【はじめに】
本記事は、AWS LamdaおよびQuickSightを用いた、Qiita投稿記事投稿状況の可視化例をご紹介します。
記事内容に関しては前編と後編に分けてご紹介予定です。
※投稿状況の集計対象となるQiita投稿者アカウントのトークンを知っていることが前提となります。
※投稿状況の集計は、Qiitaが公開しているAPIを用います。
【実装内容】
今回の記事においては
・Lambda
・S3
・EventBridge
・QuickSight
・Glue
・Athena
上記AWSサービスを用いる。
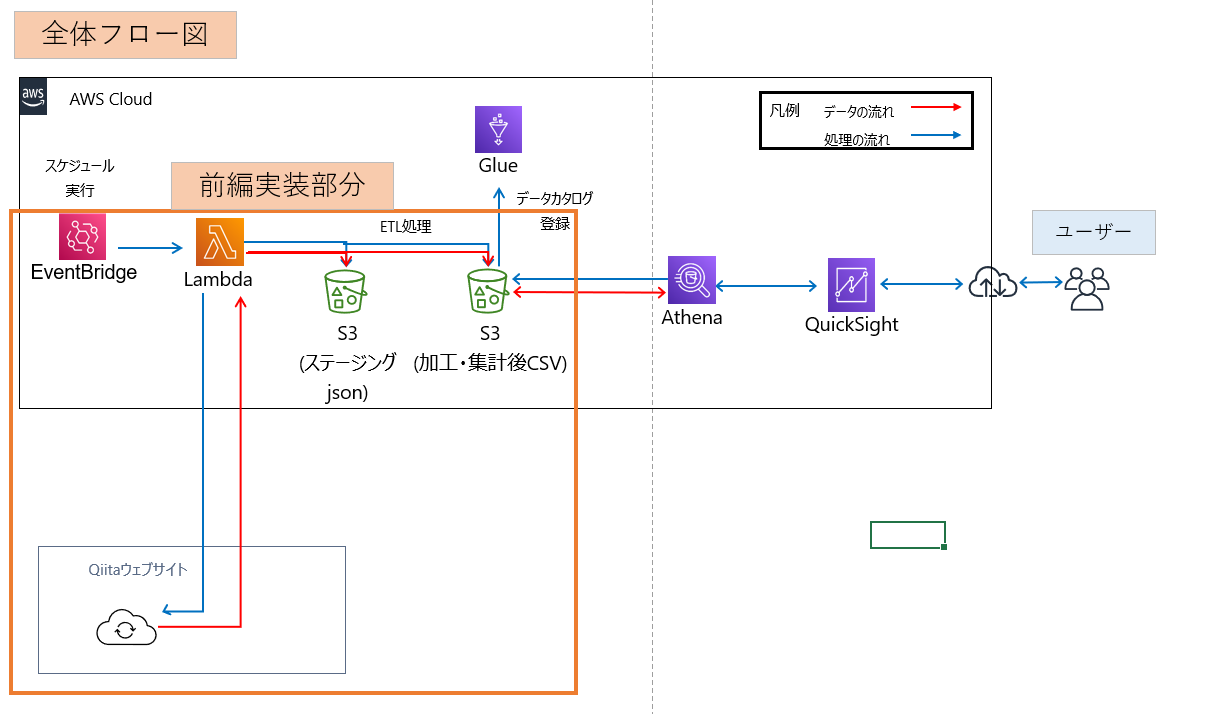
最終的な実装イメージ図は以下の通り、

【前編での実装の流れ】
①S3バケットの作成
②Lambda関数の作成
③ETL確認作業
④EventBridgeの設定
前編の実装イメージ図は以下の通り、
【実装】
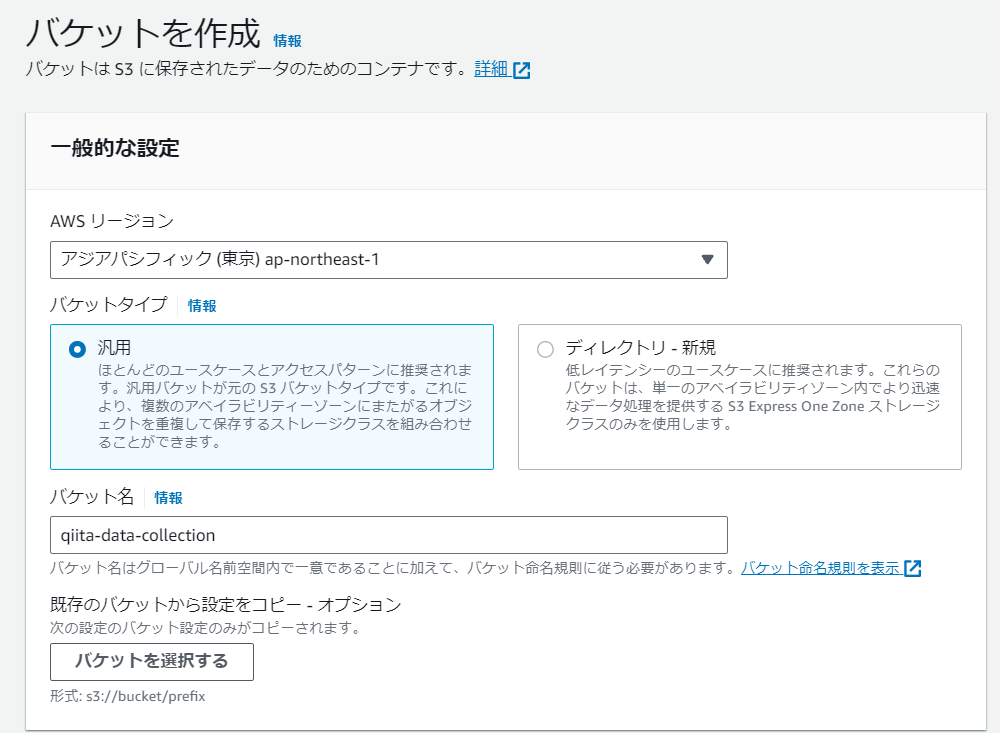
①S3バケットの作成
S3バケットを作成する。
AWSコンソールのサービス名「S3」を選択し「バケット作成」を実行する。

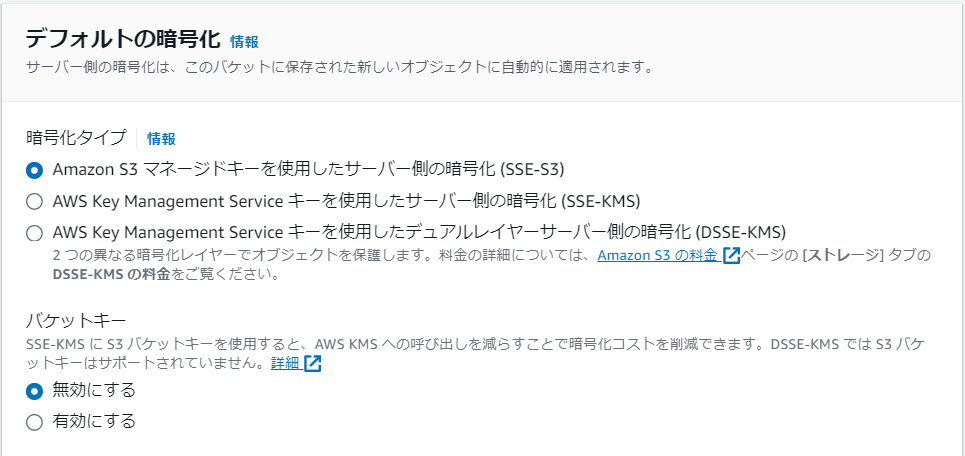
バケット名を「qiita-data-collection」とし、バケットキーは「無効にする」を選択する。ほかの設定はデフォルトのまま「バケット作成」を押下する。
【バケット名設定】
【バケットキー設定】
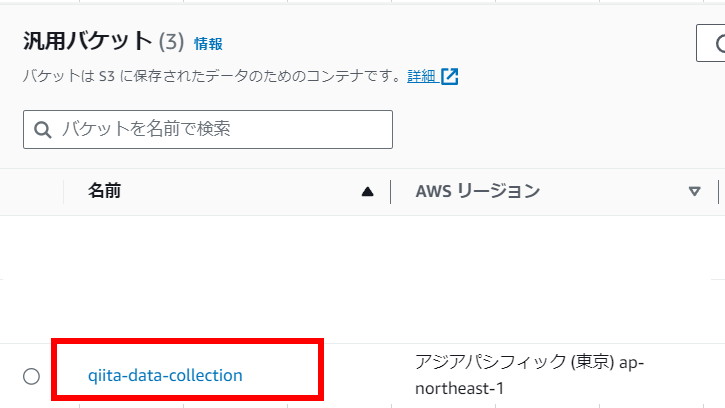
【バケット作成後】
②バケット内にオブジェクトを作成
QiitaのAPIを用いて取得したデータを格納するオブジェクトを作成する。
オブジェクトの構成は以下の通り。
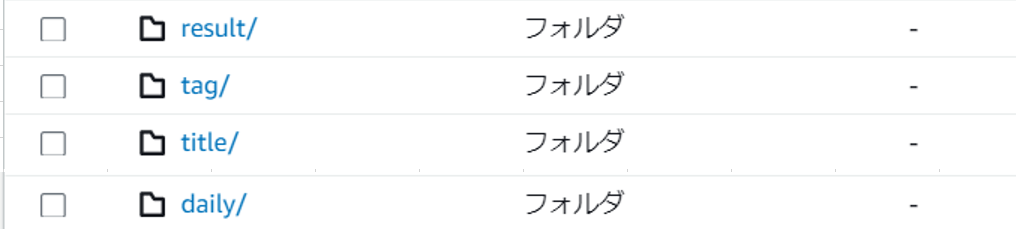
また各オブジェクトに格納するファイルは以下とする。
【result】
一日ごとの記事情報を個人トークから取得し、JSONファイルとして格納する。
【tag】
タグ別の集計データCSVファイルを格納する。
【title】
タイトル別の集計データCSVファイルを格納する。
【daily】
resultに格納するJSONファイルを整形し、CSVファイルとして格納する。
③Lambda関数を作成
①Lambda関数内にconfigフォルダを作成し、Qiita_APIを使用し、投稿情報を取得するための個人メンバーのトークン情報をconfig.pyに記載し配置する。
config.pyの内容は以下のような形
qiita_token = {
'氏名A':'QiitaトークンA',
'氏名B':'QiitaトークンB',
'氏名C':'QiitaトークンC',
・
・
・
'氏名Z':'QiitaトークンZ'
}
②Lambda関数においてpythonにてコード記述を行う。
コード記述内容は以下の通り。
①トークン情報からユーザーごとのQiita記事情報を取得する。
②取得した記事情報をJSON形式でS3のresultオブジェクトに格納する。
③取得した記事情報データを整形後CSVファイルとして保存し、
各オブジェクトtag、title、dailyに格納する。
④QuickSightのSPICEを更新する。
③Lambda関数のコード内容は下記の通り、
from config import config
import json
import datetime
import pprint
import csv
import itertools
import pandas as pd
import os
import boto3
###Lambda側でレイヤー追加が必要
import requests
def lambda_handler(event, context):
s3 = boto3.resource('s3')
qs = boto3.client('quicksight')
# 変数定義
##テーブル更新用
today1 = (datetime.datetime.utcnow() + datetime.timedelta(hours=9)).strftime('%Y%m%d')
today2 = (datetime.datetime.utcnow() + datetime.timedelta(hours=9)).strftime('%Y-%m-%d')
BUCKET_NAME = 'qiita-data-collection'
OBJECT_KEY_NAME = 'result/{}_result.json'.format(today1)
bucket = s3.Bucket(BUCKET_NAME)
obj = bucket.Object(OBJECT_KEY_NAME)
##SPICE更新用
today3 = (datetime.datetime.utcnow() + datetime.timedelta(hours=9)).strftime('%Y%m%d%H%M%S')
accountid='{#アカウントIDを記載する}'
dsid_list={'title_qiita':'{quick_sightの#データセットID}','tag_qiita':'{quick_sightの#データセットID}','qiita_daily':'{quick_sightの#データセットID}'}
#########qiita記事集計作業##################
# # メンバー全員の投稿アカウント毎の個人トークンの定義
tokens = config.qiita_token
# https のパラメータ情報
params = {
"page": "1",
"per_page": "100",
}
# 関数定義(投稿した記事のView数の取得)
def get_view(jsonlist, headers):
item_value=[]
for i, item in enumerate(jsonlist):
item_key=['User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'Title']
res2 = requests.get('https://qiita.com/api/v2/items/' + item['id'], headers=headers)
rec = json.loads(res2.text)
tags = [value['name'] for value in rec['tags']]
item_key.extend([f'tag_{idx+1}' for idx, value in enumerate(tags)])
item_key.append('update_day')
data = [rec['user']['id'], rec['url'], rec['page_views_count'], rec['likes_count'], rec['created_at'], rec['updated_at'], rec['title']]
data.extend([value for value in tags])
# update_day(取得日)に記事内容を取得した日本時間の日付を格納
data.append(today2)
item_value.append(dict(zip(item_key, data)))
return item_value
result = {}
# 関数定義(取得した記事情報をjosn形式に整える)
def get_post_list():
for user, token in tokens.items() :
# https のヘッダー情報 with 個人トークン
headers = {
"Authorization": "Bearer " + token
}
# 個人トークンを利用してのその個人の投稿記事情報の取得
res1 = requests.get('https://qiita.com/api/v2/authenticated_user/items', params=params, headers=headers)
jsonlist = json.loads(res1.text)
result[user] = get_view(jsonlist, headers)
r = obj.put(Body = json.dumps(result, ensure_ascii=False, indent=2))
print("【記事情報】" + str(json.dumps(result)))
print("【S3格納情報】】" + str(json.dumps(r)))
# 関数実行
get_post_list()
###############################################
#########データ整形、s3格納作業##################
# 実行結果を整える
iterator_list = list(itertools.chain.from_iterable(result.values()))
# json形式ファイルをデータフレームに格納
df = pd.io.json.json_normalize(iterator_list)
# データフレームにtag1~5までない場合にtagを追加する
col =df.columns
for i in range(5):
if 'tag_' + str(i+1) not in col:
df['tag_' + str(i+1)] = pd.Series()
# データフレームのカラムの順序を入れ替える
df = df.loc[:,[ 'Title','tag_1', 'tag_2', 'tag_3', 'tag_4', 'tag_5','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day']]
df['truncate_at'] = pd.to_datetime(df['created_at']).dt.round('D')
df = df.astype({'truncate_at':'str'})
df['truncate_at']= df['truncate_at'].str[0:11]
df['truncate_at'] = pd.to_datetime(df['truncate_at'])
daily_df = df
# 日々の推移データ用のs3にcsvを格納する
d_output_file = 'qiita_' + today1 + '.csv'
d_output_path = '/tmp/{}'.format(d_output_file)
daily_df.to_csv(d_output_path, index=False, encoding='utf-8_sig', quoting=csv.QUOTE_ALL)
bucket.upload_file(d_output_path, 'daily/' + '{}'.format(d_output_file))
print(os.listdir('/tmp/'))
for i in os.listdir('/tmp/'):
os.remove('/tmp/'+i)
print(os.listdir('/tmp/'))
# タイトルの閲覧ランキング用のs3にcsvを格納する
title_df = df
t_output_file = 'title_qiita.csv'
t_output_path = '/tmp/{}'.format(t_output_file)
title_df.to_csv(t_output_path, index=False, encoding='utf-8_sig', quoting=csv.QUOTE_ALL)
bucket.upload_file(t_output_path, 'title/' + '{}'.format(t_output_file))
print(os.listdir('/tmp/'))
for i in os.listdir('/tmp/'):
os.remove('/tmp/'+i)
print(os.listdir('/tmp/'))
# タグごとに集計するために各タグのデータフレームを作成しユニオン
df['post_counts'] =1
df1 = df.loc[:,[ 'Title','tag_1','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day', 'truncate_at', 'post_counts']]
df2 = df.loc[:,[ 'Title','tag_2','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day', 'truncate_at', 'post_counts']]
df2 = df2.rename(columns = {'tag_2':'tag_1'})
df3 = df.loc[:,[ 'Title','tag_3','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day', 'truncate_at', 'post_counts']]
df3 = df3.rename(columns = {'tag_3':'tag_1'})
df4 = df.loc[:,[ 'Title','tag_4','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day', 'truncate_at', 'post_counts']]
df4 = df4.rename(columns = {'tag_4':'tag_1'})
df5 = df.loc[:,[ 'Title','tag_5','User', 'url', 'page_views_count', 'likes_count', 'created_at', 'updated_at', 'update_day', 'truncate_at', 'post_counts']]
df5 = df5.rename(columns = {'tag_5':'tag_1'})
tag_df = pd.concat([df1,df2,df3,df4,df5])
# tag_1 カラムの空白行を削除し、集計
tag_df = tag_df.dropna(subset=['tag_1'])
tag_df = tag_df.groupby(['tag_1','truncate_at'],as_index=False).sum()
# # タグの閲覧ランキング用のs3にcsvを格納する
g_output_file = 'tag_qiita.csv'
g_output_path = '/tmp/{}'.format(g_output_file)
tag_df.to_csv(g_output_path, index=False, encoding='utf-8_sig', quoting=csv.QUOTE_ALL)
bucket.upload_file(g_output_path, 'tag/' + '{}'.format(g_output_file))
print(os.listdir('/tmp/'))
for i in os.listdir('/tmp/'):
os.remove('/tmp/'+i)
print(os.listdir('/tmp/'))
###############################################
#########SPICE更新作業##################
for l,n in dsid_list.items():
print('更新テーブル:' + l)
response = qs.create_ingestion(
DataSetId=n,
IngestionId= today3 + l,
AwsAccountId= accountid
)
print(response)
④Lambda関数のテスト実行を行う。
項目名:コードソースの「Test」ボタンを押下することでLambda関数が実行される。

⑤テスト後各S3のオブジェクトにデータが生成されていることを確認する。
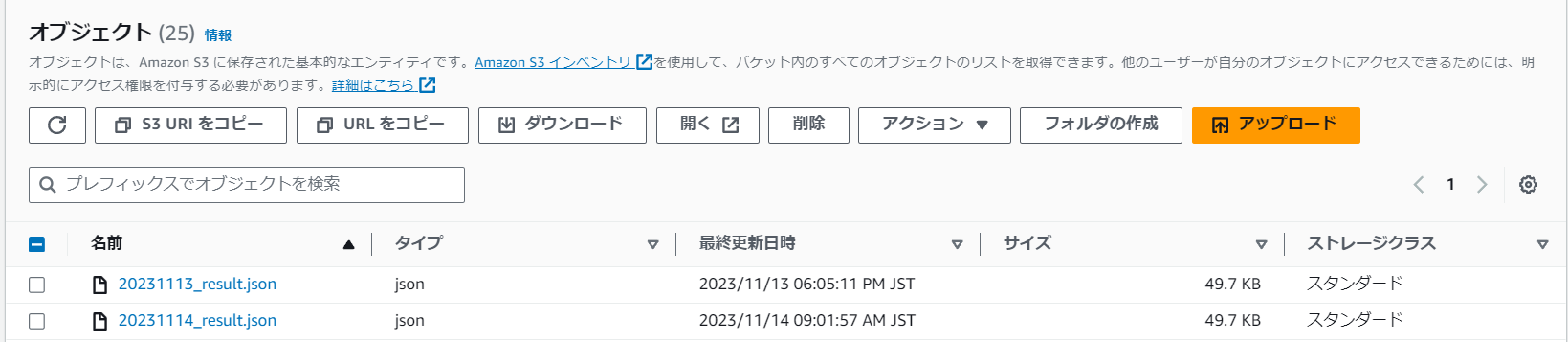
【result】
以下の通り、日付ごとにデータが格納されている。
※画像は一日おきに実行されたもの
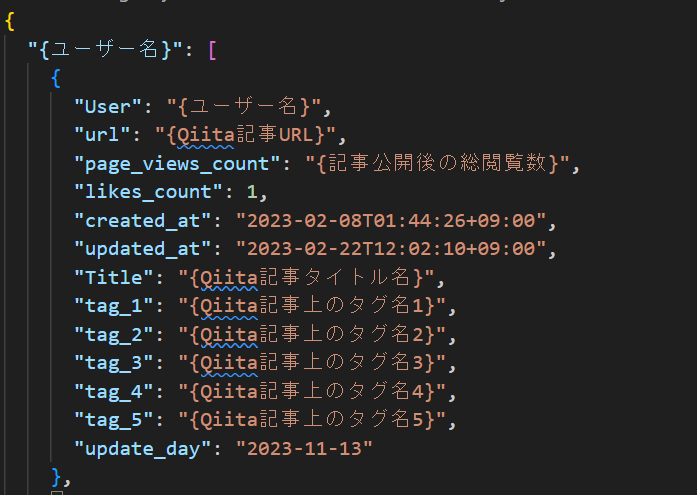
jsonの内容に関しては以下の通り辞書型で作成されます。
※一部抜粋しています。
【tag】
tagオブジェクト内にCSVファイルが作成されているか確認
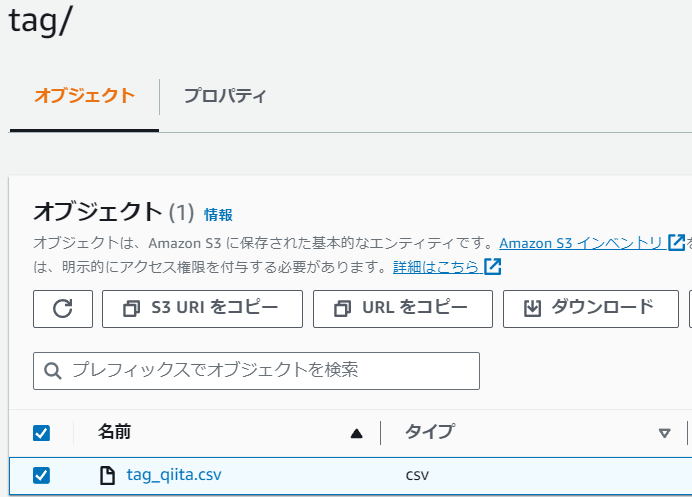
CSVファイルの中身は以下の構成で記事ごとに記載される。

【title】
titleオブジェクト内にCSVファイルが作成されているか確認
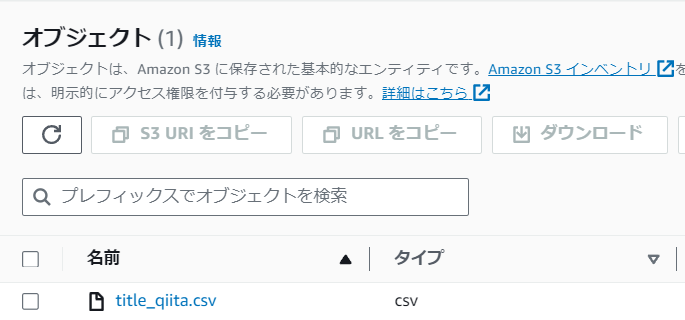
CSVファイルの中身は以下の構成で記事ごとに記載される。
※項目が長いので分割して画像を添付する。


【daily】
dailyオブジェクト内にCSVファイルが作成されているか確認
※画像は一日おきに実行されたもの
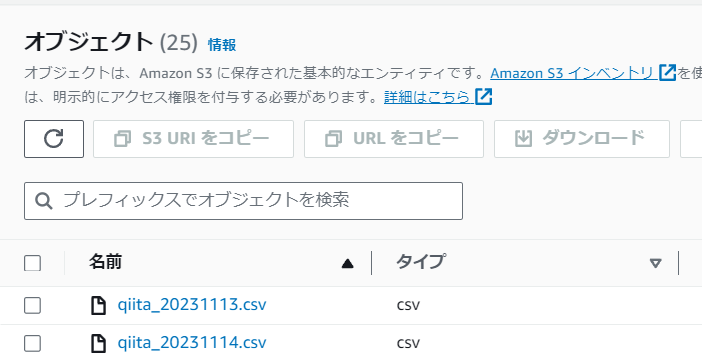
CSVファイルの中身は以下の構成で記事ごとに記載される。
※項目が長いので分割して画像を添付する


⑥EventBridgeの設定を行い、毎日午前9時にLambda関数が実行されるようにする。
「トリガーを追加」を押下する。
トリガー設定画面が表示されるため、下記画像の通りに設定し、「追加」を押下する。
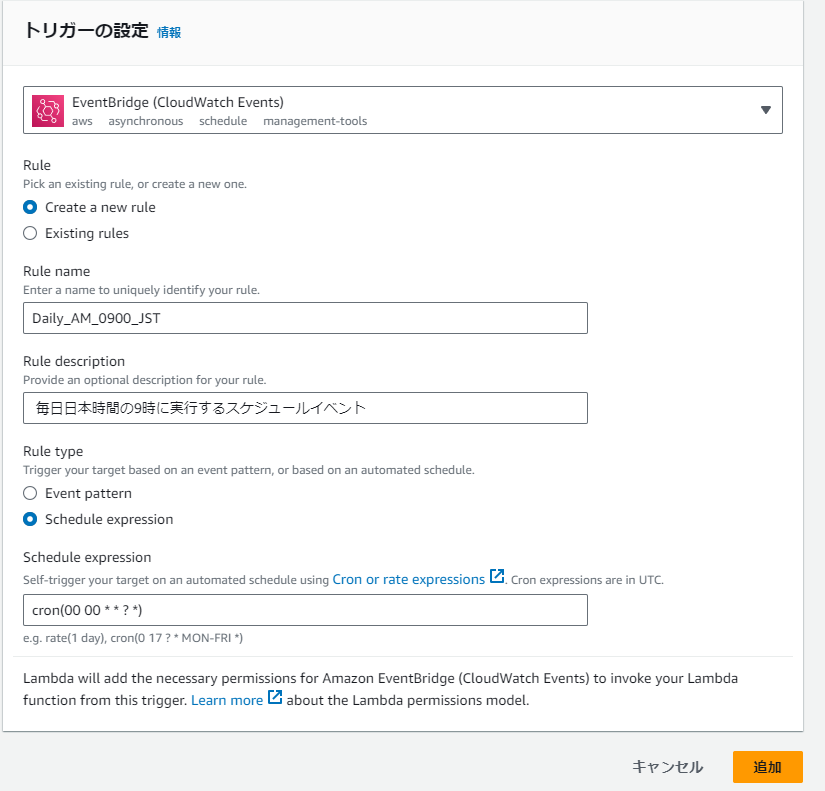
トリガーの設定完了
【まとめ】
今回はAWS Lamdaを用いたQiita記事の投稿状況の集計例についてご紹介いたしました。
後編では、集計データを用いたQuickSightによる投稿状況の可視化例をご紹介します。
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/?utm_source=qiita&utm_medium=referral&utm_campaign=qiita_zeuscloud_content-area