はじめに
Bumblebee の公式サンプルに従ってモデルを実行してみるシリーズです
今回は NER = National Engineers Register = 固有表現認識を実行します
ざっくり言うと、人名や地名などの固有名詞 + 日時、金額 といった情報を文章から抜き出す手法です
bert-base-NER と言う AI モデルを使用します
このシリーズの記事
- 画像分類: ResNet50
- 画像生成: Stable Diffusion
- 文章の穴埋め: BERT
- 文章の判別: BERTweet
- 文章の生成: GPT2
- 質疑応答: RoBERTa
- 固有名詞の抽出: bert-base-NER (ここ)
Bumblebee の公式サンプル
実装の全文はこちら
実行環境
- MacBook Pro 13 inchi
- 2.4 GHz クアッドコアIntel Core i5
- 16 GB 2133 MHz LPDDR3
- macOS Ventura 13.0.1
- Rancher Desktop 1.6.2
- メモリ割り当て 12 GB
- CPU 割り当て 6 コア
Livebook 0.8.0 の Docker イメージを元にしたコンテナで動かしました
コンテナ定義はこちらを参照
セットアップ
必要なモジュールをインストールして EXLA.Backend で Nx が動くようにします
Mix.install(
[
{:bumblebee, "~> 0.1"},
{:nx, "~> 0.4"},
{:exla, "~> 0.4"},
{:kino, "~> 0.8"}
],
config: [nx: [default_backend: EXLA.Backend]]
)
コンテナで動かしている場合、キャッシュディレクトリーを指定した方が都合がいいです
※詳細はこの記事を見てください
cache_dir = "/tmp/bumblebee_cache"
モデルのダウンロード
モデルファイルを Haggin Face からダウンロードしてきて読み込みます
必要な場合は cache_dir を指定します
{:ok, bert} =
Bumblebee.load_model({
:hf,
"dslim/bert-base-NER",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"bert-base-cased",
cache_dir: cache_dir
})
サービスの提供
Bumblebee.Text.token_classification で固有表現認識サービスを提供します
aggregation については後述します
serving = Bumblebee.Text.token_classification(bert, tokenizer, aggregation: :same)
文章の準備
固有名詞を抽出する対象の文章を準備します
テキストエリアの文章を変更すれば、変更した文章から固有名詞を抽出することができます
text_input =
Kino.Input.textarea("TEXT",
default: "Set before and after the French Revolution, the film depicts the dramatic life of Oscar, a beautiful man dressed in men's clothing, and Queen Marie Antoinette of France."
)
入力された文章を取得します
text = Kino.Input.read(text_input)

推論の実行
推論して結果をデータテーブルに表示します
serving
|> Nx.Serving.run(text)
|> then(&Kino.DataTable.new(&1.entities))
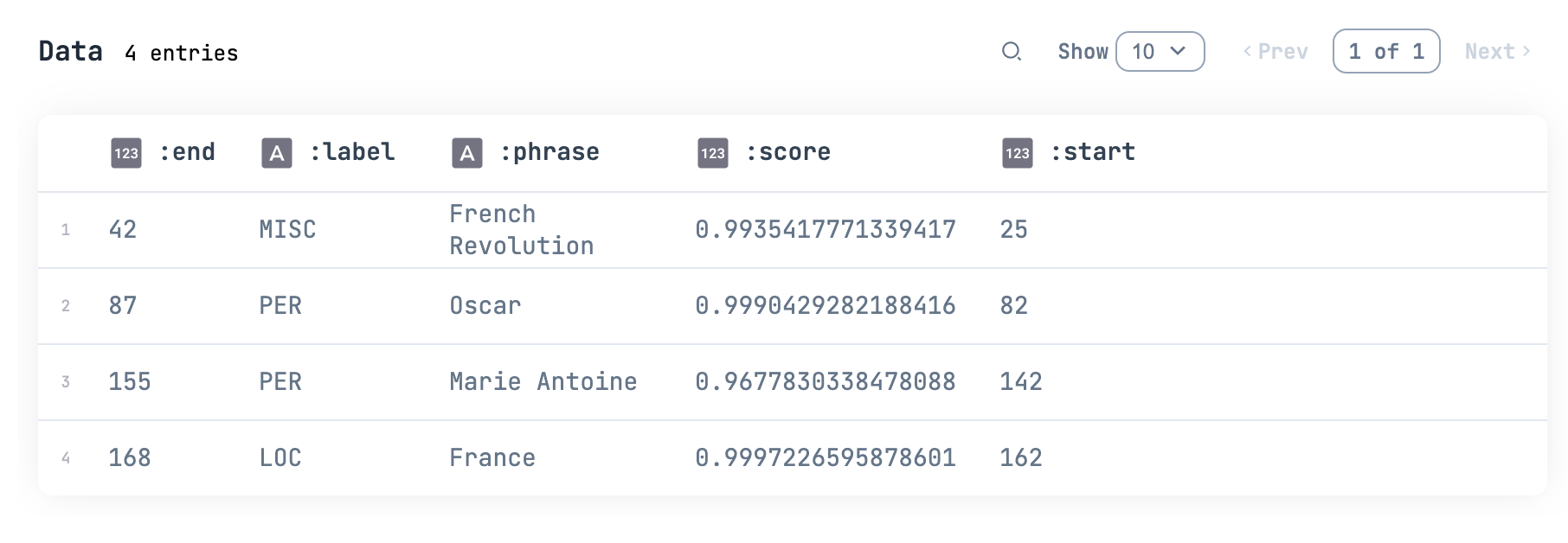
ここで label が「どんな単語なのか」を表します
- PER: 人名
- ORG: 組織名
- LOC: 地名
- MISC: その他の固有表現
- O: 固有表現以外
Bumblebee.Text.token_classification ではデフォルトで O を出力しないようにしています
オスカルやマリーアントワネット(末尾の tte が抜けているけど)が人名、フランスが地名、フランス革命はその他になりました
aggregation を指定しない場合
aggregation: :same を指定しない場合、以下のような結果になります
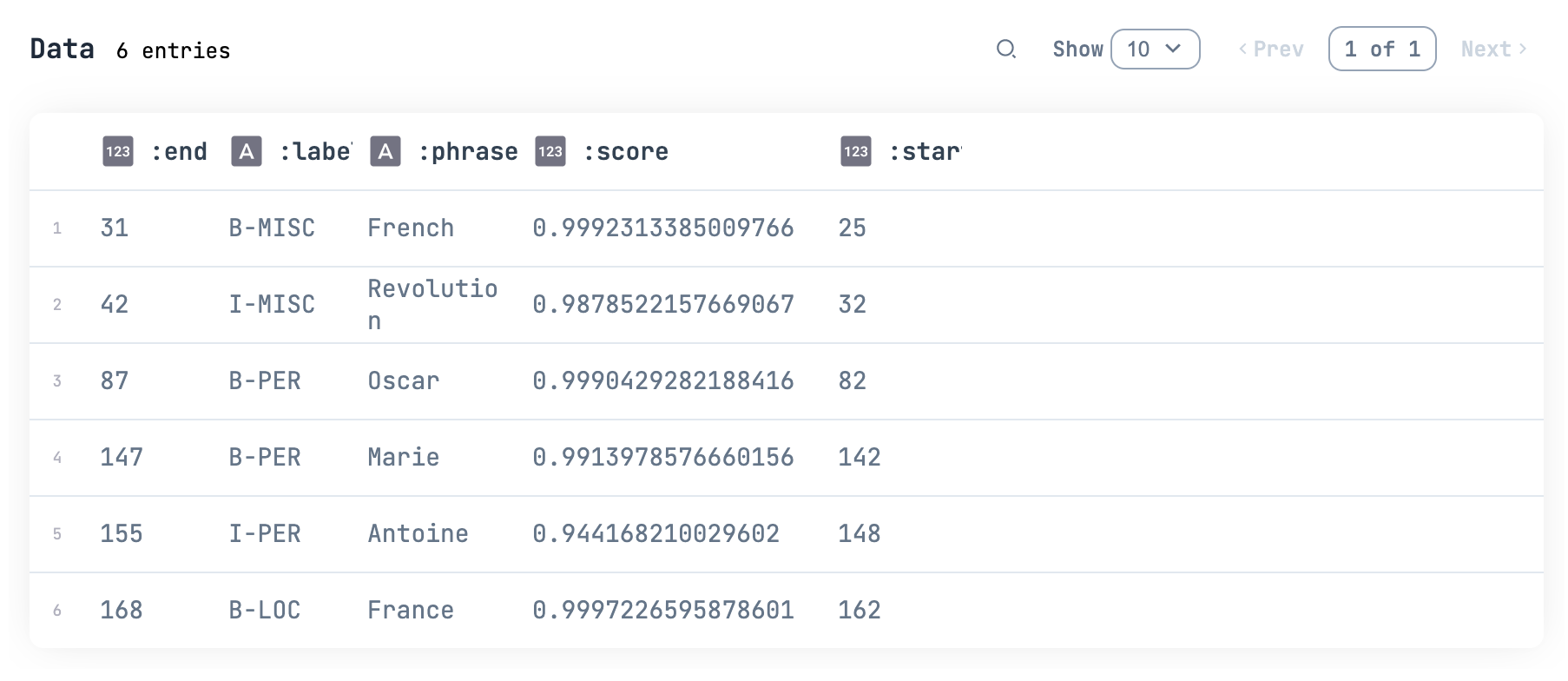
B- は Biggining で固有表現の先頭を表し、 I- が先頭以外を表しています
aggregation: :same を指定すると B- と I- を集約した結果になります
まとめ
これからの Bumblebee に期待が持てますね