EXPLAINコマンドは、
・クエリの実行計画を表示するための重要なツール
・クエリのパフォーマンスを最適化する
、、、ってのは分かっているのですが
正直、使い方がいまいち理解できてませんでした。
今回、勉強しなおしたので記載します。
同じような方の手助けになれば幸いです!
EXPLAINコマンドの概要と重要性
EXPLAINコマンドは、SQLステートメントの実行計画を表示するためのコマンド。
EXPLAINコマンドの重要性
1. クエリの最適化
クエリの実行計画を分析し、どの操作でデータ移動が必要になるかを把握することができます。
これにより、不要なデータ移動を避けるための最適なクエリプランを作成することができます。
2. パフォーマンスの改善
クエリの実行にかかる推定合計時間や操作の総数を把握することができます。
これにより、ボトルネックとなる部分や負荷の高い操作を特定し、
パフォーマンスの改善策を見つけることができます。
3. インデックスの設計
クエリの実行計画からどのインデックスが使用されているかを確認することができます。
インデックスが適切に使用されていない場合、クエリのパフォーマンスに悪影響を与える可能性があります。
EXPLAINコマンドを活用して、効果的なインデックスの設計を行うことが重要です。
4. クエリの理解とトラブルシューティング
クエリの実行計画を視覚化する手段としても利用できます。
クエリの実行計画を理解することで、クエリの動作やデータのフローを把握することができます。
また、クエリのパフォーマンスが低下している場合や予期しない結果が得られる場合には、
EXPLAINコマンドを使用してトラブルシューティングを行うことができます。
EXPLAINコマンドの基本的な使い方
EXPLAINコマンドの基本構文とオプションについて
以下は、PostgreSQLのEXPLAINコマンドの基本構文とオプションです。
EXPLAIN [ANALYZE] [VERBOSE] [COSTS] [BUFFERS] [FORMAT format_type]
query
-
ANALYZE: クエリの実行も行い、実行結果の統計情報も表示します。 -
VERBOSE: より詳細な情報を表示します。 -
COSTS: 各実行計画ノードの見積もりコストを表示します。 -
BUFFERS: 各実行計画ノードでのディスクアクセスとメモリバッファの使用に関する情報を表示します。 -
FORMAT format_type: 出力形式を指定します。デフォルトでは、テキスト形式で表示されます。
例えば、以下のように使用します。
EXPLAIN SELECT * FROM table_name WHERE column_name = 'value';
このコマンドを実行すると、クエリの実行計画が表示されます。
実行計画には、テーブルスキャン、インデックススキャン、ソート、ハッシュ結合などの操作の順序や方法が含まれます。
これにより、クエリの最適化やパフォーマンスの改善のための情報を得ることができます。
よく使うオプションである、ANALYZEオプションやVERBOSEオプションについて
ANALYZEオプション
ANALYZEオプションは、EXPLAINコマンドでクエリの実行も行い、実行結果の統計情報を表示する役割を持ちます。
クエリの実行には一定のコストがかかるため、通常はEXPLAINコマンドでは実行を行わず、単に実行計画の情報のみを表示します。
しかし、ANALYZEオプションを指定すると、クエリの実行が行われ、実行結果に基づいた統計情報も表示されます。
これにより、実行計画の推定コストや実行統計に関する詳細な情報を得ることができます。
VERBOSEオプション
VERBOSEオプションは、EXPLAINコマンドの出力に追加の詳細情報を含める役割を持ちます。
通常、EXPLAINコマンドの出力は簡潔でわかりやすくなっていますが、詳細な情報が欲しい場合にはVERBOSEオプションを指定します。
VERBOSEオプションを使用すると、
各実行計画ノードに関する追加の情報、
例えば実行に使用されたインデックスやフィルタ条件などが表示されます。
これにより、実行計画の理解やクエリの最適化に役立つ情報を得ることができます。
警告
これらのオプションを使用することで、より詳細な情報や統計情報を得ることができますが、
クエリの実行には時間やリソースがかかることに注意してください!
特に、本番環境で使う場合は注意してください!!
重いクエリで実行するのは、、、、やめておきましょう...
EXPALINの出力内容の解説
EXPALINコマンドの出力結果の見方
PostgreSQLの例を使ってEXPLAINコマンドの出力結果の読み方を解説します。
例として、以下のようなテーブルがあるとします。
テーブル名: vegetables
+---------+----------+--------+
| 野菜名 | 価格 | 在庫数 |
+---------+----------+--------+
| トマト | 100円 | 20 |
| レタス | 150円 | 15 |
| キャベツ | 120円 | 10 |
+---------+----------+--------+
そして、以下のようなクエリをEXPLAINコマンドで実行したとします。
EXPLAIN SELECT 野菜名 FROM vegetables WHERE 価格 < 130;
これに対する出力結果は、以下のようになります。
QUERY PLAN
-----------------------------------------------------------
Seq Scan on vegetables (cost=0.00..9.75 rows=2 width=8)
Filter: (価格 < 130)
(2 rows)
EXPLAINの見方です。
-
QUERY PLAN: クエリの実行ステップに関する情報が表示されます。
-
Seq Scan on vegetables: シーケンシャルスキャンが実行されていることを示します。
シーケンシャルスキャンは、テーブル全体を順番にスキャンする方法です。 -
cost=0.00..9.75: クエリのコストを示します。
このクエリのコストは0.00から9.75の範囲であることを示しています。
コストはクエリの実行にかかる推定時間やリソースを表します。
小さいほど効率の良いクエリと言えます。 -
rows=2: クエリが処理する行数を示します。
今回は「2」となっています。
これは、価格が130未満の野菜が2つあることを意味します。 -
width=8:
クエリの結果の各行が占めるバイト数を示します。
今回は「8」バイトとなっています。 -
Filter: (価格 < 130):
フィルタ条件が表示されます。
今回の場合、価格が130未満の行を選択していることがわかります。
この出力結果からわかることは、今回のクエリは「vegetables」テーブルをシーケンシャルスキャンして、価格が130未満の野菜名を選択していることです。シーケンシャルスキャンはテーブル全体をスキャンするため、テーブルの行数が多い場合はクエリの実行が遅くなる可能性があります。
以上が、PostgreSQLの例を使ってEXPLAINコマンドの出力結果の読み方を解説したものです。クエリ最適化やパフォーマンス改善のために、EXPLAINコマンドを活用してクエリの実行計画を理解しましょう。
プランノードの種類と実行コストの見方
プランノードは、クエリを実行するためのステップや手順のことです。
例えば、テーブルを読み込んだり、条件に合致する行を絞り込んだりするステップがあります。
プランノードの種類
-
Sequential Scan (シーケンシャルスキャン):
テーブルを最初から最後まで順番に読み込む手法です。
全ての行を順番にチェックするので、テーブルが大きいと時間がかかります。 -
Index Scan (インデックススキャン):
インデックスを使ってテーブルの特定の部分だけを読み込む手法です。
条件に合致するデータを素早く見つけることができます。 -
Filter (フィルタ):
条件に合致する行だけを残すかどうかを判断する手法です。
条件に合致しない行を除外します。 -
Sort (ソート):
結果を並び替える手法です。
例えば、価格が安い順にソートする場合などに使われます。
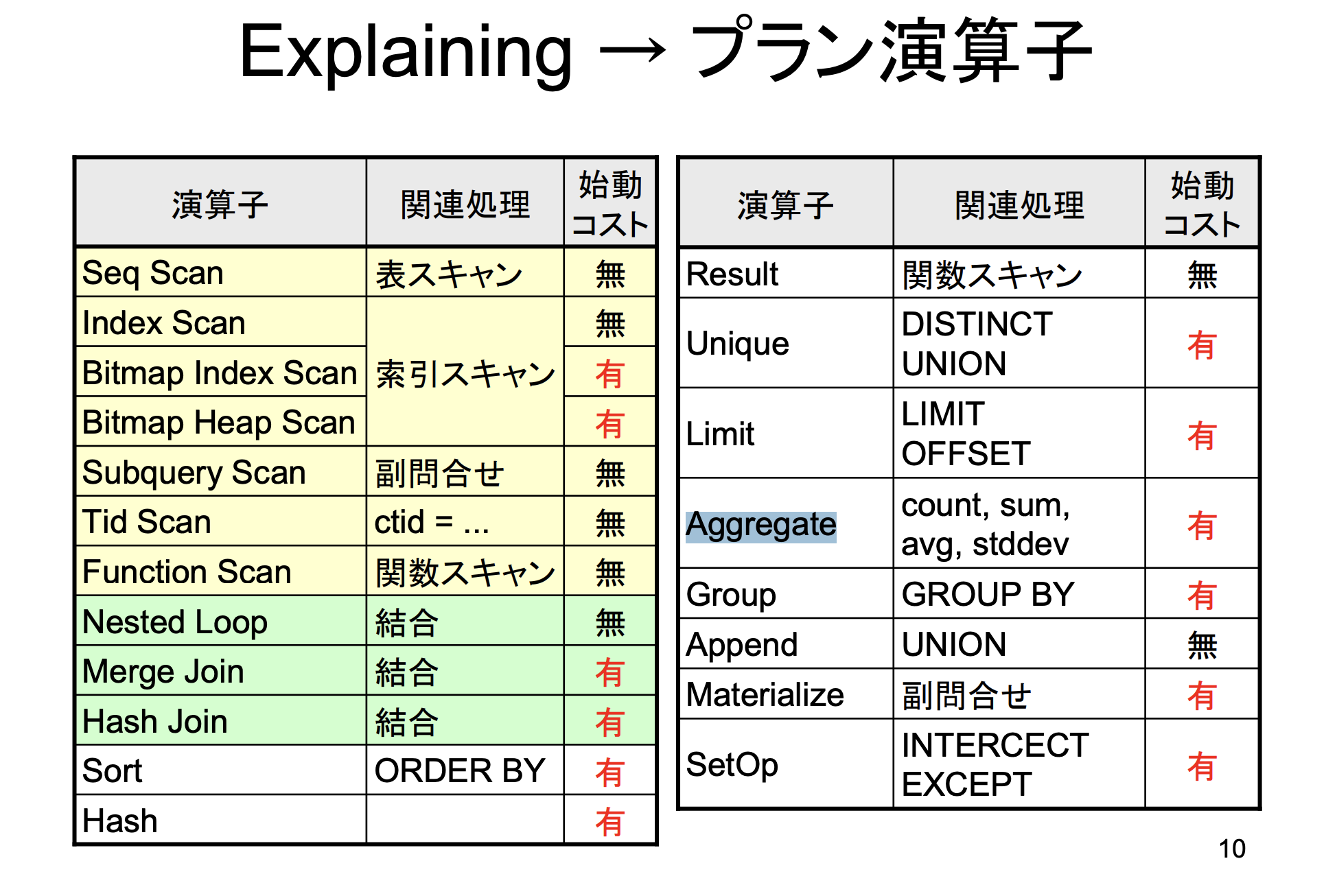
画像の参照元
https://lets.postgresql.jp/sites/default/files/2016-11/Explaining_Explain_ja.pdf
実行コストの見方
実行コストは、クエリを実行するためにかかる予測される時間やリソースを表す数値です。
小さいほどクエリの実行が速く、効率的です。
具体的には、以下の項目に注目します。
-
コストの値: コストの値が小さいほど、そのプランノードの実行が早く終わることを意味します。
たとえば、コストが「10」のプランノードは、「100」のプランノードよりも早く実行されると予測されます。 -
行数の値: そのプランノードで処理する行数を表します。
行数が多いほど、そのプランノードの処理に時間がかかる可能性があります。 -
幅の値: 結果の行1行が占めるバイト数を表します。
結果のサイズが大きいほど、ネットワーク転送などに時間がかかる可能性があります。
クエリの最適化やパフォーマンス向上を考える際には、プランノードの種類と実行コストを理解して、効率的なクエリを作成することが大切です。
クエリのパフォーマンスチューニングの基本の考え方
1. インデックスの活用
インデックスは、データを素早く見つけるための目次のようなものです。
例えば、辞書のように言葉の順番で単語を探すときに便利なページ番号が目次にあたります。
例えば: もし、学校で生徒の名前で検索する場合、生徒の名前をアルファベット順に並べたインデックスを使うと、名前を瞬時に見つけることができます。
2. テーブルスキャンの回避
テーブルスキャンとは、テーブルの全ての行を順番に見ることです。
これは、大きなテーブルの場合には時間がかかります。
代わりに、条件に合致するデータだけを見る方法を使いましょう。
例えば: もし、友達がたくさんいるクラスで「女の子の生徒の数」を数えるとき、一人ひとり名前を確認するのは大変ですよね。
でも、クラスの名簿に「女の子」と書いてあるページだけを見れば、女の子の数がすぐにわかります。
3. 使わないデータを取らない
クエリで必要なデータだけを取ることが大切です。
余分なデータを取ってくると、クエリの処理が遅くなります。
例えば: もし、アイスクリームのメニューから「バニラアイス」と「ストロベリーアイス」だけを注文する場合、他のアイスクリームの名前や味を聞く必要はありません。
必要な情報だけを聞くとスムーズに注文ができます。
当たり前のことしか書いてませんが、改めて上記の3点のポイントが自分のSQLでも実現できているか再確認しましょう!
実践的な例
シンプルな例
クエリの例:
PostgreSQLのサンプルデータベースにある"employees"というテーブルがあり、従業員の情報が保存されています。
このテーブルには以下のようなカラムがあります。
テーブル名: employees
| emp_id | first_name | last_name | department | salary |
|---|---|---|---|---|
| 1 | John | Doe | IT | 50000 |
| 2 | Jane | Smith | HR | 45000 |
| 3 | Mike | Johnson | IT | 55000 |
目的:
このデータベースで、"IT"部門の従業員の数と平均給与を求めたいとします。
クエリ:
SELECT COUNT(emp_id) AS num_employees, AVG(salary) AS avg_salary
FROM employees
WHERE department = 'IT';
解析手順:
このクエリの実行計画を知るために、EXPLAINコマンドを使ってみましょう。
EXPLAIN SELECT COUNT(emp_id) AS num_employees, AVG(salary) AS avg_salary
FROM employees
WHERE department = 'IT';
出力結果:
| QUERY PLAN |
|---|
| Aggregate (cost=18.41..18.42 rows=1 width=16) |
| -> Index Scan using idx_department on employees (cost=0.14..18.41 rows=1 width=4) |
| Index Cond: (department = 'IT'::text) |
解析結果:
-
QUERY PLAN: クエリの実行計画を示します。
-
Aggregate: クエリの集約処理を示します。
この場合はCOUNTとAVGが含まれていることを示します。
(上記のプランノードに添付している画像参照) -
cost: クエリの実行にかかるコストを示します。
数字が小さいほどコストが低く、効率的なクエリと言えます。 -
rows: クエリの結果として返される行数を示します。
このクエリでは、"IT"部門の従業員の数が1行になることがわかります。 -
width: クエリの結果の幅を示します。
このクエリでは、2つのカラム(num_employeesとavg_salary)を含む16バイトの幅があることがわかります。 -
Index Scan: インデックススキャンを示します。
この場合、"idx_department"というインデックスを使ってdepartmentカラムを検索しています。 -
Index Cond: インデックスの条件を示します。
このクエリでは、"department = 'IT'::text"という条件でインデックスが使われていることがわかります。
解析結果の意味:
このクエリでは、「IT」部門の従業員の数と平均給与を求めています。
EXPLAINの結果からわかることは、
データベースがインデックスを使って"department"カラムを検索しており、
"IT"部門の従業員だけを集計していることがわかります。
そして、"IT"部門の従業員は1人で、平均給与は55000ドルになることがわかります。
これが、PostgreSQLを使ったEXPLAINコマンドの実践的な解析手法になります。
Inner Joinを使用した例
クエリの例:
employeesテーブルには従業員の情報が、departmentsテーブルには部署の情報が保存されています。
それぞれのテーブルの内容は以下のようになっています。
テーブル名: employees
| emp_id | first_name | last_name | department_id | salary |
|---|---|---|---|---|
| 1 | John | Doe | 101 | 50000 |
| 2 | Jane | Smith | 102 | 45000 |
| 3 | Mike | Johnson | 101 | 55000 |
テーブル名: departments
| department_id | department_name |
|---|---|
| 101 | IT |
| 102 | HR |
| 103 | Finance |
目的:
このデータベースで、従業員の情報と部署名を結合して取得したいとします。
クエリ(inner join):
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
解析手順(inner join):
このクエリの実行計画を知るために、EXPLAINコマンドを使ってみましょう。
EXPLAIN SELECT e.first_name, e.last_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
出力結果(inner join):
| QUERY PLAN |
|---|
| Hash Join (cost=7.30..13.80 rows=3 width=42) |
| Hash Cond: (e.department_id = d.department_id) |
| -> Seq Scan on employees e (cost=0.00..5.25 rows=225 width=30) |
| -> Hash (cost=4.30..4.30 rows=30 width=18) |
| -> Seq Scan on departments d (cost=0.00..4.30 rows=30 width=18) |
解析結果(inner join):
-
QUERY PLAN: クエリの実行計画を示します。
-
Hash Join: ハッシュ結合を示します。
この場合、employeesテーブルとdepartmentsテーブルをdepartment_idカラムで結合しています。 -
cost: クエリの実行にかかるコストを示します。
数字が小さいほどコストが低く、効率的なクエリと言えます。 -
rows: クエリの結果として返される行数を示します。
このクエリでは、3行(John Doe、Jane Smith、Mike Johnsonの3名分のデータ)が結果として返されることがわかります。 -
width: クエリの結果の幅を示します。
このクエリでは、3つのカラム(first_name、last_name、department_name)を含む42バイトの幅があることがわかります。 -
Seq Scan: シーケンシャルスキャンを示します。
Seq Scanはテーブルを順番にスキャンする方法で、インデックスが使われていないことを意味します。 -
Hash Cond: ハッシュ結合の条件を示します。
このクエリでは、"e.department_id = d.department_id"という条件で結合が行われていることがわかります。
解析結果の意味(inner join):
このクエリでは、employeesテーブルとdepartmentsテーブルをdepartment_idカラムで結合して、従業員の情報と部署名を取得しました。
EXPLAINの結果からわかることは、
データベースがハッシュ結合を使って結合しており、
シーケンシャルスキャンが行われていることがわかります。
そして、3つの行が結合されて結果として返されることがわかります。
シーケンシャルスキャンが使われている=インデックスが使用されてない
ということなので、インデックスを使用できるかどうか検討してみてください。
(ただし、インデックスを使えばいいというものではないので慎重に....)
Left Joinを使用した例
クエリ(left join):
次に、left joinを使ったクエリを解析してみましょう。
EXPLAIN SELECT e.first_name, e.last_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id;
出力結果(left join):
| QUERY PLAN |
|---|
| Hash Left Join (cost=7.80..15.30 rows=3 width=42) |
| Hash Cond: (e.department_id = d.department_id) |
| -> Seq Scan on employees e (cost=0.00..5.25 rows=225 width=30) |
| -> Hash (cost=4.30..4.30 rows=30 width=18) |
| -> Seq Scan on departments d (cost=0.00..4.30 rows=30 width=18) |
解析結果(left join):
inner joinと出力結果はほぼ同じですが、Hash Left Joinという結合方法が使われています。これはleft joinを意味しています。
解析結果の意味(left join):
このクエリでは、employeesテーブルとdepartmentsテーブルをdepartment_idカラムでleft joinして、従業員の情報と部署名を取得するんだよね。EXPLAINの結果からわかることは、データベースがHash Left Joinを使ってleft joinしており、シーケンシャルスキャンが行われていることがわかります。そして、3つの行がleft joinされ
て結果として返されることがわかります。
まとめ
以上が、PostgreSQLでinner joinとleft joinを使用した例に対するEXPLAINコマンドの解析手法の解説です。
Explainの使い方としては、
・インデックスが貼られているか?使われているか?
・Seq Scanでテーブル読み込みしているデータ量が多すぎないか?検索条件で減らせないか?
(副問い合わせや、join条件なども確認)
などを探すのがメインになると思います。
これらの手法を理解して、データベースのクエリ最適化や効率的な結合方法を活用してください!