(追記) 完全ではないですが実装公開しました. - https://github.com/S-aiueo32/SRRAM
今回取り上げる論文
Jun-Hyuk Kim, Jun-Ho Choi, Manri Cheon and Jong-Seok Lee,"RAM: Residual Attention Module for Single Image Super-Resolution", arXiv preprint arXiv:1811.12043, 2018
Yonsei University(韓国)の研究グループの論文です.ECCVの超解像コンペであるPIRMにも参戦してましたね.強い.
TL;DR
- 超解像でもAttentionがグイグイ来てるぞ!
- Spatial Attention(SA)とChannel Attention(CA)を組み合わせたResidual Attention Module(RAM)を提案するぞ!
- 実験を通して精度と軽量さについてSOTA達成したぞ!
前提知識
Attention
アンチDLの人達が攻撃してくる時に口を揃えて出てくるセリフの一つ,それは**「ブラックボックス」**.勾配を確率的に落とすガチャ的要素もあり,多層化に伴って中間層の可視化も難しくなってくるので,その主張はごもっともだと思います.
とはいえ,その解釈性に関するの研究も近年盛んになってきています.詳しくは話せませんが,クラスの出力値が最大になる入力を見つけたり,入力画像の一部をボカして出力値が変わるか確かめたりして意図した特徴を捉えてるかを確認する手法があります.
Attentionはその手法の一つで,元々は自然言語処理で単語に優先度によってマスクをかけたいみたいな目的で考えられました.そのマスクを見れば,どこを重要と解釈しているかが一目瞭然という感じ.これを画像キャプショニングに使ってみたら,単語ごとに画像のどこを見てるか確認できます.

さらに,上手くAttentionマップを作れていれば,欲しい特徴は強調,いらない特徴は抑制され,より精度の高い特徴抽出も望めます.
(参考01) ディープラーニングの判断根拠を理解する手法
(参考02) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Attentionブロックいろいろ
昨今では,Attentionは様々な画像認識タスクに用いられていて,超解像もその例外ではありません.画像認識におけるAttentionには,次の2種類が存在します.
- Spatial Attention(SA): どの位置を注視するかを算出,各チャネルに1枚ずつAttention Map
- Channel Attention(CA): どのチャネルを注視するかを算出,各チャネルに1枚ずつ値がある i.e. 長さがチャネル数と等しいベクトル
また,SAとCAは内部的に次の3つのプロセスに分けられます.
以下では,Attentionブロックの入出力特徴マップをそれぞれ $\mathrm{\textbf{X}} \in \mathbb{R}^{H \times W \times C}$ , $\mathrm{\hat{\textbf{X}}} \in \mathbb{R}^{H \times W \times C}$ とします.このとき$H$は特徴マップの高さ,$W$は幅,$C$はチャネル数を表します.また, $\sigma(\cdot)$ と $\delta(\cdot)$ はそれぞれシグモイド関数とReLUを表します.
- squeeze: 入力特徴マップ $\mathrm{\textbf{X}}$ の統計量 $\mathrm{\textbf{S}}$ を抽出
- CAの場合はglobal poolingを用いる
- SAの場合は1x1 Convolutionを用いる
- excitation: $\mathrm{\textbf{S}}$を用いて,Attention間の相互関係を捉えて特徴マップ $\mathrm{\textbf{M}}$ を出力
- CAの場合,$\mathrm{\textbf{M}}$のシェイプは$1 \times 1 \times C$
- SAの場合,$\mathrm{\textbf{M}}$のシェイプは$H \times W \times 1$
- scaling: $\mathrm{\textbf{M}}$を$[0, 1]$で正規化して$\mathrm{\textbf{X}}$に掛け合わせることで$\mathrm{\hat{\textbf{X}}}$を得る.要するにsigmoidするということ.
これらの組み合わせによってAttentionブロックには色々な種類があり,下記3つが代表的なものです.呪文みたいにアルファベットが連呼されるので注意です.
Residual Channel Attention Block (RCAB) [PDF][GitHub]
Residual Channel Attention Network(RCAN)で用いられてるCAブロックで,squeezeとexcitationを組み合わせたのと等価らしいです.図的はこんな感じ.ResNetらしくAttentionされたマップとブロックへの入力が最後に要素和を取ってますね.
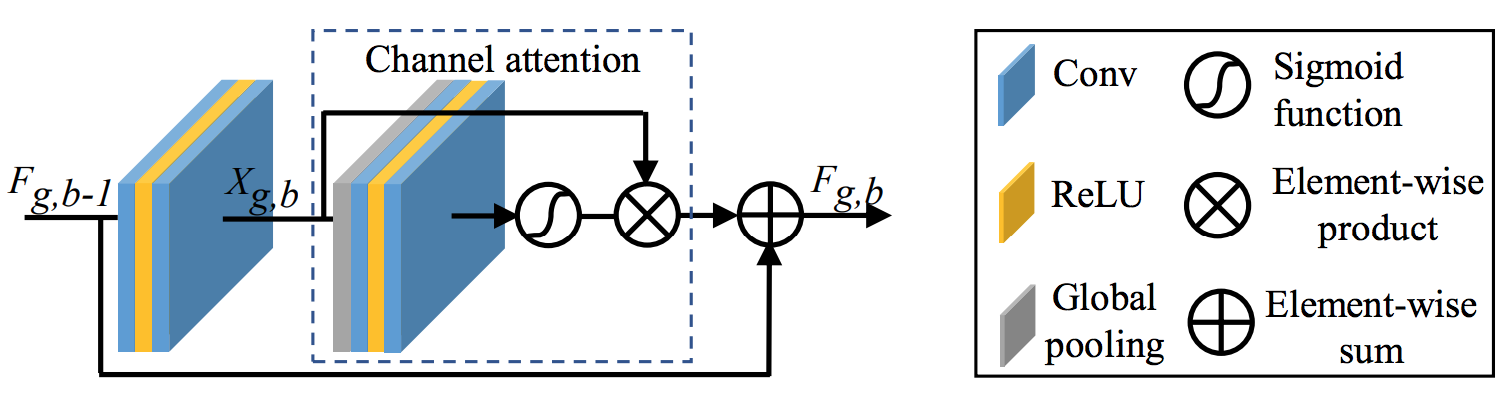
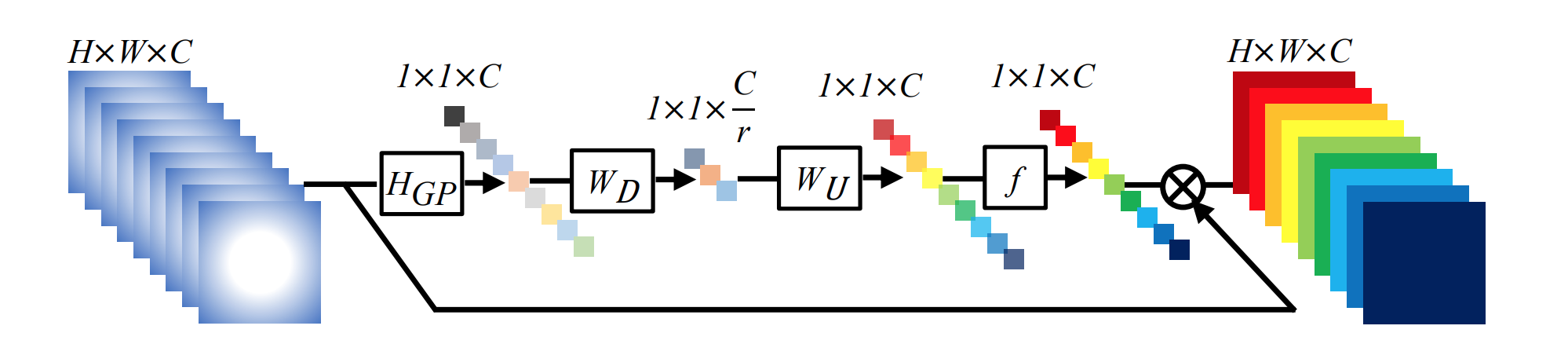
CAの部分を拡大.端的にいうと,global poolingで各チャネルを1つの値に固めて,全結合でうまい感じに特定のチャネルをAttentionしてやろうってことです.
出力マップは次式で計算されます.
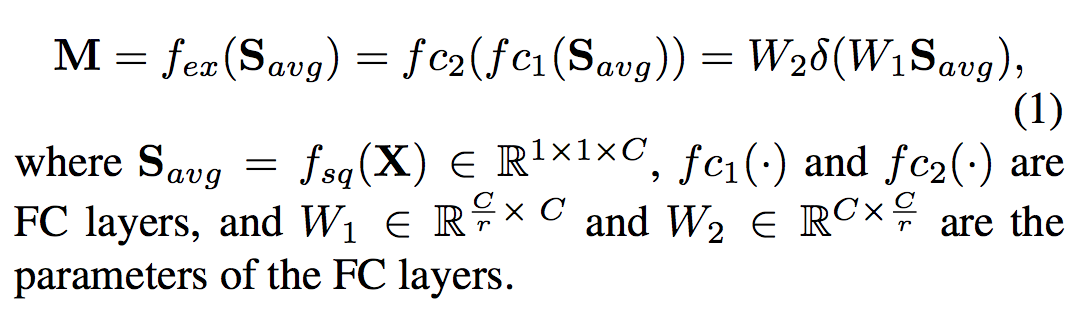
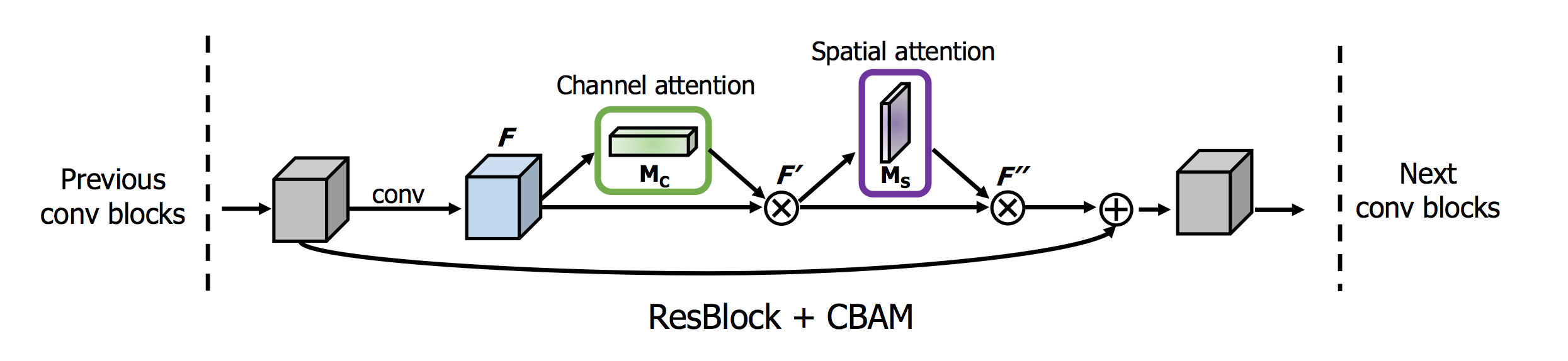
Convolutional Block Attention Module (CBAM) [PDF][GitHub]
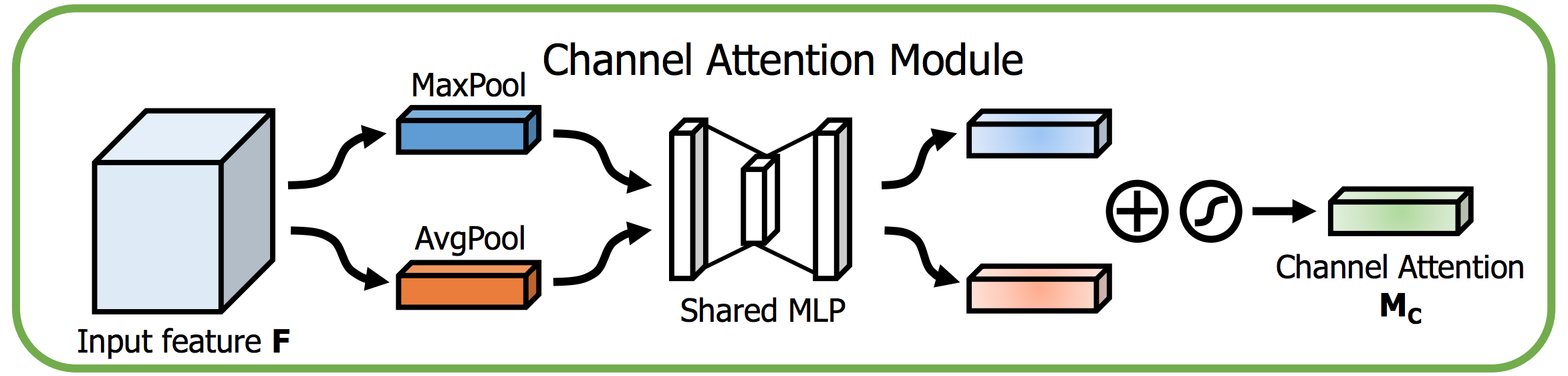
RCABがチャネル間の関係を使うのに対して,CBAMはチャネル内の空間的な関係も用います.CAとSA両方使うってことですね.まずはそれぞれについて見て行きましょう.
CBAMのCAでは,統計量を平均$\textbf{S}_{avg}$,最大$\textbf{S}_{max}$の2つをglobal poolingで計算します.これらを重み共有したネットワークに食わせた後,要素和を取ってAttentionマップを作ります.
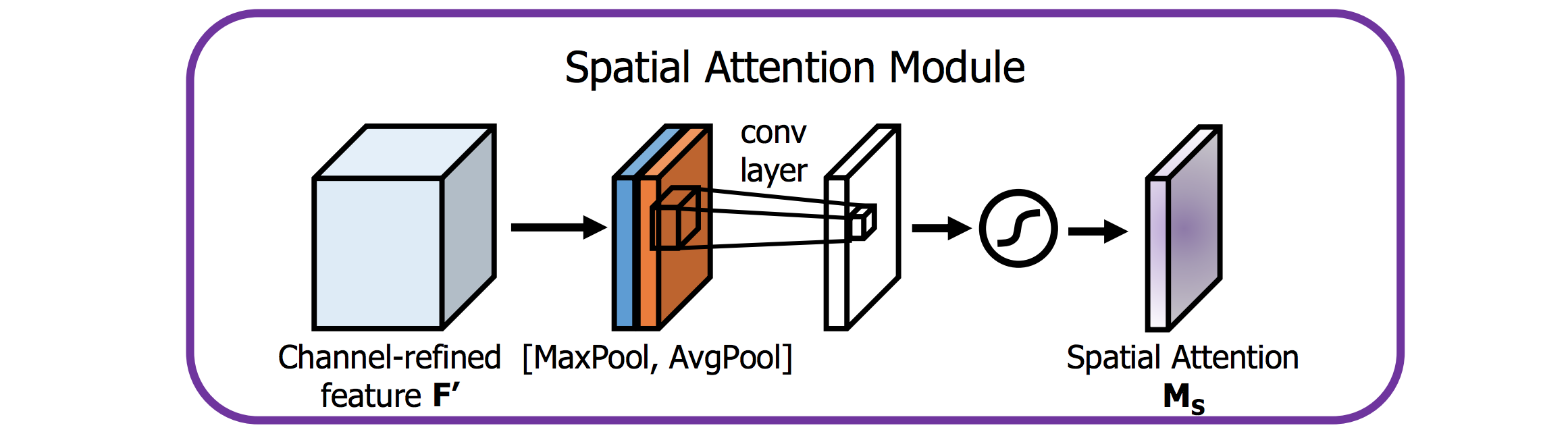
SAでも同様に,まず$\textbf{S}_{avg}$,$\textbf{S}_{max}$を計算します.その二つをconcatして畳み込むことでAttentionマップを得ます.
CAとSAができたので,どう適用するかは下図の通りです.CA→SAの順でAttentionして,全体としてResidualにしてます.
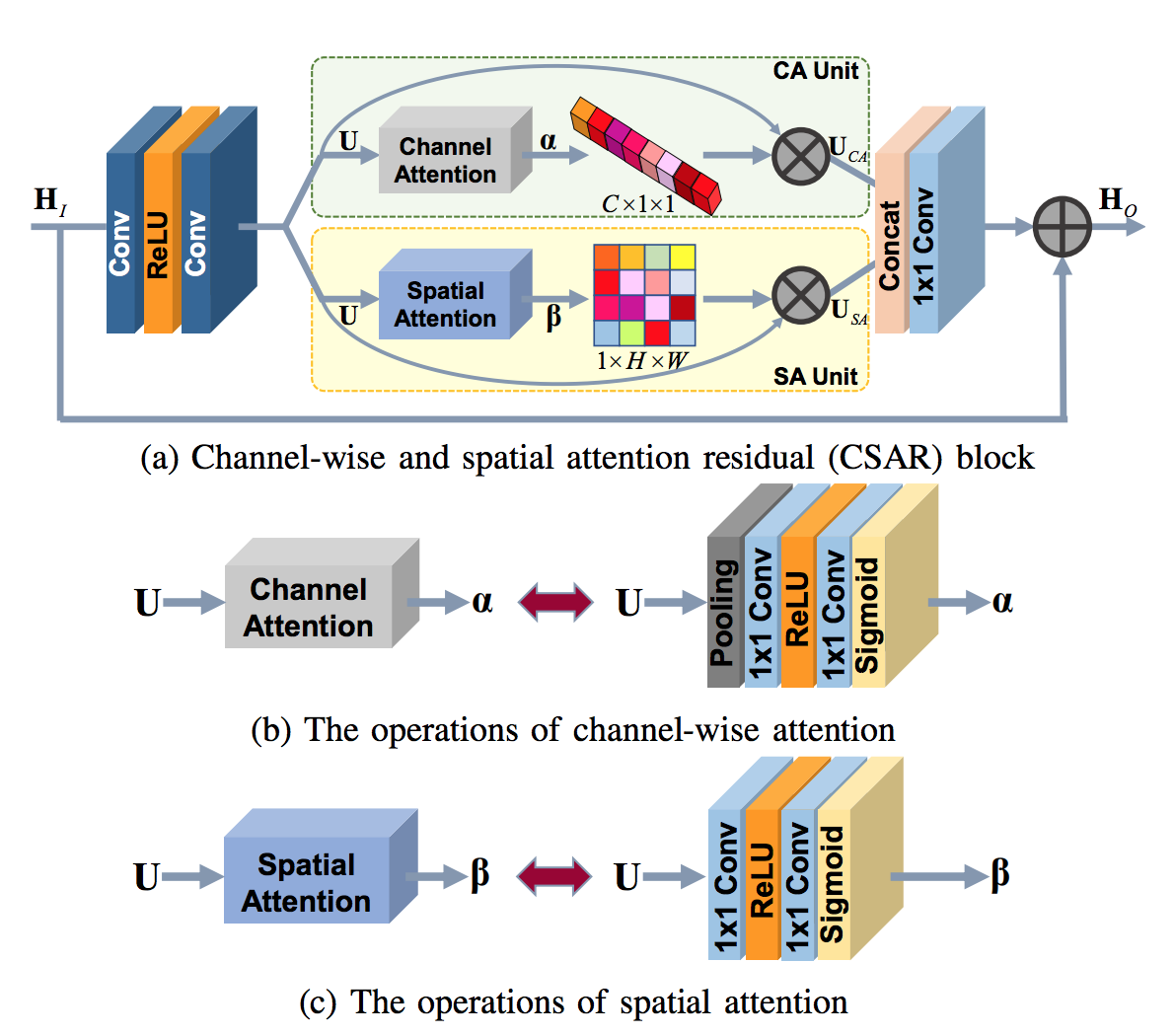
Channel-wise and Spatial Attention Residual block (CSAR block) [PDF]
CBAMと同じで,こちらもCAとSAの折衷でほぼ同じです.CBAMとの一番の差は,CBAMがCA→SAの順で直列に処理を進めるのに対して,CSAR blockではこれらを並列に行って,最後に1x1 Convolutionを用いて特徴量をFuseします.ちなみに,SAにおけるsqueezeプロセスを含みません.
提案手法
Residual Attention Module (RAM)
本論文では,下図のようなRAMというAttentionブロックの提案されています.
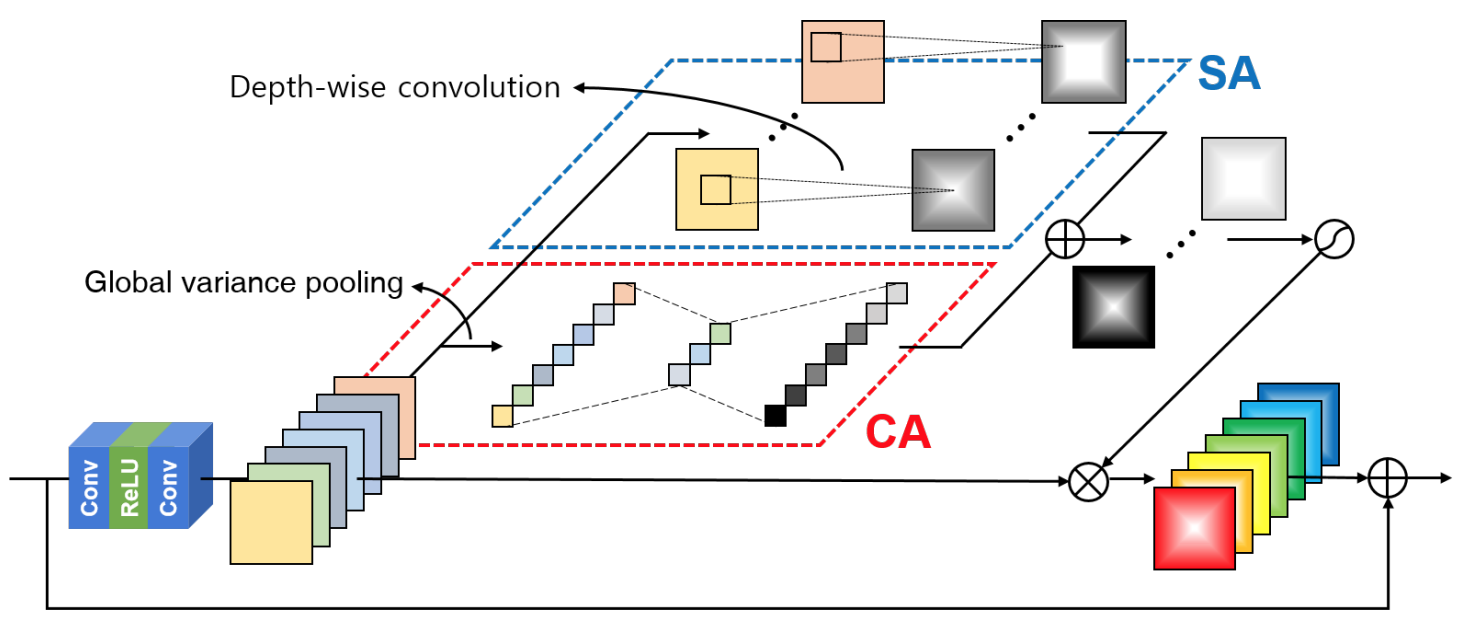
CAでは,統計量を計算するときにglobal variance poolingを使います.僕個人として初めてお目にかかりましたが,分散が高いマップの方が情報量は多いですから,強調してあげるとうまくいくって主張は何となく分かります.PCAの匂い.
SAでは,depth-wise convolution用いてます.普通の3x3 convolutionを適用して$C_{input} = C_{output}$とする場合,パラメータ数は$3 \times 3 \times C_{input} \times C_{output}$です.対して,3x3 depth-wise convlutionを用いると,$3 \times 3 \times C_{input}$となるためとっても軽量化できるんですね.また,CSAR blockと同様,squeezeプロセスを含みません.
ここで,主なAttentionブロックとRAMの比較をしてみましょう.最初からこの図を出せとかは言わないで.
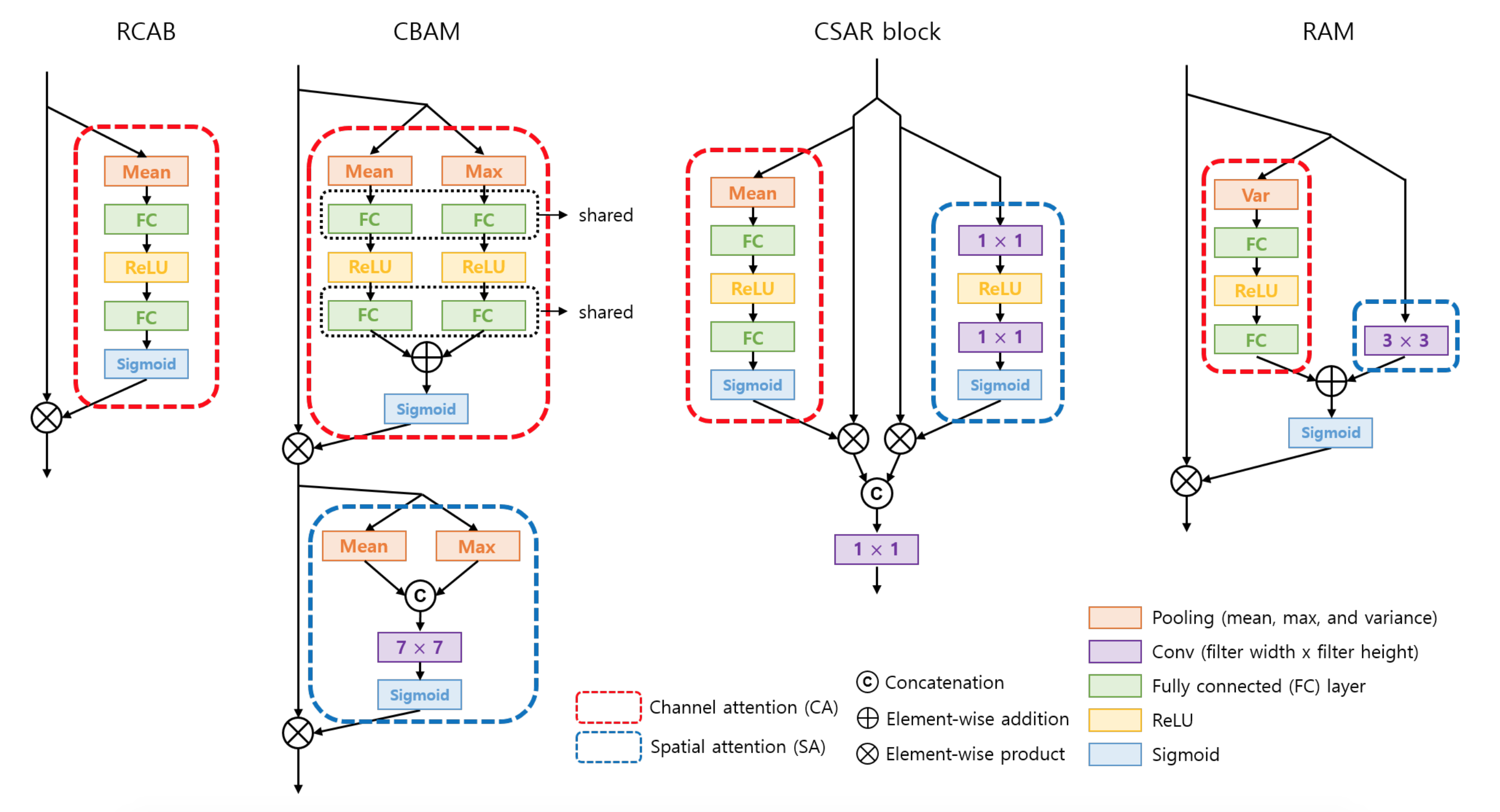
CBAM,CSAR blockではCAとSAがそれぞれ独立して適用されているのに対して,RAMではCAとSA同士をまずFuseしています.したがって,入力に対してAttentionが適用されるの1回のみです.大枠としてRCABのようなシンプルな構造を持つ一方,ちゃんとCAとSAを組み合わせているところが強みだと考えられます.
まとまると,RAMには下記のような工夫があります.
- ブロック内部に効率的なAttenntionや軽量化を意識した演算を採用
- ブロック全体としてシンプルさを維持しつつ,CAとSAの組み合わせを実現
SRRAM
RAMを用いた超解像用ネットワークをSRRAMとして提案しています.EDSRを意識した構造になっていて,特徴抽出部とアップスケール部に分けられます.特徴抽出部でひたすらブロックをスタックしていくよくあるネットワークって感じです.ネットワークは下図になります.

評価
ブロックの評価
ベースラインのネットワークを付け替えた評価結果の表です.評価指標はPSNRで,赤が1位,青が2位を示してます.ぱっと見でとりあえずRAMが強い.
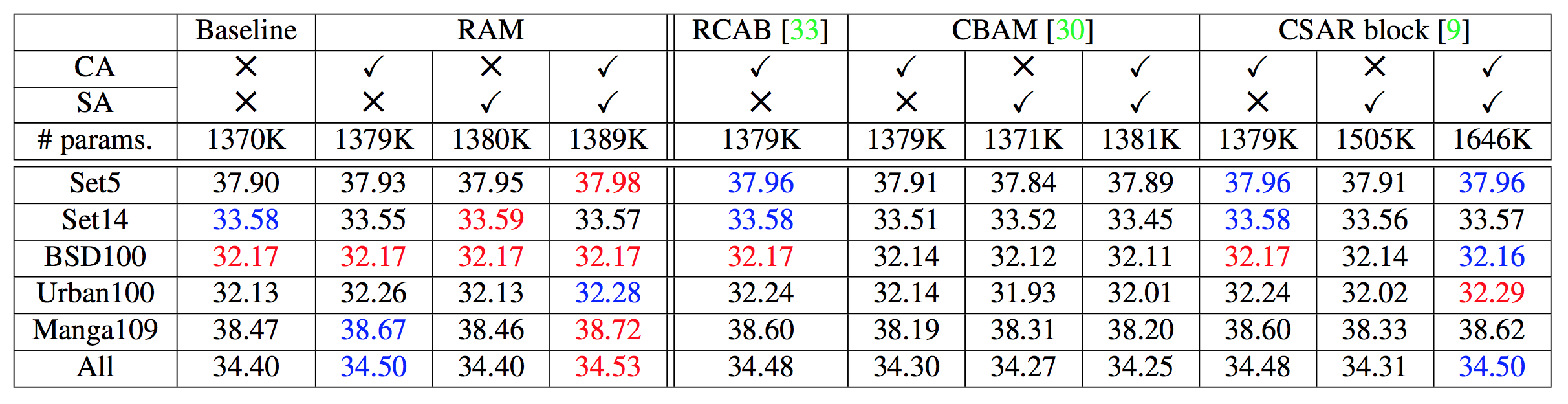
論文に書いてある主張としては,下記の点が挙げられます.
- CA+SAではRAMが一番強い
- チャレンジングなデータ(Urban100とManga109)にはvariance poolingが効果的
- CA単体はCSARより良くないけど,+SAでの精度向上量に対するパラメータ増加率で勝つる
各ブロック出力の分散
あまり理解していないけど,この図では,各ブロックのチャネルごとに分散を計算した結果です.白い方が高い分散だそうです.

下記主張がなされてます.
- CAに関しては,分散が大きい方が精度が良い(図が白い方がいい)
- SAに関しては,水平方向に黒い線がない,すなわち全てのチャネルを一律に抑制することがない.
- 全体として各フィルタが別々の役割をしていることがわかる(?)
出力される特徴マップ
1段目は高周波成分,2段目は低周波成分をAttentionできてるらしい.最後のはノイズっぽい入力だから全体を0にして無効化してくれてるらしい.

ブロック数 vs チャネル数
ブロック数を増やした方が効果的.あたりまえ体操.
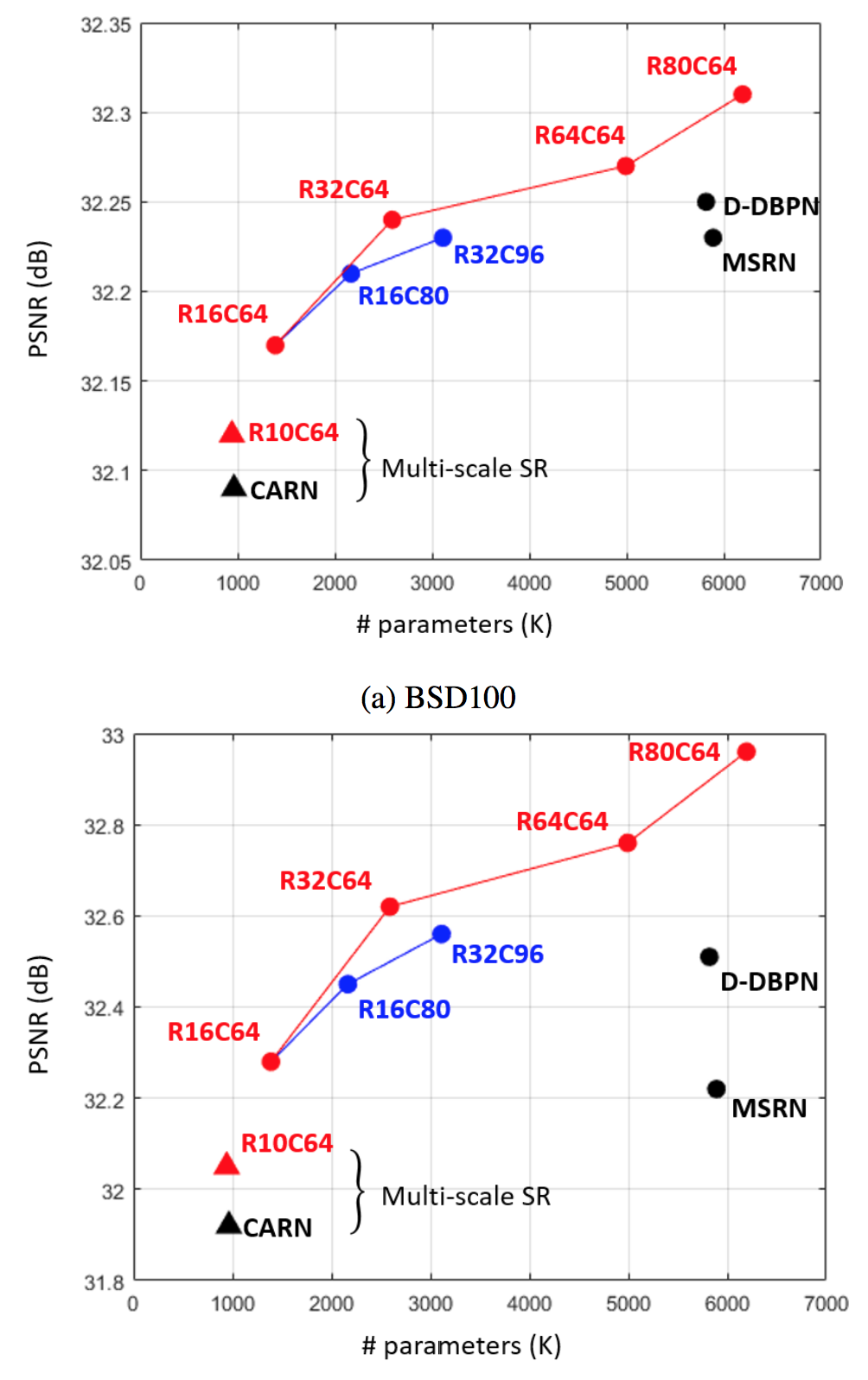
他の手法との比較
x3でSOTA.
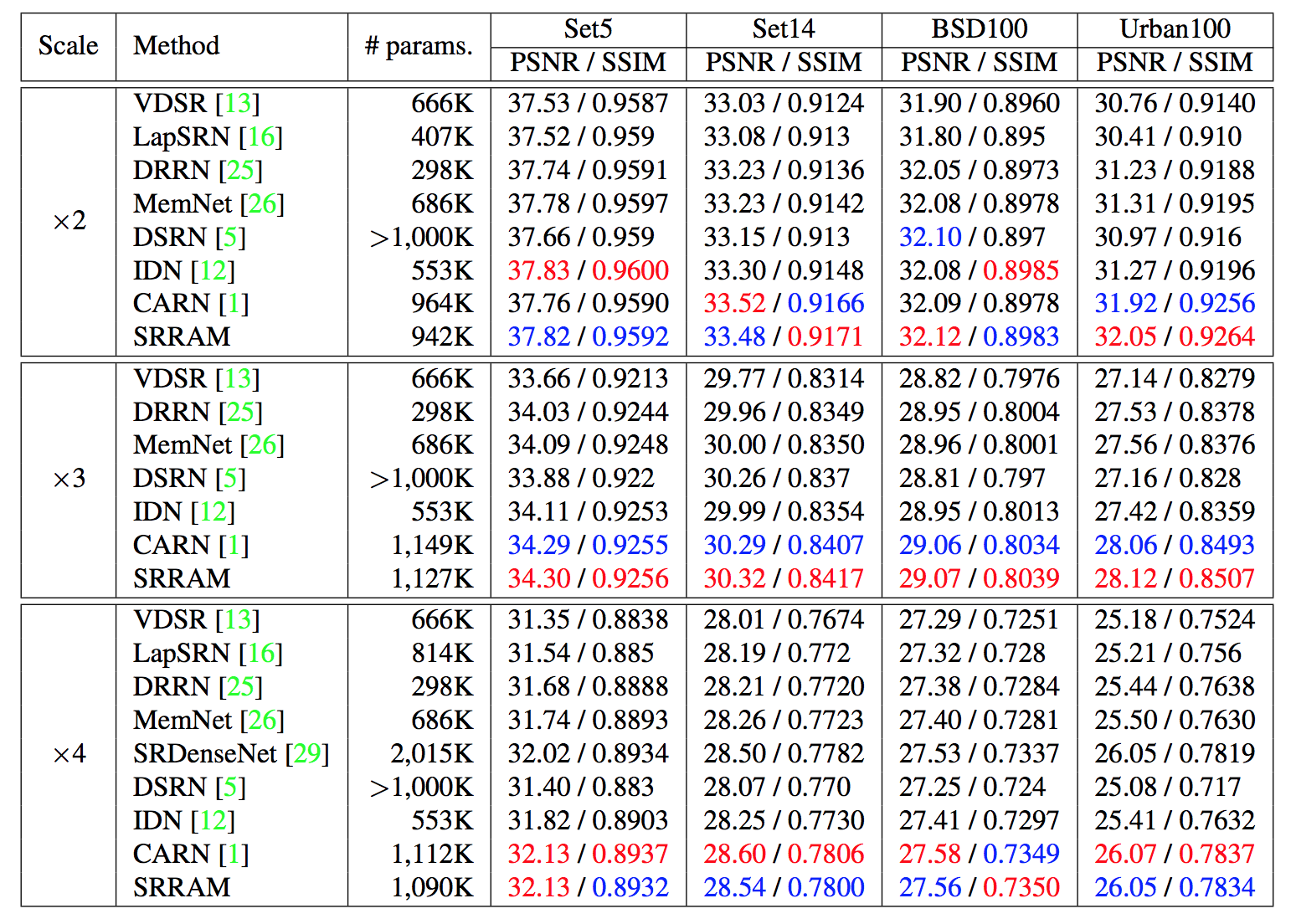
これはx2の結果.この画像ではすごくうまくいっている.付録がもっと欲しかった.

まとめ
- variance poolingやdepth-wise convolutionあたりは工夫が見られて面白かった
- 精度がそんなに上がったわけじゃないのはちょっと残念
- ブロック自体の評価はこれでいい気がするので,ネットワーク全体をもうちょっと頑張って欲しい
参考文献
- Jun-Hyuk Kim, Jun-Ho Choi, Manri Cheon and Jong-Seok Lee,"RAM: Residual Attention Module for Single Image Super-Resolution", arXiv preprint arXiv:1811.12043, 2018
- Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y. Fu. Image
super-resolution using very deep residual channel attention
networks. In Proceedings of the European Conference on
Computer Vision (ECCV), 2018. - S. Woo, J. Park, J.-Y. Lee, and I. So Kweon. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), 2018.
- Y. Hu, J. Li, Y. Huang, and X. Gao. Channel-wise and
spatial feature modulation network for single image superresolution. arXiv preprint arXiv:1809.11130, 2018.
おまけ
😡
