はじめに
dbtプロジェクトでは、データモデルの変更に伴ってER図も更新する必要があります。しかし、手動でER図を更新するのは手間がかかり、更新漏れが発生しやすいという課題があります。また、プロジェクトが大規模化すると、すべてのモデルを1つのER図にまとめると複雑になりすぎて可読性が低下します。
また
本記事では、GitHub ActionsとOpenAI GPT APIを活用して、dbtモデルの変更時に自動的にER図を生成し、さらにモデルグループごとに分割して管理する仕組みを実装した事例を紹介します。
背景と課題
従来の運用の課題
- dbtモデルを変更するたびに手動でER図を更新する必要がある
- ER図の更新漏れが発生しやすい
- データモデルとドキュメントの乖離が発生する
- レビュアーがスキーマ変更の全体像を把握しにくい
- 大規模プロジェクトでは1つのER図が複雑になりすぎる
- 依存関係のないモデルグループも混在して見づらい
解決したいこと
- mainブランチへのマージ時に自動的にER図を更新
- モデルグループごとにER図を分割して管理
- 人手を介さず常に最新のER図を保持
- レビュープロセスを通じて品質を担保
アーキテクチャ
┌─────────────────────────────────────────────────────┐
│ Developer │
│ └─ dbtモデル (*.sql, *.yml) を変更してmainにマージ │
└─────────────────┬───────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ GitHub Actions │
│ ├─ モデルグループを自動検出 │
│ ├─ グループごとにスキーマ情報を収集 │
│ ├─ OpenAI GPT-4で各グループのER図を生成 │
│ └─ ER/ディレクトリに分割保存してPRを作成 │
└─────────────────┬───────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ Pull Request │
│ └─ レビュー後、マージして最新のER図を反映 │
└─────────────────────────────────────────────────────┘
実装内容
1. GitHub Actionsワークフロー
.github/workflows/update-erd.yml
name: Update ERD
on:
push:
branches:
- main
paths:
- 'models/**/*.sql'
- 'models/**/*.yml'
workflow_dispatch:
jobs:
update-erd:
runs-on: ubuntu-latest
permissions:
contents: write
pull-requests: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: |
pip install openai PyYAML
- name: Generate ERD
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
python scripts/generate_erd.py
- name: Check for changes
id: check_changes
run: |
git add ER/
if git diff --cached --quiet; then
echo "changed=false" >> $GITHUB_OUTPUT
else
echo "changed=true" >> $GITHUB_OUTPUT
fi
- name: Create Pull Request
if: steps.check_changes.outputs.changed == 'true'
uses: peter-evans/create-pull-request@v6
with:
token: ${{ secrets.GITHUB_TOKEN }}
commit-message: "Update ER diagrams with latest schema changes"
branch: update-erd-${{ github.run_number }}
delete-branch: true
title: "Update ER Diagrams"
body: |
This PR automatically updates ER diagrams based on the latest dbt schema changes.
Generated by GitHub Actions.
labels: |
automated
documentation
ワークフローの特徴
-
トリガー条件:
models/ディレクトリ内の.sqlまたは.ymlファイルが変更された時に実行 -
手動実行:
workflow_dispatchにより、GitHub UIから手動実行も可能 -
変更検知:
git addとgit diff --cachedで新規ファイルを含む変更を検出 - 自動ブランチ削除: マージ後は自動的にブランチを削除
2. ER図生成スクリプト
scripts/generate_erd.py
#!/usr/bin/env python3
"""
ER図を自動生成するスクリプト
"""
import os
import yaml
import glob
from pathlib import Path
from openai import OpenAI
def get_model_groups(models_dir="models"):
"""modelsディレクトリからモデルグループを抽出"""
groups = {} # group_name -> group_path
# models配下のディレクトリ構造を取得
for path in Path(models_dir).rglob("*.sql"):
parts = path.parts
if len(parts) >= 3:
# models/group/ または models/group/subgroup/ を抽出
if len(parts) >= 4:
group_name = f"{parts[1]}_{parts[2]}"
group_path = f"{parts[1]}/{parts[2]}"
else:
group_name = parts[1]
group_path = parts[1]
groups[group_name] = group_path
return dict(sorted(groups.items()))
def find_files_in_group(group_path, models_dir="models"):
"""特定のグループに属するファイルを探す"""
yaml_files = []
sql_files = []
# 完全なパスを構築
full_path = f"{models_dir}/{group_path}"
# YAMLファイルを探す
for yaml_file in glob.glob(f"{full_path}/**/*.yml", recursive=True):
yaml_files.append(yaml_file)
# SQLファイルを探す
for sql_file in glob.glob(f"{full_path}/**/*.sql", recursive=True):
sql_files.append(sql_file)
return yaml_files, sql_files
def read_yaml_content(yaml_file):
"""YAMLファイルの内容を読み取る"""
try:
with open(yaml_file, 'r', encoding='utf-8') as f:
return yaml.safe_load(f)
except Exception as e:
print(f"Error reading {yaml_file}: {e}")
return None
def read_sql_content(sql_file):
"""SQLファイルの内容を読み取る"""
try:
with open(sql_file, 'r', encoding='utf-8') as f:
return f.read()
except Exception as e:
print(f"Error reading {sql_file}: {e}")
return None
def collect_group_schema_info(group_path):
"""特定グループのスキーマ情報を収集"""
schema_info = {
"yaml_files": {},
"sql_files": {}
}
yaml_files, sql_files = find_files_in_group(group_path)
# YAMLファイルの収集
for yaml_file in yaml_files:
content = read_yaml_content(yaml_file)
if content:
schema_info["yaml_files"][yaml_file] = content
# SQLファイルの収集
for sql_file in sql_files:
content = read_sql_content(sql_file)
if content:
schema_info["sql_files"][sql_file] = content
return schema_info
def generate_erd_with_gpt(schema_info, group_name):
"""GPT APIを使ってER図を生成"""
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# プロンプトを構築
prompt = f"""あなたはデータベースエンジニアです。以下のdbtプロジェクトの「{group_name}」グループのスキーマ情報を分析し、Mermaid形式のER図を生成してください。
要件:
1. このグループに関連するすべてのソーステーブルとモデルを含めてください
2. テーブル間のリレーションシップ(JOINやref)を正確に表現してください
3. 各テーブルの主要なカラムを含めてください
4. Mermaid erDiagram形式で出力してください
5. リレーションシップの説明も含めてください
dbtプロジェクト情報:
"""
# YAMLファイルの情報を追加
prompt += "\n## YAML Schema Files:\n"
for yaml_file, content in schema_info["yaml_files"].items():
prompt += f"\n### {yaml_file}\n"
prompt += yaml.dump(content, allow_unicode=True)
prompt += "\n"
# SQLファイルの情報を追加
prompt += "\n## SQL Model Files:\n"
for sql_file, content in schema_info["sql_files"].items():
prompt += f"\n### {sql_file}\n"
prompt += content
prompt += "\n"
prompt += "\n上記の情報に基づいて、包括的なER図をMermaid形式で生成してください。"
# GPT APIを呼び出し
try:
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "あなたはデータベース設計の専門家です。dbtプロジェクトのスキーマ情報から正確なER図を生成します。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=4000
)
return response.choices[0].message.content
except Exception as e:
print(f"Error calling GPT API: {e}")
return None
def extract_mermaid_diagram(gpt_response):
"""GPTレスポンスからMermaidダイアグラムを抽出"""
if not gpt_response:
return None
# ```mermaid と ``` の間のコンテンツを抽出
lines = gpt_response.split('\n')
in_mermaid = False
mermaid_lines = []
for line in lines:
if '```mermaid' in line:
in_mermaid = True
continue
elif '```' in line and in_mermaid:
break
elif in_mermaid:
mermaid_lines.append(line)
return '\n'.join(mermaid_lines)
def update_erd_file(group_name, mermaid_diagram, er_dir="ER"):
"""グループごとのERD.mdファイルを更新"""
# ERディレクトリを作成
os.makedirs(er_dir, exist_ok=True)
# ファイル名を生成
file_name = f"{er_dir}/{group_name}_ERD.md"
# タイトルを整形
title = group_name.replace('_', ' ').title()
# ER図の内容をマークダウンファイルとして出力
erd_content = f"# {title} ER Diagram\n\n"
erd_content += "```mermaid\n"
erd_content += mermaid_diagram
erd_content += "\n```\n\n"
erd_content += "## 概要\n\n"
erd_content += f"このER図は、dbtプロジェクトの`{group_name}`グループに属するモデルとソーステーブルの関係を表現しています。\n\n"
erd_content += "## 更新日時\n\n"
erd_content += f"最終更新: {os.popen('date').read().strip()}\n"
try:
with open(file_name, "w", encoding="utf-8") as f:
f.write(erd_content)
print(f"{file_name} has been updated successfully.")
return True
except Exception as e:
print(f"Error updating {file_name}: {e}")
return False
def create_index_file(groups, er_dir="ER"):
"""ERディレクトリのインデックスファイルを作成"""
index_content = "# ER Diagram Index\n\n"
index_content += "このディレクトリには、dbtプロジェクトの各モデルグループごとのER図が格納されています。\n\n"
index_content += "## モデルグループ一覧\n\n"
for group in groups:
title = group.replace('_', ' ').title()
index_content += f"- [{title}](./{group}_ERD.md)\n"
index_content += "\n## 更新について\n\n"
index_content += "これらのER図は、mainブランチへのマージ時にGitHub Actionsによって自動的に更新されます。\n"
try:
with open(f"{er_dir}/README.md", "w", encoding="utf-8") as f:
f.write(index_content)
print(f"{er_dir}/README.md has been created successfully.")
return True
except Exception as e:
print(f"Error creating index file: {e}")
return False
def main():
"""メイン処理"""
print("Detecting model groups...")
groups = get_model_groups() # {group_name: group_path}
if not groups:
print("No model groups found.")
return 1
print(f"Found {len(groups)} model group(s): {', '.join(groups.keys())}")
success_count = 0
for group_name, group_path in groups.items():
print(f"\n--- Processing group: {group_name} ---")
print(f"Collecting schema information for {group_name}...")
schema_info = collect_group_schema_info(group_path)
yaml_count = len(schema_info['yaml_files'])
sql_count = len(schema_info['sql_files'])
print(f"Found {yaml_count} YAML files and {sql_count} SQL files")
if yaml_count == 0 and sql_count == 0:
print(f"No files found for group {group_name}, skipping...")
continue
print(f"Generating ERD for {group_name} with GPT...")
gpt_response = generate_erd_with_gpt(schema_info, group_name)
if not gpt_response:
print(f"Failed to generate ERD for {group_name}")
continue
print("Extracting Mermaid diagram...")
mermaid_diagram = extract_mermaid_diagram(gpt_response)
if not mermaid_diagram:
print(f"Failed to extract Mermaid diagram for {group_name}")
continue
print(f"Updating ERD file for {group_name}...")
if update_erd_file(group_name, mermaid_diagram):
success_count += 1
# インデックスファイルを作成
print("\nCreating index file...")
create_index_file(list(groups.keys()))
print(f"\nERD generation completed! ({success_count}/{len(groups)} groups processed)")
return 0 if success_count == len(groups) else 1
if __name__ == "__main__":
exit(main())
スクリプトの特徴
-
自動グループ検出:
models/ディレクトリ構造からモデルグループを自動検出 - グループごとの処理: 各グループ独立してスキーマ情報を収集しER図を生成
-
分割管理: ER図を
ER/{グループ名}_ERD.mdとして個別ファイルに保存 -
インデックス生成:
ER/README.mdに全グループへのリンクを自動生成 - Mermaid形式: GitHubでそのまま表示可能なMermaid形式で出力
- エラーハンドリング: ファイル読み込みやAPI呼び出しの失敗を適切に処理
モデルグループの分割基準について
スクリプトはmodels/ディレクトリの構造に基づいて、自動的にモデルグループを検出します。
グループ検出のルール
パターン1: 2階層構造
models/
└── marketing/ ← グループ名: "marketing"
├── staging/
└── marts/
└── campaign_summary.sql
この場合、models/直下のディレクトリ名がそのままグループ名になります。
パターン2: 3階層構造
models/
└── analytics/ ← 第2階層(ビジネスドメイン)
└── web/ ← 第3階層(データソース)
├── staging/
├── intermediate/
└── marts/
└── user_sessions.sql
この場合、第2階層_第3階層の形式でグループ名が生成されます(例:analytics_web)。
dbtのベストプラクティスとの整合性
dbtの一般的なディレクトリ構造では:
- 第2階層: ビジネスドメインやサービス領域(例:finance, marketing, operations)
- 第3階層: 具体的なデータソースやサブドメイン(例:salesforce, google_analytics, erp)
- 第4階層以降: dbtのレイヤー(staging, intermediate, marts)
この構造に従うことで、関連するデータソースやビジネスドメインごとに自動的にER図が分割され、チームごとの並行開発や部分的な更新が容易になります。
ファイル構成
この仕組みを導入すると、以下のようなディレクトリ構成になります:
.
├── .github/
│ └── workflows/
│ └── update-erd.yml
├── scripts/
│ └── generate_erd.py
├── models/
│ ├── analytics/
│ │ └── web/
│ │ ├── staging/
│ │ ├── intermediate/
│ │ └── marts/
│ ├── finance/
│ │ └── accounting/
│ │ └── ...
│ └── (他のモデルグループ)
├── ER/
│ ├── README.md # インデックスファイル
│ ├── analytics_web_ERD.md # グループごとのER図
│ ├── finance_accounting_ERD.md
│ └── (他のグループのER図)
└── .gitignore
セットアップ手順
1. OpenAI APIキーの取得
- OpenAI Platformにアクセス
- アカウントにログイン
-
API Keysセクションに移動 -
Create new secret keyをクリック - 生成されたキーをコピー(一度しか表示されません)
2. GitHub Secretsの設定
- GitHubリポジトリの
Settingsタブをクリック - 左サイドバーの
Secrets and variables>Actionsをクリック -
New repository secretボタンをクリック - 以下を入力:
-
Name:
OPENAI_API_KEY - Secret: 取得したOpenAI APIキー
-
Name:
-
Add secretをクリック
3. ファイルの配置
リポジトリに以下のファイルを配置します:
.github/workflows/update-erd.ymlscripts/generate_erd.py
4. 実行
ワークフローは以下のいずれかで実行されます:
-
models/ディレクトリ内のファイルをmainブランチにマージ - GitHub ActionsのUIから手動実行
動作確認
実際にワークフローを実行すると、以下のような流れで動作します:
1. トリガー
mainブランチへのマージ
↓
GitHub Actionsが起動
2. モデルグループの検出
Detecting model groups...
Found 2 model group(s): analytics_web, finance_accounting
3. グループごとのER図生成
--- Processing group: analytics_web ---
Collecting schema information for analytics_web...
Found 1 YAML files and 3 SQL files
Generating ERD for analytics_web with GPT...
Extracting Mermaid diagram...
Updating ERD file for analytics_web...
ER/analytics_web_ERD.md has been updated successfully.
--- Processing group: finance_accounting ---
Collecting schema information for finance_accounting...
Found 2 YAML files and 5 SQL files
Generating ERD for finance_accounting with GPT...
Extracting Mermaid diagram...
Updating ERD file for finance_accounting...
ER/finance_accounting_ERD.md has been updated successfully.
4. インデックスファイル作成
Creating index file...
ER/README.md has been created successfully.
5. プルリクエストの作成
変更がある場合、自動的にプルリクエストが作成されます:
- ブランチ名:
update-erd-{run_number} - タイトル: "Update ER Diagrams"
- ラベル:
automated,documentation
6. 実際に生成されたER図とプルリクエスト例
以下は、スタースキーマ構造を持つデータウェアハウスのサンプルプロジェクトで、実際にこのワークフローによって生成されたER図の例です。スクリプトによってER図が生成されていることが確認できました。
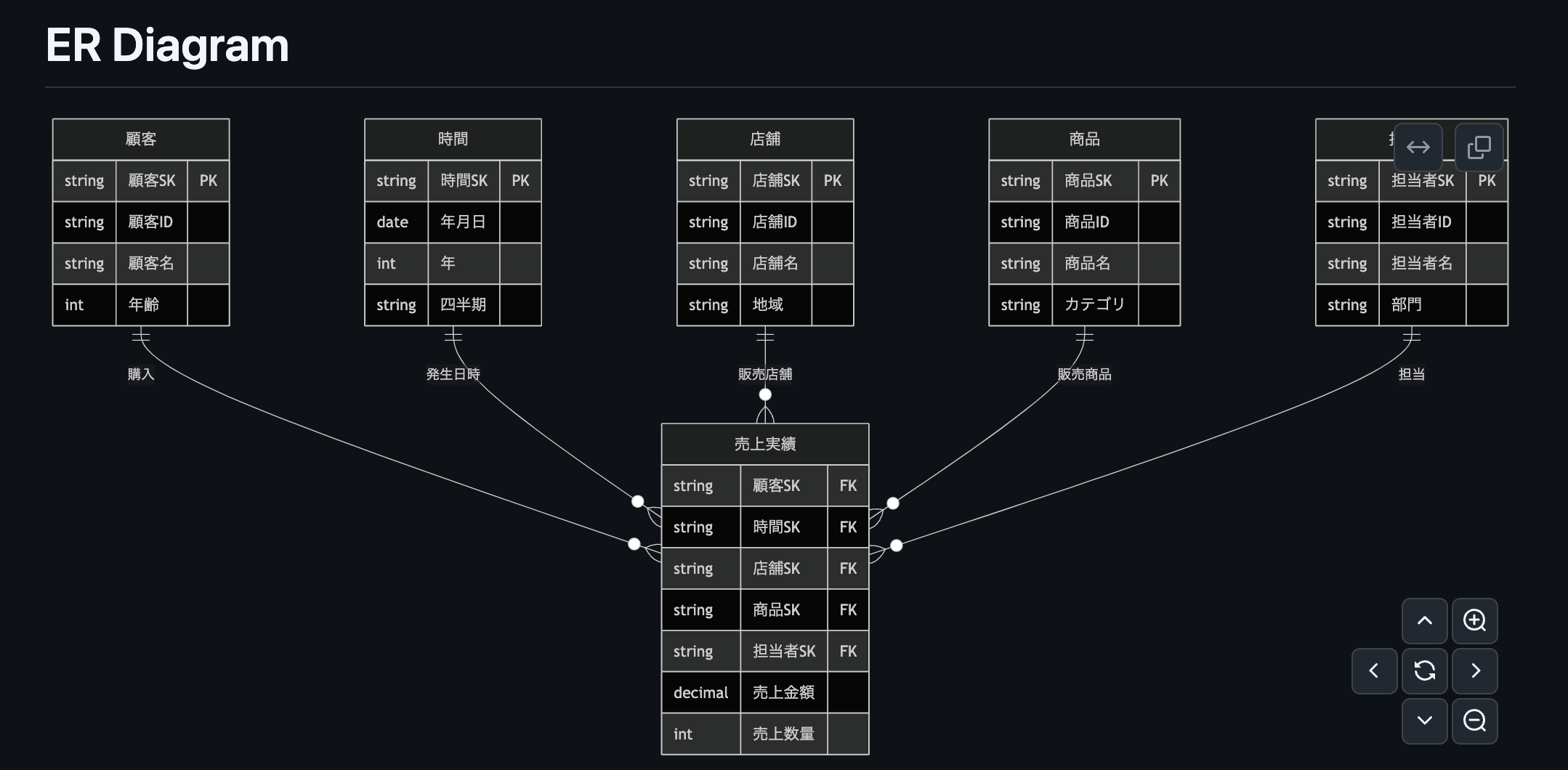
また以下のように自動てプルリクエストまで作成が行わなれました。
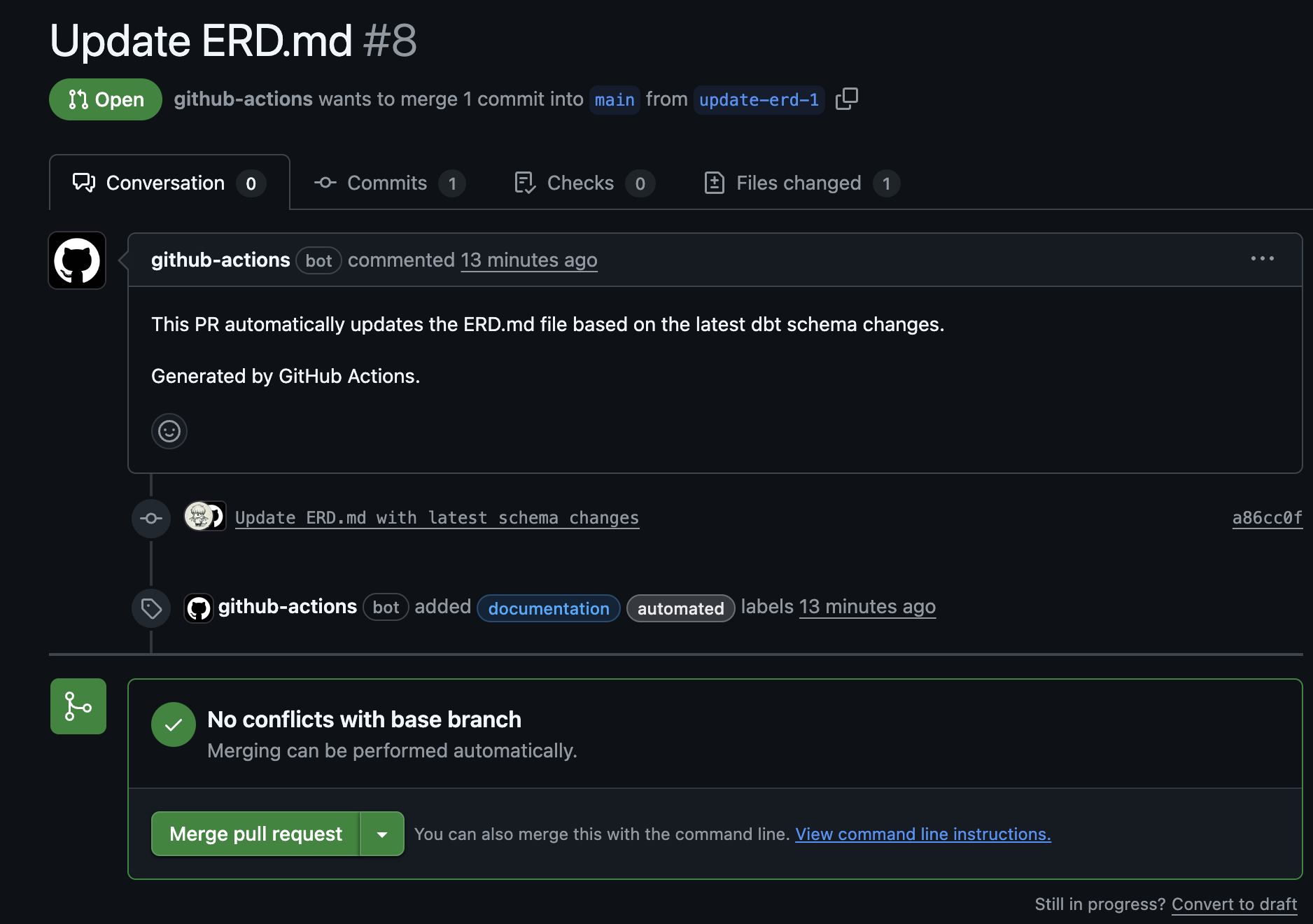
終わりに
dbtプロジェクトにおけるドキュメント管理は、プロジェクトの成長とともに複雑化していきます。本記事で紹介した自動化の仕組みは、LLMの強力な理解力とGitHub Actionsの柔軟性を組み合わせることで、ドキュメント管理の負担を軽減し、常に最新の状態を保つことを可能にします。特にグループごとの分割管理により、大規模なプロジェクトでもスケーラビリティを維持できます。この手法は他のドキュメント生成タスクにも応用できるため、ぜひ自身のプロジェクトに合わせてカスタマイズしてみてください。