要件
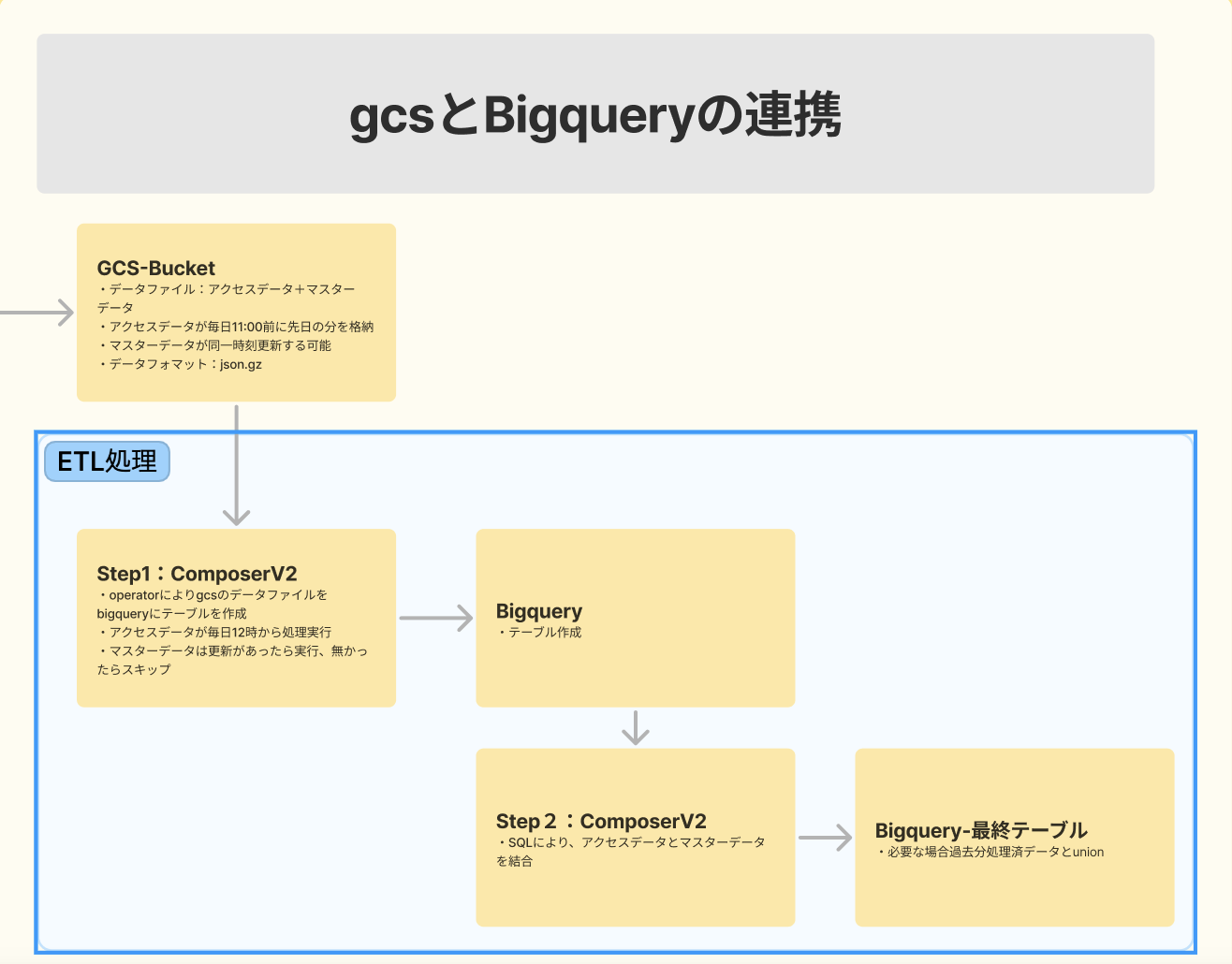
gcsに毎日更新するデータファイルと一部更新可能なマスターデータファイルを毎日12時Bigqueryにファイルごとテーブルを作成する。
イメージが下記の図のように、Step1~Step2までの部分を実装します。
Runtime
composer:2.0.21
Airflow:2.2.5
python: 3.8
(GCPやcomposerの環境設定については割愛)
実装
Dagの基幹クラス
(先輩が作っていただいたものを個人や会社の情報を削除してから、そのまま流用)
import os
from abc import ABCMeta, abstractmethod
from datetime import datetime
import airflow
from airflow import DAG
DEFAULT_OWNER = 'airflow'
class DagBase(metaclass=ABCMeta):
def __init__(self,
file_name: str,
doc_md: None,
schedule_interval=None,
owner=DEFAULT_OWNER,
catchup=False,
start_date=datetime(datetime.today().year, datetime.today().month, datetime.today().day)
):
self._dag_id = os.path.basename(file_name).replace(".pyc", "").replace(".py", "")
self._env_id = airflow.settings.conf.get("core", "environment_id")
self._schedule_interval = self._set_schedule_interval(schedule_interval=schedule_interval)
self._owner = owner
self._is_catchup = catchup
self._start_date = start_date
self._doc_md = doc_md
@abstractmethod
def generate_tasks(self):
"""
:return:
"""
pass
def generate_dag(self) -> DAG:
"""
:return: DAG
"""
with DAG(
dag_id=self._dag_id,
start_date=self._start_date,
schedule_interval=self._schedule_interval,
catchup=self._is_catchup,
doc_md=self._doc_md,
default_args={
"owner": self._owner,
"schedule_interval": self._schedule_interval,
"start_date": self._start_date
}
) as dag:
self.generate_tasks()
return dag
mainDAGの部分
from datetime import date, timedelta
from airflow.providers.google.cloud.operators.bigquery import BigQueryInsertJobOperator
from tool import dag_tools
from dag_base.dag_base import DagBase
from airflow.operators.dummy_operator import DummyOperator
from airflow.models import Variable
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import GCSToBigQueryOperator
class Dag(DagBase):
def __init__(self):
super().__init__(file_name=__file__,
doc_md=__doc__,
schedule_interval="0 12 * * *")
# task_sequence
def generate_tasks(self):
start = DummyOperator(task_id="start")
sleep = DummyOperator(task_id="sleep")
wait = DummyOperator(task_id="wait",
trigger_rule='all_done')
end = DummyOperator(task_id="end")
master_table_list = []
access_table_list = []
for i in table_list:
if "accesses" in i:
access_table_list.append(i)
else:
master_table_list.append(i)
masterToBigqueryList = self.task_list_master(master_table_list)
accessToBigqueryList = self.task_list_access(access_table_list)
bigqueryJob = self.bigquery_query_execute()
start >> accessToBigqueryList >> sleep >> masterToBigqueryList >> wait >> bigqueryJob >> end
def task_list_master(self, master_table_list):
masterToBigqueryList = []
# master_tables処理タスク
dealMasterTable = self.deal_master_table(master_table_list=master_table_list)
for i in dealMasterTable:
task_id = i + "_Master"
table_name = i.split(".")[0].split(f"_{yesterday}")[0]
masterToBigquery = GCSToBigQueryOperator(
task_id=task_id,
bucket=BUCKET,
source_objects=[PATH_PREFIX + i],
source_format="NEWLINE_DELIMITED_JSON",
compression="GZIP",
destination_project_dataset_table=f"{DATASET}.{table_name}",
create_disposition="CREATE_IF_NEEDED",
write_disposition="WRITE_TRUNCATE",
autodetect=True,
retries=0
)
masterToBigqueryList.append(masterToBigquery)
return masterToBigqueryList
def task_list_access(self, access_table_list):
accessToBigqueryList = []
# access_tables処理タスク
dealAccessTable = self.deal_access_table(access_table_list=access_table_list)
for i in dealAccessTable:
task_id = i + "_Accesses"
output_table = "adebis-share_adebis_baitoru_com_121_accesses"
accessToBigquery = GCSToBigQueryOperator(
task_id=task_id,
bucket=BUCKET,
source_objects=[PATH_PREFIX + i],
source_format="NEWLINE_DELIMITED_JSON",
compression="GZIP",
destination_project_dataset_table=f"{DATASET}.{output_table}",
create_disposition="CREATE_IF_NEEDED",
write_disposition="WRITE_APPEND",
autodetect=True
)
accessToBigqueryList.append(accessToBigquery)
return accessToBigqueryList
def deal_access_table(self, access_table_list):
"""
access_table_list: 最新のアクセスデータファイルだけ返します
:return:List
"""
access_deal_table_list = []
for i in access_table_list:
if i.split("121_")[1].split("_")[1].split(".")[0] == yesterday:
access_deal_table_list.append(i)
return access_deal_table_list
def deal_master_table(self, master_table_list):
"""
master_table_list: 最新のマスターデータファイルだけ返します
:return:List
"""
master_deal_table_list = []
for i in master_table_list:
if i.split("121_")[1].split("_")[1].split(".")[0] == yesterday:
master_deal_table_list.append(i)
return master_deal_table_list
def bigquery_query_execute(self):
"""
Bigquery Job execute
:return: BigQueryInsertJobOperator
"""
table_for_join = "table-name"
Create_Table_Query = (
f"{QUERY}"
)
Bigquery_job = BigQueryInsertJobOperator(
task_id="Create_Join_Table",
configuration={
"query": {
"query": Create_Table_Query,
"useLegacySql": False,
}
},
location=LOCATION
)
return Bigquery_job
"""
Composer(Airflow)で設定した変数を取得
"""
# GCP上の設定
gcp_config = Variable.get("config", deserialize_json=True)
PROJECT_ID = gcp_config['project_id']
DATASET = gcp_config['dataset']
TABLE = gcp_config["table"]
LOCATION = gcp_config["location"]
BUCKET = gcp_config["bucket"]
PATH_PREFIX = gcp_config["path_prefix"]
# 処理テーブルリスト
table_list = dag_tools.get_all_tables_from_gcs(project_id=PROJECT_ID,
bucket_name=BUCKET)
# 当日一日前の日付け
yesterday = (date.today() - timedelta(days=1)).strftime("%Y%m%d")
# クエリ
QUERY = "(省略)"
# DAGの実行
dag = Dag()
do_Dag = dag.generate_dag()
GCSからファイルリスト取得するための方法
(from tool import dag_toolsの部分)
from google.cloud import storage
def get_all_tables_from_gcs(project_id, bucket_name):
client = storage.Client(project=project_id)
blobs = client.list_blobs(bucket_name)
file_list = []
for file in blobs:
# bucketのディレクトリ構造により調整
if file.name.split("/")[1]:
file_list.append(file.name.split("/")[1])
return file_list