はじめに
今流行りの Midjourney
テキストを渡すと、それに合った画像を生成してくれます
下の画像は Delicious chocolate です

これをローカルで動かしたい、というツイートがあり、
@zacky1972 さんがこれを見て「誰かやってみない?」と言っていたのでやってみました
元リポジトリーはこちら
フォークして、 Docker 、 CPU 環境で動くようにしたのがこちら
実行環境
- macOS Monterey 12.4
- Rancher Desktop 1.5.1
Dockerfile
まず元リポジトリーをクローンしてきます
git clone https://github.com/CompVis/latent-diffusion.git && \
cd latent-diffusion
今回動かしたいのは scripts/txt2img.py です
これに必要なモデルファイルをダウンロードします
6.15 GB もあるので、ダウンロードに結構時間がかかるのと、
ディスク容量ギリギリの人(私はいつも)は気を付けましょう
mkdir -p models/ldm/text2img-large/ && \
wget -O models/ldm/text2img-large/model.ckpt \
https://ommer-lab.com/files/latent-diffusion/nitro/txt2img-f8-large/model.ckpt
ローカルマシンに CUDA 対応の CPU がない場合、コードの中で cuda を指定しているところを消したり cpu に置き換えたりします
ldm/models/diffusion/ddim.py
...
def register_buffer(self, name, attr):
- if type(attr) == torch.Tensor:
- if attr.device != torch.device("cuda"):
- attr = attr.to(torch.device("cuda"))
setattr(self, name, attr)
...
ldm/modules/encoders/modules.py
...
class TransformerEmbedder(AbstractEncoder):
"""Some transformer encoder layers"""
- def __init__(self, n_embed, n_layer, vocab_size, max_seq_len=77, device="cuda"):
+ def __init__(self, n_embed, n_layer, vocab_size, max_seq_len=77, device="cpu"):
super().__init__()
self.device = device
self.transformer = TransformerWrapper(num_tokens=vocab_size, max_seq_len=max_seq_len,
...
class BERTTokenizer(AbstractEncoder):
""" Uses a pretrained BERT tokenizer by huggingface. Vocab size: 30522 (?)"""
- def __init__(self, device="cuda", vq_interface=True, max_length=77):
+ def __init__(self, device="cpu", vq_interface=True, max_length=77):
super().__init__()
from transformers import BertTokenizerFast # TODO: add to reuquirements
self.tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
self.device = device
self.vq_interface = vq_interface
self.max_length = max_length
...
class BERTEmbedder(AbstractEncoder):
"""Uses the BERT tokenizr model and add some transformer encoder layers"""
def __init__(self, n_embed, n_layer, vocab_size=30522, max_seq_len=77,
- device="cuda",use_tokenizer=True, embedding_dropout=0.0):
+ device="cpu",use_tokenizer=True, embedding_dropout=0.0):
super().__init__()
self.use_tknz_fn = use_tokenizer
if self.use_tknz_fn:
self.tknz_fn = BERTTokenizer(vq_interface=False, max_length=max_seq_len)
self.device = device
self.transformer = TransformerWrapper(num_tokens=vocab_size, max_seq_len=max_seq_len,
attn_layers=Encoder(dim=n_embed, depth=n_layer),
emb_dropout=embedding_dropout)
...
class FrozenCLIPTextEmbedder(nn.Module):
"""
Uses the CLIP transformer encoder for text.
"""
- def __init__(self, version='ViT-L/14', device="cuda", max_length=77, n_repeat=1, normalize=True):
+ def __init__(self, version='ViT-L/14', device="cpu", max_length=77, n_repeat=1, normalize=True):
super().__init__()
self.model, _ = clip.load(version, jit=False, device="cpu")
self.device = device
self.max_length = max_length
self.n_repeat = n_repeat
self.normalize = normalize
scripts/txt2img.py
...
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
sd = pl_sd["state_dict"]
model = instantiate_from_config(config.model)
m, u = model.load_state_dict(sd, strict=False)
if len(m) > 0 and verbose:
print("missing keys:")
print(m)
if len(u) > 0 and verbose:
print("unexpected keys:")
print(u)
- model.cuda()
model.eval()
return model
...
元の README には Anaconda で環境構築するように書いていますが、
コンテナに閉じ込めてしまいたい(いろんなところで動かしたい)ので Dockerfile を作ります
Docker で Anaconda 環境を構築する部分はこちらの記事を参考にしました
Dockerfile
FROM python:3.8
RUN apt-get update && apt-get install -y \
sudo \
wget \
vim
WORKDIR /opt
RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && \
sh Miniconda3-latest-Linux-x86_64.sh -b -p /opt/miniconda3 && \
rm -r Miniconda3-latest-Linux-x86_64.sh
ENV PATH /opt/miniconda3/bin:$PATH
RUN pip install --upgrade pip && \
conda update -n base -c defaults conda
# 必要そうなファイルをコピー
# models は大きいのでマウントする
# scripts はいじることが多そうなのでマウントする
COPY ./configs /app/configs
COPY ./ldm /app/ldm
COPY ./setup.py /app/setup.py
COPY ./main.py /app/main.py
WORKDIR /app
# 実行環境を設定
COPY ./environment.yaml /app/environment.yaml
RUN conda env create -f environment.yaml
RUN conda init bash
RUN echo "conda activate ldm" >> ~/.bashrc
ENV CONDA_DEFAULT_ENV ldm && \
PATH /opt/conda/envs/ldm/bin:$PATH
CMD ["/bin/bash"]
画像の出力先ディレクトリーを作っておきます
mkdir outputs
簡単に起動できるように docker-compose.yml を作ります
---
version: "2.3"
services:
ldm:
container_name: ldm
build:
context: .
volumes:
- ./models:/app/models
- ./scripts:/app/scripts
- ./outputs:/app/outputs # 出力先ディレクトリー
tty: true # 起動したままにする
モデルファイルが 6.15 GB もあるため、メモリを非常に多く消費します
私のマシンでは、 Rancher Desktop の設定で 14 GB も VM に割り当てないと動きませんでした
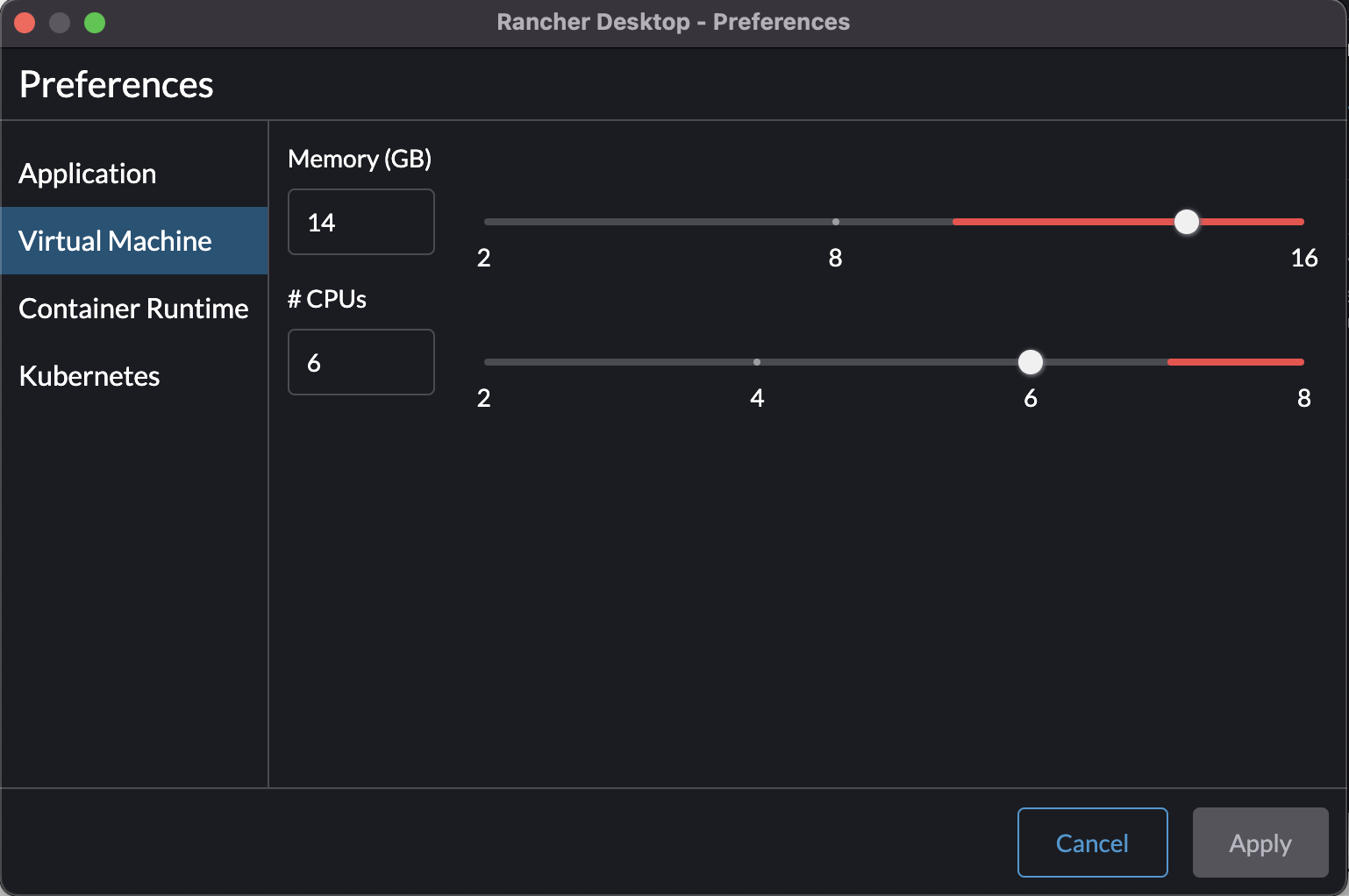
この状態でコンテナを起動します
ビルドが走って、しばらくするとコンテナが開始されます
$ docker-compose up --build
...
Attaching to ldm
コンテナに入ります
docker exec -it ldm /bin/bash
REDME に従って追加のパッケージをインストールします
※Dockerfile 内で conda activate ldm するとエラーになっていたので、これだけコンテナに入ってから実行
pip install transformers==4.19.2 scann kornia==0.6.4 torchmetrics==0.6.0
pip install git+https://github.com/arogozhnikov/einops.git
コンテナ内で実行します
以下の実行例では a virus monster is playing guitar, oil on canvas というテキストを画像にしています
$ python scripts/txt2img.py --prompt "a virus monster is playing guitar, oil on canvas" --ddim_eta 0.0 --n_samples 4 --n_iter 4 --scale 5.0 --ddim_steps 50
Loading model from models/ldm/text2img-large/model.ckpt
...
Sampling: 0%| | 0/4 [00:00<?, ?it/s]Data shape for DDIM sampling is (4, 4, 32, 32), eta 0.0
Running DDIM Sampling with 50 timesteps
DDIM Sampler: 100%|████████████████████████████████████████████████████████████████████████████████████| 50/50 [08:11<00:00, 9.83s/it]
Sampling: 25%|██████████████████████▎ | 1/4 [08:41<26:04, 521.48s/it]Data shape for DDIM sampling is (4, 4, 32, 32), eta 0.0
Running DDIM Sampling with 50 timesteps
DDIM Sampler: 100%|████████████████████████████████████████████████████████████████████████████████████| 50/50 [08:27<00:00, 10.15s/it]
Sampling: 50%|████████████████████████████████████████████▌ | 2/4 [17:46<17:50, 535.48s/it]Data shape for DDIM sampling is (4, 4, 32, 32), eta 0.0
Running DDIM Sampling with 50 timesteps
DDIM Sampler: 100%|████████████████████████████████████████████████████████████████████████████████████| 50/50 [07:45<00:00, 9.31s/it]
Sampling: 75%|██████████████████████████████████████████████████████████████████▊ | 3/4 [25:50<08:31, 511.72s/it]Data shape for DDIM sampling is (4, 4, 32, 32), eta 0.0
Running DDIM Sampling with 50 timesteps
DDIM Sampler: 100%|████████████████████████████████████████████████████████████████████████████████████| 50/50 [07:02<00:00, 8.46s/it]
Sampling: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 4/4 [33:06<00:00, 496.54s/it]
Your samples are ready and waiting four you here:
outputs/txt2img-samples
Enjoy.
n_samples に 4 を指定しているので、1回毎に 4枚画像が生成され、
n_iter に 4 を指定しているので、4回実行されます
outputs/txt2img-samples に16枚画像が生成され、
それらが 4 * 4 で組み合わされた画像が outputs/a-virus-monster-is-playing-guitar,-oil-on-canvas.png として生成されます
出来上がった画像はこちら

確かに、ウィルスモンスターがギターを弾いている油絵です
ちなみに、1回実行するのに数十分かかります
やはり GPU がないと厳しいですね、、、
Elixir's space adventures cartoon で実行するとこんな感じです

絵柄といい題字といい、カートゥーンっぽさが見事に出ています
まとめ
やはり GPU がないと重たいモデルは厳しいですね
コンテナ化できたので、ちゃんと整理して AWS の GPU インスタンスに乗せればまともに動くはず