前書き
機械学習モデルを構築する際に、トレーニングに使用するデータセット内のターゲット変数(予測したい変数)が不均衡だと色々不都合があるので、多いほうのデータを削除してバランスをとりたい時があります。この記事はpandasを使ってデータセットのバランスを調整する方法を説明します。
不均衡なデータセットに関する詳しい情報を知りたい方はこちらをご覧ください。
あなたのマシン学習データセットの不均衡なクラスと戦うための8つの戦術
データの作成
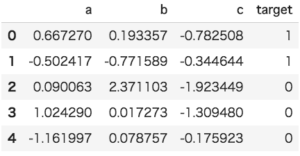
pandasを使って今回使用するデータを作成します。import pandas as pd
import numpy as np
df = pd.DataFrame({'a': np.random.randn(10),
'b': np.random.randn(10),
'c': np.random.randn(10),
'target':np.random.randint(2, size=10)})
df.head()
df.target.value_counts().plot.bar()
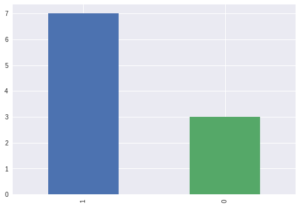
targetは0と1で構成されたデータですが、ご覧の通り0と1の数の割合が不均衡となっています。
データを削除してバランスをとる
以下のコードによって、特徴targetの1を含むデータを、先頭から3番目までの合計4つ削除します。df = df.drop(df.loc[df.target == 1].index[0:4])
df.target.value_counts().plot.bar()
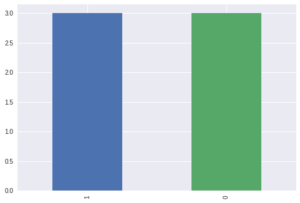
targetの割合が均等になりました。