はじめに
"Youtube Data API"を使って、指定した検索ワードに関連する動画データの
再生された回数、高く評価したユーザーの数などを可視化するプログラムを作成します。
※ 本投稿は、Mac OSを前提としています。
macOS Catalina 10.15.7で作業しています。
※ 本投稿では、Python 3.9を利用します。
$ python3 -V
Python 3.9.1
$ pip3 --version
pip 21.0.1 from /usr/local/lib/python3.9/site-packages/pip (python 3.9)
前提条件
"Youtube Data API"の登録には、Googleアカウントが必要になりますので、
事前にGoogleアカウントを取得して下さい。
1. "Youtube Data API"の登録
下記に示す手順で"Yotube Data API"の登録を行い、APIキーを取得します。
(1) Google Cloud Platformにアクセス
Google Cloud Platformにアクセスします。
(2) 新しいプロジェクトの作成
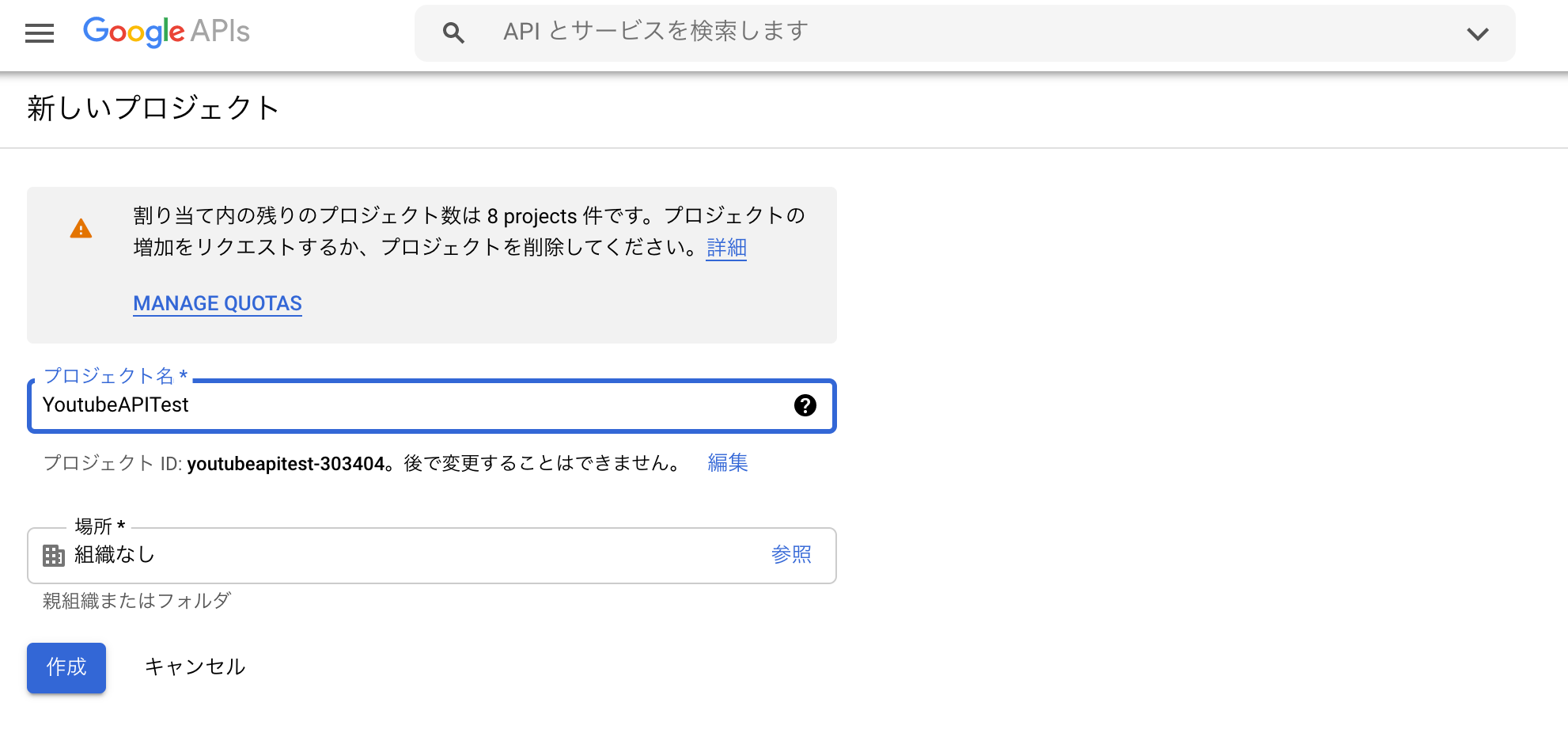
「プロジェクトを作成」ボタンを押下し、新しいプロジェクトを作成します。
例:YoutubeAPITest
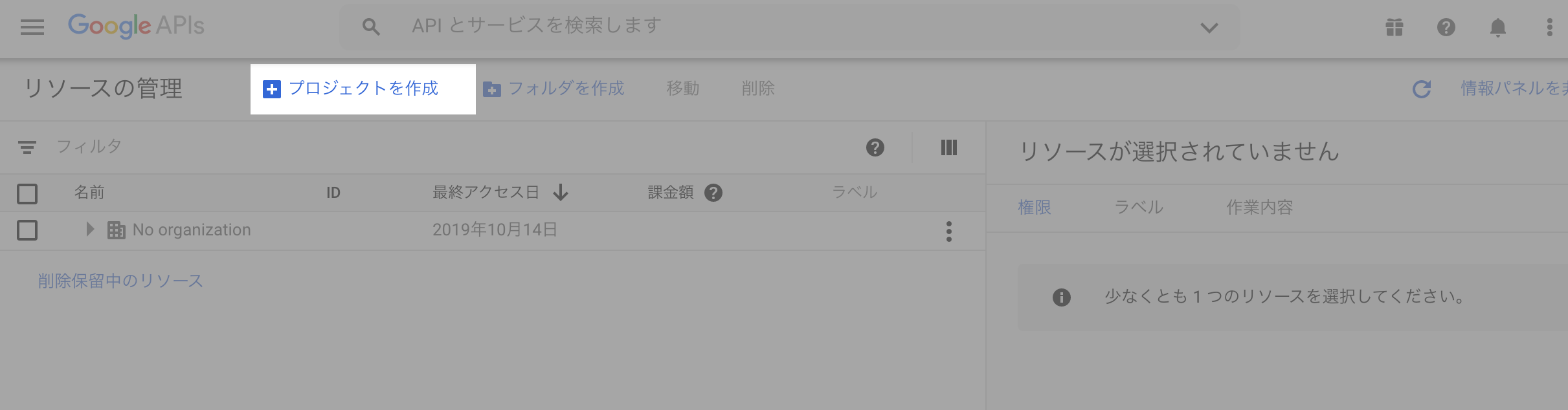
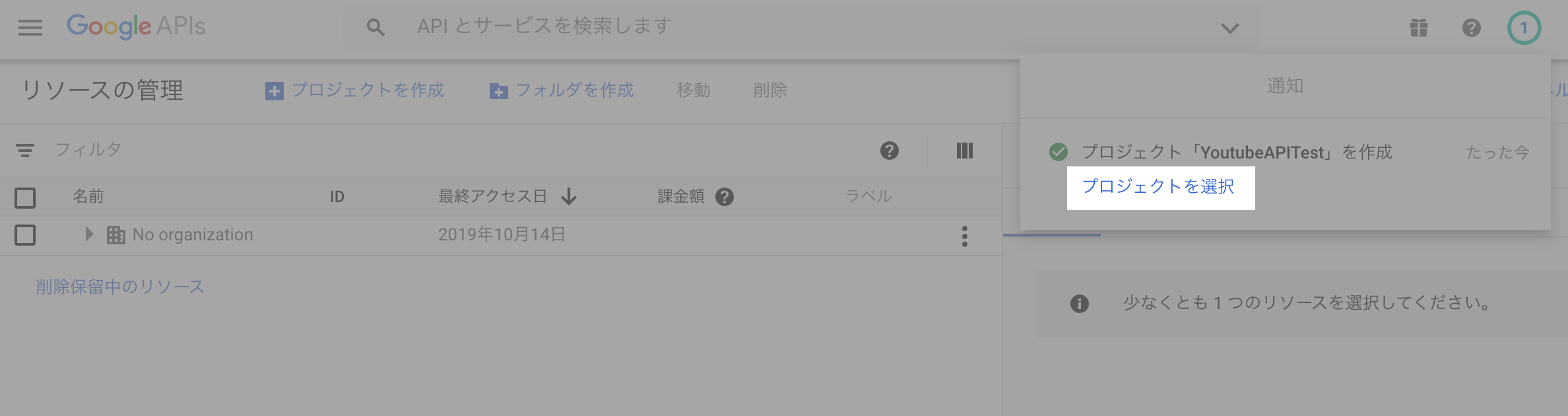
(3) 「プロジェクトを選択」ボタンを押下し、プロジェクトの設定画面に遷移します。
(4) 検索ボックスに「YouTube Data API v3」を入力し、その先のページへ遷移します。
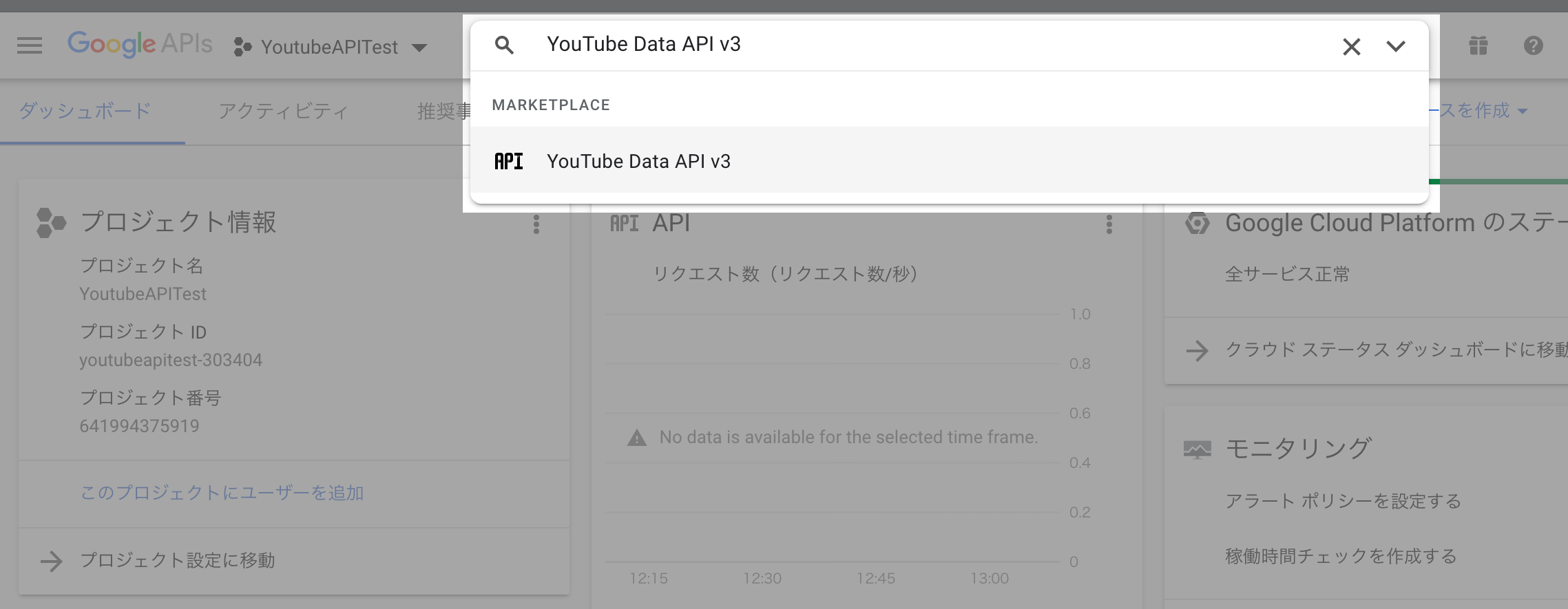
(5) 遷移後の画面で、「YouTube Data API v3」のAPIを有効にします。
(6) 認証情報の画面で、「認証情報を作成」ボタンを押下し、APIキーを取得します。
取得したAPIキーは、Pythonで利用する為、控えておいて下さい。
2. Youtube からデータを取得するサンプルプログラムの作成
"Youtube Data API"を使って、Youtubeにアクセスし、
検索結果を標準出力するプログラムを作成します。
(1) 作業ディレクトリの作成
任意のパスに作業ディレクトリを作成して下さい。
$ mkdir youtubeapi
$ cd youtubeapi
(2) google-api-python-clientのインストール
Python用の"Google API クライアント ライブラリ"をインストールします。
※ Youtube Data APIを利用するために必要なライブラリです。
$ sudo pip3 install google-api-python-client
(3) サンプルプログラムの作成
検索結果を1件だけ標準出力するサンプルプログラムを作成します。
# coding: UTF-8
from googleapiclient.discovery import build
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_response = youtube.search().list(
part='snippet',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
).execute()
print(search_response['items'][0])
簡単にプログラムの説明を行います。
① YOUTUBE_API_KEY = '{APIキー}'
{APIキー}の部分に1.(6)で取得したAPIキーを設定して下さい。
② youtube.search().list
指定したクエリパラメータに一致する検索結果のコレクションを返します。
以下にサンプルで指定している検索パラメータとコレクションの説明を行います。
※ 詳細は、YouTube Data API のリファレンス(Search: list)を参照して下さい。
| 検索パラメータ | 説明 |
|---|---|
| part | 必須パラメータ id もしくは、snippetを指定する必要があります。 snippetを指定すると、id以外に結果のタイトルなども取得できます。 サンプルでは、snippetを指定しています。 |
| q | クエリパラメータ 検索したい文字列を指定します。 サンプルでは、英会話を指定しています。 |
| order | 検索結果の並べ替え方法を指定します。 サンプルでは、viewCount(再生回数の多い順)を指定しています。 |
| type | 検索対象を特定のタイプのリソースのみに制限します。 サンプルでは、video(動画)を指定しています。 |
| コレクションのプロパティ | 説明 |
|---|---|
| items[] | 検索条件に一致する結果のリスト サンプルでは、配列[0]を指定し、 取得した検索結果(1件)を標準出力しています。 |
(4) サンプルプログラムの動作確認
サンプルプログラムを実行し、検索結果(1件)が標準出力されていることを確認します。
$ python3 sample1.py
{'kind': 'youtube#searchResult', 'etag': 'EJ5-MMzyLItypTbjNGgTBbc6QS4', 'id': {'kind': 'youtube#video', 'videoId': 'QT_tCa3KEEA'}, 'snippet': {'publishedAt': '2019-07-07T22:00:02Z', 'channelId': 'UCTYQzAi6YOcgv2mkzsfzmpA', 'title': '英語の耳を作る!リスニング訓練', 'description': 'ネイティブのナレーターが話す音声を何度も聞いて、あなたのリスニング力を鍛えましょう! 音声は合計で4回流れます。最初は自然な速度の音声が2回流れるので、何を ...', 'thumbnails': {'default': {'url': 'https://i.ytimg.com/vi/QT_tCa3KEEA/default.jpg', 'width': 120, 'height': 90}, 'medium': {'url': 'https://i.ytimg.com/vi/QT_tCa3KEEA/mqdefault.jpg', 'width': 320, 'height': 180}, 'high': {'url': 'https://i.ytimg.com/vi/QT_tCa3KEEA/hqdefault.jpg', 'width': 480, 'height': 360}}, 'channelTitle': "Kendra's Language School", 'liveBroadcastContent': 'none', 'publishTime': '2019-07-07T22:00:02Z'}}
3. サンプルプログラムの改良
2.で作成したサンプルプログラムを改良していきます。
本節はスキップし、「4. Youtube から取得したデータを可視化するプログラムの作成」に
進んで頂いても問題ありません。
3-1. 標準出力の変更
2.で作成したサンプルプログラムでは、JSON形式のデータが1行で標準出力されている為、
どんなデータが検索結果として返ってきているのか確認しにくいので、
出力フォーマットを変更します。
(1) サンプルプログラムの修正
下記のように修正を行います。
jsonモジュールを使って、標準出力する結果を見やすくします。
# coding: UTF-8
from googleapiclient.discovery import build
import json
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_response = youtube.search().list(
part='snippet',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
).execute()
# 辞書型からJSON形式の文字列型へ変換
json_data = json.dumps(search_response['items'][0])
# JSON形式で出力
data = json.loads(json_data)
print(json.dumps(data, indent=2, ensure_ascii=False))
(2) サンプルプログラムの動作確認
サンプルプログラムを実行し、出力結果を確認します。
改行、インデントが入り、見やすくなっていることが確認できます。
$ python3 sample2.py
{
"kind": "youtube#searchResult",
"etag": "EJ5-MMzyLItypTbjNGgTBbc6QS4",
"id": {
"kind": "youtube#video",
"videoId": "QT_tCa3KEEA"
},
"snippet": {
"publishedAt": "2019-07-07T22:00:02Z",
"channelId": "UCTYQzAi6YOcgv2mkzsfzmpA",
"title": "英語の耳を作る!リスニング訓練",
"description": "ネイティブのナレーターが話す音声を何度も聞いて、あなたのリスニング力を鍛えましょう! 音声は合計で4回流れます。最初は自然な速度の音声が2回流れるので、何を ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/QT_tCa3KEEA/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/QT_tCa3KEEA/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/QT_tCa3KEEA/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Kendra's Language School",
"liveBroadcastContent": "none",
"publishTime": "2019-07-07T22:00:02Z"
}
}
3-2. 検索結果の詳細データの取得
3-1.で出力された結果には、再生された回数、高く評価したユーザーの数などが
出力されていません。理由は、youtube.search().listでは、
それらの情報を取得できない為です。
再生された回数、高く評価したユーザーの数など詳細な情報を取得するためには、
youtube.videos().listを利用する必要があります。
(1) サンプルプログラムの修正
下記のように修正を行います。
# coding: UTF-8
from googleapiclient.discovery import build
import json
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_response = youtube.search().list(
part='id',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
).execute()
# 動画を一意に識別するために YouTube によって使用される IDを取得
videoId=search_response['items'][0]["id"]["videoId"]
# 動画の詳細情報の検索クエリ
search_response = youtube.videos().list(
id=videoId,
part="snippet,statistics"
).execute()
# 辞書型からJSON形式の文字列型へ変換
json_data = json.dumps(search_response['items'][0])
# JSON形式で出力
data = json.loads(json_data)
print(json.dumps(data, indent=2, ensure_ascii=False))
簡単にプログラムの説明を行います。
① videoId=search_response['items'][0]["id"]["videoId"]
youtube.search().listの結果から"videoId"を取得します。
② youtube.videos().list
指定したvideoIdのコレクションを返します。
①で取得したvideoIdを指定しています。
また、取得したいコレクションのプロパティも指定します。
以下にサンプルで指定しているコレクションのプロパティの説明を行います。
※ 詳細は、YouTube Data API のリファレンス(Videos)を参照して下さい。
| コレクションのプロパティ | 説明 |
|---|---|
| snippet | 動画の基本的な情報(タイトル、説明など)が格納されます。 |
| statistics | 動画に関する統計情報が格納されます。 |
③ youtube.search().list
検索パラメータ(part)に、idを指定しています。
snippetの情報は、youtube.videos().listで取得できる為、
通信データ量の節約の為、idを指定しています。
(2) サンプルプログラムの動作確認
サンプルプログラムを実行し、出力結果を確認して下さい。
結果の量が多いので、割愛しますが、viewCount(再生された回数)、
likeCount(高く評価したユーザーの数)が確認出来ます。
3-3. 検索結果の取得件数の制御
ここまでは、検索結果(1件)のデータを扱ってきましたが、
検索結果の取得件数を制御する方法について、説明したいと思います。
まず、大前提としてYoutube Data APIには、日単位で利用できる量に制限があります。
大量の検索結果を取得するクエリを何度も実行していると、
1日の上限数に達し、次の日までクエリが実行できなくなります。
そのため、取得したい件数を明確に指定出来るようにすることは重要です。
(1) youtube.search().listの1回あたりの取得件数
youtube.search().listの取得件数は、2.(3)で説明した
検索パラメータの1つmaxResultsで0以上50以下の値を指定できます。
デフォルト値は、5です。
下記のサンプルを実行して下さい。
取得した検索結果の配列の長さ(検索結果の数)を出力するサンプルですが、
maxResultsを指定していない為、デフォルトの5件が結果として出力されます。
※ 検索結果が5件以内の場合(2件など)、2件と表示されます。
# coding: UTF-8
from googleapiclient.discovery import build
import json
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_result_list = []
search_response = youtube.search().list(
part='snippet',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
).execute()
search_result_list += search_response['items']
print(len(search_result_list))
$ python3 sample4.py
5
次にmaxResultsに上限値の50を指定した下記のサンプルを実行して下さい。
検索結果が50件以上存在した場合であっても、50件と表示されます。
# coding: UTF-8
from googleapiclient.discovery import build
import json
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_result_list = []
search_response = youtube.search().list(
part='snippet',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
maxResults="50", #1クエリあたりの検索結果の上限数を指定
).execute()
search_result_list += search_response['items']
print(len(search_result_list))
$ python3 sample5.py
50
(2) 次ページ以降のデータ取得
(1)を例にすると、51件目以降のデータを取得する場合、
2.(3)で説明したコレクションのプロパティの1つnextPageTokenを使います。
具体的には、youtube.search().list_nextを使用し、引数に前回の検索結果を渡します。
下記にサンプルを記載します、クエリを3回実行するので、
上限値50×3の150件が表示されます。
# coding: UTF-8
from googleapiclient.discovery import build
import json
# Youtube Data APIのキーを指定
YOUTUBE_API_KEY = '{APIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_count=3
search_result_list = []
for i in range(int(search_count)):
if i==0:
# 検索クエリ(初回)
search_query = youtube.search().list(
part='snippet',
q='英会話', #検索したい文字列を指定
order='viewCount', #視聴回数が多い順に取得
type="video", #検索対象のタイプを指定
maxResults="50", #1クエリあたりの検索結果の上限数を指定
)
else:
# 検索クエリ(2回目以降)
search_query = youtube.search().list_next(search_query, search_response)
# 検索実行
search_response = search_query.execute()
search_result_list += search_response['items']
print(len(search_result_list))
$ python3 sample6.py
150
3.では可視化したいデータの取得方法、取得したいデータ件数の制御方法について
説明しました。
4.では取得したデータを可視化するプログラムについて説明します。
4. Youtube から取得したデータを可視化するプログラムの作成
Youtube から取得したデータをPandas/matplotlibを使って、可視化します。
Youtube から取得したデータをCSVファイルに出力するプログラムと
CSVファイルを読み込んで可視化するプログラムの2つに分けます。
3-3.で説明した通り、Youtube Data APIには、日単位で利用できる量に制限がある為、
色んな角度から可視化したい場合、何度もYoutube Data APIを利用するのではなく、
一度出力したCSVファイルに対して、処理を行ったほうが効率が良いためです。
4-1. Youtubeデータ抽出プログラムの作成
(1) Pandasのインストール
最初にPython用のデータ解析用ライブラリ(Pandas)をインストールします。
$ sudo pip3 install pandas
(2) プログラムの作成
下記に作成したプログラムを示します。
ファイル名は、任意です。
ここでは、ExtractYoutubeData.pyという名前にしています。
プログラムの内容を簡単に説明すると、
指定した検索条件(検索ワード、動画の公開日)、並べ替え方法で動画を抽出し、
指定した件数分の動画情報をCSVに出力するプログラムです。
# coding: UTF-8
from googleapiclient.discovery import build
import json
import sys
import datetime
import pandas as pd
# Youtube Data APIのキーを指定
DEVELOPER_KEY = '{APIキー}'
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
SEARCH_LIMIT = 50
"""
デバック処理(JSON出力)
"""
def print_json(output):
# 辞書型からJSON形式の文字列型へ変換
json_data = json.dumps(output)
# JSON形式で出力
data = json.loads(json_data)
print(json.dumps(data, indent=2, ensure_ascii=False))
"""
検索処理
"""
def search(options):
# YouTube Data APIの接続設定
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY)
"""
検索の実行回数を算出
1回の検索で取得するデータの最大件数(SEARCH_LIMIT)と
引数で受け取ったCSV出力件数(options["csvOutCount"])から算出する。
"""
search_count_arg = divmod(int(options["csvOutCount"]), SEARCH_LIMIT)
search_count = search_count_arg[0]
if search_count_arg[1] != 0:
search_count+=1
"""
検索結果(リスト)の取得
検索の実行回数分、検索クエリを実行し、検索結果(リスト)を取得する。
"""
search_result_list = []
for i in range(int(search_count)):
if i==0:
# 検索クエリ(初回)
search_query = youtube.search().list(
part="id",
type="video",
q=options["q"],
publishedAfter=options["publishedAfter"],
publishedBefore=options["publishedBefore"],
order=options["order"],
maxResults=SEARCH_LIMIT
)
else:
# 検索クエリ(2回目以降)
search_query = youtube.search().list_next(search_query, search_response)
# 検索結果(リスト)の取得
search_response = search_query.execute()
#print_json (search_response)
# 検索結果(リスト)の"items"部分を格納する。
search_result_list += search_response["items"]
# 次ページにデータが存在しない場合、ループを抜ける。
if "nextPageToken" not in search_response:
break
"""
検索結果(詳細)の取得
引数で受け取ったCSV出力件数(options["csvOutCount"])分、
詳細情報を取得する検索クエリを実行し、検索結果(詳細)を取得する。
"""
# CSVファイルのヘッダ名称の設定
list_df = pd.DataFrame(columns=["videoURL", "title", "publishedAt", "description", "channelId", "channelTitle", "viewCount", "likeCount", "dislikeCount", "favoriteCount", "commentCount"])
for i in range(int(options["csvOutCount"])):
# 検索結果(リスト)の取得件数に達した場合、ループを終了する。
if i == len(search_result_list):
break
search_result = search_result_list[i]
# 動画を一意に識別するために YouTube によって使用される IDを取得
videoId=search_result["id"]["videoId"]
# 動画のvideoIDから動画のURLを作成
videoURL="https://youtu.be/"+videoId
# 動画の詳細情報の検索クエリ
search_query = youtube.videos().list(
id=videoId,
part="snippet,statistics"
)
# 検索結果を取得する。
search_response = search_query.execute()
#print_json (search_response)
# 検索結果の"items"部分を格納する。
search_result_detail = search_response["items"][0]
"""
snippetの情報を取得
"""
snippet=search_result_detail["snippet"]
# 動画のアップロード日時を取得
publishedAt=snippet.get("publishedAt", None)
# 動画のアップロード先チャンネルを一意に識別するために YouTube によって使用される IDを取得
channelId=snippet.get("channelId", None)
# 動画が属するチャンネルのチャンネル タイトルを取得
channelTitle=snippet.get("channelTitle", None)
# 動画のタイトルを取得
title=snippet.get("title", None)
# 動画の説明を取得
description=snippet.get("description", None)
"""
statisticsの情報を取得
"""
statistics=search_result_detail["statistics"]
# これまでに動画が再生された回数
viewCount=statistics.get("viewCount", 0)
# [高く評価] ボタンを押して動画を高く評価したユーザーの数
likeCount=statistics.get("likeCount", 0)
# [低く評価] ボタンを押して動画を低く評価したユーザーの数
dislikeCount=statistics.get("dislikeCount", 0)
# その時点で動画をお気に入りに登録しているユーザーの数
favoriteCount=statistics.get("favoriteCount", 0)
# 動画に対するコメントの数
commentCount=statistics.get("commentCount", 0)
# 1行分のDataFrame
temp_df = pd.Series([videoURL, title, publishedAt, description, channelId, channelTitle, viewCount, likeCount, dislikeCount, favoriteCount, commentCount], index=list_df.columns)
# リストのDataFrameに1行分のDataFrameを追加
list_df = list_df.append(temp_df, ignore_index=True)
# リストのDataFrameを返す。
return list_df
"""
メイン処理
引数1:検索条件① 検索ワード
引数2:検索条件② From(@が入力された場合、1970-01-01 00:00:00Zに自動変換する。)
引数3:検索条件③ To(@が入力された場合、実行日時に自動変換する。)
引数4:検索結果の並べ替え方法
relevance – 検索結果を検索クエリの関連性が高い順に並び替える。
date – 検索結果を作成日の新しい順に並び替える。
rating – 検索結果を評価の高い順に並び替える。
title – 検索結果をタイトルのアルファベット順に並び替える。
videoCount – 検索結果をアップロード動画の番号順(降順)に並び替える。
viewCount – 検索結果を再生回数の多い順に並び替える。
引数5:CSV出力件数
引数6:CSVファイル名称
"""
if __name__ == "__main__":
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":処理開始")
# 引数の数をチェック
if len(sys.argv) < 7:
print ("Check the number of argv!")
sys.exit(1)
# 引数の取得
q = sys.argv[1]
publishedAfter = sys.argv[2]
publishedBefore = sys.argv[3]
order = sys.argv[4]
csvOutCount = sys.argv[5]
csvFileName = sys.argv[6]
# 日付の変換(@の場合、From、Toにそれぞれのデフォルト値を設定する。)
if publishedAfter == "@":
publishedAfter = "1970-01-01T00:00:00Z"
if publishedBefore == "@":
publishedBefore = datetime.datetime.now().isoformat()+"Z"
# 検索パラメータの設定
dic = {"q":q, "publishedAfter":publishedAfter, "publishedBefore":publishedBefore, "order":order, "csvOutCount":csvOutCount}
# 検索処理を実行し、検索結果を取得する。
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":検索処理")
list_df = search(dic)
# 検索結果をCSVに出力
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":CSV出力")
list_df.to_csv(csvFileName, encoding="UTF-8", mode="w", index=False)
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":処理終了")
(3) プログラムの実行
コロナ前後(リモートワークが増加し始めた後と前)の英会話に関するデータについて
可視化したいので、下記のようにプログラムを実行します。
$ python3 ExtractYoutubeData.py 英会話 2020-01-26T00:00:00.000000Z @ viewCount 500 afterCOVID.csv
2021年03月06日 15:33:37:処理開始
2021年03月06日 15:33:37:検索処理
2021年03月06日 15:34:12:CSV出力
2021年03月06日 15:34:12:処理終了
$ python3 ExtractYoutubeData.py 英会話 @ 2020-01-26T00:00:00.000000Z viewCount 500 beforeCOVID.csv
2021年03月06日 15:36:18:処理開始
2021年03月06日 15:36:18:検索処理
2021年03月06日 15:36:54:CSV出力
2021年03月06日 15:36:54:処理終了
afterCOVID.csvには、リモートワークが増加し始めた2020年1月26日以降のデータ、
beforeCOVID.csvには、2020年1月26日以前のデータをそれぞれ500件出力しています。
また、並べ替え方法にviewCount(再生された回数)を指定しているので、
再生回数の多い動画が出力されます。
※ 500件の指定には意味があります。詳細については、補足を参照して下さい。
4-2. 可視化プログラムの作成
(1) matplotlibのインストール
データを可視化するためのライブラリ(matplotlib)をインストールします。
$ sudo pip3 install matplotlib
(2) japanize_matplotlibのインストール
デフォルトでは、matplotlibで日本語を正しく表示できない為、
日本語化ライブラリ(japanize_matplotlib)をインストールします。
$ sudo pip3 install japanize-matplotlib
(3) プログラムの作成
下記に作成したプログラムを示します。
ファイル名は、任意です。
ここでは、VisualizeYoutubeData.pyという名前にしています。
プログラムの内容を簡単に説明すると、
最初に指定したCSVのデータを読み込みます。
その後、likeCount(高く評価したユーザーの数)とviewCount(再生された回数)から、
閲覧した人の1%以上が「いいね」をしている動画を抽出しています。
※ 4-1.で再生回数の多い動画が抽出されていますが、更に評価が高い動画を抽出します。
最後に上記の条件で抽出した動画を多く保持しているチャンネルの
上位20位を横棒グラフで可視化しています。
# coding: UTF-8
import sys
import datetime
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
"""
可視化処理
"""
def visualize(options):
# 1.YouTube Data(CSV)を読み込む。
df = pd.read_csv(options["csvFileName"], sep=",", encoding="UTF-8", usecols=lambda x: x not in ["description"])
# 2.閲覧した人の1%が「いいね」をしている動画に絞り込む。
df2 = df.query('(likeCount/viewCount)*100 >= 1')
# 3.YouTubeのチャンネル単位にグループを作成する。
grouped = df2.groupby("channelTitle")
# 4.可視化
# 2.の条件を満たす動画をたくさん保持しているチャネルの上位20位までを出力する。
grouped.size().sort_values(ascending=False).head(20).sort_values(ascending=True).plot(kind="barh", figsize=(40,8), fontsize=5, colormap='gist_gray')
plt.title('動画の閲覧数と評価が高いチャンネル')
plt.subplots_adjust(bottom=0.10, left=0.15, top=0.95, right=0.95)
plt.show()
"""
メイン処理
引数1:CSVファイル名称
"""
if __name__ == "__main__":
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":処理開始")
# 引数の数をチェック
if len(sys.argv) < 2:
print ("Check the number of argv!")
sys.exit(1)
# パラメータの設定
dic = {"csvFileName":sys.argv[1]}
# 可視化を実行する。
visualize(dic)
print (datetime.datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')+":処理終了")
(4) プログラムの実行
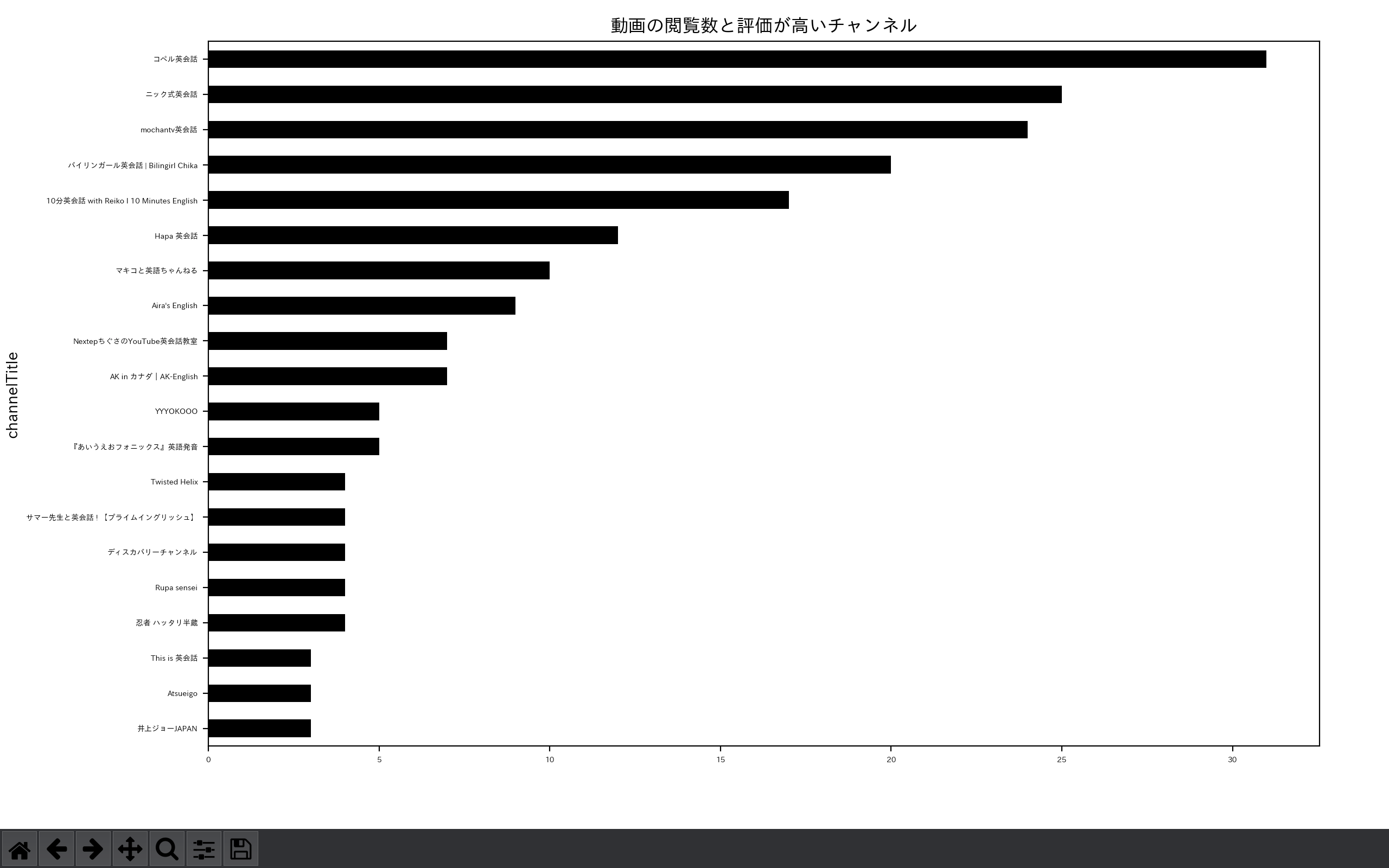
① 2020年1月26日以前のデータを確認します。
$ python3 VisualizeYoutubeData.py beforeCOVID.csv
② 2020年1月26日以降のデータを確認します。
$ python3 VisualizeYoutubeData.py afterCOVID.csv
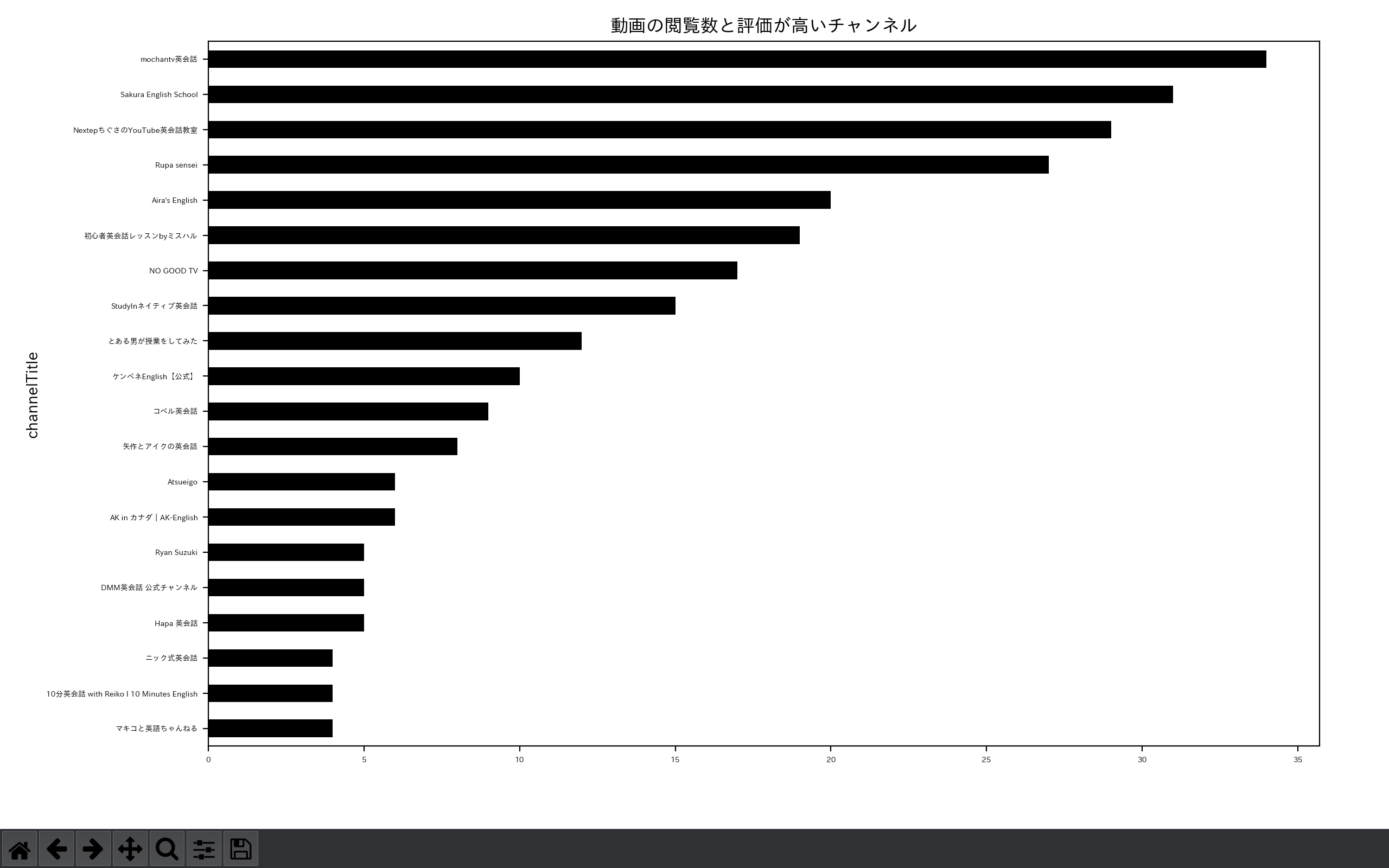
リモートワークの増加前後で上位の結果が変わっていることを確認できます。
以上で終了となります。
Youtube Data API、Python(Pandas/matplotlib)のどちらも汎用性が高いので
色々と試して下さい。
補足
Youtube Data API には、500件問題というものがあります。
3-3.(2)でnextPageTokenを使うと、51件目以降のデータも取得できると説明しましたが、
500件を超えると想定外の結果が返ってきます。
Youtube Data API で問題を解決してほしいですが、
下記のような処理を行えば、500件目以降のデータも取得できると考えています。
(1) youtube.search().listの検索パラメータに
order=date、maxResults=50を指定し、検索を実行します。
(2) (1)で取得した最終データの公開日付を保持します。
(3) youtube.search().listの検索パラメータに
publishedBefore={(2)で保持した公開日付}、order=date、maxResults=50を指定し、
検索を実行します。
※ 公開日付によっては、既に取得済みのデータが抽出されるかもしれません。
その際は、重複データを除外して下さい。
(4) データが0件になるまで、(2)と(3)を繰り返します。
参考ページ
Youtube Data APIを使ってPythonでYoutubeデータを取得する
pandas.DataFrameの行を条件で抽出するquery
macOS Mojaveでmatplotlibの豆腐フォントを日本語にする方法(Python)
matplotlibのグラフの配置と位置・サイズに関する一考察
color example code