Text Extractionとは
watsonx.aiには画像ファイルからテキストを抽出するAI-OCRサービスがあります。
この記事では、watsonx.ai Text ExtractionのPythonライブラリを使用して、画像上のテキストの読み取り、位置検出を行う手順を紹介します。
さらに、テキスト検出結果を可視化する方法として、画像上にバウンディングボックスを描画する方法も紹介します。
テキスト抽出のフロー
- IBM Cloud Object Storageに画像をアップロードする
- Text Extractionへのリクエストを作成する
- Text Extractionのステータスを見て、テキスト抽出に成功したことを確認する
- テキスト抽出結果をIBM Cloud Object Storageから取得する

注意
この画像はREST APIを使用した際のフローですが、Pythonライブラリを使用する場合もほとんど同様の処理となります。
IBM Cloud Object Storageの設定
IBM Cloud Object Storageのバケット作成
- IBM Cloudのリソース・リストから、ストレージを展開し、IBM Cloud Object Storageサービス・インスタンスをクリックして開く
- バケットの作成をクリックする

-
すぐに始める方法でバケットを作成する

- 固有のバケット名をつけて、バケットを資格情報とともに作成する

- ファイルのアップロード、バケットのテストはスキップし、バケットの作成を完了する

IBM Cloud Object Storageサービス・インスタンスへの接続情報の取得
watsonx.aiからIBM Cloud Object Storageのバケットに接続するため、HMACクレデンシャルをもつ鍵を作成する。
-
IBM Cloud Object Storageの対象のサービス・インスタンスのページで、サービス資格情報を開き、新規資格情報をクリック

-
適当な名前で資格情報を作成する
- ロール:管理者
- HMAC資格情報を含める:オン

-
access_key_idとsecret_access_keyの値を辞書から取得する

対象のバケットの構成を開き、エンドポイントから接続先のパブリックURLを取得する。

watsonx.aiの設定
プロジェクトの作成
- watsonxのページを開く
- プロジェクトの右側の+ボタンをクリックし、プロジェクトの新規作成ページを開く

- 適当な名前をつけて、プロジェクトを作成する

- プロジェクト → 管理 → 一般をクリックし、プロジェクトIDを取得する
※プロジェクト作成時にもバケットが作成されますが、今回はこのバケットは使用しません。

プロジェクトとIBM Cloud Object Storageの接続
- 作成したプロジェクトを開く
- アセットページを開き、新規資産をクリック

- データ・ソースへの接続をクリック

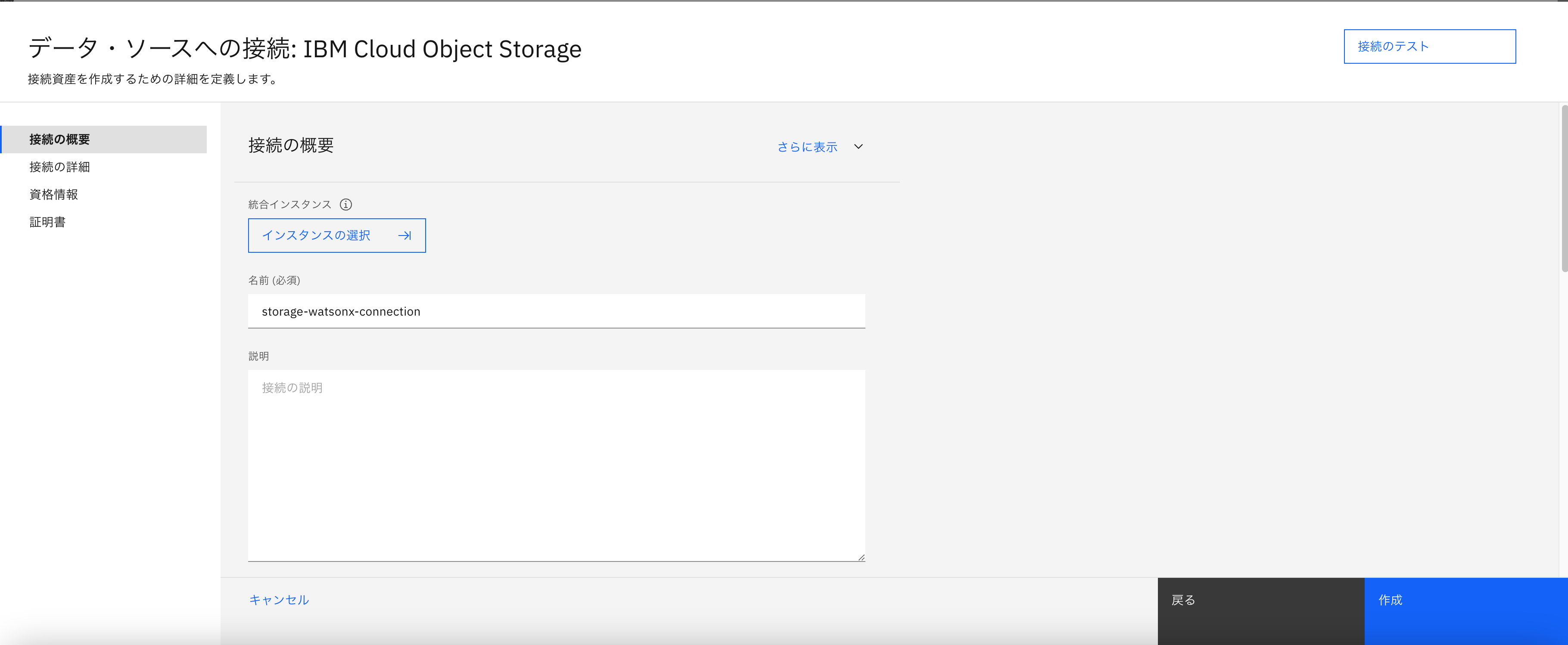
- IBM Cloud Object Storageを選択し、接続の追加を行う

- 接続の設定を行い、テストを確認した上でアセットを作成する
- 名前:適当
- バケット:上で作成したバケット名
- ログインURL:上で取得したURL
- 認証方法:アクセス・キーと秘密鍵
- アクセス・キー:
access_key_idの値 - 秘密鍵:
secret_access_keyの値
- アクセス・キー:
- 作成した接続を開き、そのページのURLから
connection_asset_idを取得する
(例.URLが"eu-gb.dataplatform.cloud.ibm.com/connections/<connection_asset_id>?project_id=<project_id>&context=wx"の場合、<connection_asset_id>の部分を取得する)

タスククレデンシャルの作成
以下のリンクの手順を参考に、タスククレデンシャルを作成します。
参考:タスク認証情報の管理
Python上でText Extractionサービスを使用する
環境のセットアップ
必要なパッケージをインストールする。
pip install "ibm-watsonx-ai>=1.1.15"
watsonx.aiに接続するためのクレデンシャルを設定する
watsonx.aiのAPIキーを作成する手順は以下のソースが参考になると思います。
※クレデンシャルに設定するURLはリージョンによって変わります。
from ibm_watsonx_ai import Credentials
credentials = Credentials(
url="https://eu-gb.ml.cloud.ibm.com",
api_key="<watsonx.ai_api_key>"
)
API Clientを初期化する
project_idには、watsonx.aiの設定時に取得したものをセットする。
from ibm_watsonx_ai import APIClient
project_id = "<project_id>"
client = APIClient(credentials=credentials, project_id=project_id)
IBM Cloud Object Storageへテキスト抽出対象ファイルをアップロードする
今回はテキスト抽出対象ファイルとして、この記事の冒頭にも載せたテキスト抽出フローの画像を使用する。

bucketnameには前の手順で設定した名前を定義する。(私の場合:"cloud-object-storage-for-text-extraction")
connection_asset_idには接続の作成時に取得した値を定義する。
from ibm_watsonx_ai.helpers import DataConnection, S3Location
# ローカル上のテキスト抽出対象ファイルの名前
local_source_file_name = "text_extraction_flow.png"
# COS上のテキスト抽出対象ファイルの名前
source_file_name = "./files/text_extraction_flow.png"
# COS上のテキスト抽出結果ファイルの名前(マークダウン形式で出力する場合は.mdにする)
results_file_name = "./files/text_extraction_result.json"
bucketname = "<bucketname>"
connection_asset_id = "<connection_asset_id>"
# ローカルファイルをCOSにアップロードするための接続を設定
remote_document_reference = DataConnection(
connection_asset_id=connection_asset_id,
location=S3Location(bucket=bucketname, path="."),
)
# COSクライアントを設定(.write時に直接バケットを触るため必要)
remote_document_reference.set_client(client)
# COS上にテキスト抽出対象ファイルをアップロード
remote_document_reference.write(local_source_file_name, remote_name=source_file_name)
画像からテキスト抽出を実行し、抽出結果をローカルにダウンロードする
テキスト抽出ジョブ(extraction.run_job)は非同期処理なので、完了を待ってからダウンロードする必要があります。
また、今回は抽出テキストの言語として英語、画像内の表はなしとして設定しました。
より詳細な設定オプションについては、Text Extractionsライブラリのドキュメントを参照ください。
import time
# アップロードしたファイルを処理対象として参照するための接続を設定
document_reference = DataConnection(
connection_asset_id=connection_asset_id,
location=S3Location(bucket=bucketname, path=source_file_name),
)
# COS上のテキスト抽出結果ファイルの名前(マークダウン形式で出力する場合は.mdにする)
results_file_name = "./files/text_extraction_result.json"
# 処理結果を保存するための接続を設定
results_reference = DataConnection(
connection_asset_id=connection_asset_id,
location=S3Location(bucket=bucketname, path=results_file_name),
)
# Text Extractionのインスタンスを作成
extraction = TextExtractions(credentials=credentials, project_id=project_id)
# テキスト抽出を実行
response = extraction.run_job(
document_reference=document_reference,
results_reference=results_reference,
steps={
TextExtractionsMetaNames.OCR: {"languages_list": ["en"]}, # 対象言語
TextExtractionsMetaNames.TABLE_PROCESSING: {"enabled": False}, # 画像内に表が存在するかどうか
},
results_format="json" # 出力形式
)
# EXTRACTION_IDの取得
extraction_job_id = extraction.get_id(extraction_details=response)
# ジョブの完了を待つ(非同期処理)
while True:
job_details = extraction.get_job_details(extraction_id=extraction_job_id)
status = job_details['entity']['results']['status']
if status == 'completed':
break
time.sleep(10) # 10秒ごとにステータスチェック
# 結果のダウンロード
results_reference = extraction.get_results_reference(extraction_id=extraction_job_id)
output_filename = "text_extraction_result.json"
results_reference.download(filename=output_filename)
今回は画像内のテキスト位置を可視化するため、位置情報を含むJSON形式で出力しました。
一般的な文書からのテキスト抽出では、文書構造を保持できるMarkdown形式で出力した方が良いかと思います。
抽出されたJSONファイルの構造
Text Extractionで画像から抽出したJSONファイルの構造を説明します。
基本構造
{
"metadata": { ... }, // ドキュメントの基本情報
"styles": [ ... ], // テキストのスタイル定義
"top_level_structures": [ ... ], // ルートレベルの要素ID
"all_structures": { // 文書の構造情報
"sections": [ ... ], // セクション情報
"paragraphs": [ ... ], // 段落情報
"tokens": [ ... ] // 個々のテキスト要素
}
}
抽出されたテキストは階層構造で管理されており、sections → paragraphs → tokensという流れで文書の構造を表現しています。
tokensの詳細
tokensは実際に抽出されたテキストとその位置情報を含む最も重要な部分です。
画像のタイトル部分を例に、トークンの分割を説明します:

上記のタイトル「IBM watsonx.ai text extraction API workflow」は、以下のように個別のトークンに分割されています:
- TOKEN_362e51: "IBM"
- TOKEN_365932: "watsonx.ai"
- TOKEN_514535: "text"
- TOKEN_d791aa: "extraction"
- TOKEN_fe6e6e: "API"
- TOKEN_632471: "workflow"
各トークンには以下のような詳細情報が含まれています:
{
"id": "TOKEN_362e51",
"text": "IBM", // 抽出されたテキスト
"bbox": { // テキストの位置情報
"page_number": 1, // ページ番号
"x": 119.25, // 左からの位置
"y": 36.37, // 上からの位置
"width": 27.36, // テキストの幅
"height": 12.0 // テキストの高さ
}
}
このbbox(バウンディングボックス)情報により、元の画像内でのテキストの正確な位置がわかります。
テキスト抽出結果の可視化:バウンディングボックスの描画
Text Extractionによるテキスト抽出結果を可視化するPythonスクリプトです。抽出されたテキストの位置を元の画像上に赤いバウンディングボックスで表示します。
from PIL import Image, ImageDraw
import json
def draw_bounding_boxes(image_path, json_data):
# 画像を開く
img = Image.open(image_path)
# JSONデータの座標範囲を確認
tokens = json_data['all_structures']['tokens']
# スケーリング係数を計算(ポイントからピクセルへ)
scale_x = 1.333
scale_y = 1.333
draw = ImageDraw.Draw(img)
# 各トークンに対して赤い枠を描画
for token in tokens:
bbox = token['bbox']
# ポイントからピクセルに変換
x = bbox['x'] * scale_x
y = bbox['y'] * scale_y
width = bbox['width'] * scale_x
height = bbox['height'] * scale_y
# 赤い枠を描画
draw.rectangle(
[(x, y), (x + width, y + height)],
outline='red',
width=2
)
# 結果を保存
output_path = './text_extraction_flow_with_boxes.png'
img.save(output_path)
print(f"画像を保存しました: {output_path}")
# JSONデータを解析
with open("./text_extraction_result.json", "r") as f:
json_data = json.load(f)
# 元の図面の画像パスを指定して実行
draw_bounding_boxes('./text_extraction_flow.png', json_data)
重要なポイント
- スケーリング係数1.333を使用してText Extractionから返されるポイント座標をピクセル座標に変換
-
tokens配列の各要素に含まれるbbox情報から位置とサイズを取得 - バウンディングボックスは赤色、線の太さ2ピクセルで描画
注意
スケーリング係数(1.333)は画像のDPIや使用しているOSによって調整が必要な場合があります。
参考:px(pixel)とpt(point)について
処理後の画像(バウンディングボックス付き)

今回のスクリプトではtokensごとにバウンディングボックスをつけましたが、工夫次第でparagraphやsection単位で処理することも可能かと思います。
おわりに
今回はIBM watsonx.aiのText ExtractionというAI-OCRサービスの使用手順を紹介しました。VLMの進化が著しい中でも、画像や文書上のテキストとその位置情報を高精度で抽出するには、現状AI-OCRの特徴を活かせる場面が多いと考えられます。