はじめに
こんにちは、アドベントカレンダーのラストを飾らせていただく皆川です。
クリスマスということなのでブロックをリア充に見立ててAIに崩してもらおうと思いました。
強化学習とはなんぞや
機械学習という言葉をよく耳にすると思うのですが、機械学習とは教師あり学習・教師なし学習・強化学習の三つから構成されています。下記の画像を参考にいただくとわかりやすいです。
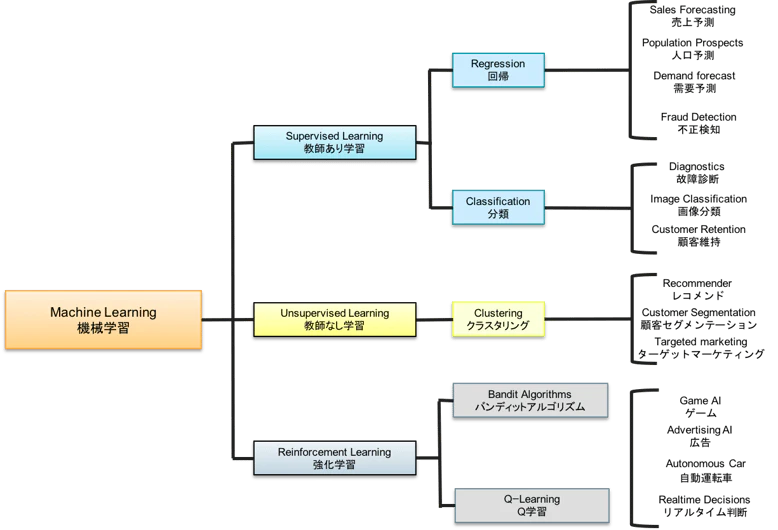
出典:教師あり学習と教師なし学習(https://goo.gl/images/Yti2zX )
強化学習とは「環境に置かれたエージェントが環境に対して行動し得られる報酬が最大化されるような方策を求める手法」です。
よくわからないですよね、、、、簡単に説明すると
まず設計者(人間)はエージェント(AI)に対して何をしたらいくつ報酬をあげるのかということを設定します。(例:ボールをゴールに入れたら1.0の報酬、逆に決められたら−1.0の報酬)
次にエージェントが知るべき環境を与えてあげます(例:ボールの速度、ボールとエージェントの相対距離)
あとは、エージェントに何回もゲームに挑戦させます。そうすると、エージェントは得られる報酬を最大化させようと行動を調整します。(例:報酬を最大化させるためにボールに近づきボールをゴールの中に入れようとする)
ML-Agents
この強化学習をするために、UnityではML-Agentsというライブラリが用意されています。発表されてから早1年が経ち、日々アップデートされ使いやすくなっています。
ゲームにおいて、AIの作成をするのはとても骨の折れる作業です。しかし、このML-Agentsを使えば簡単に時間がかからずAIにゲームの仕組みを理解させ、優秀なNPCを作成することができます。
以下の動画をご覧いただければイメージがつきやすいと思います
SF Bay Area devs - Join us on 12/7 for the Unity Evangelists 2017 Blow Out, where recent updates to ML-Agents will be shared and the first ever machine learning community challenge will be announced! More info: https://t.co/17LIRJHt2q pic.twitter.com/u7ThUAw8qN
— Unity (@unity3d) 2017年12月1日
参考にしたもの
実際、自分が作る時に参考になったものをご紹介いたします
GitHub
https://github.com/Unity-Technologies/ml-agents
まあこれをみれば他のものはいらないのですが、初めてだと若干きついかもしれません
書籍
Unityではじめる機械学習・強化学習 Unity ML-Agents実践ゲームプログラミング
ML-Agents唯一の書籍。2018/8/3に発売されたものなのですが、v0.3(この記事投稿時はv0.6)なのでほとんど役に立たないのですが、初めてやる人はこれで全体の大枠をつかんでからやるのもオススメです。
※1/8 追記
メールが届きまして、https://www.borndigital.co.jp/book/6702.html
こちらのサイトにv0.6改訂の内容が記載されました。
UnityBlog
https://blogs.unity3d.com/jp/2018/12/17/ml-agents-toolkit-v0-6-improved-usability-of-brains-and-imitation-learning/
MLはバージョンアップが激しいので、UnityBlogで追うことが大切です
UnityConnect
https://connect.unity.com
お学びグループ、Forrum、PublicChannel(Unity MachineLearning)ここで質問ができるのでオススメです。
記事
@kai_kou さん MacでUnity ML-Agentsの環境を構築する(v0.5.0対応)
https://qiita.com/kai_kou/items/6478fa686ce1af5939d8
環境構築
ML-Agents(v0.6.0)ではUnity2017.4以降で、pythonは3.6です(ターミナル,アナコンダどちらでも大丈夫です)。
以下の手順に沿って進めていきます
1.まずはml-agents-masterをクローンします
git clone https://github.com/Unity-Technologies/ml-agents.git
2.そしたらcdをml-agentsにしてパッケージをインストールします
pip3 install -e .
3.適当なUnityProjectを作成します
4.先ほどダウンロードしたUnitySDKを作成したプロジェクトにインポートします
5.Edit > Project Settings > Player > Other Settings > Scripting Runtime Version > Experimental (.NET 4.6 Equivalent or .NET 4.x Equivalent)
*ここで一度プロジェクトの再ダウンロードを要求されるのであらかじめシーンを保存しておきます
6.TensorFlowSharp Pluginをプロジェクトにインポートします
7.Edit > Project Settings > Player > Other Settings >Scripting Define Symbols > ENABLE_TENSORFLOW
ここまでが全プロジェクト共通の設定です。
ブロック崩し
まず基本となる簡単なブロック崩しゲームを作ります
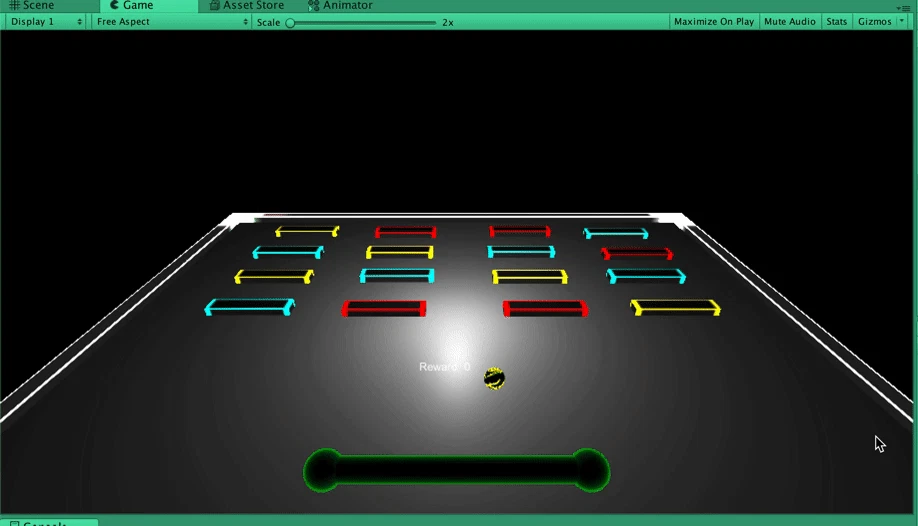
球を弾き返してブロックを壊せば点数が入る簡単なゲームです。
今回はこのプレイヤーが操作している棒をAgentとして強化学習させていきます
ブロック崩しにML-Agentを適用させる
ML-Agentで学習させるには、AgentとBrainとAcademyが必要になります。
Agent
using UnityEngine;
using MLAgents;
public class BreakOutAgent : Agent
{
[SerializeField] private GameObject[] _blocks;
[SerializeField] private GameObject _ball;
private Rigidbody _rigidbody;
private Rigidbody _ballRigidBody;
//Agentの初期化時に呼ばれるStart関数のようなもの(Start関数は使えない)
public override void InitializeAgent()
{
_rigidbody = gameObject.GetComponent<Rigidbody>();
_ballRigidBody = _ball.GetComponent<Rigidbody>();
}
//ここではBrainに環境の情報を与えます、情報を与えすぎると学習に時間がかかってしまうので必要なものだけ選びます。(今回だと、ボールとプレイヤーの相対位置とボールのベクトル)また、ブロックの情報なども与えたいので本来はVisualObservationの方が好ましいと思います。
public override void CollectObservations()
{
AddVectorObs(_ball.transform.position - gameObject.transform.position);
AddVectorObs(_ballRigidBody.velocity);
}
//フレーム毎に呼ばれます
public override void AgentAction(float[] vectorAction, string textAction)
{
//プレイヤー上に報酬の表示
Monitor.verticalOffset = -4;
Monitor.Log("Reward", "" + GetCumulativeReward(), gameObject.transform);
//エピソード完了
if (GameManager._score == 210 || GameManager._life == 0)
{
Done();
return;
}
//0~2で行動を決める
var _movement = (int) vectorAction[0];
switch (_movement)
{
case 1:
_rigidbody.AddForce(transform.right * -50, ForceMode.Impulse);
AddReward(-0.01f);
break;
case 2:
_rigidbody.AddForce(transform.right * 50, ForceMode.Impulse);
AddReward(-0.01f);
break;
}
}
//Agentがボールに当たったら報酬を受け取るようにする
private void OnCollisionEnter(Collision other)
{
if (other.gameObject.tag == "Ball")
{
AddReward(0.1f);
}
}
private void OnGUI()
{
GUI.skin.label.normal.textColor = Color.white;
}
//エピソード完了時に呼ばれる
public override void AgentReset()
{
GameManager._life = 3;
GameManager._score = 0;
gameObject.transform.position = new Vector3(0, 0, 0);
foreach (var _block in _blocks)
{
_block.SetActive(true);
}
_ball.transform.position = new Vector3(0f, 0.6f, -7f);
_ball.SetActive(true);
}
}
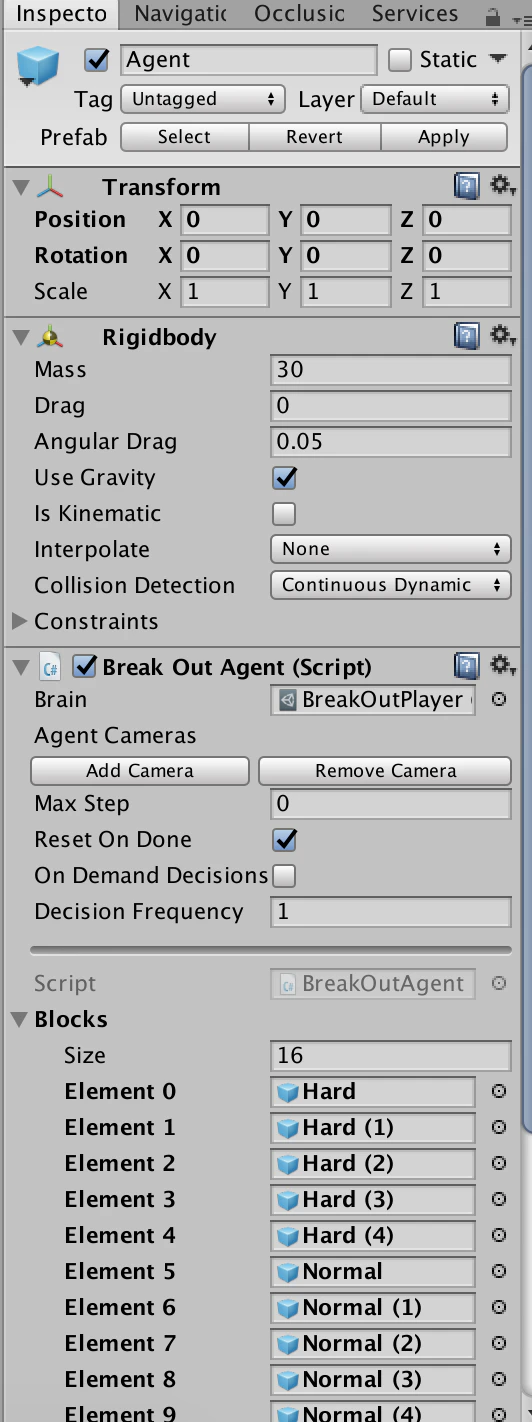
推論時と学習時で以下に紹介するBrainの指定を変えます。
Brain
Agentを操る脳です。ScriptableObjectとして用意されているのでProjectビューから作成できます。
PlayerBrain
プレイヤー(人間)が操る場合ではこちらを使用します。模倣学習や、学習前の実験で使用します。
VectorObservationはボールの速度ベクトル(x,y,z)とプレイヤーとボールの相対位置(x,y,z)の情報を与えるので6に設定してあります。branchは(0~2)を指定して、1の際は左、2の際は右へプレイヤーが移動するように指定しています。
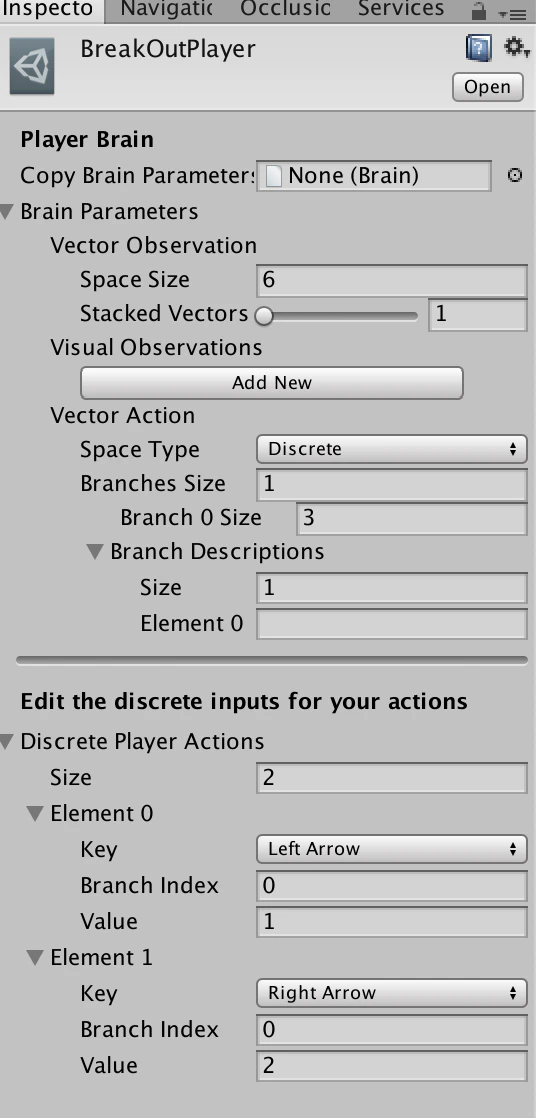
LearningBrain
学習・推論時に使用します。設定はPlayerと同じで、Modelには学習終了後の.byteファイルを指定します。学習前はmodelは空にしておきます。
HeuristicBrain
手書きスクリプトでActionを決定する場合はこちらを使用します。
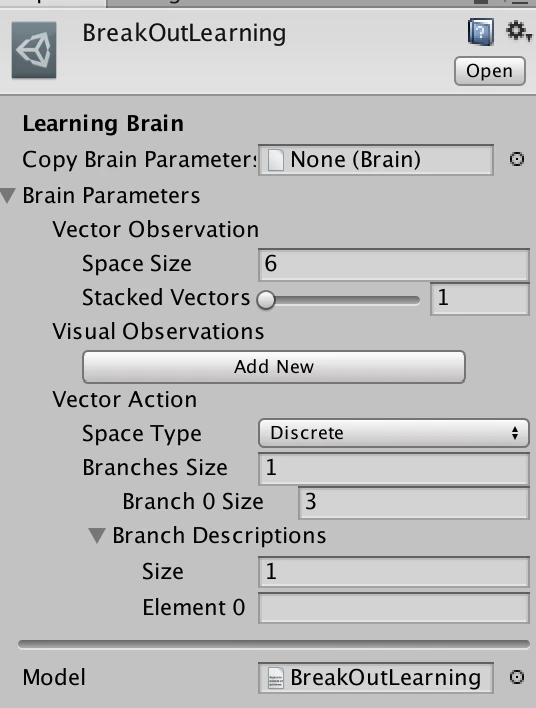
Academy
学習時のBrainの指定や学習についての設定を行います。名前の通りに学校です。
using MLAgents;
public class BreakOutAcademy : Academy {
//環境のリセット時に呼ばれる
public override void AcademyReset()
{
}
//ステップごとに呼ばれる
public override void AcademyStep()
{
}
}
ステップとはupdateと同じようなもので、ステップ数を指定して何ステップ毎にBrainがActionを決定するかを決めたりします。
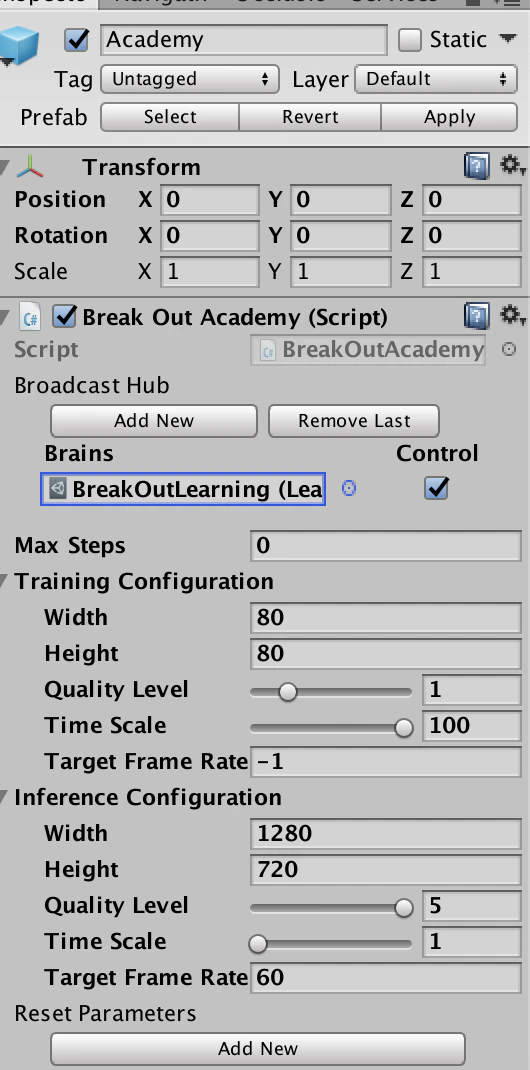
学習時にはBroadcasthubにLearningBrainを指定してControlにチェックを入れます。その他はとりあえず既定値のままにしておきます。
学習の実行
上記で紹介している以外のものがたくさんあるのですが、以上で基本的な設定は終わります。
次に学習を実行します。AgentとAcademyのBrainがLearningであることをしっかりと確認したらターミナルへいきます。
ターミナルのディレクトリがml-agentsであることを確認したら以下のコマンドを実行します
mlagents-learn ../config/trainer_config.yaml --run-id=firstRun --train
trainer_config.yamlはconfigの中にあるのでターミナルに直接ドラッグしてパスを指定してください。
--run-id はmodelファイルを作成するときの名前なのでなんでも大丈夫です。
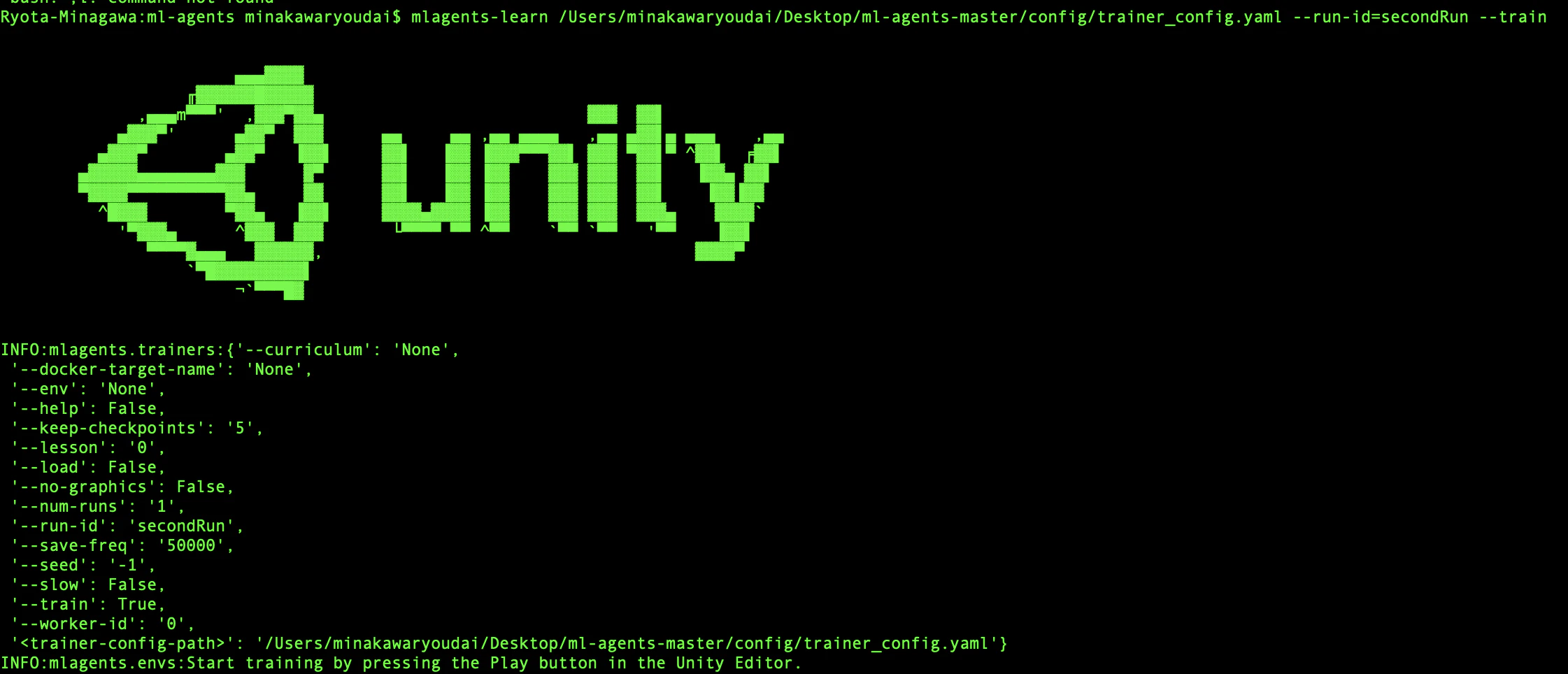
Editorの再生ボタンを押すように要求されるので押すと学習が開始します
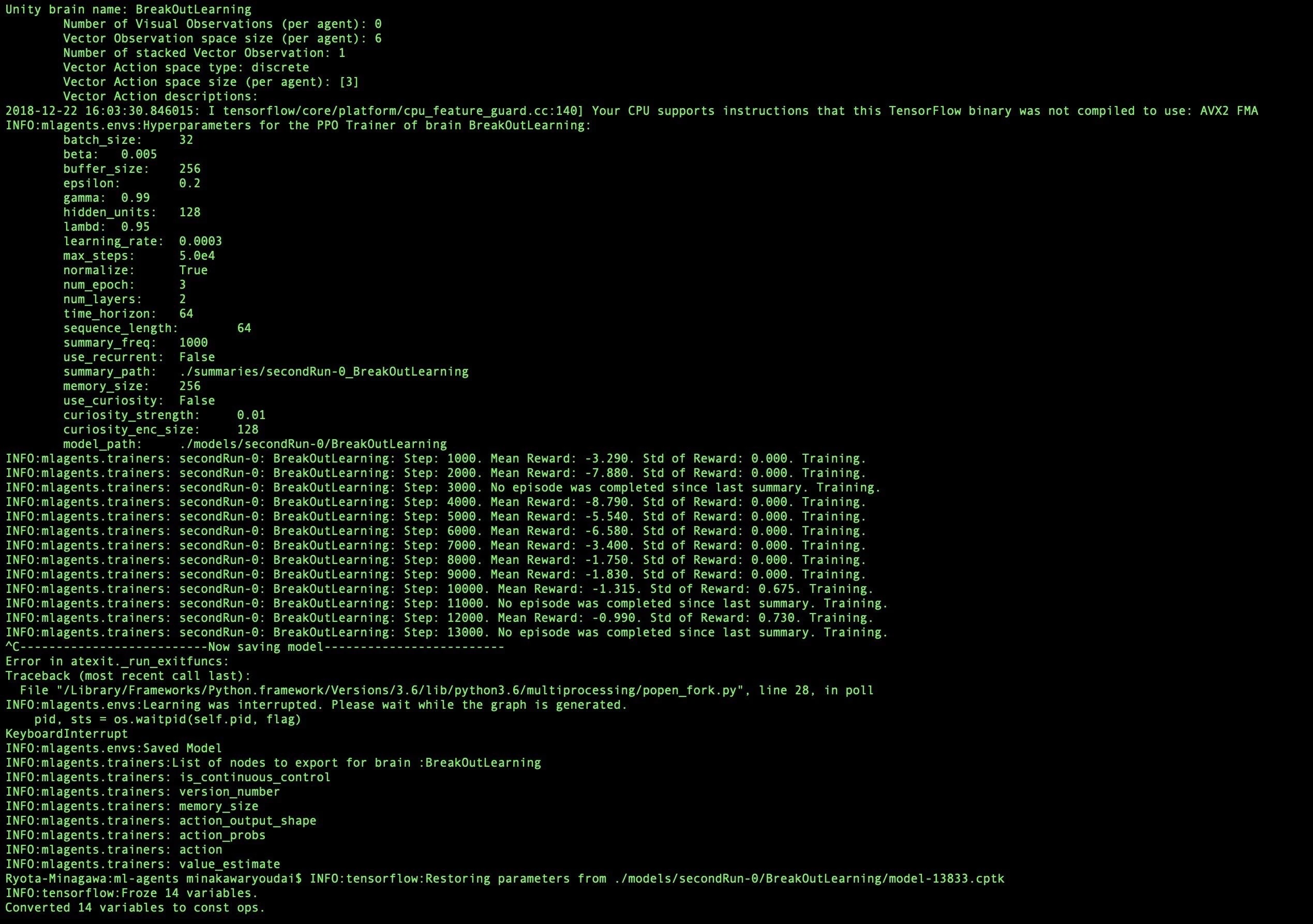
カクカクしてますがとりあえず動いて感動です

終わるとml-agents > models > firstRun ができているのでプロジェクトにインポートして、BreakOutLearning.bytesをBreakOutLearningのModelに指定してあげます。
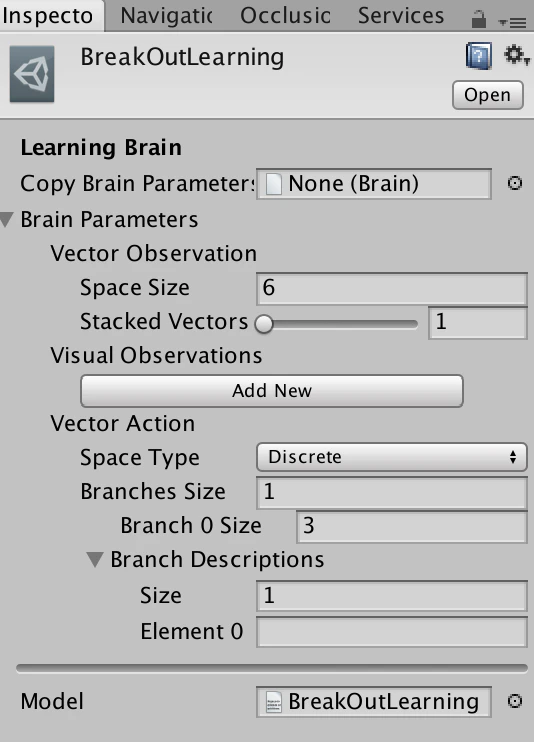
最後にAgentのBrainをBreakOutLearningにしてプロジェクトを実行します(推論)
最後に
思った以上に簡単に作れることがわかっていただけたでしょうか?自分はこれを作成している途中でgithubから再ダウンロードしたら、バージョンが変わってて全然わかんなくなった(締め切り近い)という地獄のような経験をしました。
多分日本語記事で最新版のML-Agentsに関する記事はあんまりないと思うので是非参考にしていただければ嬉しいです。
ML-Agentsはそんなに機械学習に関する知識がないひとでも作れるようになっているので、ぜひまずは手始めに公式サンプルの3DBallをやってみてはいかがでしょうか!
ここを直した方がいいなどいろんなご意見いただけると嬉しいです。