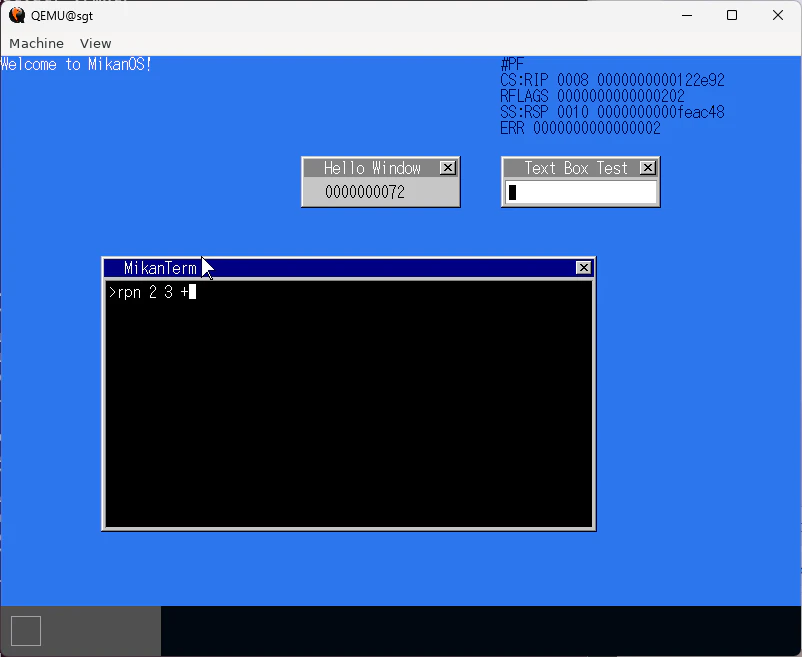
PFエラーの調査記録
『ゼロからのOS自作入門』を基にOSの勉強を進めていたところ,エラーが発生するという問題が起こりました.
プログラムは著者配布のものをそのまま実行していたため,自身のプログラムの記述ミスなどではなく,原因の特定にとても時間がかかりました.
よく頑張ったで賞を受賞できそうなこの取り組みを記録しました.
1.概要
今回のPF(ページフォールト)エラー,原因を一言で表すと
アプリが必要とするページ数の計算が正確でなかった
と言えます.
結果はシンプルですが,プログラムの細かいところまで把握していなかったので,どこでエラーがでているのか特定することが困難を極めました.
2.前提知識
① ページ確保
ページングの目的はアプリが使うメモリアドレスと物理アドレスの変換を行うことにあります.この仕組みにより,アプリケーションは連続したメモリを扱っているように見えます.
しかし実際のメモリは,4KB単位のページとして分割されて管理されています.そのため,必要なサイズをページ数に変換する処理が必要になります.
② ページフォールト
PFは「存在しないメモリアドレスへのアクセスがあった」という際にでるものです.
分かりやすい例を挙げると,Cで配列を確保する際,
int a[4];
a[5]; // 範囲外アクセス
のような状態です.
このエラーは単なる範囲外アクセスだけでなく,ページが未割り当てであったり,アクセス権限が不正である場合にも発生します.
3.エラー解決までの道のり
まずはエラーが発生している行の特定を進めました.
最もフィジカルで最もプリミティブなやり方としては,printfなどを挟んで確認する方法ですが,PFエラーが出た時点でOSが強制再起動してしまい,その方法ではうまくいきません.
(あと単純に画面に出力をさせるのめんどくさい)
なので似たような方法としてCPUをスリープさせる,
while(1) __asm__("hlt");
を置いて実行するという方法をとりました.
これによりエラー発生箇所は特定できましたが,これだけではわからないことも多く,解決できませんでした.
次にエラーが発生したときのRIPやCR2の値を確認してエラーの特定を進めようとしました.
- RIP:次に実行される命令のアドレス
- CR2:ページフォールト発生時にアクセスしようとした仮想アドレス
しかし,出力されるのは memcpy でエラーが出ているという情報でした.
PFエラーであれば,このようなメモリアクセス周辺で発生するのは自然であり,これでも特定はできませんでした.
エラーの特定もできず,解決策も浮かばずでAIとしばらくおしゃべりしていたところ,突然のセリフ
👉 これは1ページ(4KB)を超えている
これが決め手となり解決の糸口を見つけました.
4.解決
問題はこの行です.
const auto num_4kpages = (phdr[i].p_memsz + 4095) / 4096;
この行はページ数を計算する式ですが,試しに 4095 を 4095 * 2 にしてみたところ,エラーが発生せずアプリを実行することが出来ました.
ページ数を決める計算式は前述の通り,
(メモリサイズ + 4095) / 4096
で表されています.
例えばメモリサイズが16MiBならば,
((16 × 1024 × 1024) + 4095) / 4096 = 4096(小数点以下切り捨て)
となります.
しかしこれは
「アドレスがページ境界に揃っている」前提
になっています.
■ ページ境界に揃っている場合(OK)
アドレス →
┌──────────────┬──────────────┬──────────────┐
│ Page 0 │ Page 1 │ Page 2 │
│ 0x0000~ │ 0x1000~ │ 0x2000~ │
├──────────────┼──────────────┼──────────────┤
│■■■■■■■■■■■■■■■■■■■■■■■■■│ │ │
└──────────────┴──────────────┴──────────────┘
↑
開始アドレス(ページ境界)
✔ 必要なページ数 = サイズ ÷ 4096 でOK
■ ページ境界に揃っていない場合(NG)
アドレス →
┌──────────────┬──────────────┬──────────────┐
│ Page 0 │ Page 1 │ Page 2 │
│ 0x0000~ │ 0x1000~ │ 0x2000~ │
├──────────────┼──────────────┼──────────────┤
│ ░░░░░░■■■■■■■■■■■■■■■■■│■■■■■■■■ │
└──────────────┴──────────────┴──────────────┘
↑
開始アドレス(ページ途中)
❌ サイズだけで計算すると Page 1 までしか確保されない
❌ しかし実際は Page 2 にもはみ出す
👉 その結果:未マップ領域にアクセスして PF 発生
そのため簡単な対処としては,
ページ数を +1 する
だけでも解決します.
ただしこれは少し無駄があるため,より正確には以下のようにきちんと計算するべきです:
const uint64_t start = phdr[i].p_vaddr;
const uint64_t end = start + phdr[i].p_memsz;
const uint64_t page_start = start & ~0xfff;
const uint64_t page_end = (end + 0xfff) & ~0xfff;
const auto num_4kpages = (page_end - page_start) / 4096;
アドレス →
┌──────────────┬──────────────┬──────────────┐
│ Page 0 │ Page 1 │ Page 2 │
│ 0x0000~ │ 0x1000~ │ 0x2000~ │
├──────────────┼──────────────┼──────────────┤
│ ░░░░░░■■■■■■■■■■■■■■■■■■■■■■■■■| │
└──────────────┴──────────────┴──────────────┘
✔ Page 0〜2 をまとめて確保
✔ はみ出しを含めて安全にマッピング
5.なぜELFローダのアドレスがページ境界にそろってないのか
冷静に考えると,アドレスを強制的にページ境界にそろえたほうがこのような問題は起きず,実装も単純になりそうです.
ではなぜ,そのような設計になっていないのでしょうか?
これは一見単純化に見えますが,実際にはトレードオフがあります.
まず,ELFはビルド時にファイル上の位置とメモリ上の配置の対応関係がプログラムヘッダとして埋め込まれています.もし強制的にページ境界に揃えるとこの対応関係が崩れてしまいます.
■ イメージ
▼ 正しい配置(対応が一致している)
file memory
0x0100 ───────→ 0x1003
0x0101 ───────→ 0x1004
0x0102 ───────→ 0x1005
✔ ファイルとメモリが1対1で対応
✔ プログラムは正しく動く
▼ 無理やりページ境界に揃えた場合
file memory
0x0100 ───────→ 0x1000 ← 強制的に揃えた
0x0101 ───────→ 0x1001
0x0102 ───────→ 0x1002
❌ 本来の位置からズレる
❌ ポインタやジャンプ先が壊れる
また,ページ境界に揃えるために不要な空き領域が生じる可能性があり,メモリ効率の観点でも不利になります.
多くの場合,リンカによって結果的にページ境界に揃うことが多いですが, 仕様上は必須でなく,ずれている場合もあります.
Linuxなどではこの問題に対する対応をローダ側で施していますが,本書のコードではこの問題に対する明示的な対処が行われていません.
その理由として考えられるのは,
「たまたま問題が顕在化しなかった」
可能性です.
実際,ELFのセグメント配置がページ境界にうまく揃っている場合には,単純なページ数計算でも問題は発生しません.
つまり,本書の実行環境やビルドされたバイナリの状態では,偶然にもページ境界と整合する配置になっていたため,このバグが表面化しなかったと考えられます.
しかし,環境やコンパイラ,リンク方法が少し変わるだけで,このような前提は容易に崩れます.
今回のケースは,
その「たまたま」の外側に出てしまった例
だと言えます.
6.まとめ
本書の通りに進めていれば間違いはないだろう,という考えを真正面から砕かれた出来事でした.今回の問題の本質は,「前提が間違っていたこと」,そしてそれが「たまたま正しく見えていたこと」にあります.
正しく動いているコードであっても,その裏にある前提が保証されていなければ,環境が変わった瞬間に破綻します.その意味で,正しい設計というのは想像以上に深く,険しい道のりなのだと実感しました.
このエラーを解決する過程で実装を隅から隅まで読み込んだ結果,ページングの仕組みや処理の流れをよく理解することができました.OSは起動して当たり前なインフラですが,その当たり前はわずか1行のミスで簡単に崩れ,しかも復旧は容易ではありません.その事実こそが,OS開発の難しさをよく表していると感じます.
今回の経験を経て,最近トラブルの多いWindows君にも,少しだけ優しく接してみようと思います🙃.