はじめに
MLX は Apple Silicon を利用した機械学習ライブラリです
EMLX は Nx のバックエンドとして MLX を使用します
EMLX を使うことで、 MacBook 上での機械学習が高速化できるはず
ということで、ベンチマークしてみました
実行環境
- 端末: MacBook Pro 13インチ、M2、2022
- チップ: Apple M2
- コアの総数: 8(パフォーマンス: 4、効率性: 4)
- メモリ: 24 GB
- Elixir: 1.18.1
- Erlang: 27.2
Livebook の起動
MacBook 上で起動するため、 Livebook をソースコードから実行します
git clone -b v0.14.5 https://github.com/livebook-dev/livebook.git
cd livebook
mix setup
ELIXIR_ERL_OPTIONS="-epmd_module Elixir.Livebook.EPMD" mix phx.server
セットアップ
新しいノートブックを開き、セットアップセルで必要なモジュールをインストールします
Mix.install([
{:nx, "~> 0.9"},
{:exla, "~> 0.9"},
{:torchx, "~> 0.9"},
{:emlx, github: "elixir-nx/emlx"},
{:kino_benchee, "~> 0.1"}
])
KinoBenchee はベンチマークのためのモジュールです
ベンチマーク
ベンチマーク用のモジュールを定義します
defmodule MyBenchmark do
def add(backend) do
tensor = Nx.iota({200, 200}, type: {:f, 64}, backend: backend)
Nx.add(tensor, tensor)
end
def dot(backend) do
tensor = Nx.iota({200, 200}, type: {:f, 64}, backend: backend)
Nx.dot(tensor, tensor)
end
def run_add() do
Benchee.run(
%{
"binary" => fn -> add(Nx.BinaryBackend) end,
"exla" => fn -> add(EXLA.Backend) end,
"torchx" => fn -> add(Torchx.Backend) end,
"emlx" => fn -> add(EMLX.Backend) end
},
memory_time: 2,
reduction_time: 2
)
end
def run_dot() do
Benchee.run(
%{
"binary" => fn -> dot(Nx.BinaryBackend) end,
"exla" => fn -> dot(EXLA.Backend) end,
"torchx" => fn -> dot(Torchx.Backend) end,
"emlx" => fn -> dot(EMLX.Backend) end
},
memory_time: 2,
reduction_time: 2
)
end
end
加算でベンチマークを実行します
MyBenchmark.run_add()
実行結果
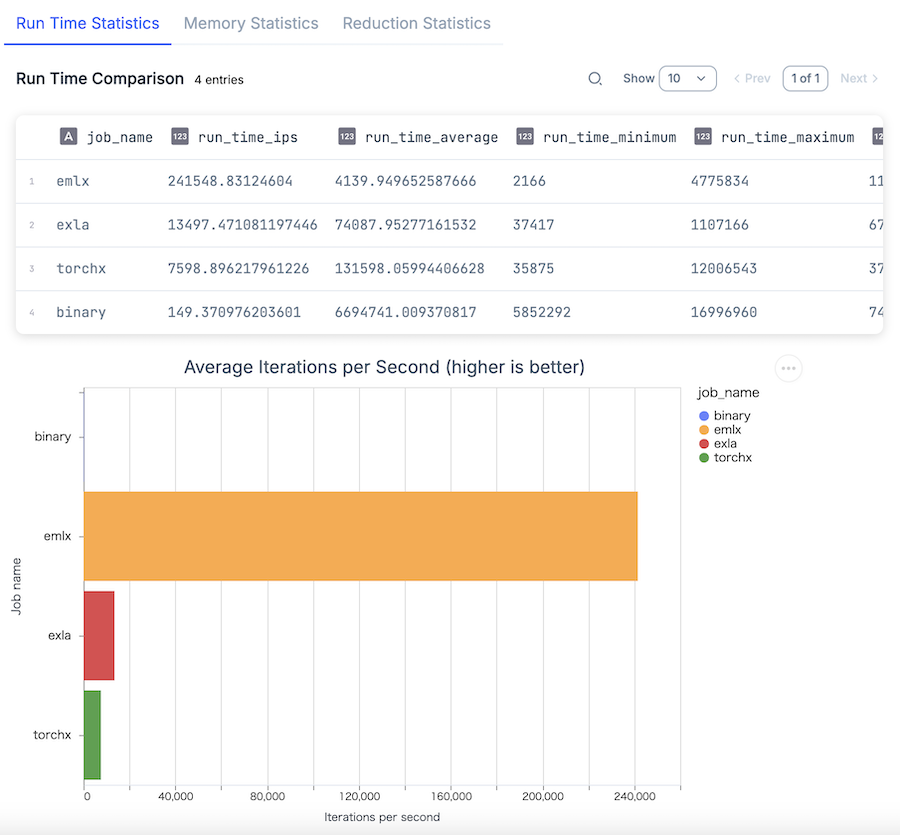
EMLX が他を圧倒しています
バイナリバックエンドの 1617 倍、 TorchX の 32 倍、 EXLA の 18 倍高速です
内積でベンチマークを実行します
MyBenchmark.run_add()
実行結果
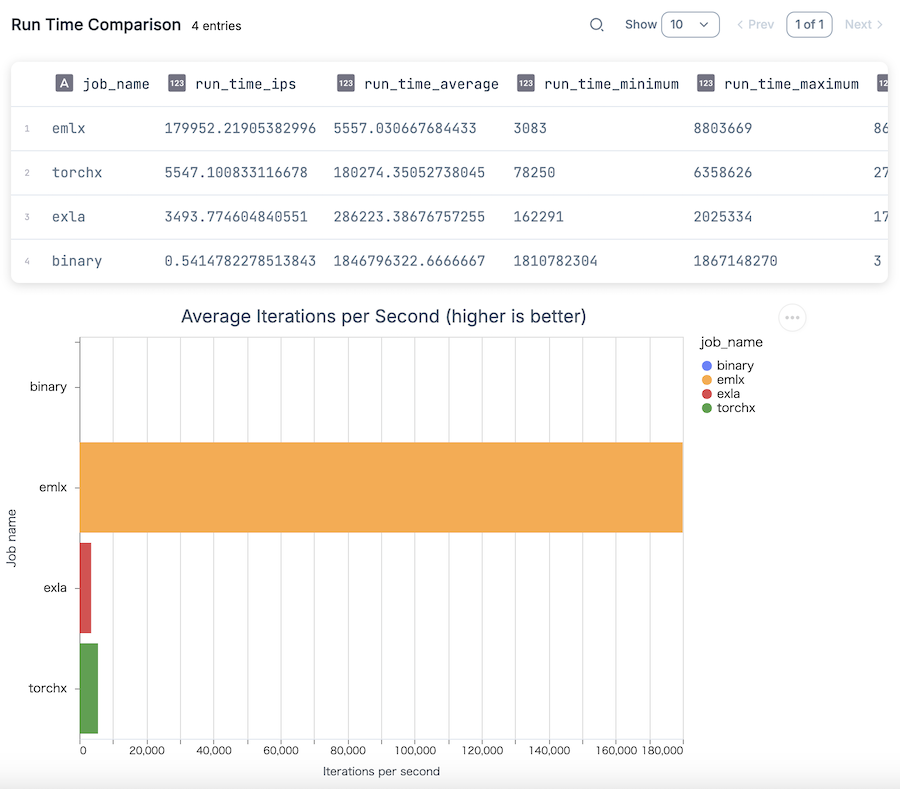
内積だと更に顕著です
バイナリバックエンドの 332335 倍、 TorchX の 52 倍、 EXLA の 32 倍も高速です
まとめ
Apple Silicon の性能を余すことなく発揮できる EMLX を活用できれば、 MacBook で AI を高速に動かせそうです
対応関数が増えることを期待しています