はじめに
近年のデータ基盤技術の界隈では、データレイクハウス(Data Lakehouse) という言葉がよく聞かれるようになってきました。データレイクハウスを最初に提示したのはDatabricks1だと思いますが、最近はMicrosoft Fabric2や他のデータ基盤製品でも採用されるようになってきています。
データレイクハウスを一言で説明すると「データレイクハウスとは、データウェアハウスとデータレイクの良いとこ取りをしたもの」という表現がよくされます。ただ、データウェアハウスもデータレイクも一般利用者向けではなく社内向けのシステムであり、あまり馴染みがなくてこれだけ聞いてもよく分からないという方も多いと思いますので、そのような方でもできるだけ分かりやいように情報をまとめてみようと思い、この記事を書いてみました。あまりデータレイクハウスの話の流れから脱線しないように、傍論は緑枠の補足説明の形で記載しています。データレイクハウスの正式な説明については、Michael ArmbrustさんらのCIDR 2021の論文3や同著者の技術ブログ記事1とその日本語訳4などをご確認ください。
データレイクハウスとは
データレイクハウスは、従来から存在するデータウェアハウス(Data Warehouse)やデータレイク(Data Lake)と同様に、データ基盤システムのアーキテクチャパターンの一つと言えます。このイメージについて、従来のデータウェアハウスやデータレイクからデータレイクハウスまでに至る流れを、下図に簡単に年表形式で示します。この図はdatabricksのWhat Is a Lakehouse?2の図を参考にして、内容をより単純化して作成したものです。
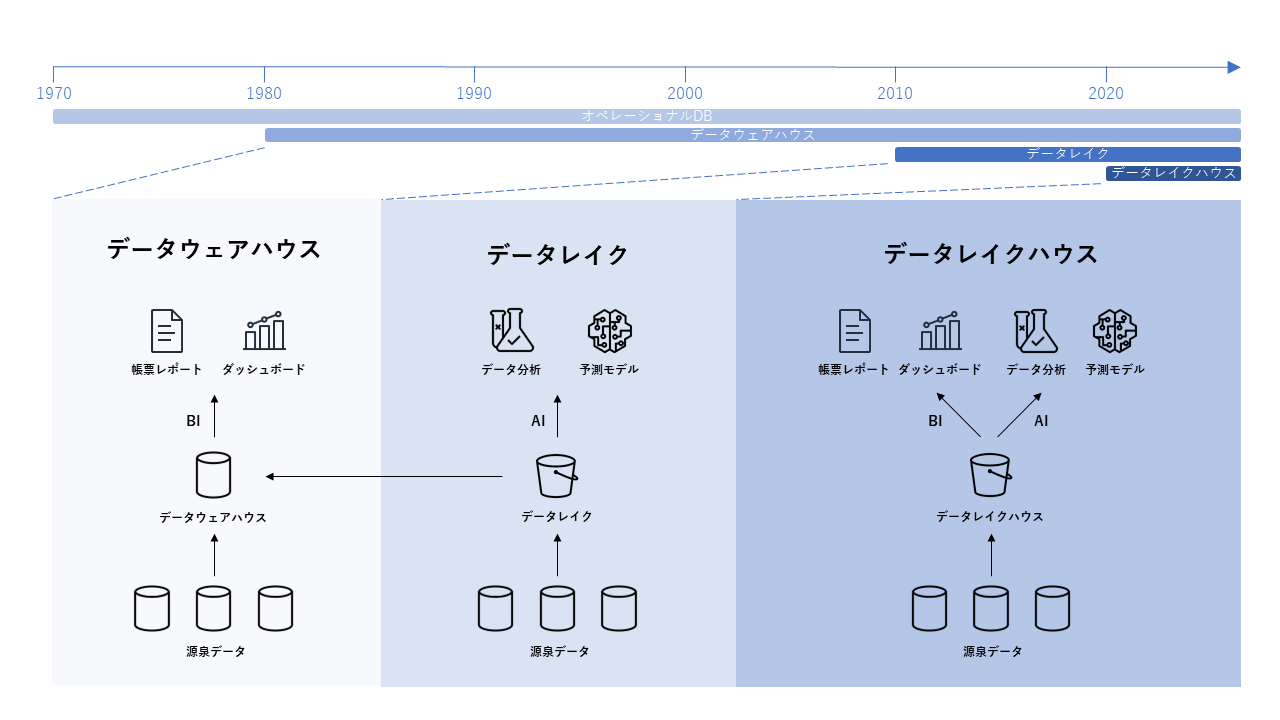
いらすとやで表現すると、このようなイメージです。

社内データ活用のためのシステムとして、データウェアハウスは1980年代頃から、データレイクは2010年代頃から導入され始めるようになったと言われています。データウェアハウスの歴史的な経緯等は英語版Wikipediaの記事に記載されています。データレイクハウスは、データレイク上にデータウェアハウスの機能を持たせるような形でデータを管理します。データウェアハウスは帳票レポートや経営ダッシュボードのようなBI(Business Intelligence) 用途、データレイクはデータ分析や機械学習のようなAI(Artificial Intelligence) 用途に主に利用されていますが、データレイクハウスではこのBIとAIの両方の用途に活用しやすいという面で注目されています。
データウェアハウスとデータレイク
データレイクハウスの何が嬉しいかというと、データウェアハウスとデータレイクの両方のデータ基盤を別々に準備しなくても、1つのシステム基盤でBIとAIの両方の用途に対応できるという点になります(下図)。
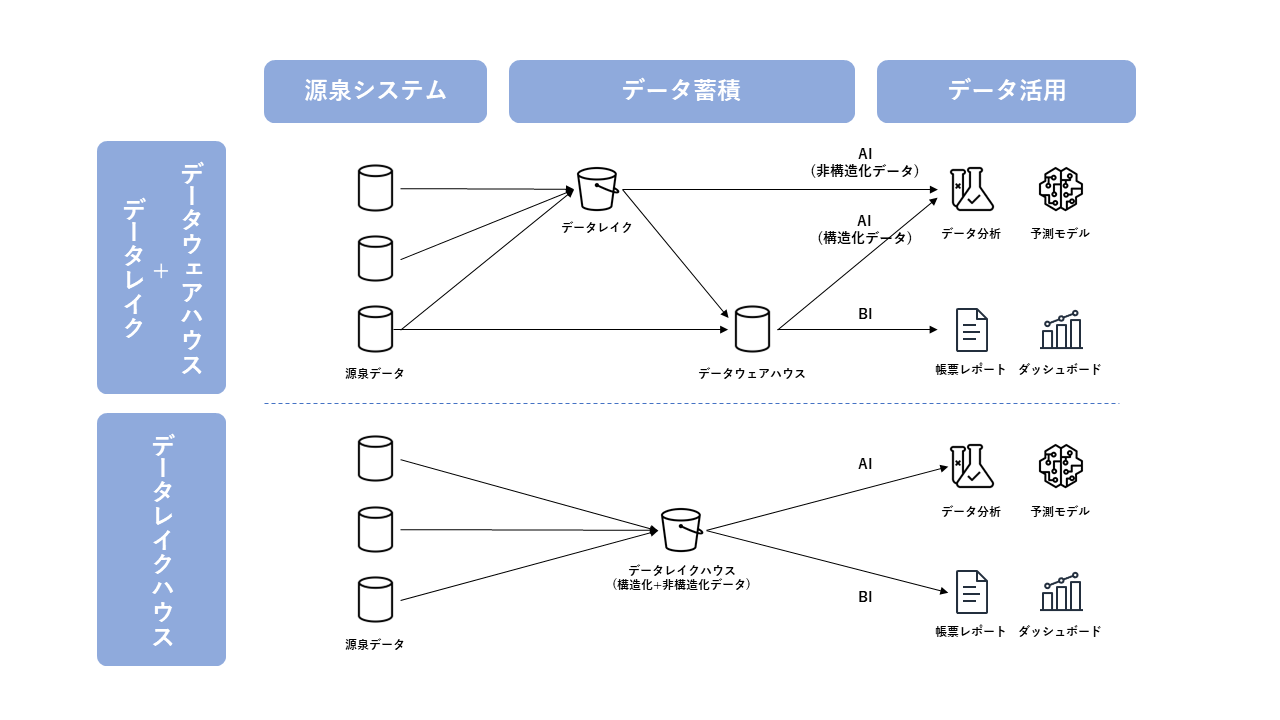
この嬉しさの背景について理解するためには、データウェアハウスやデータレイクのデータ基盤ってどんなものだったっけ、というところから知っておく必要があると思いますので、まずこれらの概念から簡単に紹介します。
データウェアハウス(Data Warehouse | DWH)
データウェアハウスは、直訳するとデータの倉庫 という意味になります。データウェアハウスの説明については、インターネット上で検索すると多くの記事で様々な観点から説明されていますが、ここでは私の職種であるデータエンジニアの視点からデータウェアハウスの特徴について説明します。
データウェアハウスは社内データを蓄積・活用できるようにする目的で利用される情報系のシステムで、1980-1990年頃から多くの企業で導入され始めました。データウェアハウスの導入目的は、経営者や営業員などがビジネス上の決定をデータウェアハウス内の定量的なデータに基づいて判断できるようにするために利用されます。
例えば、社内のマーケティング担当者や販売担当者が、自社のどの商品をどの顧客にいつどの方法でアプローチすれば売上が上がりやすいかを決める際に、社員個人の勘や経験のみを頼りに判断するのではなく、自社の過去10年間の販売実績データを集計した結果から判断できるようにしたい、と考えたとします。このような仕組みをITシステムで実現するには、社内の様々な業務システムのデータをデータウェアハウスに蓄積し、利用者がSQL文を実行してExcelの分析資料を作成したり、BIツール等を利用して直接データを利用できるようにします。このようにして、社内の意思決定者がデータに基づいた判断材料を獲得できるようにします。
BI(Business Intelligence)ツール
BIツールとは企業向けのデータ集計・可視化ツールであり、データ蓄積や集計処理の機能をデータウェアハウス側で担い、可視化やUI面の機能をBIツール側で担う形でデータウェアハウスと組み合わせてよく導入されます。BIツールを利用すると、利用者自身がセルフサービスでデータを分析することや、データを可視化した結果をダッシュボード上に公開して他の利用者と共有することができるようになります。
特徴
データウェアハウスのデータベースには、多くの場合は標準的なDB製品(PostgreSQLやMySQLなど)ではなく、データウェアハウス専用のDB製品が利用されます。このDB製品名の具体例を挙げると、Amazon Redshift, Google BigQuery, Snowflakeなどがあります。データウェアハウス用途に専用の製品が利用される理由は、下記のような理由と考えられます。
- 大量データ処理性能
データウェアハウスではユースケースの特性上、数億件を超えるような大量データの集計処理(OLAP, Online Analytical Processing)の性能が求められやすい傾向があります。データウェアハウス専用のDB製品はOLAPの性能向上に向いた技術(大規模並列処理や列ストアなど)が採用されているため、性能チューニングの労力をかけなくても標準的なDB製品よりも高いOLAP性能が得られやすい利点があります。
- テーブル形式のデータ管理
データウェアハウス専用のDB製品のほとんどは、テーブル形式でデータを保存するRDB(リレーショナルデータベース)として実装されています。そのため、データウェアハウス上のデータを標準的なRDB製品のようにデータを扱うことができ、一般的なDB管理の知識しか持っていなくても比較的簡単に使うことができる利点があります。
クラウド型データウェアハウス
当初のデータウェアハウス専用のDB製品は、およそ数千万円から数億円以上の価格のハードウェア一体型の筐体のアプライアンス製品として販売される形がほとんどでした。しかし、2010年代頃からクラウド型の従量課金制も可能なデータウェアハウス製品が登場したことで、近年では新規導入または既存システムから移行する場合でも、コストや拡張性等の観点からクラウド型のデータウェアハウス製品が採用される場合が多くなってきています。
データマート(Data Mart)
データウェアハウスは、通常は複数の社内システムの実績データを設計済のテーブル定義に従い保持します。そのため、特定の業務向けの加工済データを保持したい場合は、その利用者が管理するDBが利用される場合があります。このDBはデータマートと呼ばれ、直訳するとデータの小売店 の意味になります。データマートは利用者視点での管理しやすさが重視されるため、DWH専用ではない通常のDB製品が採用される場合もよくあります。
懸念点
データウェアハウスは現在でも多くの会社で利用されている現役のシステムですが、2010年代頃に機械学習やAIのブームが始まると、データサイエンティストによるAI用途のデータ活用にはデータウェアハウスは使いにくいと指摘されるようになりました。それは、下記のような理由によります。
- 非構造化データの保持が困難
2010年代頃からは、ディープラーニング(Deep Learning)に代表されるような、非構造化データ(画像データ、音声データなど)でも高精度に学習できるAI技術が急速に発展したことで、構造化データだけでなく非構造化データの活用ニーズも高まりました。しかし、データウェアハウスは一般的に構造化データをテーブル形式で利用する想定で設計されていて、容量あたりのデータ保持コストも高いため、非構造化データの蓄積先としてはあまり適していません。
- データモデリングが必要
大半のデータウェアハウス製品はRDBであり、データを蓄積する前にデータ構造や分析要件をもとにテーブル定義を設計する必要があります(データモデリング)。このため、データウェアハウスの導入時や一度設計したデータモデルを後から変更する場合には、DBエンジニアによるテーブル設計やデータの入れ替え必要になり、データを利用できるようになるまでの時間や設計工数がかかってしまいます。
このような背景から、データサイエンティストがAI用途に利用したいデータがデータウェアハウス内に保存されていず、後からデータを蓄積するにもそのための時間やコストがかかりすぎるためデータ活用を進められない、というような課題が顕在化するようになりました。
データレイク(Data Lake)
前述の課題に対して提案されたのが、データレイク5という形のデータ基盤です。データレイクは、直訳するとデータの湖 という意味になります。データレイクは、社内の統合的なデータ基盤システムとして、業務システムから抽出したデータファイルをそのままの形式で保持する形で利用します。そのままの形式で保持する目的は、主にデータ利用時にデータの元の状態を辿りやすくするためです。データレイクは当初はHadoopで実装する方法も提案されていましたが、現在ではクラウド型のオブジェクトストレージを利用して構築する方法が主流になっています。
データレイク上のデータファイルは必ずしもスキーマ定義を持たず、データ管理が困難になりやすいため、データカタログ等のメタデータ管理システムと組み合わせて運用される場合があります。利用者がデータレイク上のデータを利用する際は、データレイクから直接データファイルをダウンロードするか、またはデータエンジニアがデータウェアハウスやデータマートにデータを移行する処理を開発することでデータを利用できるようになります。
データレイクは非構造化データも含めた様々な形式のデータを低コストに蓄積することができるため、データサイエンスや機械学習等の利用データが多いほど有利になりやすいAI用途のデータ基盤システムとして適しています。一方で、データレイク自体は単なるストレージでありデータ処理用の計算リソースを持たないため、データ加工や分析のためには別のDBやJupyter等の分析環境と組み合わせて利用する必要があります。
データカタログ(Data Catalog)
データカタログ(Data Catalog)は、データレイクやデータウェアハウス等のデータ基盤システムのデータ情報(メタデータ)を一元管理するためのシステムです。データ利用者はデータカタログに登録された情報から、利用可能なデータの概要やデータサンプル、データの管理者や所在、データの来歴(データリネージ)等の情報を知ることができます。データカタログのメタデータは大きく技術メタデータ(Technical Metadata)と業務メタデータ(Business Metadata)に分類でき、業務メタデータは機械的な自動登録が困難のため人手による管理が必要になります。
特徴
データレイクは、通常はクラウド上のオブジェクトストレージを利用して実装され、下記のような利点があります。
- データ保持形式が柔軟で低コスト
オブジェクトストレージでは、データをテーブル形式ではなくディレクトリ+ファイルの形式でデータを蓄積するため、非構造化データでも簡単に保管することができます。また、クラウド型のオブジェクトストレージは、サービス利用料さえ支払えばほぼ容量無制限に利用できる上に、そのサービス利用料も他のサービスと比較すればそれほど高くありません。
- 社内の統合データ活用基盤としての利用
通常の社内システムではストレージ容量の上限等のために、そのシステムで利用された過去の実績データを永久保持せずに定期的なタイミングで削除する運用がされている場合があります。このようにして削除されていたデータをデータレイク上に保持することで、後からデータサイエンティスト等の利用者からデータ提供依頼を受けた場合にも対応しやすくなります。
スキーマオンライトとスキーマオンリード(Schema on Write, Schema on Read)
データウェアハウスとデータレイクの比較について、データウェアハウスはスキーマオンライト(Schema on Write)であるのに対し、データレイクはスキーマオンリード(Schema on Read)であると説明されることもあります。Schema on Writeでは、データ書込の前にテーブル定義(スキーマ)が決定されている必要があるため、データ書込時の作業は大変ですがデータ読込時は楽で、Schema on Readではその逆という特性があります。
データスチュワード(Data Steward)
データ利用者を要望を受けてデータレイク等が保持する社内データを提供する役割を、データスチュワードを呼びます。データスチュワードを直訳すると、データの執事 という意味になります。データガバナンスの観点では社内データのアクセス権限は適切に管理される必要がありますが、データスチュワードは社内のあらゆるデータにアクセスする権限が無ければ役割を果たせないので、専用の職責として定義される場合があります。
懸念点
しかし、データレイクも良い面ばかりではなく問題点もあり、下記などの弱点が指摘されています。
- データ品質管理
オブジェクトストレージはデータをファイル単位で扱うため、不正データの混入やスキーマの不整合、値の重複や欠損等のデータ品質不備が発生していても、データレイク単体で検出することはできません。そのため、データレイク上のデータを利用する際は、データファイルの内容についてデータ利用者が手元のDBやExcel等でデータ品質が自身の利用目的として十分かを確認し、必要に応じてデータを修正する必要があります。
- データガバナンス
データレイク上で機微情報を含むデータを管理する場合は、適切な利用者にのみデータアクセス権限を与えるデータガバナンス(Data Governance)の仕組みが必要です。オブジェクトストレージのアクセス権限管理は主にディレクトリ単位で実施しますが、権限管理の要件が決まらない場合や後から変更になる場合は、データレイクのデータアクセス権限のルールが複雑化することで、データ利用者へのデータ提供の可否判断やルールの実装が困難になる可能性があります。
このように管理不全になったデータレイクは、皮肉を込めてデータスワンプ(Data Swamp)と呼ばれます。データスワンプを直訳するとデータの沼という意味になり、データレイクの運用はこうならないように注意して進める必要があります。
データメッシュ(Data Mesh)
全社統合的なデータレイクでデータを一元管理する考え方への限界を指摘する意見も存在し、代わりに社内の各ドメインで分散してデータ基盤システムを持つ前提で全体のデータを運用する方式のデータメッシュ(Data Mesh)の考え方も注目されています。データメッシュはデータレイクハウスとは別軸の概念であるため本記事では詳述しませんが、データメッシュも興味深い考え方の一つで、下記の記事6などで解説されています。
データフェデレーション(Data Federation)
社内にある複数のDBシステムを、一つのシステムから仮想的に参照できるようにする技術をデータフェデレーションと呼びます。データフェデレーションは、直訳するとデータ連邦制 の意味になります。この技術を利用すると、データ利用時に物理的なデータ移行が不要になるためコストを低減できる利点がありますが、データ加工時に仮想化先のDBに処理負荷がかかりやすくなるため性能管理面の考慮が必要になります。
マスタデータマネジメント(Master Data Management | MDM)
データ管理の分野の中でも、社内の各システムに散在する顧客や商品等のマスタデータが信頼できる唯一の情報源(Single Source of Truth)となるように維持管理する方法論に焦点を当ててた考え方をマスタデータマネジメント(MDM)と呼びます。MDMは、本記事で述べているデータ分析系のシステムだけではなく、業務系システムの開発/運用の世界でもよく取り上げられて議論される分野の一つです。
データウェアハウス+データレイクの組み合わせ
これまで述べたようにデータウェアハウスとデータレイクにはそれぞれ利点と欠点がありますが、この2つを組み合わせることで、データの柔軟性と管理性に関するお互いの弱点を補完し合うことができます。この構成では、データレイクには今後データ分析に利用する可能性があるデータをファイル形式を保持し、データウェアハウスには現時点でBIツール等により定常的に利用することが明確な構造化データを投入するようにして利用します。このようにして、AI用途に求められやすいデータ柔軟性と、BI用途に求められやすいデータ管理性の両方をシステム全体として備えることができます。
このデータウェアハウス+データレイクの組み合わせのアーキテクチャは、データレイクハウス登場以前のデータ基盤技術の世界では、AIとBIの両対応のデータ基盤システムの最終形の一つと考えられていたように思います。
懸念点
しかし、データレイクハウスの観点からみると、データレイク+データウェアハウスの組み合わせの構成は下記のような懸念点があると言えます。
- AIとBIのシステムの分断
データレイクとデータウェアハウスを組み合わせた場合でも、それぞれのシステム自体は独立に存在しています。AIモデルを開発する部門とBIツールを利用する部門は仕事内容や達成目標が異なっており、AIの部署はデータレイクとpythonやSAS等のデータ分析ツール、BIの部署はデータウェアハウスとBIツールをそれぞれ管理することになりやすいです。お互いのシステム上のデータを利用したい場合には部署を跨いだやり取りが必要になるため、他部署のデータを入手する際の手続き等で時間がかかるような状況が発生しやすくなります。
- データの二重持ち
データレイク上のデータを、BIツール等での定常的な利用のためにさらにデータウェアハウスに投入するユースケースでは、データレイクとデータウェアハウスの両方に同じデータコピーが物理的に存在する状態になります。このようなデータの二重持ちは、ストレージのデータ保管やデータ複製処理のための余計なコストがかかり、データがデータウェアハウスに投入されるまでのデータ遅延も引き起こされやすくなります。
実際に、AIを開発するデータサイエンティストがDWH/BI系のデータ基盤システムにあまり明るくなかったり、逆にDWH/BI系システムを管理するデータエンジニアやデータアナリストがデータサイエンスやAIについてよく知らなかったりする光景はそれほど珍しくないように思います。その原因の一つは、このようなシステムの分断にあるのかもしれないと思います。
データレイクハウス(Data Lakehouse)
以上のデータ基盤に関する背景を踏まえて、改めてデータレイクハウスについて説明します。データレイクはデータウェアハウスやデータレイクの延長にある新しいデータ基盤アーキテクチャの考え方です。データレイクハウスでは、データレイクと同様にオブジェクトストレージ上にデータファイルを配置しますが、構造化データについてはオープンテーブルフォーマット(Open Table Format)7 の形で管理される点がデータレイクとの大きな違いになります。データレイクハウスとオープンテーブルフォーマットの関係性のイメージを下図に示します。
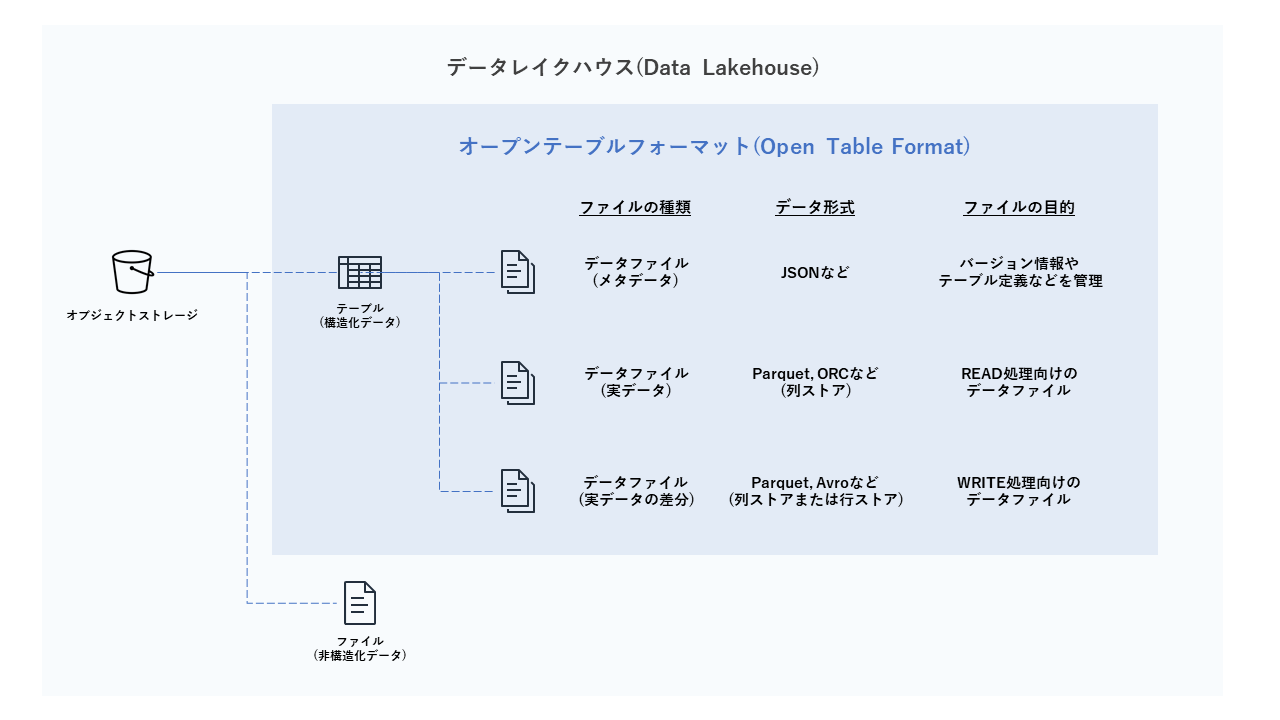
オープンテーブルフォーマットを直訳すると公開データ仕様という意味になり、これ自体はただのデータ形式の仕様でしかありませんが、オブジェクトストレージ上にこのデータ仕様でデータを配置してオープンデータフォーマット対応のDB製品で扱うことで、データウェアハウス相当のデータ管理性やOLAP性能が得られるようになります。
例えば、RDBのようにテーブルのスキーマ定義の管理やSQL文の実行ができるようになり、テーブル内のデータのACID特性を維持するトランザクション管理も可能になります。また、あるデータレイクハウスのベンダが、DB製品の性能比較でよく利用されるTPCベンチマークで既存のデータウェアハウス製品に対抗可能な高いOLAP性能を得られていると発表しているように、データウェアハウスの代わりとしてデータレイクハウスを利用する使い方もできます。このようにして、データレイクハウスを利用することで、データレイク相当のデータ形式の柔軟性とコストの安さを維持しながら、データウェアハウス相当のデータ管理性や性能を得ることができます。
特徴
データレイクとデータウェアハウスを組み合わせる代わりに、データレイクハウスをデータ基盤に採用することで、下記の利点を得ることができます。
- AIとBIのシステムの統合
データレイクハウスでは、データレイク的なオブジェクトストレージ上に配置したデータファイルに対して、データウェアハウスのコンピューティング用のサーバ上からSQL文を利用して直接的にデータ処理を実行することができます。そのため、AIとBIの両用のデータ基盤システムとして管理できるようになり、データレイクからデータウェアハウスへのデータコピー処理も不要になるためデータ二重持ちの問題も解消されやすくなります。
- データの柔軟性と管理性の両立
データレイクハウス単一のシステムで、データレイクとデータウェアハウスの両方の機能を利用できます。例えば、データレイクのように非構造化データと構造化データの両方を低コストに保持しながら、データウェアハウスのようにテーブル形式でデータを管理して高いOLAP性能が得られるため、両方のデータ基盤の長所を生かしたデータ利用ができるようになります。
参考のために、databricksのデータウェアハウスとデータレイク、データレイクハウスの比較表5の日本語訳を下記に転記します。
| 項目 | データレイク | データレイクハウス | データウェアハウス |
|---|---|---|---|
| データ種類 | 〇全て | 〇全て | ×構造化データのみ |
| コスト | 〇安価 | 〇安価 | ×高価 |
| データ形式 | 〇オープン | 〇オープン | ×固有 |
| 拡張性 | 〇高い | 〇高い | ×低い |
| 想定ユーザ | ×AIのみ | 〇AI/BI | ×BIのみ |
| 信頼性 | ×低い | 〇高い | 〇高い |
| 管理性 | ×低い | 〇高い | 〇高い |
| 処理性能 | ×低い | 〇高い | 〇高い |
この比較表がdatabricksのデータレイクハウスの立場から作成されている点は差し引いて捉える必要があるかもしれませんが、多かれ少なかれこの表の通りデータレイクハウスがデータレイクとデータウェアハウスの良いとこ取りをしているのは事実ではないかと思います。
メダリオンアーキテクチャ(Medallion Architecture)
データレイクハウス内のデータを、想定されたデータ品質やデータ加工の程度によりBronze, Silver, Goldの3つのデータ領域に分けて管理する考え方をメダリオンアーキテクチャと呼びます。メダリオンアーキテクチャでは、Bronze領域には生データ、Silver領域には整形済データ、Gold領域には業務向けに加工したデータを保持します。Bronze領域はデータレイク、Gold領域はデータマートに概ね対応しますが、Silver領域がデータウェアハウスに対応するかについては議論8があるようです。
オープンテーブルフォーマット(Open Table Format)
データレイクハウスの重要技術であるオープンテーブルフォーマットについて、より詳しく解説してみます。オープンテーブルフォーマットは、2024年時点で具体的にはApache Hudi9, Apache Iceberg10, Delta Lake11の3種類のデータ仕様の実装が公開されています。逆の言い方をすれば、この3つの実装の総称がオープンテーブルフォーマットと呼ばれています。
これらのオープンテーブルフォーマットの実装に共通する考え方として、テーブルを構成するデータファイルを「メタデータ」「実データ」「実データの差分」の3種類の役割に分けて、それぞれのデータファイルを組み合わせてテーブル全体を管理しています。これらのデータファイルの内容と役割について下記に説明します。
- データファイル(メタデータ)
RDB相当のデータ管理を実現するためのメタデータを、JSONまたは独自のファイル形式で保持します。メタデータの例として、データ更新操作の情報やデータのバージョン情報、テーブルのスキーマ定義や列値の統計情報、データファイルのパスなどがあります。DB製品側でこれらのメタデータを利用して、テーブル内のトランザクション管理や過去データを参照するタイムトラベル機能、プルーニング(枝刈り)によるデータ処理性能の向上などに役立てます。なお、これらのメタデータは基本的にテーブル単位であり、複数テーブルを跨ぐトランザクション管理のためのデータのバージョン情報は必ずしも保持していません。
タイムトラベル(Time Travel)
オープンデータフォーマットは、UPDATE文やDELETE文などのデータ更新処理をデータファイルおよびメタデータの情報追加により表現する仕様のため、データ更新前の過去断面の状態のデータをいつでも参照することができ、この機能をタイムトラベルと呼びます。データ容量の削減やコンプライアンス上の理由で過去のデータファイルを明示的に削除する操作(VACCUME)を実行すると、削除したデータファイルに含まれるデータ断面はタイムトラベル機能でも参照できないようになります。
- データファイル(実データ)
実際のデータをREAD(読込)処理向けに保持するファイルで、データの管理性や読込性能等の都合から数百MB程度単位の複数のファイルに分割されて保管されます。このデータファイルは、主に大量データの集計処理(OLAP)用途で利用される想定のため、ParquetやORCのような列ストアのデータファイル形式が利用されます。一方で、列ストアは小さなデータ単位の更新処理は不得意であるため、WRITE(更新)処理は既存の実データファイルに対して直接実行せずに、それ専用の差分データファイルを保持する形で対応する等の工夫がされます。
列ストアのデータファイル形式
オープンテーブルフォーマットでは、parquetやORCのような列ストアのデータファイル形式が積極的に利用されています。列ストアではファイル内で列単位でデータを圧縮して保持するので、ファイルサイズが小さくなりOLAP性能が向上する利点がありますが、特定IDの行単位を取得/更新などの操作では、内部的に解凍/再圧縮処理が必要になるため高い性能が得られにくい特性をもつ点にについて留意する必要があります。
- データファイル(実データの差分)
実際のデータをWRITE処理向けに保持する差分データ用のファイルで、実装によってはParquet(列ストア)ではなくAvro(行ストア)のファイル形式が利用される場合もあります。Parquetファイルを利用する場合でも、INSERT処理のみであれば新規データのみを含むparquetファイルを追加すればよいため、ストリーミング処理による頻繁なデータ投入処理に対応することができます。古い差分データは、性能向上のために定期的にコンパクション(Compaction)と呼ばれる圧縮処理によりREAD処理向けの実データに統合されます。
Copy on Write(CoR)とMerge on Read(MoR)
オープンテーブルフォーマットでは、UPDATE処理やDELETE処理が実行された場合、基本的には既存データを含む実データファイルを元にデータ更新後のparquetファイルを新規作成する方法で対応します(Copy on Write)。この更新方法は性能が低いので、parquetファイル全体を再作成せずにデータの差分情報のみを記録しておき、データ読込時にその差分データと実データと組み合わせることで対応する更新方法もあります(Merge on Read)。Copy on WriteとMerge on Readのどちらの方式を採用するかは、WRITE性能とREAD性能とのトレードオフになります。
なお、この記事で説明しているオープンテーブルフォーマットの考え方はあくまで分かりやすさを重視しているため、正確なデータ仕様の実装についてはHudi, Iceberg, Delta Lakeの各公式サイトをご確認ただければと思います。それぞれデータ仕様の実装の比較については、下記のAWS Black Beltセミナーのスライド11に分かりやすくまとめられていると思いました。
懸念点
データレイクハウスは優れたデータ基盤アーキテクチャだと思いますが、あえて懸念点を述べてみたいと思います。
- BIまたはAIの単独のユースケース
BIとAIの両方の用途を想定する場合は、データレイクハウスを採用することで、データレイクとデータウェアハウスの組み合わせよりもシンプルなデータ基盤アーキテクチャを構築できます。しかし、BI用途またはAI用途のどちらか一方のみを想定する場合は、データウェアハウスまたはデータレイクのどちらかのみを導入する場合と比較して、データレイクハウスを採用してもあまり恩恵が得られない可能性があります。
- オープンデータフォーマット対応のDB製品
繰り返しになりますが、オープンデータフォーマット自体は単なるデータ仕様であり、そのデータを処理するにはDB製品側の処理エンジン側がオープンデータフォーマットの実装に対応している必要があります。しかし、2024年現在で対応可能なDB製品はあまり多くなく、対応していてもHudi, Iceberg, Delta Lakeの3つの実装のうちどれか一つしか対応していない場合もあります。
とはいえ、これらの懸念点はデータレイクハウスの有効性自体を否定するものではありません。また、データ形式の対応についても、Hudi, Iceberg, Delta Lakeのデータ形式の差異を吸収するDelta Universal Format12のような技術も出てきているので、技術の進歩とともに徐々に改善されていくのではないかと考えています。
データレイクハウスの将来
従来のデータベース技術の世界では、データはDB製品をインストールしたサーバのストレージ上に、そのDB製品でしか読み書きできない固有のファイル形式で保持されることが普通でした。そのため、DB製品を変更するには変更前のDB製品のテーブル情報やSQL文に加えて、DB製品が保持するデータ自体も変更先のDB製品に物理的に移し替える必要がありました。そして、もし変更前のDB製品に存在するテーブル数やSQL文、データ量などが膨大な場合は、この移行のためだけに数か月から数年以上の期間、および数千万円から数億円以上のコストがかかってしまう場合がありました。このコストはDB製品を利用する会社にとって直接的にビジネス的な価値に繋がるわけではないので、結果として特定のDB製品へのベンダーロックインとなり、データ活用基盤の新陳代謝が進まない一因になっていたとも考えられると思います。
しかし、もし将来的にDB製品の多くがデータレイクハウスおよびオープンテーブルフォーマットに対応するようになると、オブジェクトストレージ上にオープンデータフォーマットで移行対象データを配置しておけばDB移行の際の物理的なデータ移行が不要になるため、DB移行にかかるコストが大幅に削減できるようになる可能性があると考えます。そうなると、オープンデータフォーマット非対応のDB製品は採用されなくなり、DB製品のベンダ側としてはデータフォーマット面では差別化できなくなるのでコンピューティング面やアプリケーション面での工夫で競合と勝負する、というような世界になるのかもしれません。
いずれにせよ、今後社内データのビジネス活用やシステム導入コストの低減が進むにつれて、データレイクハウスを導入する会社も徐々に増加していくのではないかと思っています。
-
Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia, Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, CIDR 2021. ↩