はじめに
Bumblebee の公式サンプルに従ってモデルを実行してみるシリーズです
今回は BERTweet という自然言語処理 AI モデルを使って、文章がポジティブかネガティブかを判定します
このシリーズの記事
- 画像分類: ResNet50
- 画像生成: Stable Diffusion
- 文章の穴埋め: BERT
- 文章の判別: BERTweet (ここ)
- 文章の生成: GPT2
- 質疑応答: RoBERTa
- 固有名詞の抽出: bert-base-NER
Bumblebee の公式サンプル
実装の全文はこちら
実行環境
- MacBook Pro 13 inchi
- 2.4 GHz クアッドコアIntel Core i5
- 16 GB 2133 MHz LPDDR3
- macOS Ventura 13.0.1
- Rancher Desktop 1.6.2
- メモリ割り当て 12 GB
- CPU 割り当て 6 コア
Livebook 0.8.0 の Docker イメージを元にしたコンテナで動かしました
コンテナ定義はこちらを参照
セットアップ
必要なモジュールをインストールして EXLA.Backend で Nx が動くようにします
Mix.install(
[
{:bumblebee, "~> 0.1"},
{:nx, "~> 0.4"},
{:exla, "~> 0.4"},
{:kino, "~> 0.8"}
],
config: [nx: [default_backend: EXLA.Backend]]
)
コンテナで動かしている場合、キャッシュディレクトリーを指定した方が都合がいいです
※詳細はこの記事を見てください
cache_dir = "/tmp/bumblebee_cache"
モデルのダウンロード
モデルファイルを Haggin Face からダウンロードしてきて読み込みます
必要な場合は cache_dir を指定します
{:ok, bertweet} =
Bumblebee.load_model({
:hf,
"finiteautomata/bertweet-base-sentiment-analysis",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"vinai/bertweet-base",
cache_dir: cache_dir
})
tokenizer は別のリポジトリーのものを使う必要があります
サービスの提供
Bumblebee.Text.text_classification で文章識別サービスを提供します
serving = Bumblebee.Text.text_classification(bertweet, tokenizer)
マスクされた文章の準備
テキスト入力を作り、文章を入力します
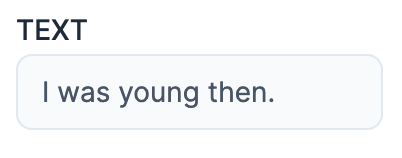
text_input = Kino.Input.text("TEXT", default: "I was young then.")
入力された文章を取得します
text = Kino.Input.read(text_input)

推論の実行
推論してデータテーブルに結果を表示します
serving
|> Nx.Serving.run(text)
|> then(&Kino.DataTable.new(&1.predictions))
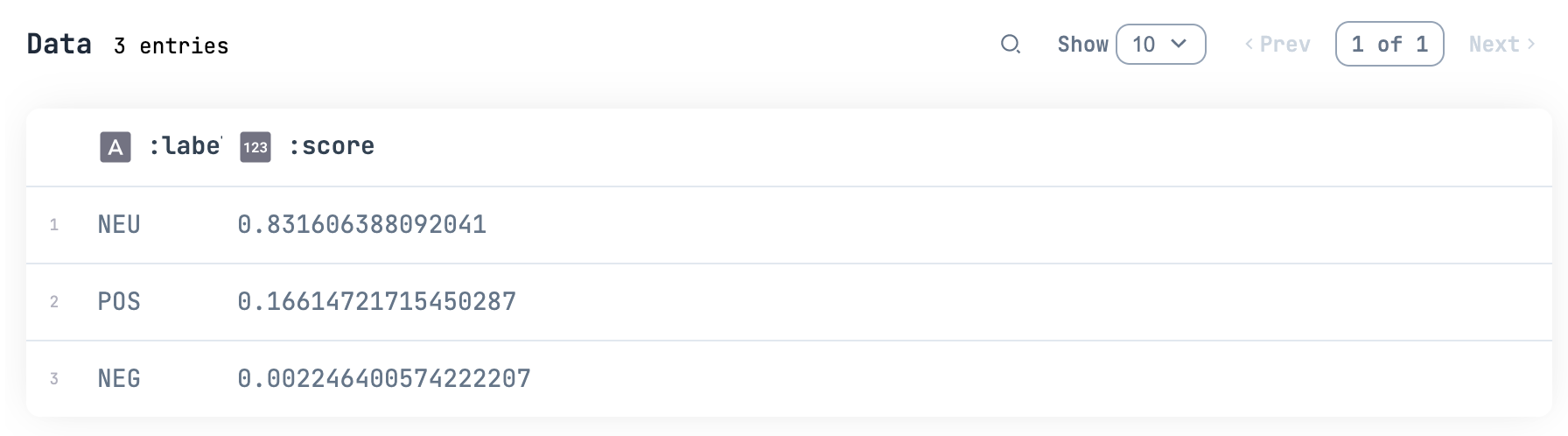
NEU はニュートラル、 POS はポジティブ、 NEG はネガティブです
「あの頃私は若かった」だとどちらとも言えない、ということですね
他の文章を見てみましょう
My face is wet and I have no strength. (顔が濡れて力が出ない)
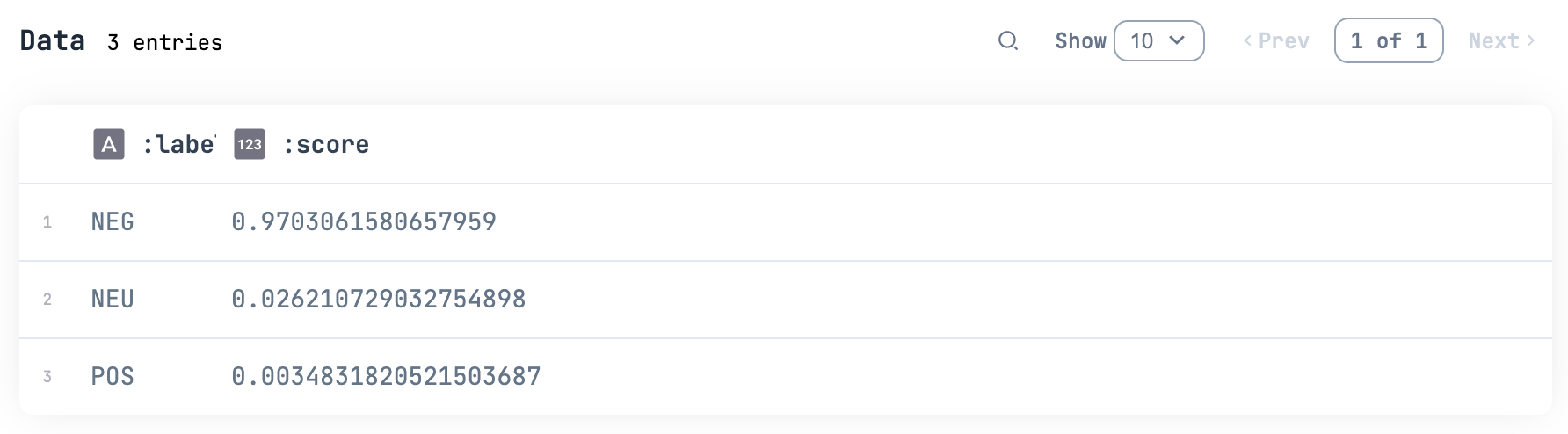
明らかにネガティブですね
That cliffhanger is our best chance! (その崖っぷちが最高のチャンスなんだぜ!)
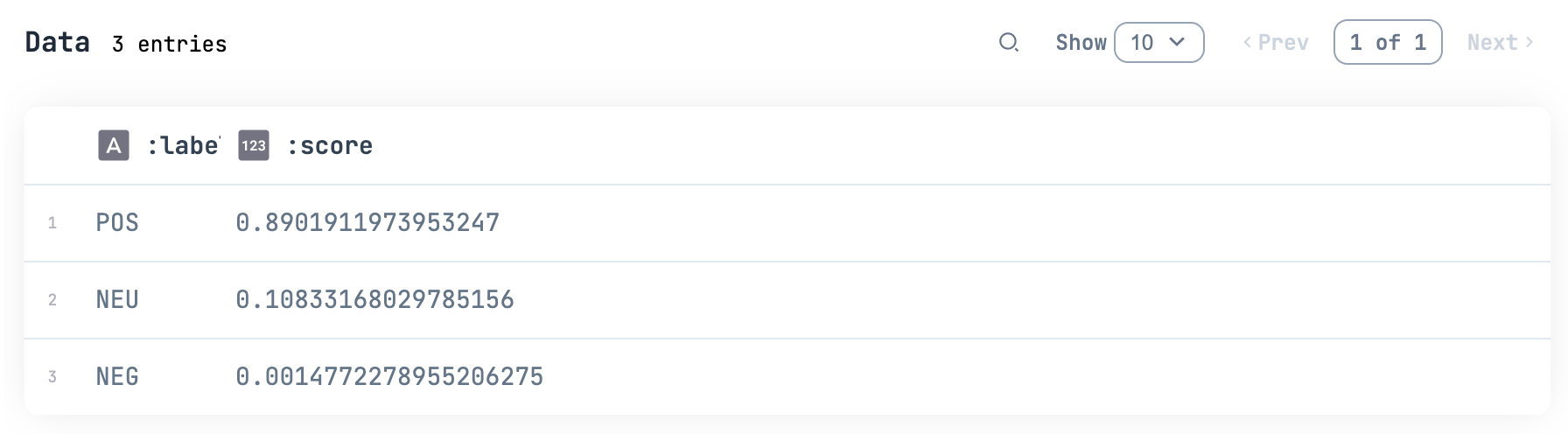
かなりポジティブです
まとめ
もはや Elixir で何でもできてしまいそうです