はじめに
この記事は @the_haigo さんの記事を参考に、
Livebook で Axon を動かしてみた際の感想、備忘録です
実装したコード
実行環境
Elixir で AI をやってみるにあたって、色々試行錯誤するだろうということで、
Docker + Livebook で動かしてみる事にしました
- OS: macOS Monterey 12.4
- Docker: 20.10.16
- Rancher Desktop: 1.4.1
コンテナ定義
参考にした記事では Pytorch の VGG16 を ONNX に変換する際、
Python も使っていたので Jupyter も入れて並列起動させました
Dockerfile
FROM livebook/livebook
# 何かと便利なものたち
# Evision も使いたいので OpenCV 関連
RUN apt upgrade -y \
&& apt update \
&& apt install --no-install-recommends -y \
gnupg2 \
apt-transport-https \
libopencv-dev \
build-essential \
erlang-dev \
software-properties-common \
sudo \
&& apt clean \
&& rm -rf /var/lib/apt/lists/*
# Python3.9 を python 、 pip で使う
RUN apt update \
&& apt install --no-install-recommends -y \
python3.9 \
python3-pip \
&& apt clean \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.9 10 \
&& update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 10
# Python の依存ライブラリたち
RUN pip install --upgrade pip \
&& pip install jupyterlab torch torchvision
ENV HOME=/home/livebook
# Evision はコンパイル済のものを使う(ビルドにすごく時間がかかるので)
ENV EVISION_PREFER_PRECOMPILED=true
WORKDIR /home/livebook
# Elixir の依存ライブラリをインストールするための準備
RUN mix local.hex --force \
&& mix local.rebar --force
# Jupyter と Livebook を並列で起動するシェルスクリプト
COPY ./run_servers.sh /root/run_servers.sh
RUN chmod +x /root/run_servers.sh
# ノートブックは出来上がったものをコンテナ内にコピー
# volumes でマウントすると、 Elixir の依存ライブラリのインストールでエラーになった
COPY ./notebooks /home/livebook/notebooks
CMD ["/root/run_servers.sh"]
run_servers.sh
#!/bin/bash
# 末尾に & を付けると並列実行
/app/bin/livebook start &
jupyter lab --allow-root --ip=0.0.0.0 --no-browser --notebook-dir=/home/livebook &
wait -n
exit $?
docker-compose.yml
---
version: '3.2'
services:
livebook:
build: .
container_name: livebook
ports:
- '8080:8080'
- '8888:8888'
volumes:
- ./data:/data
docker-compose up で起動すれば、
Jupyter と Livebook 両方の URL が表示されます
$ docker-compose up --build
[+] Building 0.2s (14/14) FINISHED
...
[+] Running 1/1
⠿ Container livebook Recreated 0.7s
Attaching to livebook
...
livebook | [C 2022-06-13 08:31:17.012 ServerApp]
livebook |
livebook | To access the server, open this file in a browser:
livebook | file:///home/livebook/.local/share/jupyter/runtime/jpserver-8-open.html
livebook | Or copy and paste one of these URLs:
livebook | http://xxx:8888/lab?token=...
livebook | or http://127.0.0.1:8888/lab?token=...
livebook | [Livebook] Application running at http://localhost:8080/?token=...
Pytorch から ONNX への変換
ここは元記事 https://qiita.com/the_haigo/items/8f5157a185e08f6d6bce#pytorch-onnx-export のままです
出力先だけ /data/vgg16.onnx にしています
ONNX から dets への変換
ここが最大の難所でした
元記事のとおり、 AxonOnnx をインストールして、 import してみましたが、、、
Mix.install([
{:axon_onnx, github: "elixir-nx/axon_onnx"}
])
{model, params} = AxonOnnx.import("/data/vgg16.onnx")
AxonOnnx.import を実行すると、しばらくしてプロセスが kill されてしまい、
処理が実行できませんでした
コンテナに入ってみて
docker exec -it livebook /bin/bash
top コマンドでメモリを確認してみると、
AxonOnnx.import の実行中、明らかにメモリがどんどん使用され、
100% に達するところでプロセスが落ちていました
VGG16 だとメモリ消費はしょうがないのか、、、?
私は macOS で Rancher Desktop を使って Docker を動かしていたので、
Rancher Desktop の設定を変更してみます
変更の手順
-
現在のコンテナを停止する(
docker-compose upしたターミナルで control + c) -
現在のコンテナを削除する
docker-compose down -
Rancher Desktop の Kubernetes Settings から Memory を変更する

-
Rancher Desktop を再起動する
-
コンテナを起動する
docker-compose up
コンテナ内で free や top を実行してメモリの total が変わっていれば OK です
ちょっとずつ増やしていった結果、メモリを 10GB まで増やすと AxonOnnx.import が実行できました
、、、本当にこんなにメモリが必要?
EXLA を使ってみる(ダメでした)
Axon は Nx を使って行列計算しています
そして、 Nx が実際に行列計算を行う際、バックエンドを選択できるようになっています
デフォルトではバイナリバックエンドが使われます
これは Elixir のコードで一生懸命計算するバックエンドです
残念ながらこれは非常に遅く、メモリ効率も悪いです
Python で行列計算を行う際、 Array のまま各要素毎に + や - で演算するようなものです
当然、 Python であれば numpy を使わなければいけません
Nx の場合も、より速くメモリ効率の良いバックエンドを使わなければなりません
というわけで、 EXLA を使ってみます
EXLA は Google XLA という高速演算コンパイラを Nx のバックエンドとして提供してくれます
インストール対象に EXLA を追加します
Mix.install([
{:axon_onnx, github: "elixir-nx/axon_onnx"},
{:exla, "~> 0.2.1"}
])
そして、 EXLA をバックエンドとして使用するように設定します
EXLA.set_as_nx_default([:tpu, :cuda, :rocm, :host])
この状態で実行すると、 メモリ 4GB でも落ちることなく、なおかつ速く変換できました
、、、が、
一見正常終了したように見せて、変換後のモデルを推論に使ってみるとエラーに、、、
もしかしたら私の環境等の問題かもしれませんが、、、
現状では メモリをたっぷり確保してバイナリバックエンドを使うしかなさそうです
Axon による推論
元記事では stb_image を使っていましたが、 OpenCV に慣れ親しんでいるので Evision を使いましょう
推論時はちゃんと動くので、 EXLA を忘れずに入れておきます
Mix.install([
{:download, "~> 0.0.4"},
{:evision, "~> 0.1.0-dev", github: "cocoa-xu/evision", branch: "main"},
{:kino, "~> 0.5.2"},
{:nx, "~> 0.1", [env: :prod, repo: "hexpm", hex: "nx", optional: true]},
{:exla, "~> 0.2.1"},
{:axon, "~> 0.1.0-dev", github: "elixir-nx/axon", branch: "main"}
])
OpenCV として使いたいので、 Evision には OpenCV の別名をつけておきます
alias Evision, as: OpenCV
モデルの読込
dets に変換したモデルを読み込みます
{:ok, params} = :dets.open_file('/data/vgg16.dets')
[{1, {model, params}}] = :dets.lookup(params, 1)
クラス番号とラベルの変換用マップ
ここにある ImageNet のクラス一覧を読み込んで、
クラスの番号とラベルの Map を作っておきます
もっとスマートに書けると思いますが、、、
File.rm("imagenet1000_clsidx_to_labels.txt")
class_list =
Download.from(
"https://gist.githubusercontent.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt"
)
|> elem(1)
class_map =
class_list
|> File.read!()
|> String.split("\n")
|> Enum.reduce(%{}, fn line, acc ->
[class_number, class_name] = String.split(line, ":")
class_number =
class_number
|> String.replace("{", "")
|> String.trim()
|> Integer.parse()
|> elem(0)
class_name =
class_name
|> String.replace("}", "")
|> String.trim()
|> String.replace(", ", "!")
|> String.replace(",", "")
|> String.replace("!", ", ")
|> String.replace("'", "")
acc |> Map.put(class_number, class_name)
end)
こんな感じの Map ができます
%{
912 => "worm fence, snake fence, snake-rail fence, Virginia fence",
326 => "lycaenid, lycaenid butterfly",
33 => "loggerhead, loggerhead turtle, Caretta caretta",
...
}
画像のダウンロード、前処理
いつもの Lenna さんの画像を読み込んで、テンソルにします

File.rm("Lenna_%28test_image%29.png")
lenna =
Download.from("https://upload.wikimedia.org/wikipedia/en/7/7d/Lenna_%28test_image%29.png")
|> elem(1)
mat = OpenCV.imread!(lenna)
tensor =
OpenCV.resize!(mat, [_width = 224, _height = 224])
|> OpenCV.cvtColor!(OpenCV.cv_COLOR_BGR2RGB())
|> OpenCV.Nx.to_nx()
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
|> Nx.transpose()
|> Nx.new_axis(0)
元記事と違うのは以下の箇所です
- Evision の
resizeを使って 224 * 224 にリサイズしています
OpenCV.resize!(mat, [_width = 224, _height = 224])
-
OpenCV だと色が BGR になっているので
cvtColorで RGB に変換していますこの辺りは本当に Python と同じ感覚です
OpenCV.cvtColor!(OpenCV.cv_COLOR_BGR2RGB())
-
Nx.to_nxで Nx で演算できるテンソルに変換しています
OpenCV.Nx.to_nx()
その後は元記事と同じようにモデルに入力するための前処理を実行しています
推論の実行
Axon.predict で推論を実行します
preds =
Axon.predict(model, params, tensor)
|> Nx.flatten()
|> Nx.argsort()
|> Nx.reverse()
|> Nx.slice([0], [5]) # 先頭5件だけ取り出す
|> Nx.to_flat_list()
ここで EXLA をバックエンドに設定し忘れていると、いつまで経っても結果が返ってきません
必ず EXLA をバックエンドに設定しましょう
推論結果のラベル表示
preds には以下のようにクラスの番号が入っています
[452, 434, 808, 515, 431]
クラスの番号では何のことかわからないので、作っておいた class_map を使ってラベルに変換します
preds
|> Enum.map(fn element ->
Map.get(class_map, element)
end)
実行結果はこうなります
["bonnet, poke bonnet", "bath towel", "sombrero", "cowboy hat, ten-gallon hat", "bassinet"]
ボンネットやバスタオル、バシネットはおかしいですが、
ソンブレロやカウボーイハットは妥当な感じです
推論の関数化
画像のダウンロードや推論を一つの関数にまとめます
defmodule Detector do
def detect(image_url, model, params, class_map) do
basename =
image_url
|> URI.parse()
|> Map.fetch!(:path)
|> Path.basename()
File.rm(basename)
mat =
image_url
|> Download.from()
|> elem(1)
|> OpenCV.imread!()
tensor =
OpenCV.resize!(mat, [_width = 224, _height = 224])
|> OpenCV.cvtColor!(OpenCV.cv_COLOR_BGR2RGB())
|> OpenCV.Nx.to_nx()
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
|> Nx.transpose()
|> Nx.new_axis(0)
model
|> Axon.predict(params, tensor)
|> Nx.flatten()
|> Nx.argsort()
|> Nx.reverse()
|> Nx.slice([0], [5])
|> Nx.to_flat_list()
|> Enum.map(fn element ->
Map.get(class_map, element)
|> IO.puts()
end)
Helper.show_image(mat)
end
end
Open Images Dataset から適当な画像を見つけてテストしてみましょう
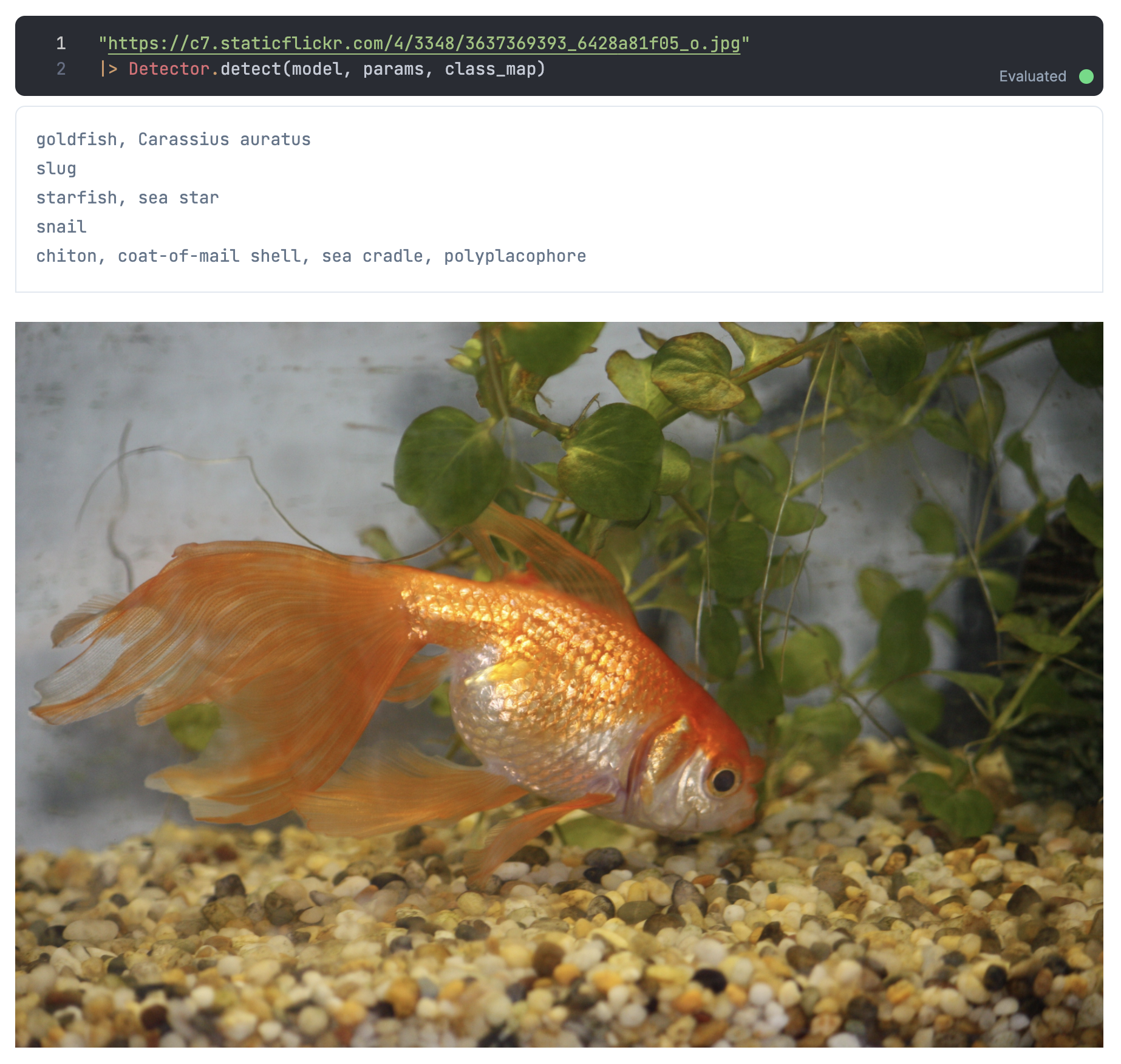

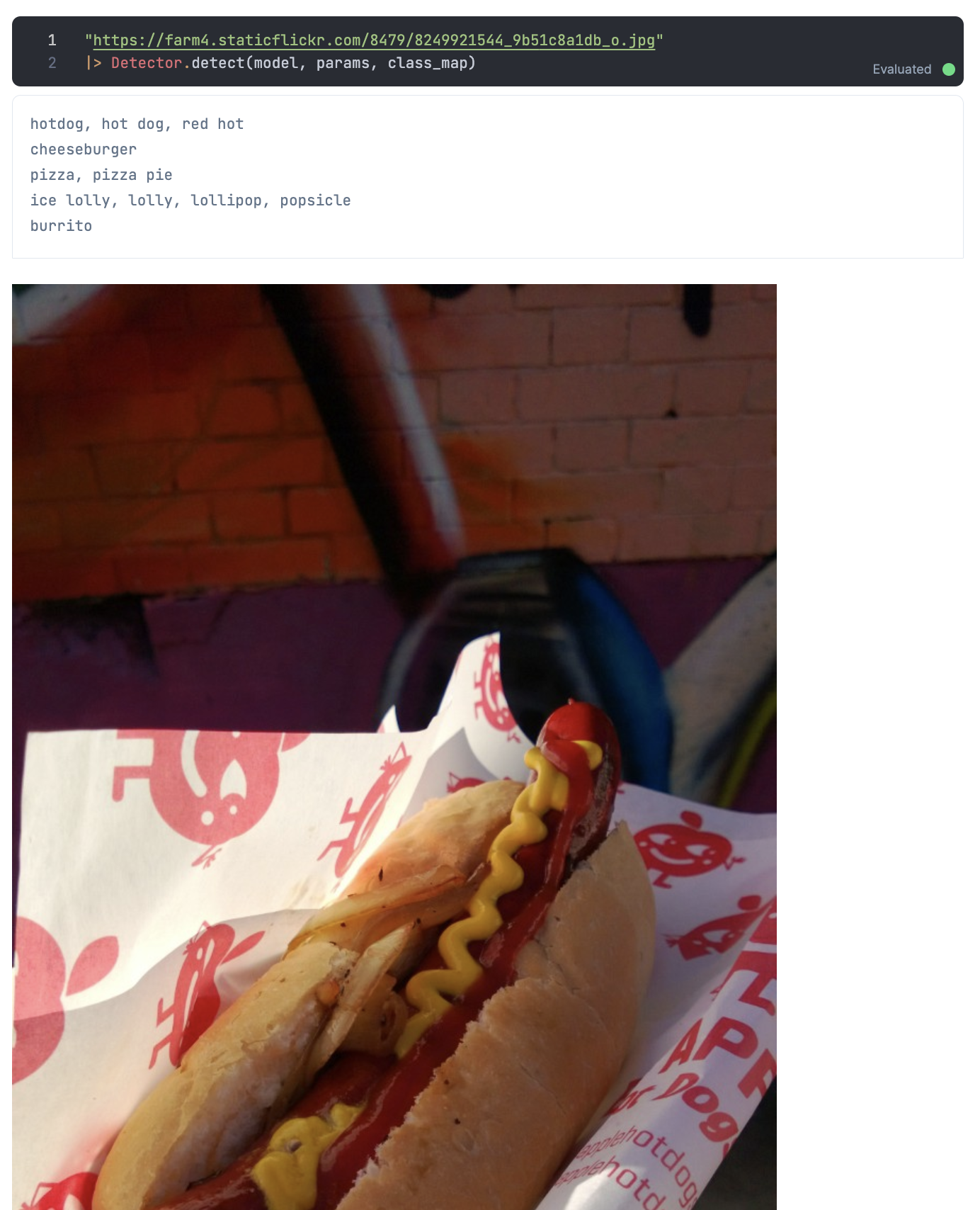

いい感じに検出できているようです
まとめ
Nx を使う場合、バックエンドが重要であることがよく分かりました
EXLA バックエンドで変換がうまくいけば、メモリ問題は解消するのですが、、、
また、やはり Evision を使うと Python のときと同じ感覚で画像処理できるので、
ほとんど実装方法に迷うことがありません
他のモデルも試してみたいと思います