はじめに
データの分散管理が増加する中、AWS S3の柔軟なストレージとDatabricksの分析プラットフォーム、さらにdbt(data build tool)を組み合わせることで、スケーラブルで管理しやすいデータパイプラインを構築できます。
本記事では、以下の内容を段階的に解説します:
- AWS S3をDatabricks Unity Catalogに接続する方法
- 接続したデータをDatabricksとdbtで処理する方法
- Databricksジョブを使ってデータパイプラインを自動化する方法
Part 1: AWS S3をUnity Catalogに接続する
Unity Catalogを利用して、AWS S3をDatabricksと連携します。この手順では、IAMロールの設定やS3バケットの準備を行います。
必要な準備
-
DatabricksアカウントIDの確認:
Databricksアカウントコンソール(アカウントを管理)から取得
-
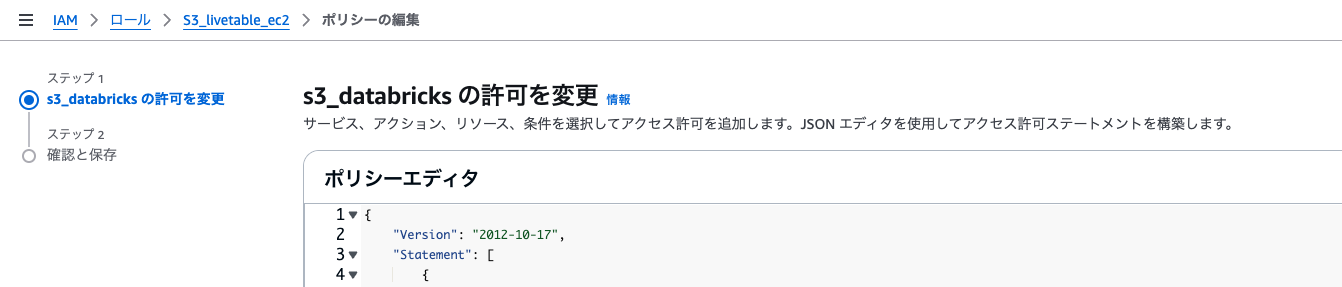
AWS IAMロールの作成と設定:
DatabricksがS3にアクセスできるようにIAMロールを作成し、IAMポリシーとの信頼ポリシーを設定します。 -
IAMポリシーを設定:
必要なS3アクセス権をIAMロールに付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetLifecycleConfiguration",
"s3:PutLifecycleConfiguration"
],
"Resource": [
"arn:aws:s3:::<作成したS3バケット>/*",
"arn:aws:s3:::<作成したS3バケット>"
],
"Effect": "Allow"
},
{
"Action": [
"sts:AssumeRole"
],
"Resource": [
"arn:aws:iam::<AWSアカウントID>:role/<作成したIAMロール>"
],
"Effect": "Allow"
}
]
}
信頼ポリシーの編集
- 作成したIAMロールを検索してクリックします。
- 「信頼関係」タブを開き、「信頼ポリシーを編集」をクリックします。
- 以下のポリシーを貼り付けます。

{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL",
"arn:aws:iam::<AWSアカウントID>:role/<作成したIAMロール>"
]
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<DatabricksアカウントID>"
}
}
}
]
}
Databricksでの設定
-
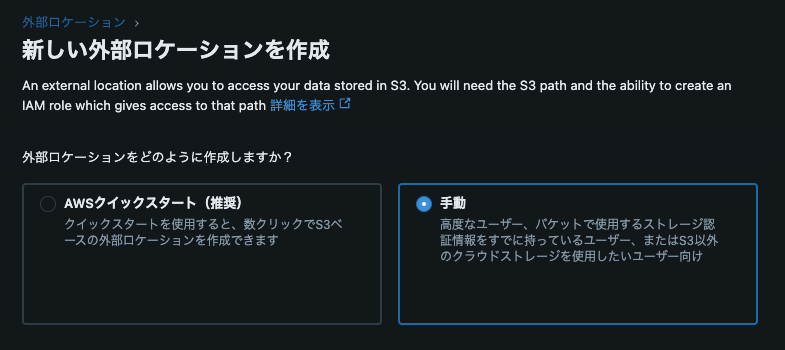
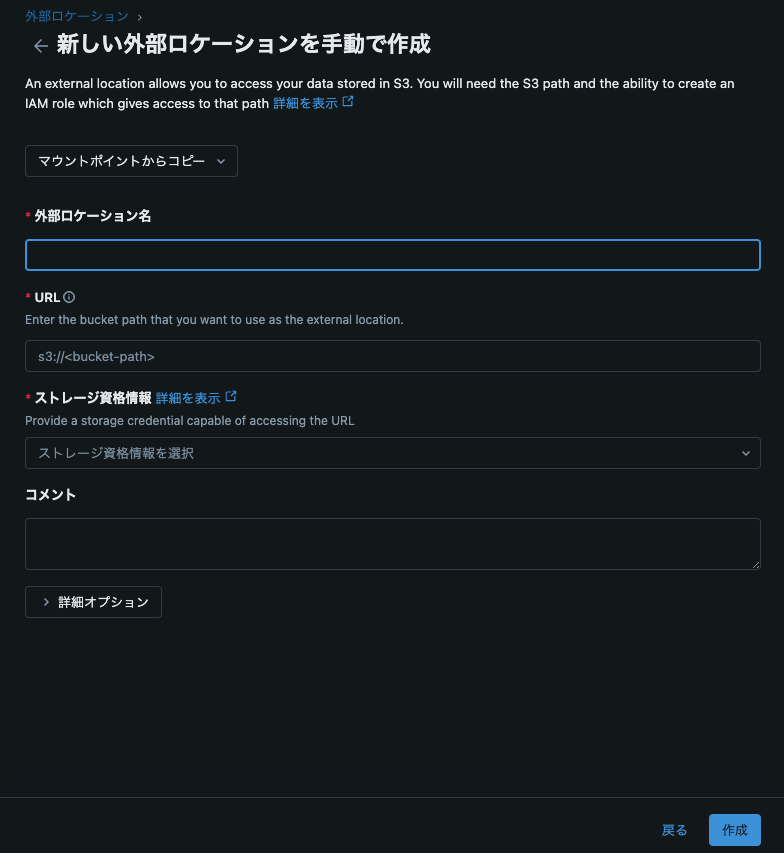
Databricksの「外部ロケーションを追加」画面で、S3バケットとIAMロールのARNを指定します。
-
設定を保存し、Unity Catalogの外部ストレージとしてS3を登録します。
↓
3.ノートブックを使った外部ロケーションからのテーブル取り込み
ノートブックから以下のコードを貼り付けます。ワークスペースとスキーマを定義して、S3の外部ロケーションからCSVを読み込み、テーブルに書き込みます。
df = spark.read.csv("/Volumes/workspace_aws/default/test_s3_csv/customers/raw_customers.csv", header=True)
df.write.mode("overwrite").saveAsTable("default.raw_customers")
df = spark.read.csv("/Volumes/workspace_aws/default/test_s3_csv/orders/raw_orders.csv", header=True)
df.write.mode("overwrite").saveAsTable("default.raw_orders")
df = spark.read.csv("/Volumes/workspace_aws/default/test_s3_csv/payments/raw_payments.csv", header=True)
df.write.mode("overwrite").saveAsTable("default.raw_payments")
Part 2: データパイプラインの構築(Databricks + dbt)
次に、S3からのデータを活用し、Databricksとdbtを使ってデータトランスフォーメーションを行います。
dbtモデルの開発をスキップしたい場合は以下のリポジトリを利用することでdbt on databricksを簡単にテストすることもできます。
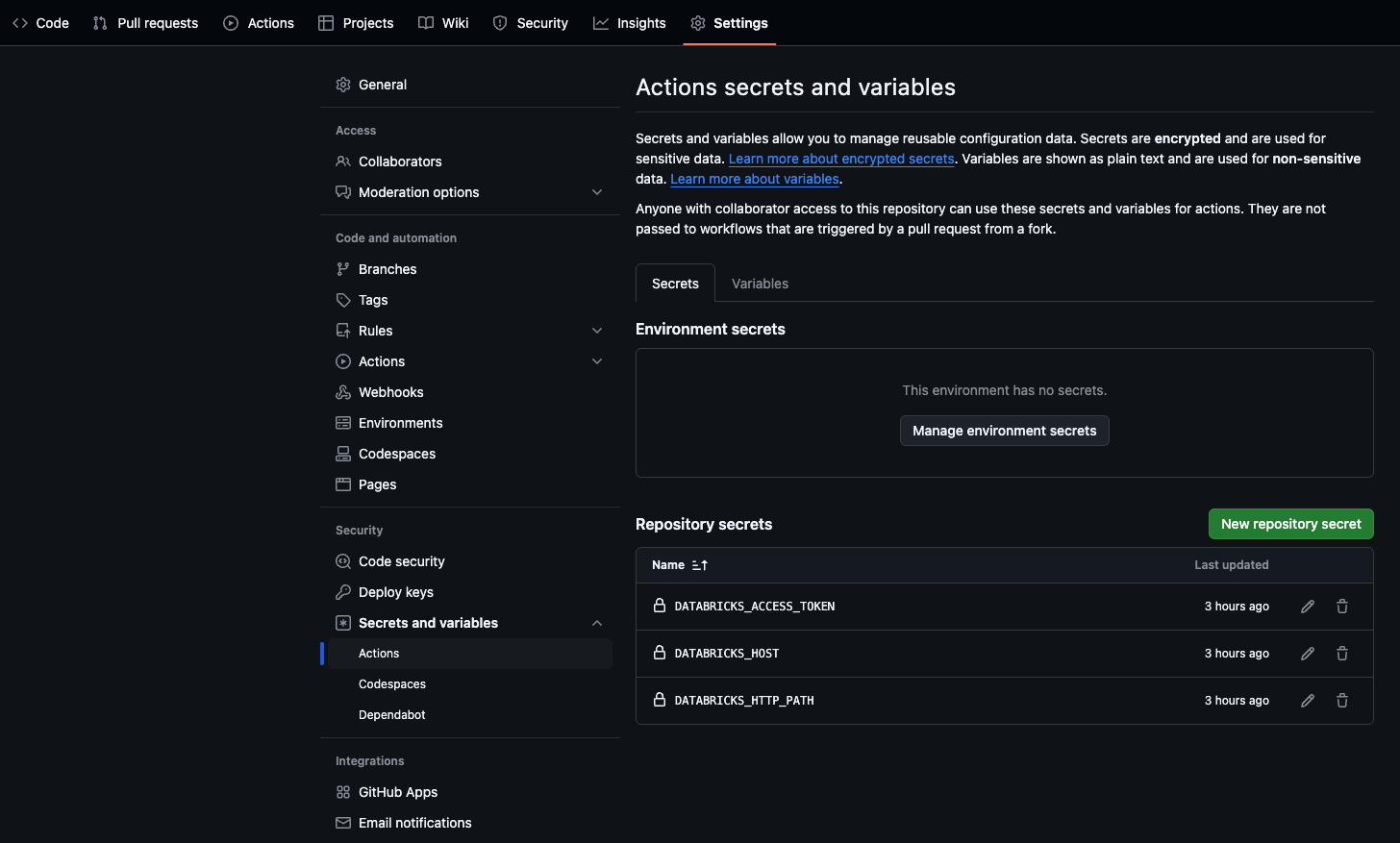
デモ用のGithubリポジトリ:https://github.com/olyalukashina/jaffle_shop.git
使用の注意点として、dbt seedから初期ファイルが読み取られるようになっているため、profiles.ymlの追加と環境変数の追加を行う必要性があります。
・profiles.yml
jaffle_shop:
target: dev
outputs:
dev:
type: databricks
schema: default
host: "{{ env_var('DATABRICKS_HOST') }}"
http_path: "{{ env_var('DATABRICKS_HTTP_PATH') }}"
token: "{{ env_var('DATABRICKS_ACCESS_TOKEN') }}"
・models/staging/stg_customers.sql
with source as (
{#-
Normally we would select from the table here, but we are using seeds to load
our data in this project
#}
select * from default.raw_customers
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamed
dbtプロジェクトの設定
-
dbt-databricksのインストール
Databricksに適したパッケージをインストールします:
pip install dbt-databricks -
dbtプロジェクトの初期化
既存の
jaffle_shopプロジェクトをDatabricksに適応:dbt init my_project cd my_project -
profiles.ymlの設定
S3から読み込んだデータをDatabricksで処理するよう、
profiles.ymlを以下のように設定します。my_databricks_project: target: dev outputs: dev: type: databricks host: <databricks-instance> http_path: <sql-warehouse-path> schema: analytics token: <your-access-token> target: dev default: -
dbtモデルの作成
S3データに基づくモデルを作成します(例: 売上データの集計)。
-- models/sales_summary.sql SELECT order_date, SUM(total) AS daily_sales FROM {{ ref('raw_sales') }} GROUP BY order_date ORDER BY order_date; -
dbtプロジェクトをGithubに保存
作成したdbtプロジェクトをGithubにpushします。
Part 3: Databricksジョブで自動化
-
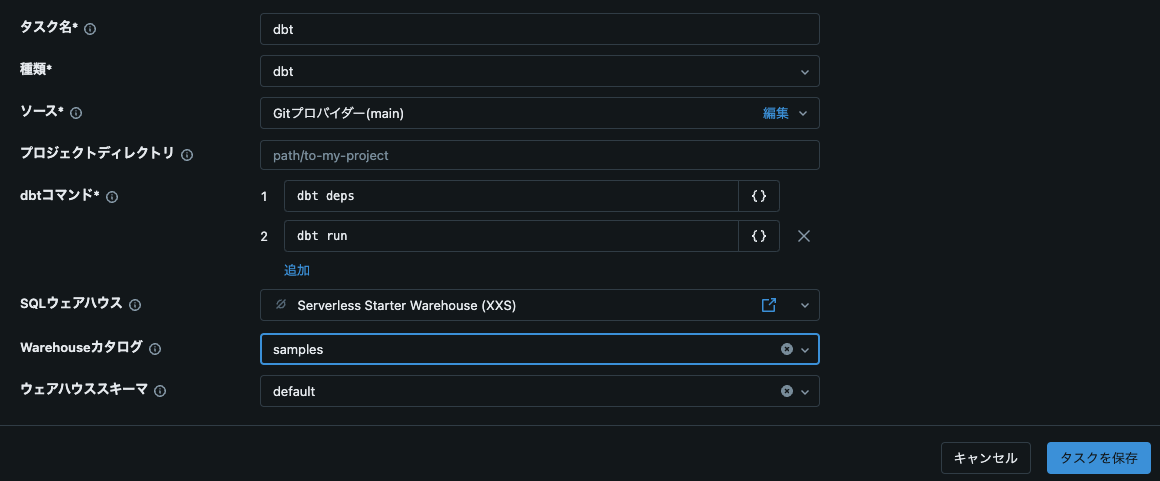
Databricksジョブの作成
-
Databricksの「ワークフロー」セクションで新しいジョブを作成して保存します。
-
dbtタスクを追加し、必要なdbtコマンドを設定:
dbt deps dbt run -
-
トリガーの設定
- スケジュールとトリガーのタブで、S3の到着をトリガーに設定します。
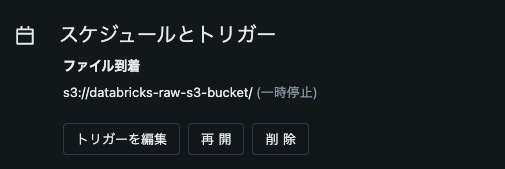
- スケジュールとトリガーのタブで、S3の到着をトリガーに設定します。
-
ノートブックをフローに追加
- これによりS3の外部ロケーションからdatabricksのテーブルへのロードも自動化されます。またこの処理が終わった後にdbtが走るようになります。
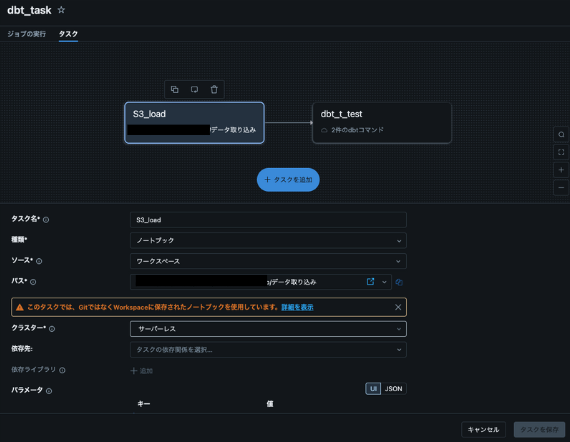
- これによりS3の外部ロケーションからdatabricksのテーブルへのロードも自動化されます。またこの処理が終わった後にdbtが走るようになります。
-
動作チェック
実際にS3にデータを入れてみてフローが動くか確認します。成功と表示され、すべてのdbtモデルがPASSされていれば成功となります。


またUnity Data Catalogか作られたテーブルのリネージを確認することもできます。
https://docs.databricks.com/ja/data-governance/unity-catalog/data-lineage.html
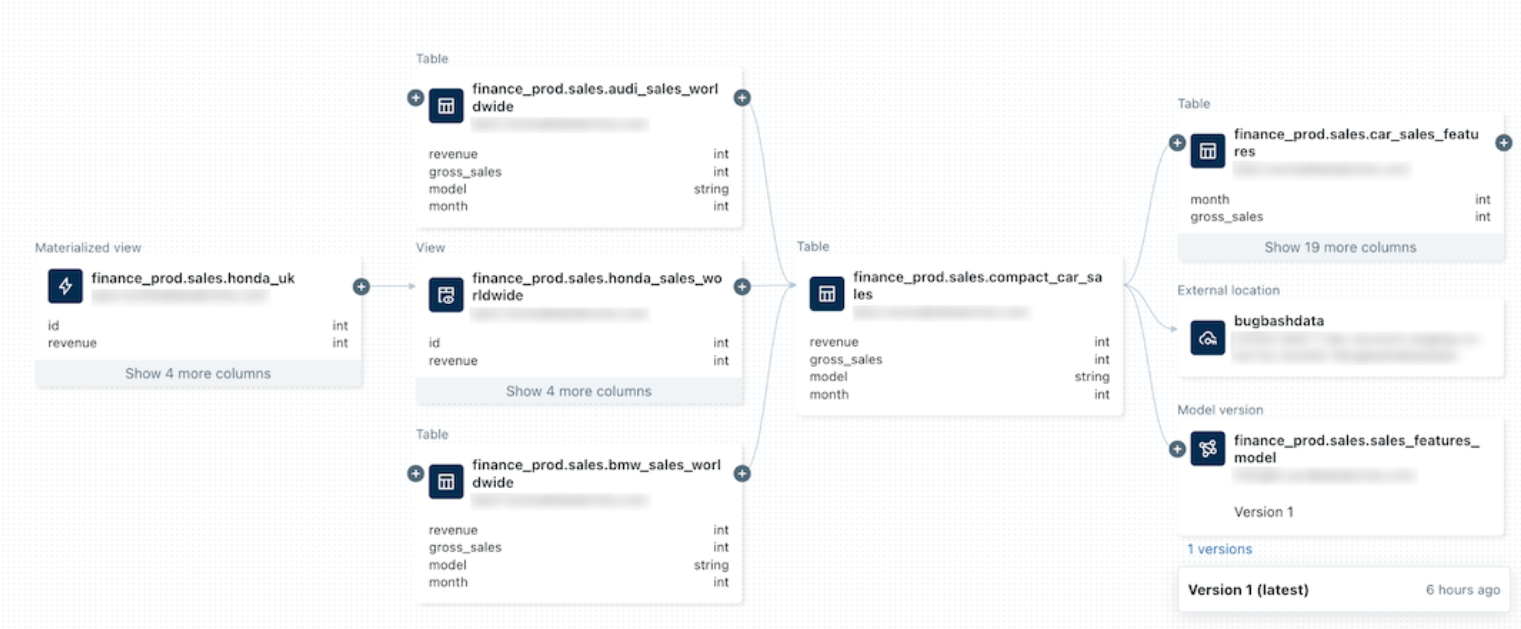
-
実行通知
さらに以下の設定を行うことでメールやSlackへの成功失敗通知を流すことも可能です。(例:Slackの設定)
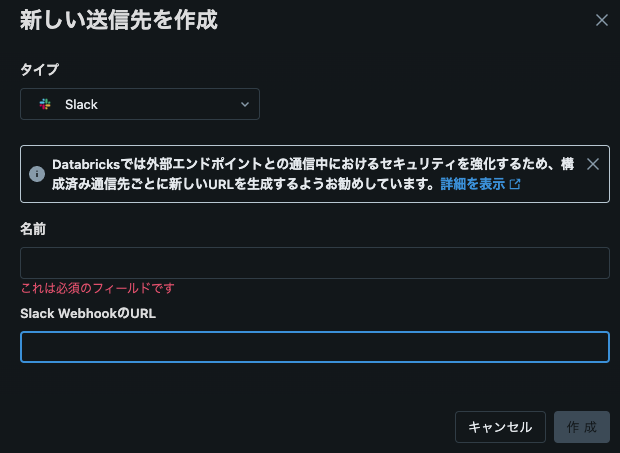
↓
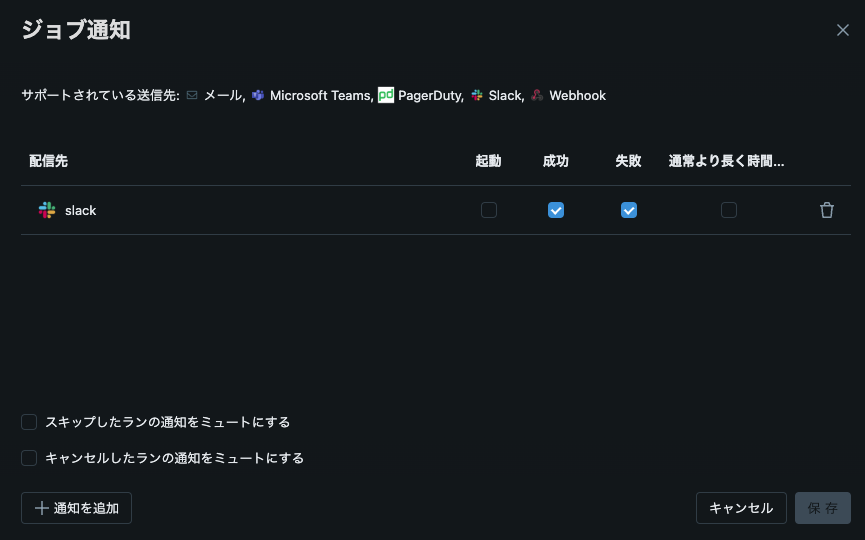
成功通知

結論
この記事では、AWS S3をDatabricksと統合し、dbtを使ったデータパイプラインの構築方法を解説しました。このアプローチを活用すれば、スケーラブルなデータ基盤を構築し、データガバナンスを強化できます。さらに、Databricksジョブを使用することで、定期実行やエラー通知の自動化が可能となり、運用効率が向上します。
Databricksとdbtの連携を活用して、エンタープライズ規模のデータ分析基盤を構築してみてください!