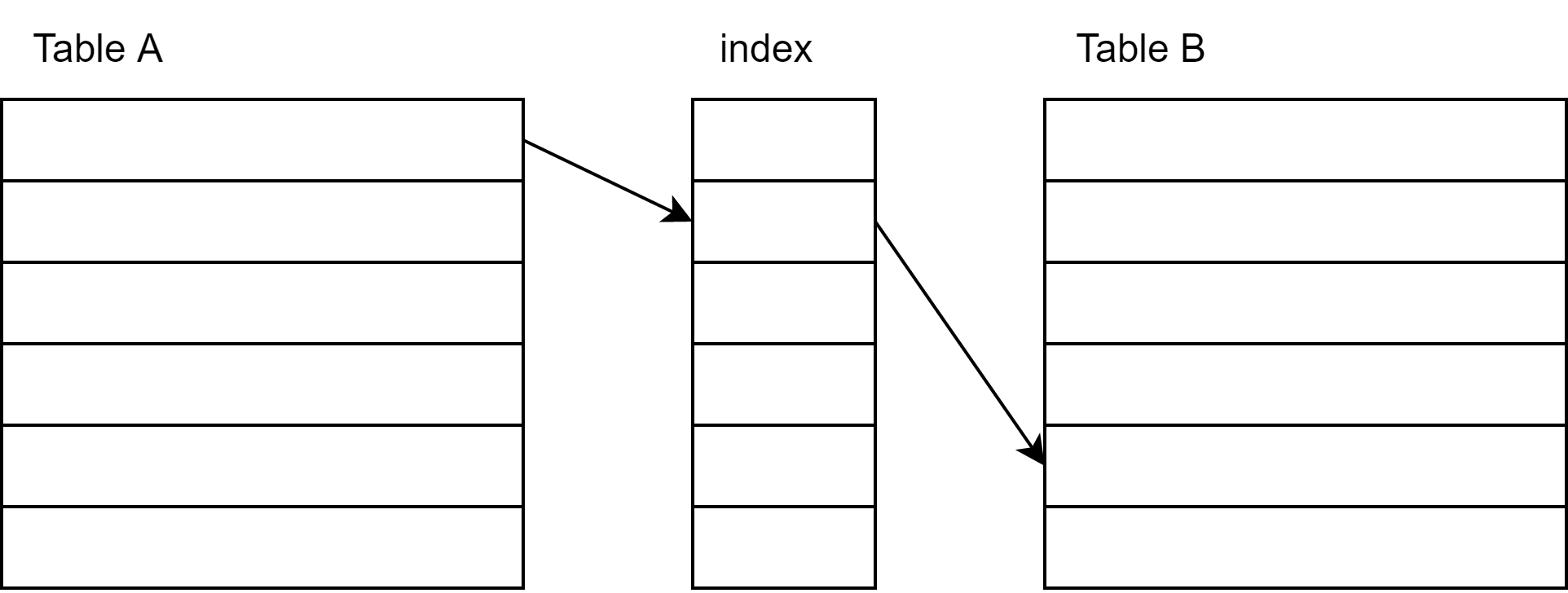
理由は単純にindexを挟むことで内部表を全行スキャンしなくても内部表を絞り込めるためです。
駆動表を小さくする × 内部表の結合キー列にインデックスが付与されている
くり返しになりますがコチラがNested Loopsのチューニングの基本になります。
ただ、インデックスを挟んでもインデックスに対して内部表で大量のレコードがヒットしてしまうとインデックスを挟んでも想定のパフォーマンスはでなくなってしまいますので注意が必要です。
Hash
処理順序

1. オプティマイザが小さいと見積もったテーブルをスキャン
2. 結合キーに対してハッシュ関数をかけてハッシュテーブルを生成
3. もう一方の大きいテーブルをスキャンしてハッシュ値を生成して一致するかチェックして結合
特徴
- ハッシュテーブル生成のためにメモリを消費する。(Temp落ちしたら速度がガクっと落ちる)
- 等値結合でのみ使用されるアルゴリズム。
- 結合対象の両テーブルをフルスキャンする必要がある。
Sort Merge
処理順序
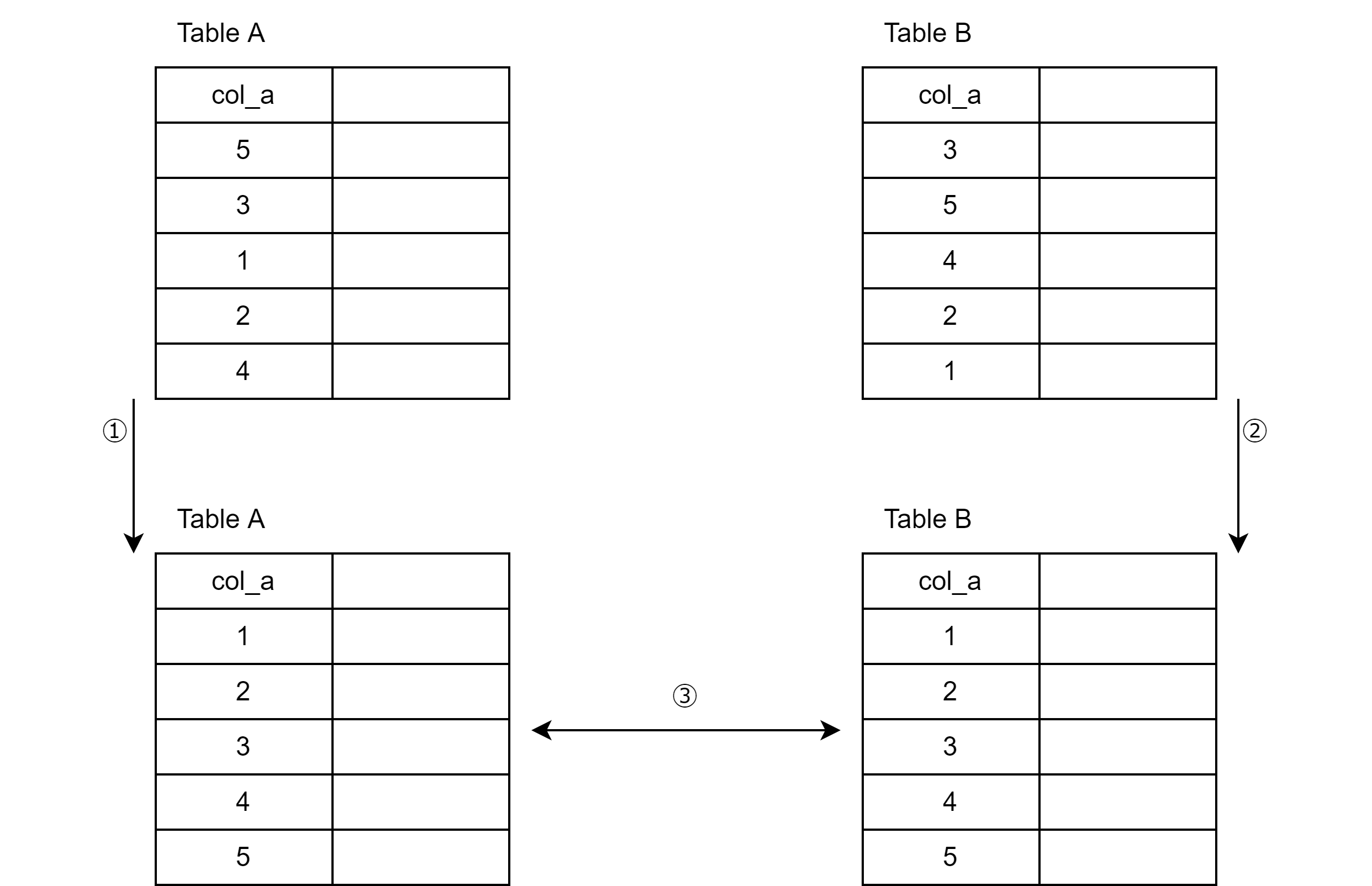
1.結合テーブルをソート
2.もう1つの結合テーブルもソート
3.ソートしたテーブル同士を結合
特徴
- Hash同様、メモリを多く消費する。基本的には両テーブルをハッシュ化するためHashよりも多くメモリを消費する。
- Hashと異なり同値以外の結合でも利用可能。(意外とテーブルの結合って同値以外に>、<、>=、<=とかでできるって知らない人いますよね。)
当章を読んで
SQLをチューニングする際に言われるキーワードはたくさんあります。
- 結合では駆動表を小さく
- 結合条件の左辺では演算は行わない
- like検索では前方一致になるように
などなど、、、
今回は駆動表は小さく の理由を説明しておりましたが、闇雲に従っただけではなく意図をりかいすることは大切だなと思いました。