はじめに
2022/12/12 更新
最新版のモジュールを使うように更新しました
どれくらい Qiita の記事がアクセスされたのか、どういう記事の評価が高いのか知りたい!
今回は Elixir Livebook と Explorer 、そして Qiita API を利用して Qiita の投稿記事を分析します
ちなみに、 Livebook は以下のリンクから簡単に macOS 、 Windows にインストールすることができます
Livebook は Jupyter と同じように可視化、コードの共有ができ、
Explorer は pandas と同じようにデータフレームを操作できます
是非、これを機に Livebook でデータ分析をしてみてください
実装したノートブックの全文はこちら
実行環境
以下のリポジトリーの Docker コンテナ上で実行しています
Docker さえあれば簡単に実行できるので是非やってみましょう
アクセストークンの取得
データ分析を実行する前に、 Qiita API で認証するためのアクセストークンを準備する必要があります
Qiita にサインインし、以下の操作を行なってください
- Qiita の右上、ログインユーザーのアイコンをクリック
- 「設定」をクリック
左メニューの「アプリケーション」をクリック
個人用アクセストークンの右「新しくトークンを発行する」をクリック
- 「アクセストークンの説明」に適当な値を入力
- スコープの「read_qiita」にチェック
- 「発行する」をクリック

アクセストークンが表示されるので、このページを表示したままにしておくか、どこか安全な場所にメモしてください

セットアップ
Livebook から新規ノートブックを開きます
以下のコードをセルに入力し、依存パッケージのインストールを実行します
Mix.install([
{:httpoison, "~> 1.8"},
{:json, "~> 1.4"},
{:explorer, "~> 0.4"},
{:kino, "~> 0.8"},
{:kino_vega_lite, "~> 0.1"}
])
トークンの入力エリアを表示します
# Qiita のアクセストークンを入力する
token_input = Kino.Input.password("TOKEN")
表示された入力エリアに先ほど準備した Qiita のアクセストークンを入力します
Qiita API のベース URL を設定します
base_url = "https://qiita.com/api/v2"
この後使うモジュールにエイリアスを設定しておきます
alias Explorer.DataFrame
alias Explorer.Series
alias VegaLite, as: Vl
require Explorer.DataFrame
認証ヘッダーを設定します
auth_header = {"Authorization", "Bearer #{Kino.Input.read(token_input)}"}
"dummy"
記事一覧を取得する
Qiita の記事一覧は以下のようにして取得します
articles =
"#{base_url}/authenticated_user/items"
|> HTTPoison.get!([auth_header])
|> then(&JSON.decode!(&1.body))
件数を確認してみましょう
Enum.count(articles)

私の記事は20件を超えているはずですが、、、
QIita API のドキュメントを確認すると、どうやらページングしないといけないようです
page
ページ番号 (1から100まで)
Example: 1
Type: string
Pattern: /^[0-9]+$/per_page
1ページあたりに含まれる要素数 (1から100まで)
Example: 20
Type: string
Pattern: /^[0-9]+$/
私は 100 記事未満なので per_page に 100 を指定すれば全件取得できますが、
それでは今後行き詰まるので、全ページ取得できるようにします
データが存在しないページを指定したとき空配列 [] が返ってくるため、
[] が返るまでページ番号を 1 ずつ増やしながら API を呼び出すことにしましょう
Elixir には所謂 while のような構文が存在しないため、再帰呼び出しで実装しました
もっとスマートな解決方法がある場合は是非教えてください
defmodule Qiita do
@moduledoc """
Qiita API を呼び出す
"""
@base_url "https://qiita.com/api/v2"
@doc """
1ページ分の記事一覧を取得する
## パラメータ
- page: ページ番号
- auth_header: 認証ヘッダー
"""
@spec get_articles(integer, tuple) :: list
def get_articles(page, auth_header) do
"#{@base_url}/authenticated_user/items?page=#{page}"
|> HTTPoison.get!([auth_header])
|> then(&JSON.decode!(&1.body))
end
@doc """
再帰的に記事一覧を取得する
## パラメータ
- page: ページ番号
- auth_header: 認証ヘッダー
"""
@spec get_articles_cyclic(integer, tuple) :: list
def get_articles_cyclic(page, auth_header) do
IO.inspect("get page #{page}")
articles = get_articles(page, auth_header)
case articles do
# 空であれば次ページを取得しない
[] ->
IO.inspect("stop")
articles
# 空以外の場合は次ページを取得する
_ ->
articles ++ get_articles_cyclic(page + 1, auth_header)
end
end
@doc """
記事一覧を全件取得する
## パラメータ
- page: ページ番号
- auth_header: 認証ヘッダー
"""
@spec get_all_articles(tuple) :: list
def get_all_articles(auth_header) do
get_articles_cyclic(1, auth_header)
end
end
全件取得を呼び出してみましょう
# 全件取得
all_articles = Qiita.get_all_articles(auth_header)
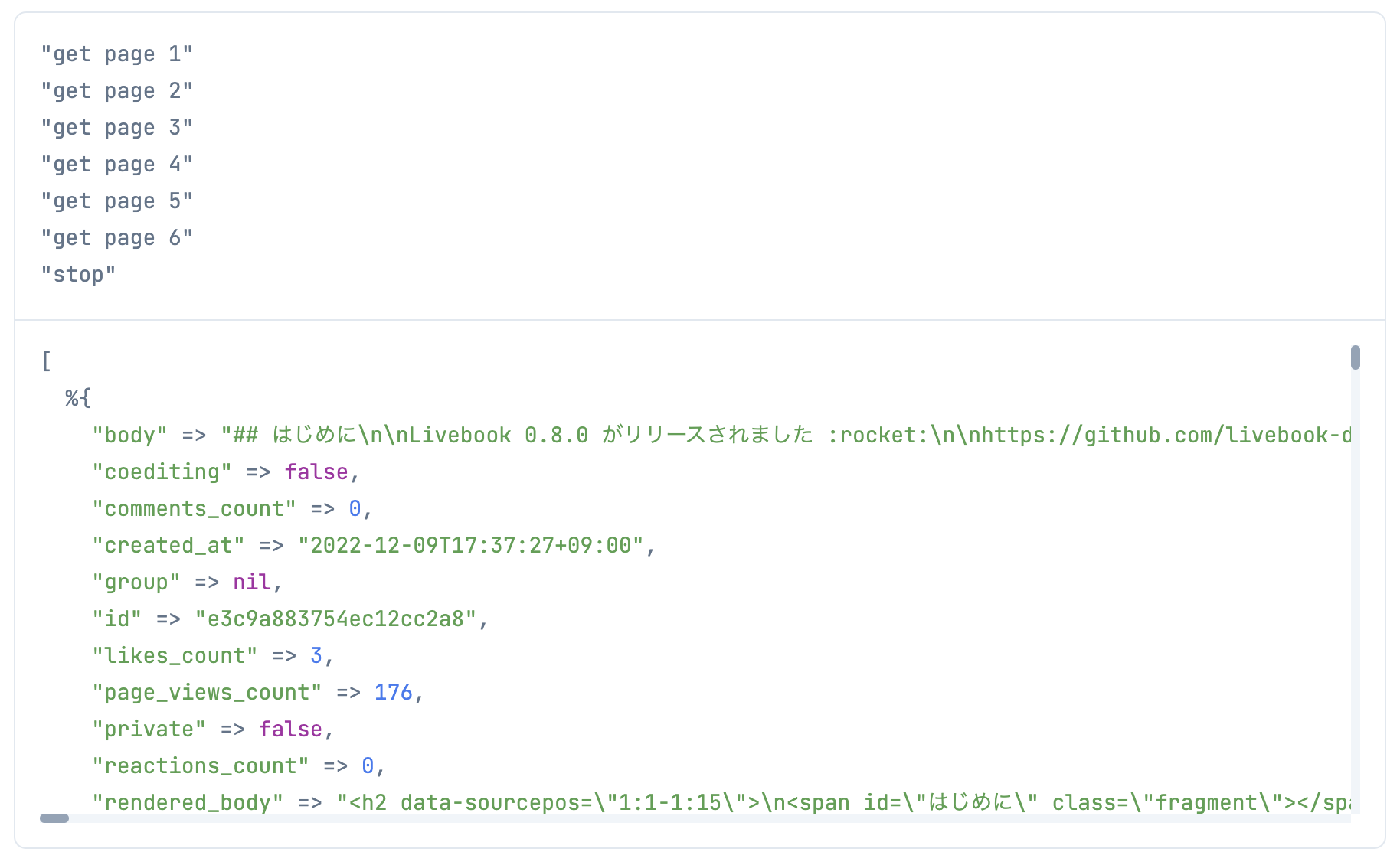
再帰処理が分かりやすいように仕込んでいた IO.inspect により、
7回目の呼び出しで [] が API から返ってきて、再帰処理が停止したことが分かります
件数を確認してみましょう
Enum.count(all_articles)

確かに全件取得できたようです
記事一覧をデータフレーム化する
qiita_df =
all_articles
|> Enum.map(fn item ->
%{
"title" => item["title"],
# 限定公開フラグ
"private" => item["private"],
# 作成日 日付は NaiveDateTime に変換する
"created_at" => NaiveDateTime.from_iso8601!(item["created_at"]),
# 閲覧数
"page_views_count" => item["page_views_count"],
# いいね数
"likes_count" => item["likes_count"],
# いいね率 = いいね数 / 閲覧数
"likes_rate" => item["likes_count"] / item["page_views_count"],
# ストック数
"stocks_count" => item["stocks_count"],
# ストック率 = ストック数 / 閲覧数
"stocks_rate" => item["stocks_count"] / item["page_views_count"],
# タグ 複数のため、 `、` で結合する
"tags" => item["tags"] |> Enum.map(& &1["name"]) |> Enum.join(","),
# 記事の長さ(文字数)
"length" => item["body"] |> String.length()
}
end)
|> DataFrame.new()
|> DataFrame.select([
"title",
"private",
"created_at",
"page_views_count",
"likes_count",
"likes_rate",
"stocks_count",
"stocks_rate",
"tags",
"length"
])
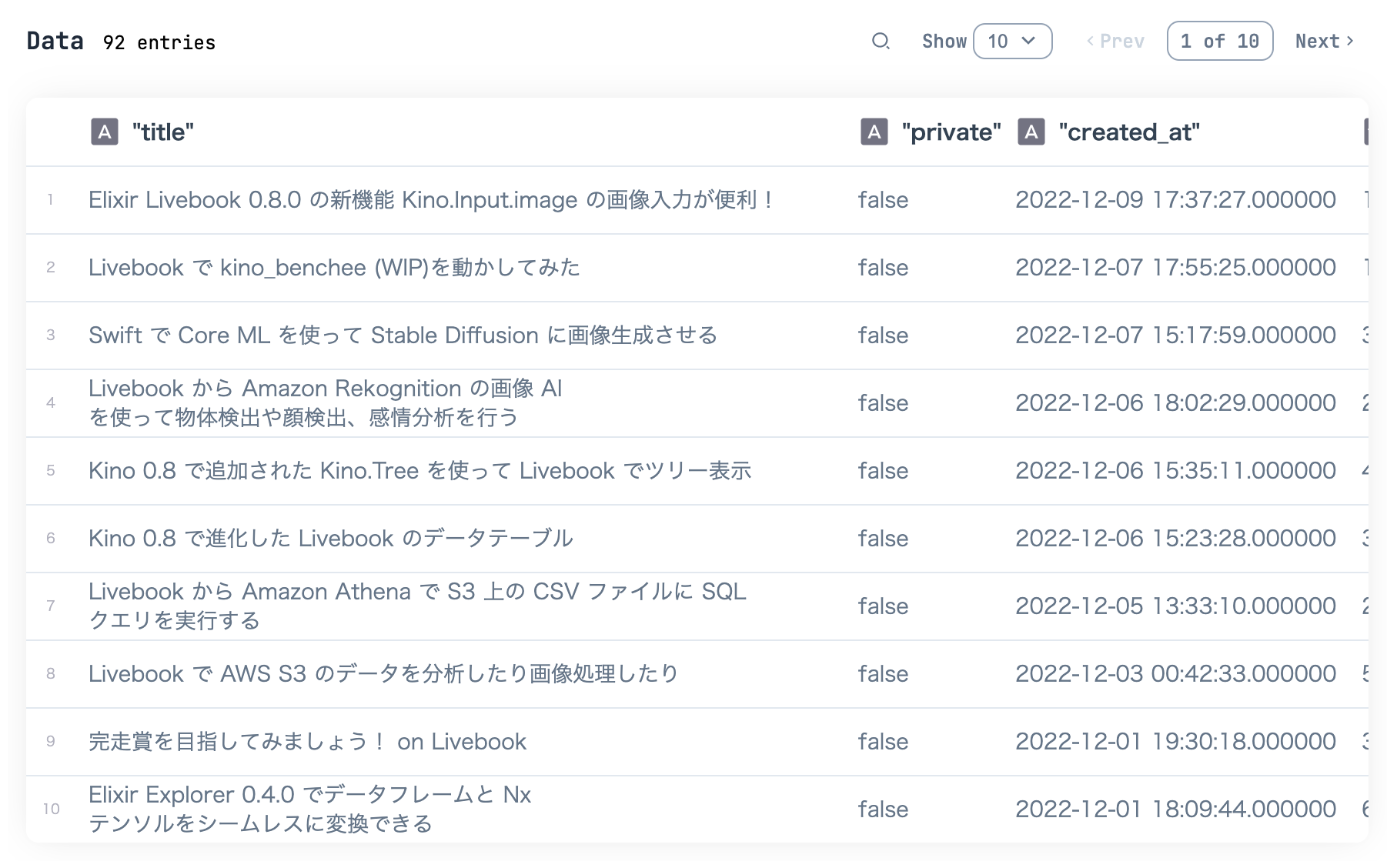
qiita_df
|> Kino.DataTable.new(sorting_enabled: true)
記事一覧を分析する
閲覧数、いいね数、ストック数の合計値、平均値、最大値、最小値を算出してみましょう
qiita_df
|> DataFrame.group_by(["private"])
|> DataFrame.summarise(
page_views_count_sum: sum(page_views_count),
page_views_count_mean: mean(page_views_count),
page_views_count_max: max(page_views_count),
page_views_count_min: min(page_views_count),
likes_count_sum: sum(likes_count),
likes_count_mean: mean(likes_count),
likes_count_max: max(likes_count),
likes_count_min: min(likes_count),
stocks_count_sum: sum(stocks_count),
stocks_count_mean: mean(stocks_count),
stocks_count_max: max(stocks_count),
stocks_count_min: min(stocks_count)
)
|> DataFrame.filter(private == false)
|> DataFrame.to_columns()
|> Map.drop(["private"])
|> dbg()
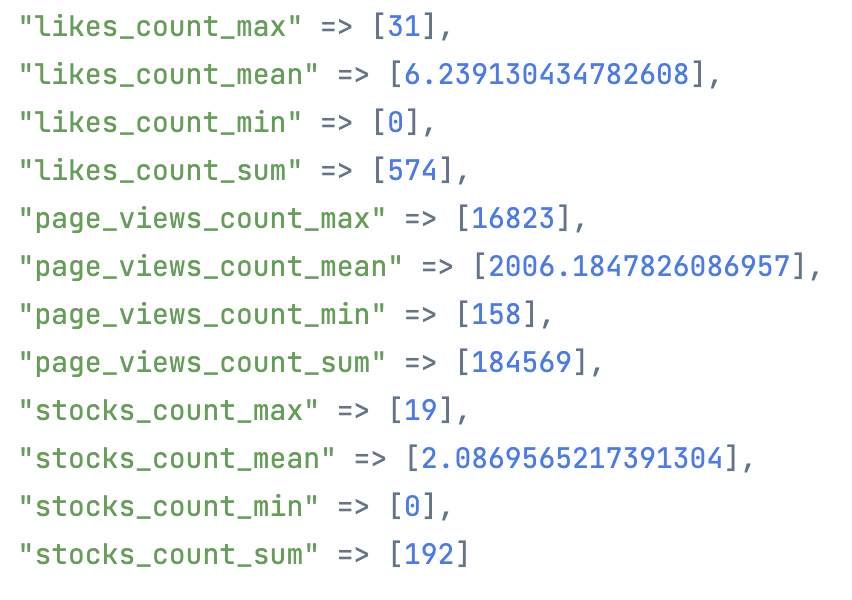
合計閲覧数は 184,569 ということで、 18 万件を超えていました
平均閲覧数でも 2,006 なので結構閲覧されています(私としては)
いいね数の合計は 574 、 ストック数の合計は 192
個人的にはいい数値だと思います
では、最大閲覧数を取得した記事はなんでしょうか
qiita_df
|> DataFrame.arrange(desc: page_views_count)
|> DataFrame.select(["title", "page_views_count", "likes_count", "stocks_count"])
|> Kino.DataTable.new()
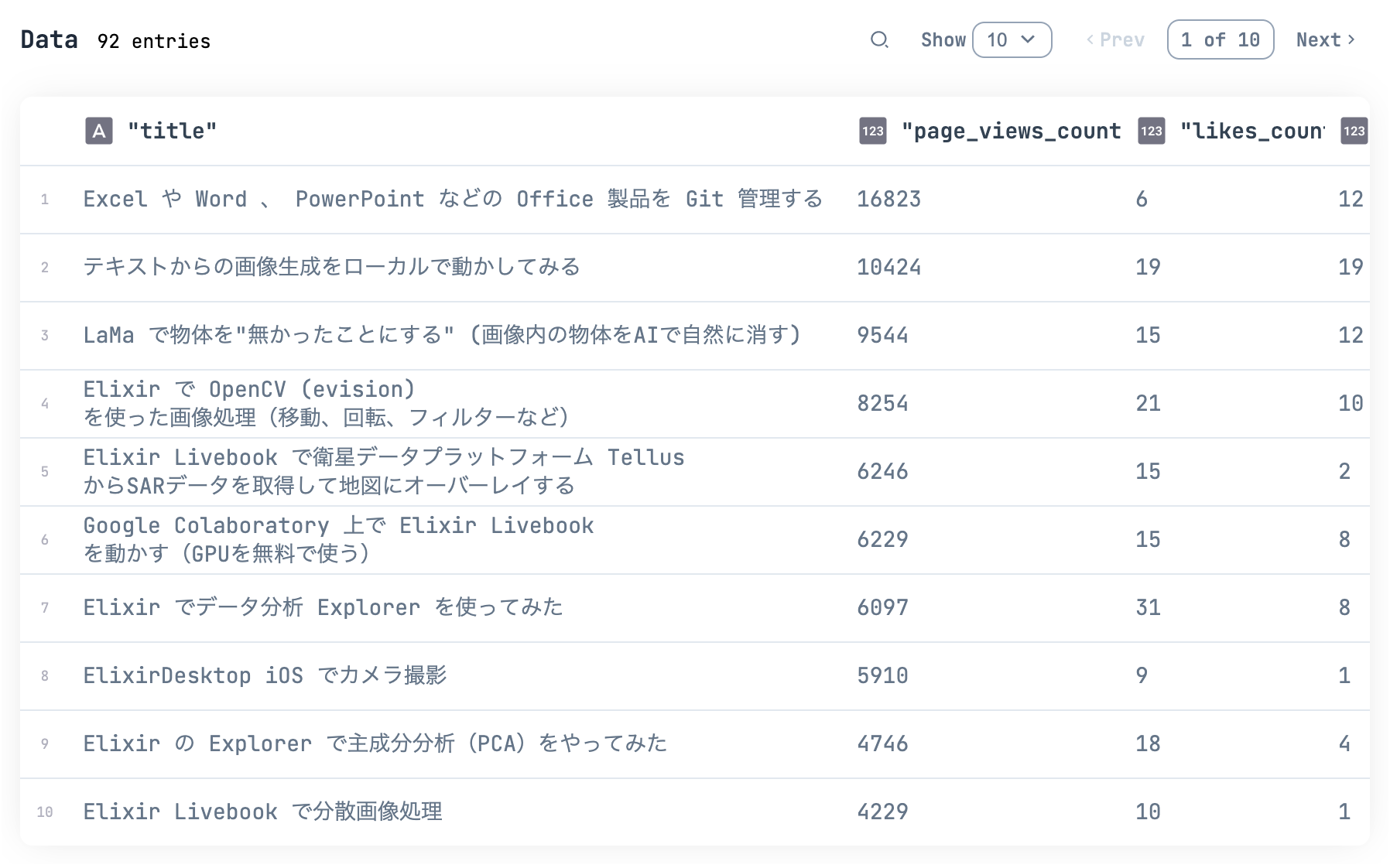
最大閲覧数は以下の記事でした
なんだかんだ Office 製品ユーザーは多く、かつ Git でどう変更管理しようか困っている人が多いようです
また、 AI 系の記事はやはり人気があるみたいですね
続いて最大いいね数です
qiita_df
|> DataFrame.arrange(desc: likes_count)
|> DataFrame.select(["title", "likes_count", "page_views_count", "stocks_count"])
|> Kino.DataTable.new()
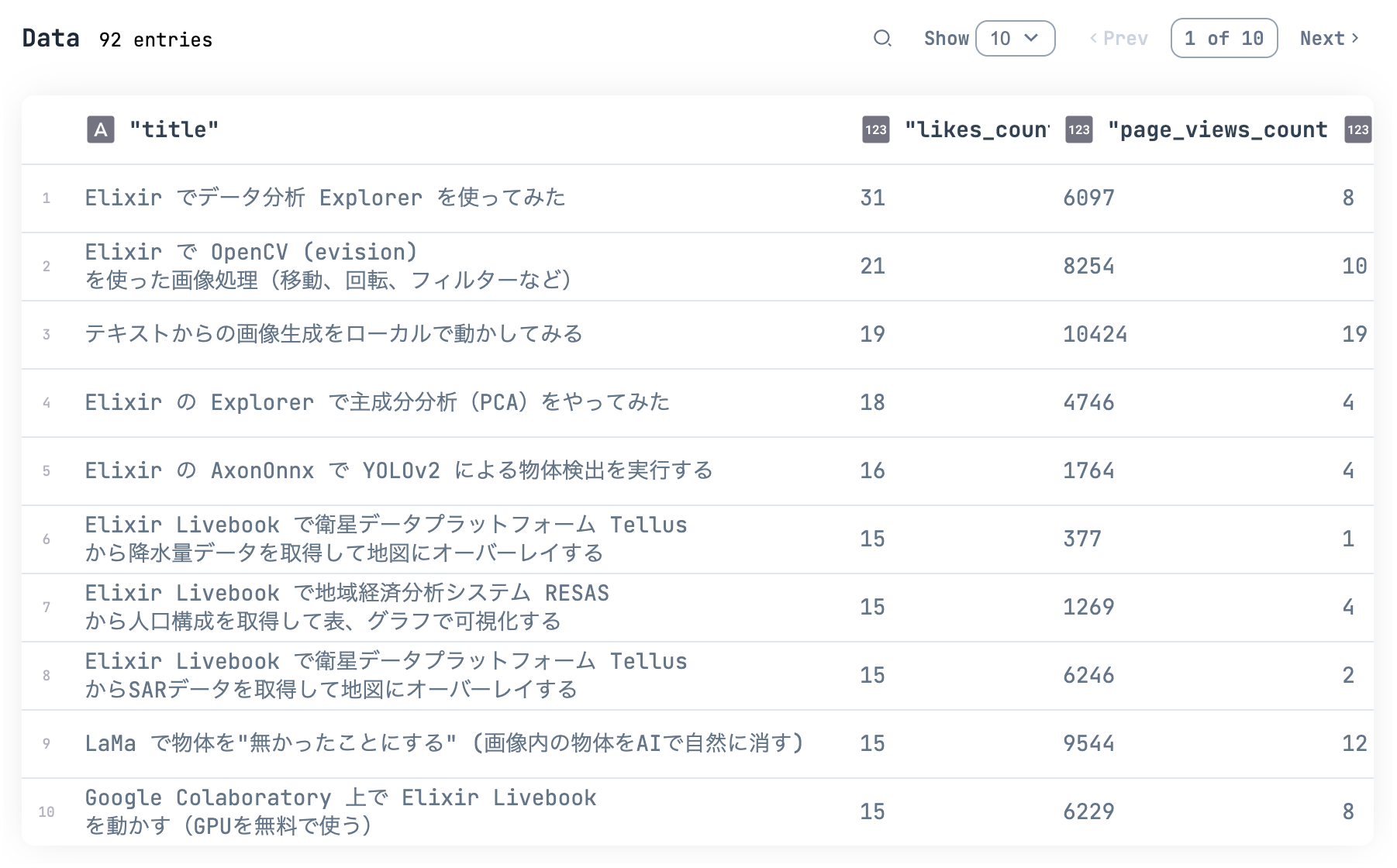
最大いいね数は以下の記事でした
Elixir コミュニティの繋がりを感じますね
また、やはりこちらでも AI 系の人気の高さが窺えます
最大ストック数を見てみましょう
qiita_df
|> DataFrame.arrange(desc: stocks_count)
|> DataFrame.select(["title", "stocks_count", "likes_count", "page_views_count"])
|> Kino.DataTable.new()
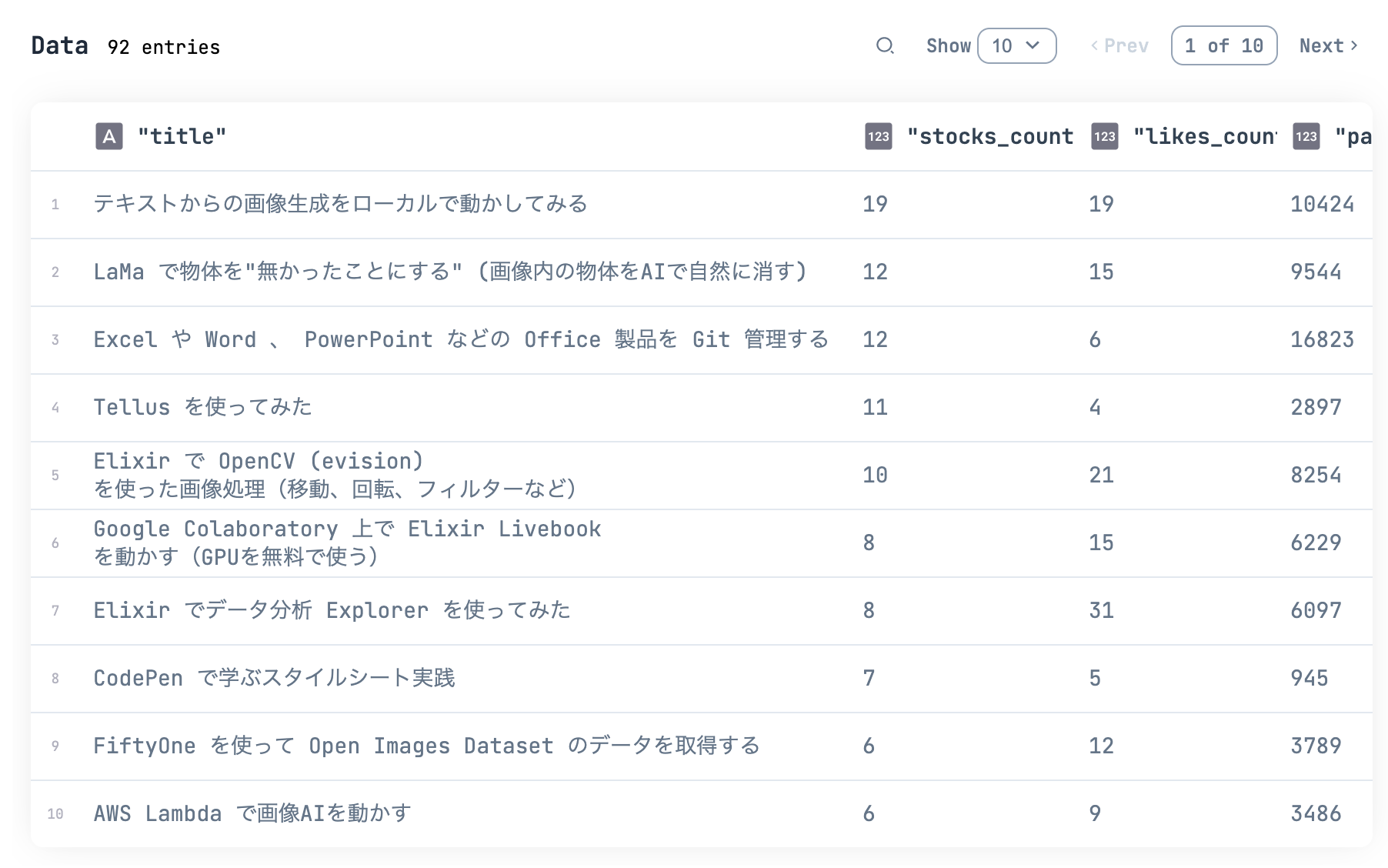
最大ストック数はこちらの記事でした
やはり AI 系はみんな自分で試したくなるようですね
グラフ化する
VegaLite を使ってグラフ化してみましょう
データを DataFrame から取得する関数を定義します
get_values = fn df, col ->
df
|> DataFrame.pull(col)
|> Series.to_list()
end
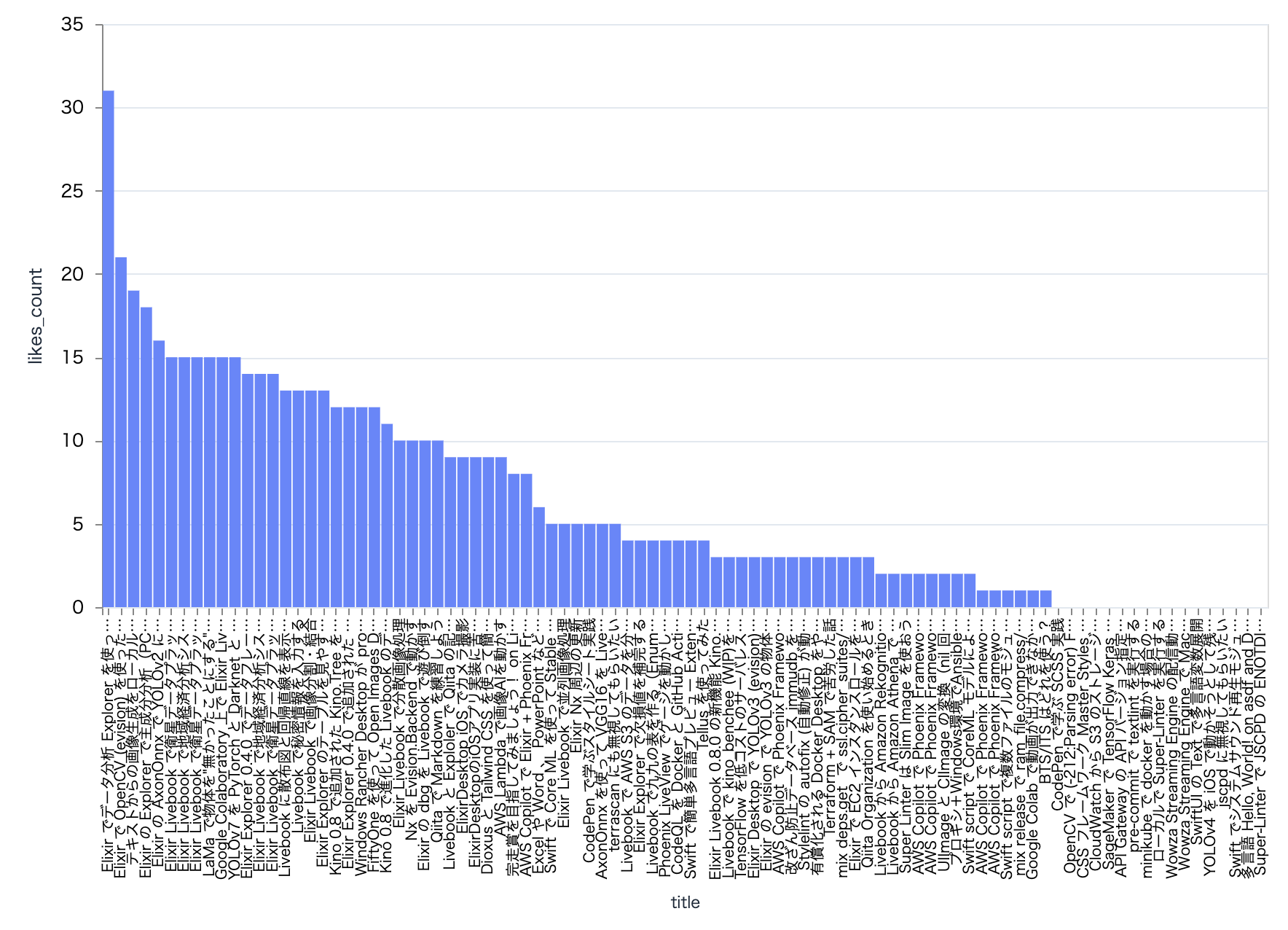
記事毎の閲覧数をグラフ化してみます
x = get_values.(qiita_df, "title")
y = get_values.(qiita_df, "page_views_count")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:bar)
|> Vl.encode_field(
:x,
"x",
type: :nominal,
title: "title",
# 閲覧数の降順に並べる
sort: %{"field" => "y", "order" => "descending"}
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "page_views_count"
)
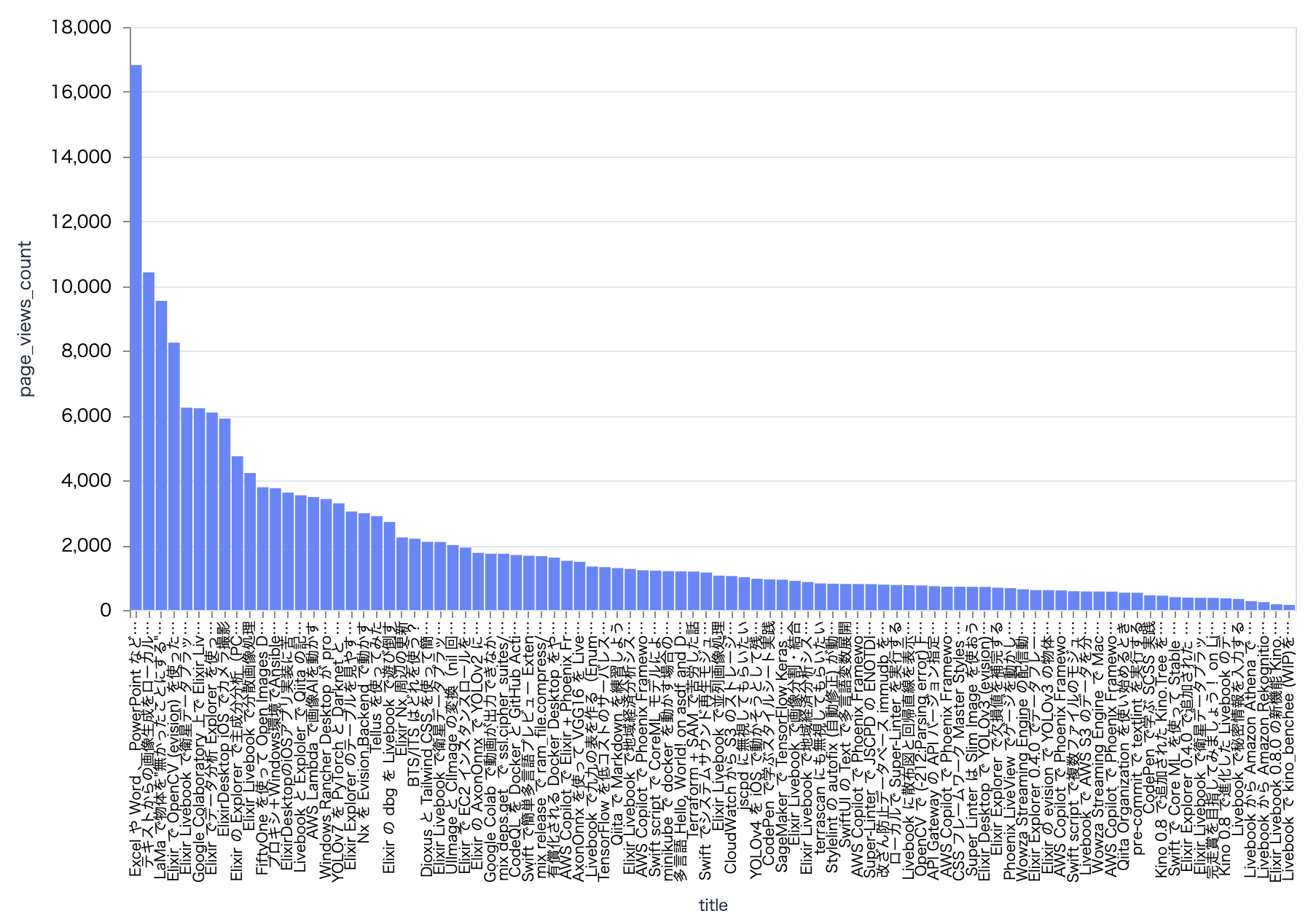
見事にポアソン分布っぽい
たまたま人気が出ることもあるが、大抵は低い閲覧数、ということが分かりますね
いいね数でも大体同じ傾向です
x = get_values.(qiita_df, "title")
y = get_values.(qiita_df, "likes_count")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:bar)
|> Vl.encode_field(
:x,
"x",
type: :nominal,
title: "title",
sort: %{"field" => "y", "order" => "descending"}
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "likes_count"
)
時系列で閲覧数を見てみましょう
x = get_values.(qiita_df, "created_at")
y = get_values.(qiita_df, "page_views_count")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:line)
|> Vl.encode_field(
:x,
"x",
type: :temporal,
title: "created_at"
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "page_views_count"
)
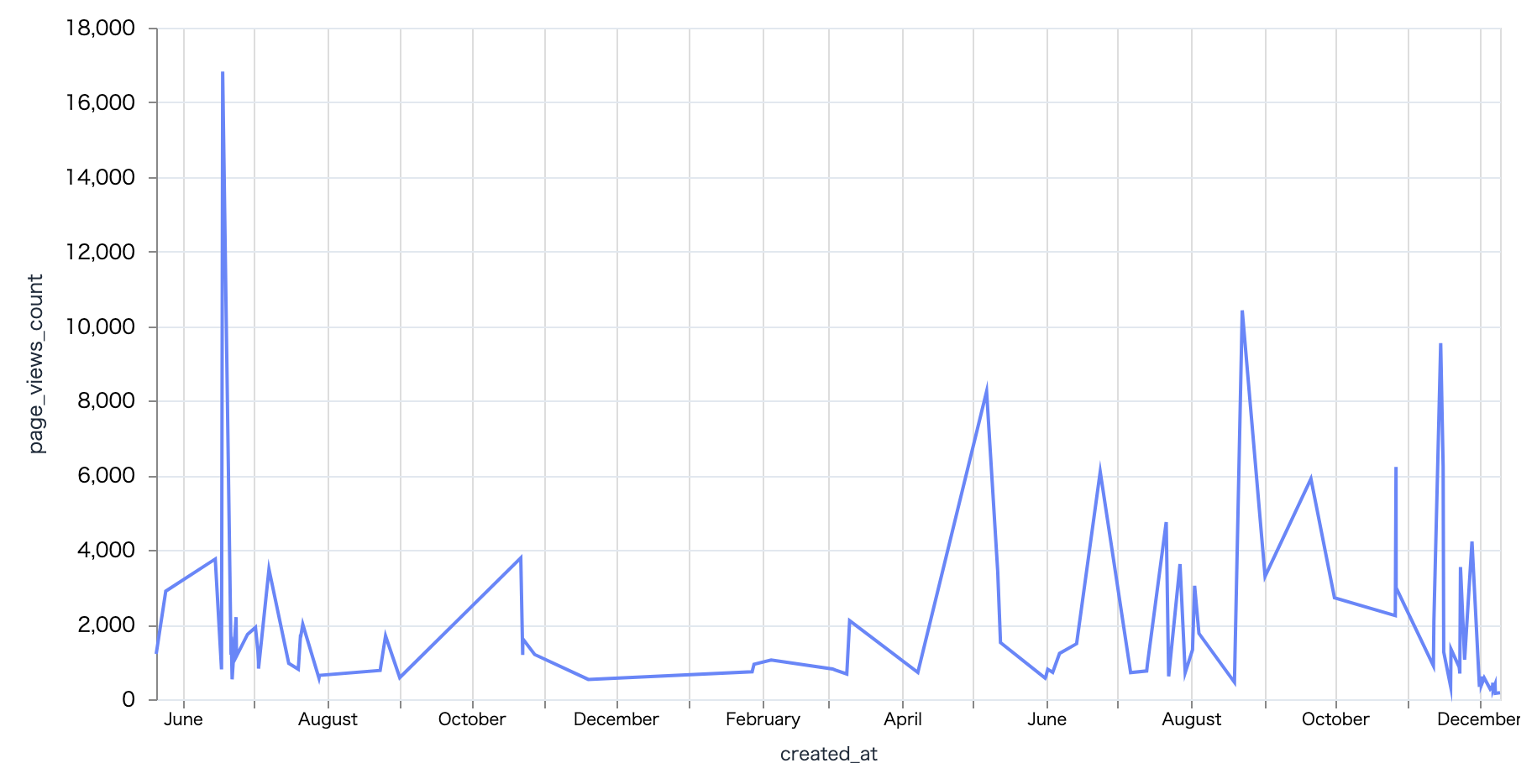
昔の方が多く見られていた、とか、最近の方が閲覧数は増えている、とかいうような傾向は全くみられませんね
記事の長さ(文字数)とスタック数に関連がありそうかを見てみましょう
x = get_values.(qiita_df, "length")
y = get_values.(qiita_df, "stocks_count")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:point)
|> Vl.encode_field(
:x,
"x",
type: :quantitative,
title: "length"
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "likes_count"
)
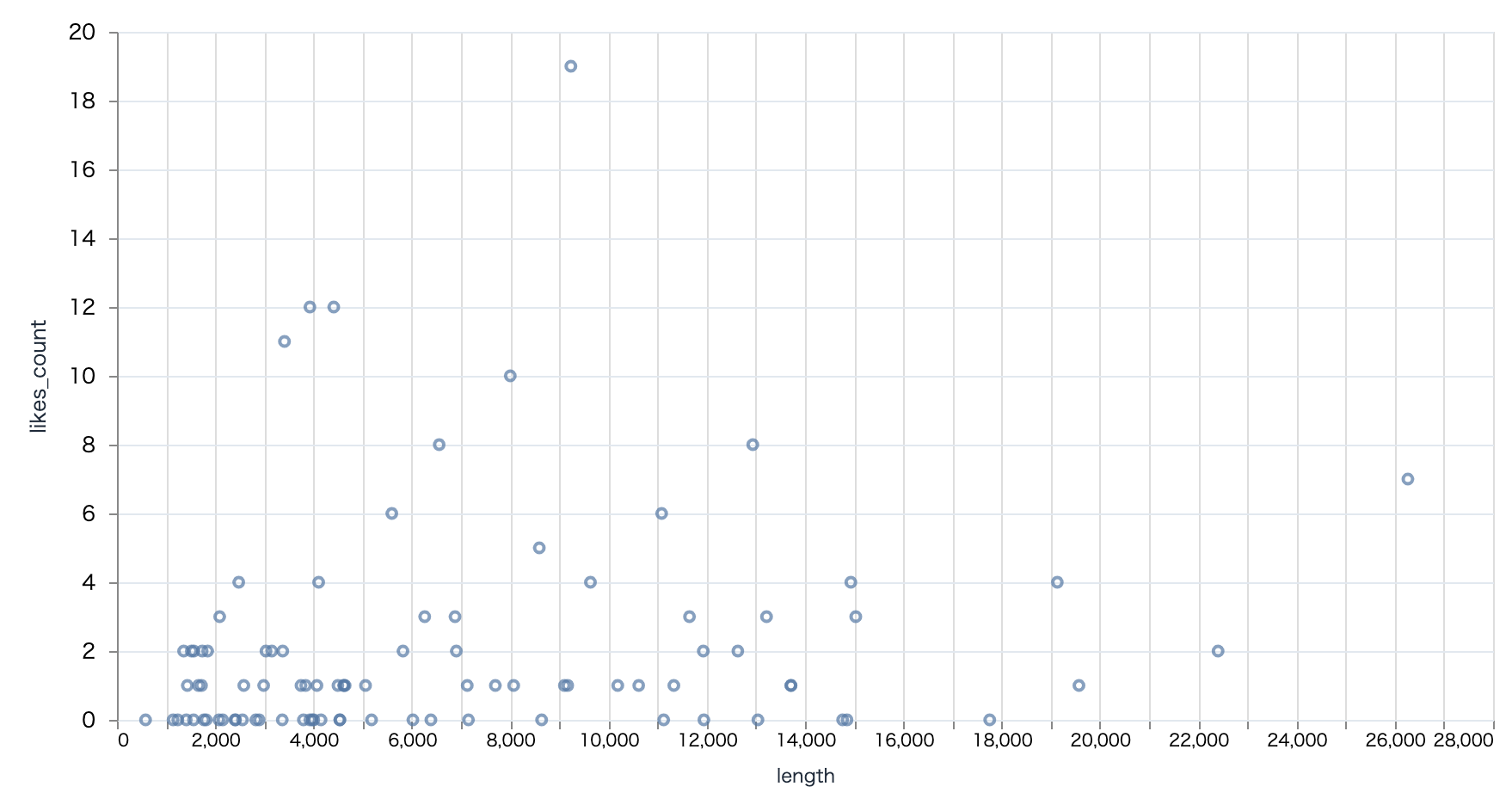
サンプル数が少ないので微妙ではありますが、文字数が多ければスタックされやすい、というわけでもなさそうですね
タグを分析する
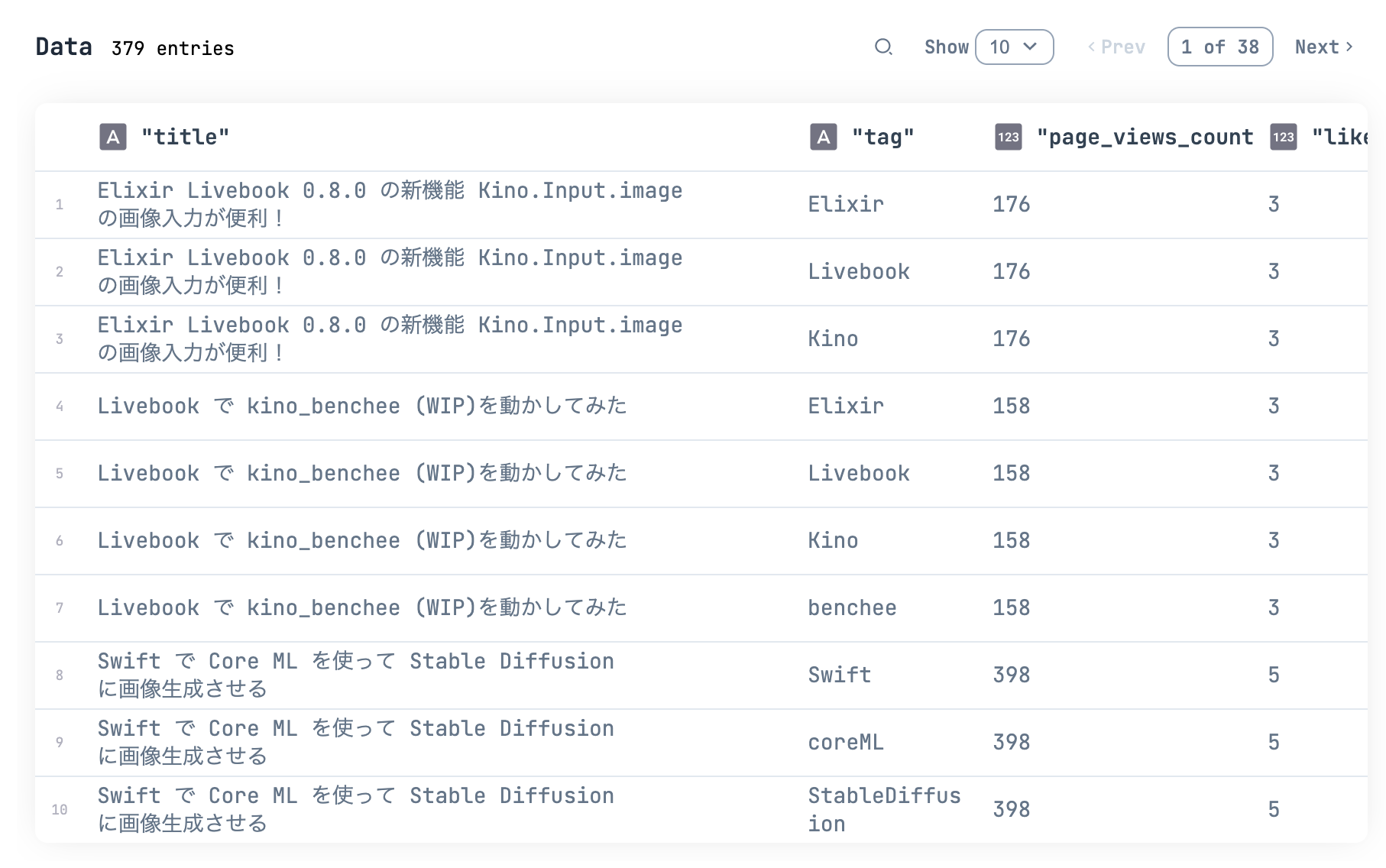
タグ毎のデータの傾向を見たいので、データをタグ単位に変更します
qiita_tag_df =
all_articles
|> Enum.flat_map(fn item ->
item["tags"]
|> Enum.map(fn tag ->
%{
"tag" => tag["name"],
"title" => item["title"],
"page_views_count" => item["page_views_count"],
"likes_count" => item["likes_count"],
"stocks_count" => item["stocks_count"]
}
end)
end)
|> DataFrame.new()
|> DataFrame.select(["title", "tag", "page_views_count", "likes_count", "stocks_count"])
qiita_tag_df
|> Kino.DataTable.new(sorting_enabled: true)
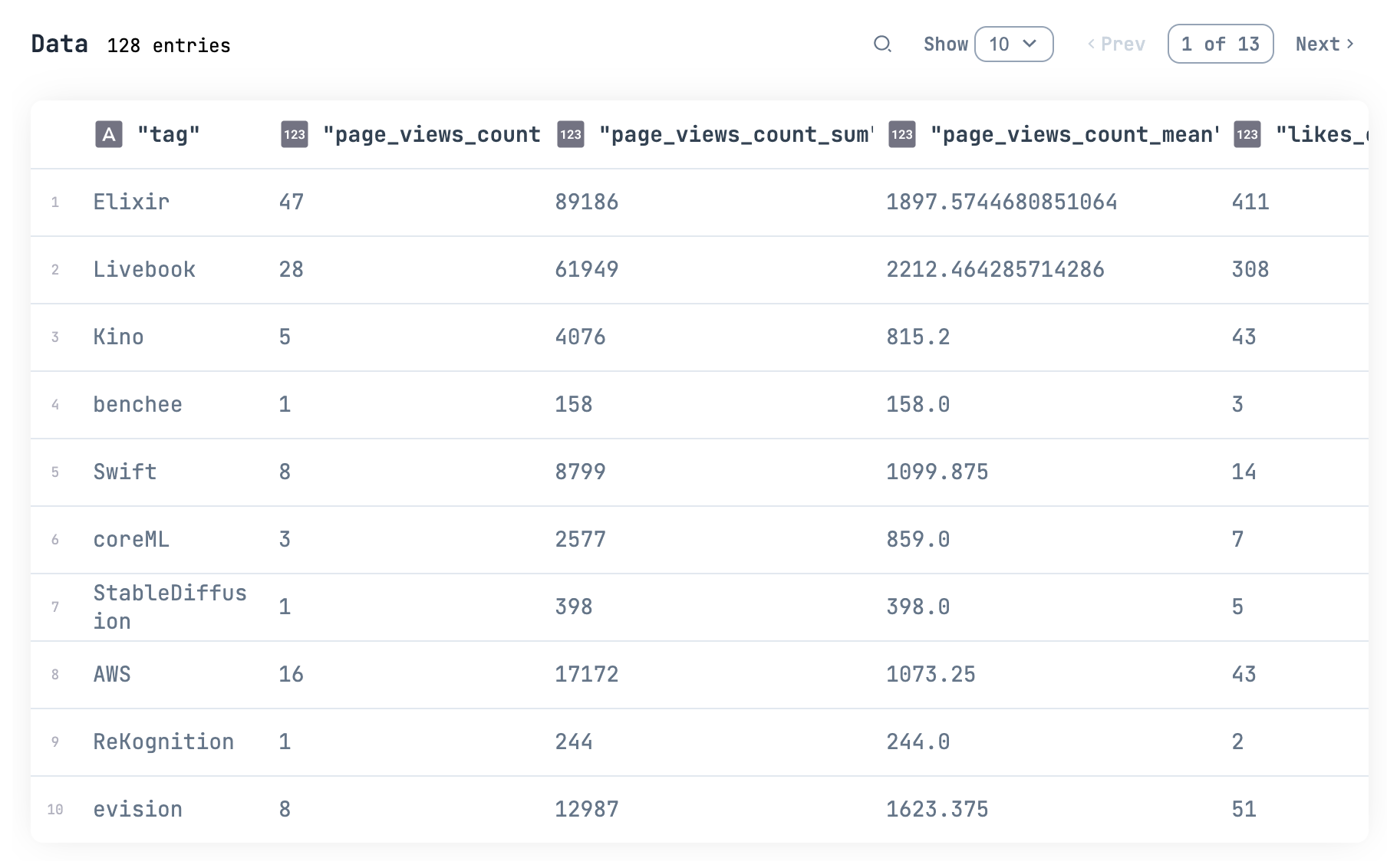
タグ毎に集計してみましょう
qiita_tag_summarised_df =
qiita_tag_df
|> DataFrame.group_by(["tag"])
|> DataFrame.summarise(
page_views_count: count(page_views_count),
page_views_count_sum: sum(page_views_count),
page_views_count_mean: mean(page_views_count),
likes_count_sum: sum(likes_count),
likes_count_mean: mean(likes_count),
stocks_count_sum: sum(stocks_count),
stocks_count_mean: mean(stocks_count)
)
qiita_tag_summarised_df
|> Kino.DataTable.new()
タグ毎の投稿数をグラフ化してみます
x = get_values.(qiita_tag_summarised_df, "tag")
y = get_values.(qiita_tag_summarised_df, "page_views_count")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:bar)
|> Vl.encode_field(
:x,
"x",
type: :nominal,
title: "tag",
sort: %{"field" => "y", "order" => "descending"}
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "count"
)
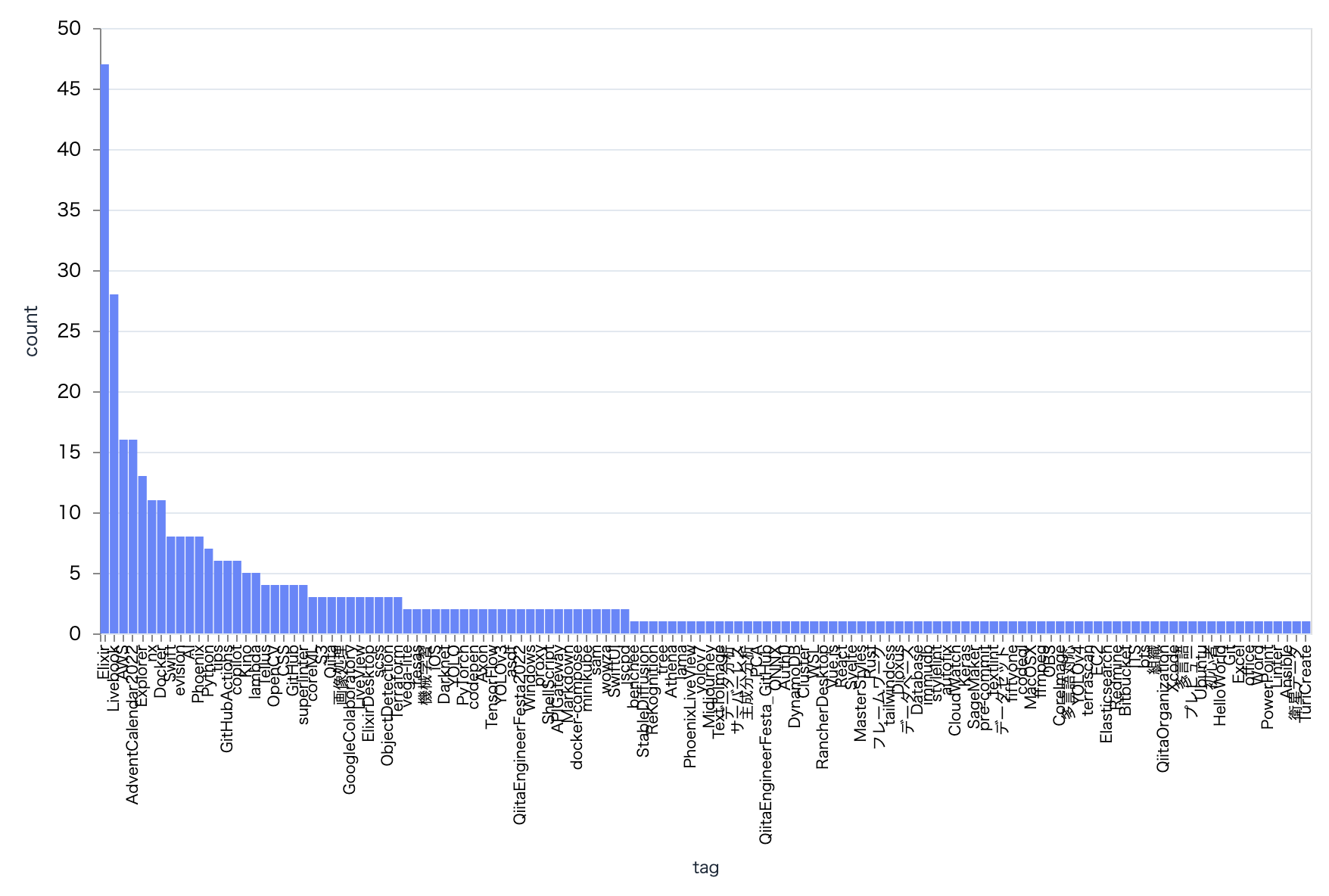
明らかに Elixir に偏っていますね
色々な集計値について見てみたいので、グラフ表示を関数化します
plot_tag_bar = fn col, agg ->
x = get_values.(qiita_tag_summarised_df, "tag")
y = get_values.(qiita_tag_summarised_df, "#{col}_#{agg}")
Vl.new(width: 800, height: 400)
|> Vl.data_from_values(x: x, y: y)
|> Vl.mark(:bar)
|> Vl.encode_field(
:x,
"x",
type: :nominal,
title: "tag",
sort: %{"field" => "y", "order" => "descending"}
)
|> Vl.encode_field(
:y,
"y",
type: :quantitative,
title: "#{col}_#{agg}"
)
end
タグ毎の合計閲覧数です
plot_tag_bar.("page_views_count", "sum")
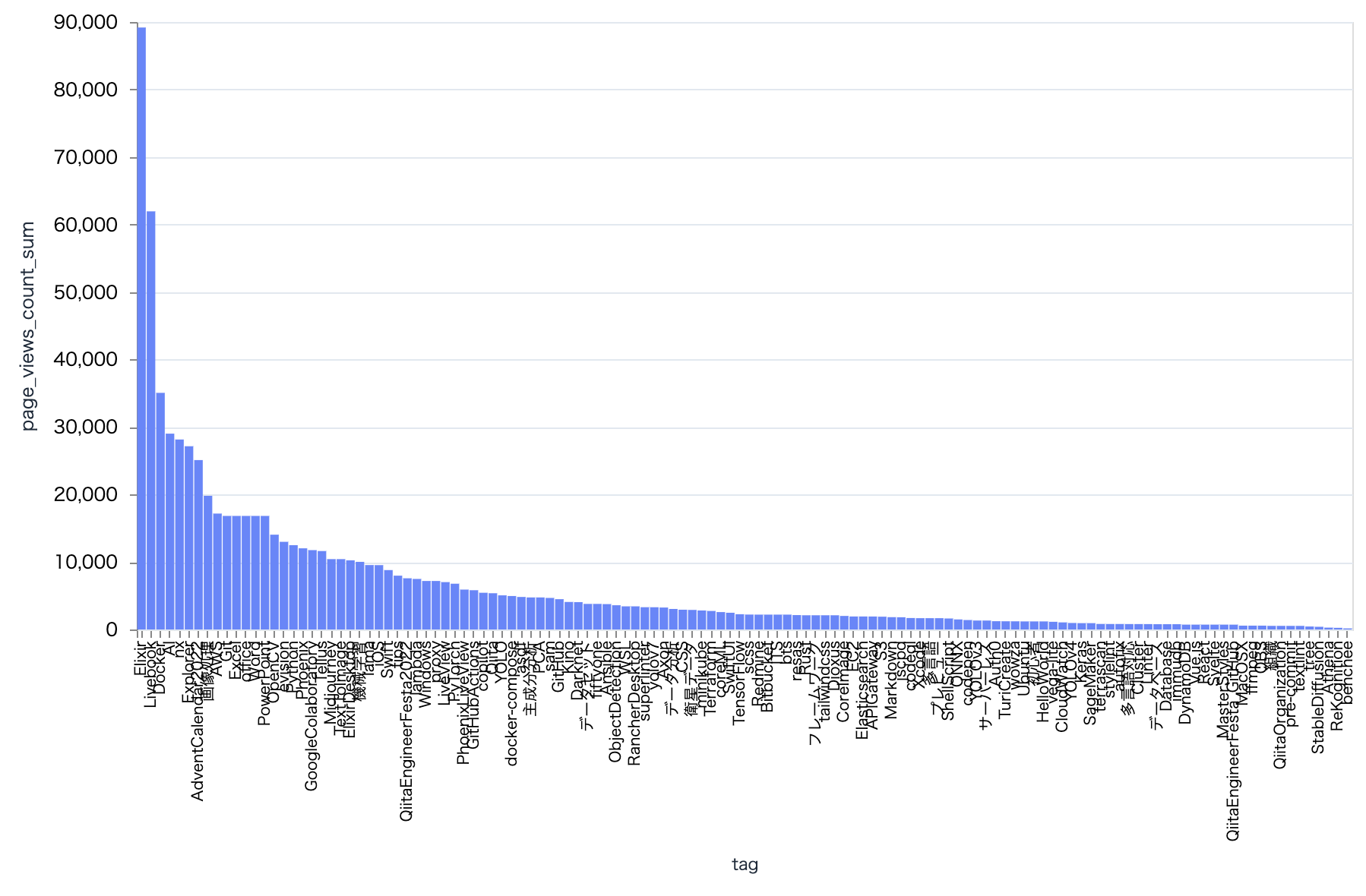
当然投稿数が多いので、 Elixir がトップです
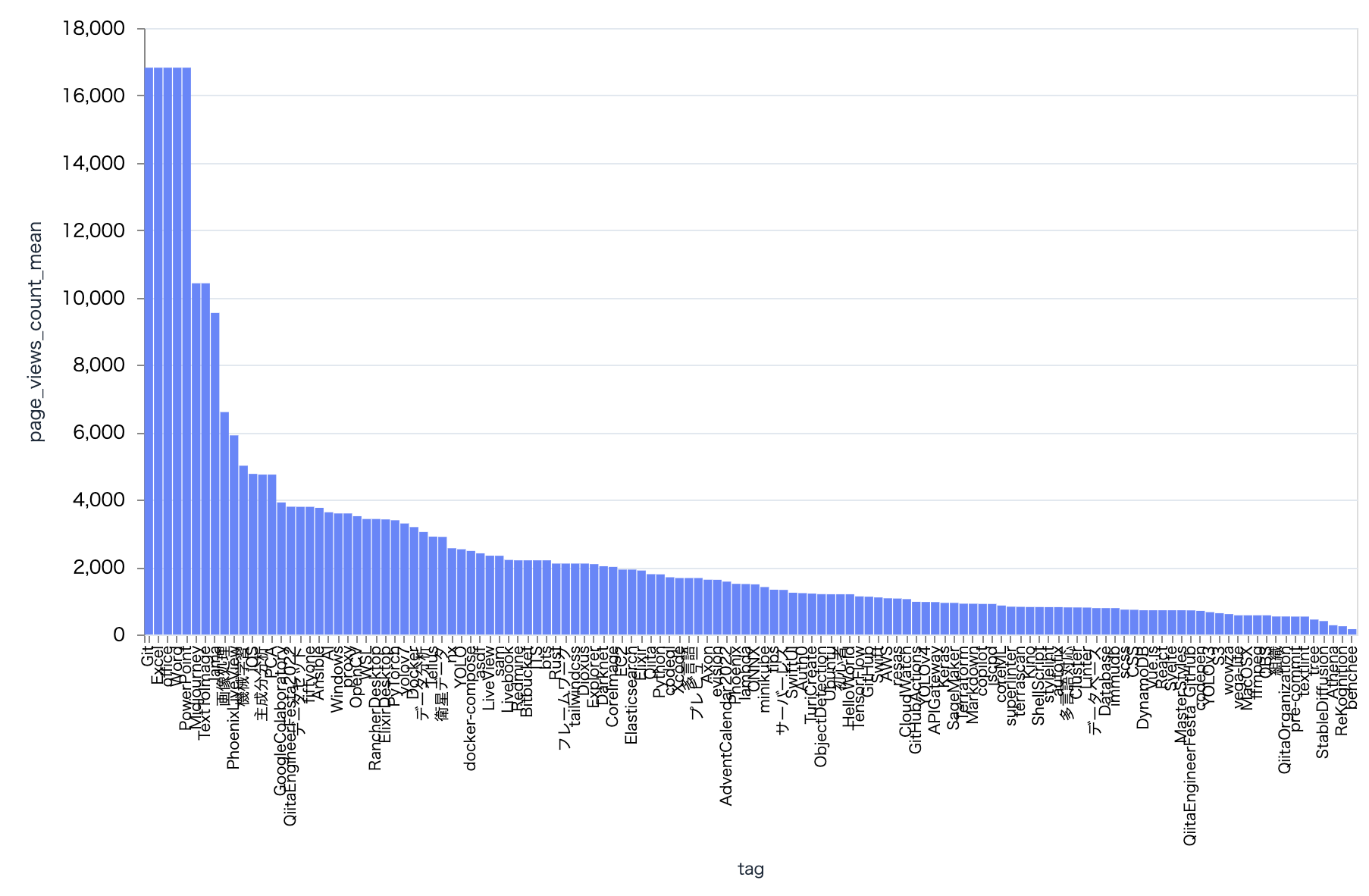
では、タグ毎の平均閲覧数にしてみましょう
plot_tag_bar.("page_views_count", "mean")
そうすると、1回しか付けていないのに閲覧数トップの記事に付いていた Git や Excel が上位を占めます
いいね数も合計は Elixir が首位
plot_tag_bar.("likes_count", "sum")
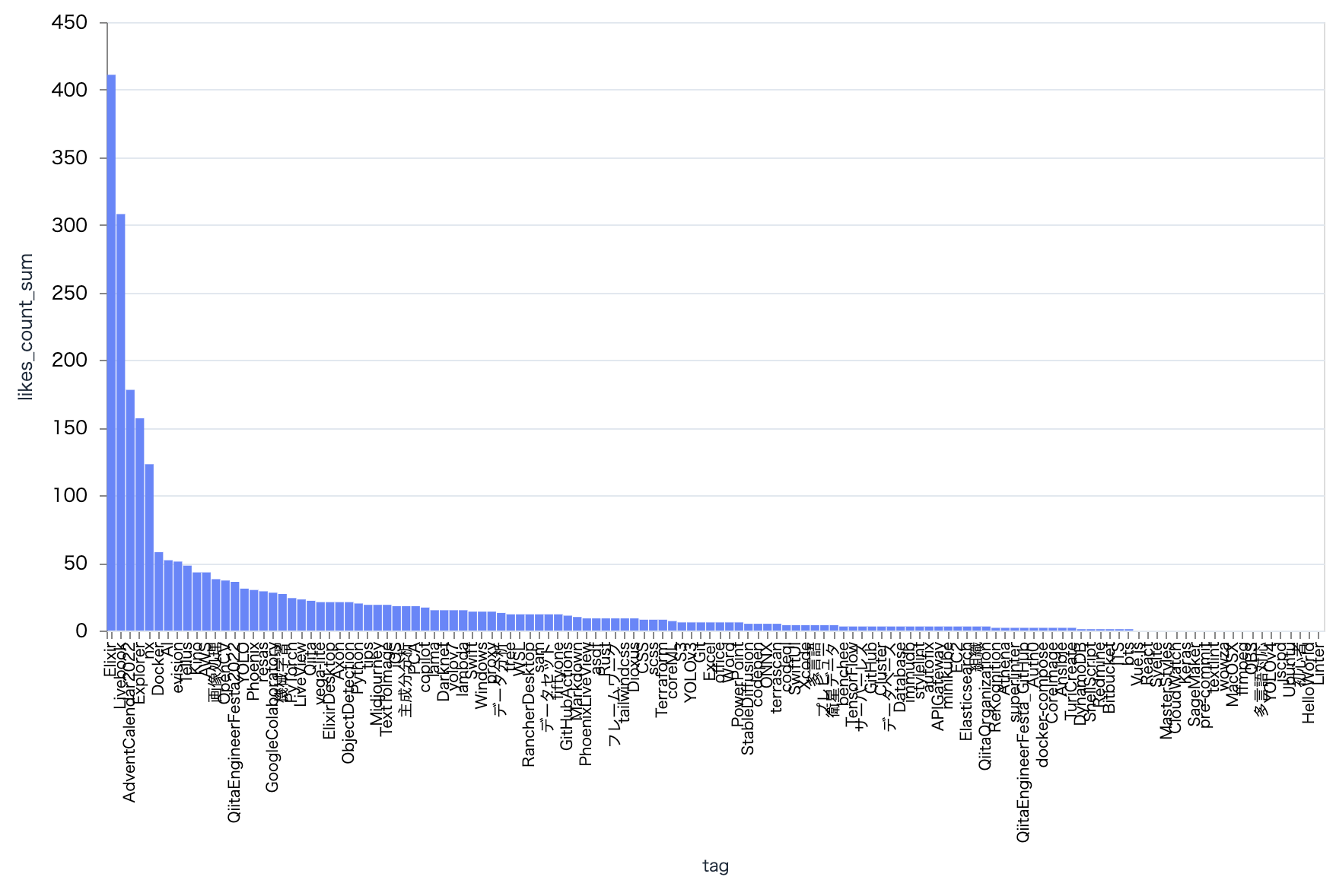
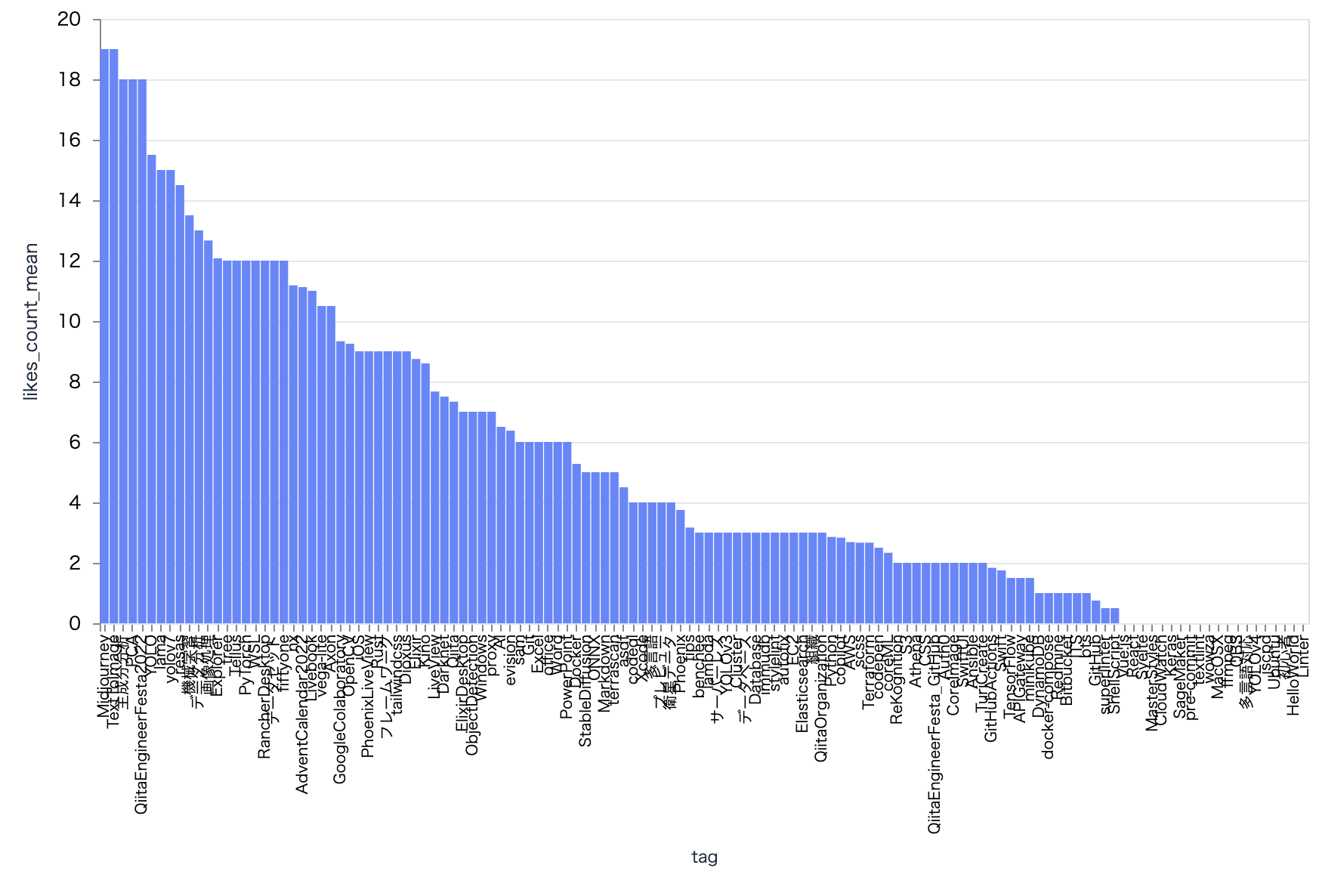
いいね数の平均は Midjourney がトップ
これも1回しか付いていないからですね
plot_tag_bar.("likes_count", "mean")
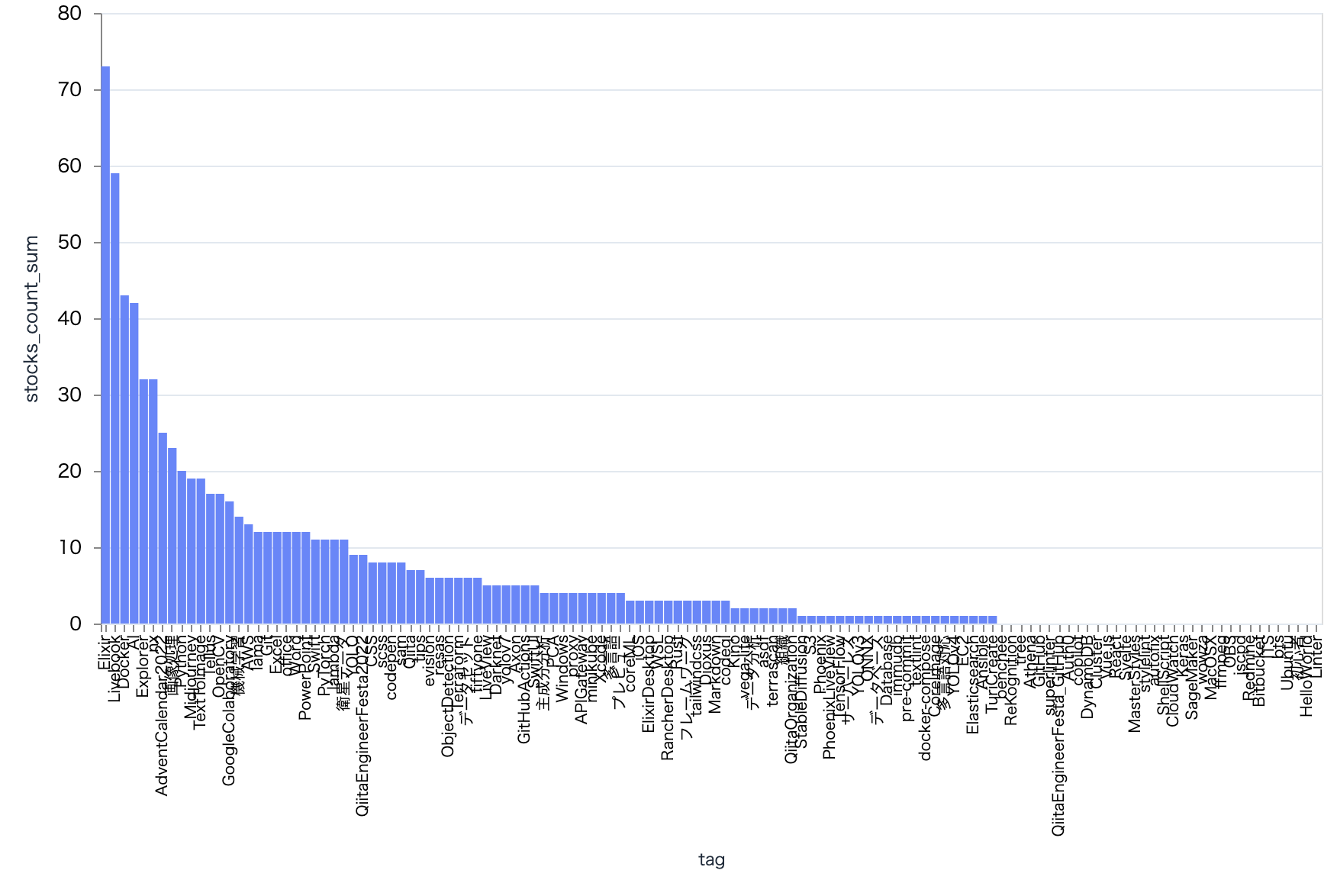
ストック数合計も Elixir が1位
plot_tag_bar.("stocks_count", "sum")
ストック数の平均も Midjourney がトップ
plot_tag_bar.("stocks_count", "mean")
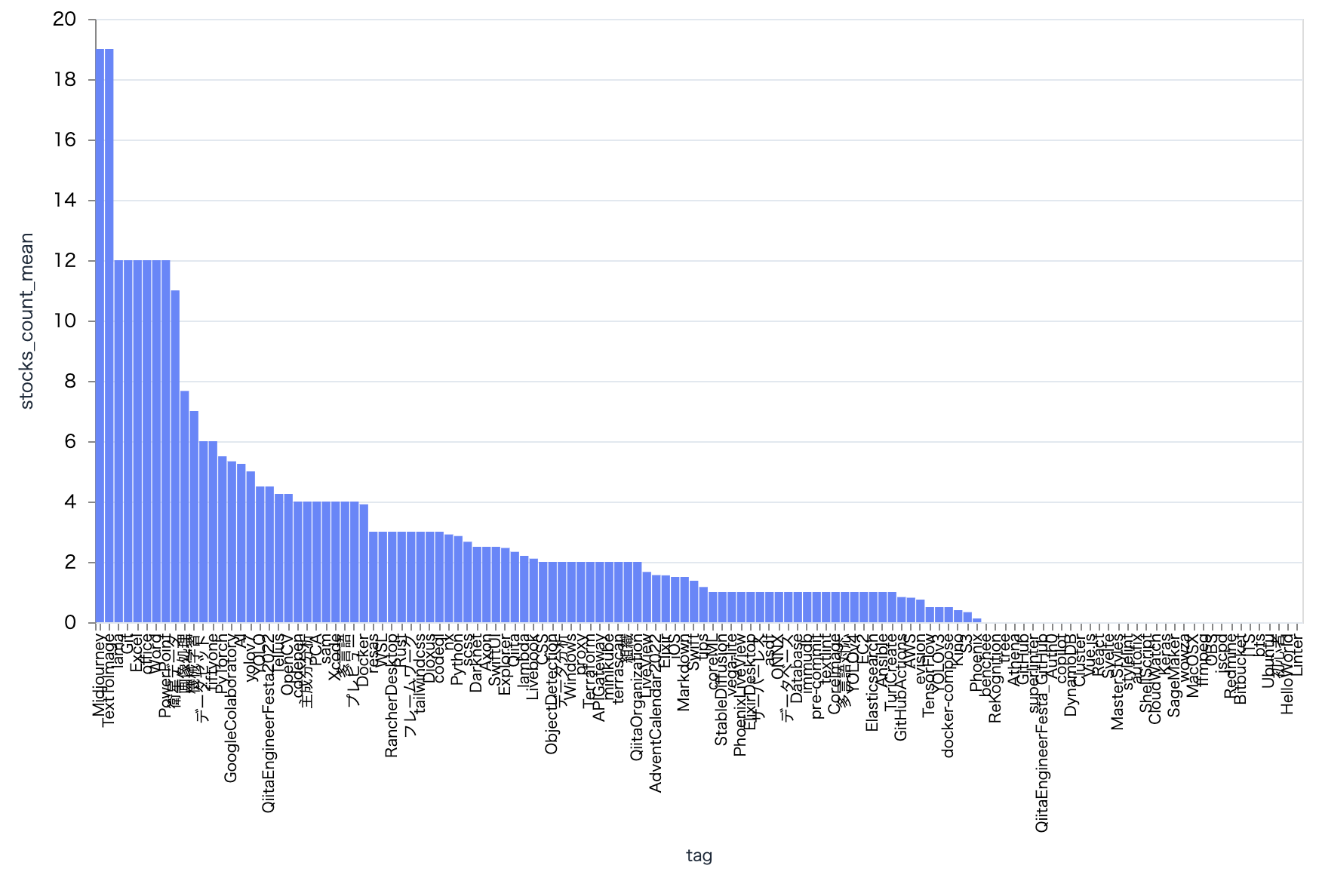
1回しか付けていないようなタグは外れ値にした方が良さそうです
まとめ
Livebook と Explorer で Qiita 投稿記事の様々な分析ができました
みなさんも、是非自分の投稿記事について Elixir で分析してみましょう