Databricksクラスターの起動状態監視
Databricksのライセンス料金は、起動するクラスターのサイズと起動時間に依存する従量課金制です。そのため、databricksは少額の料金から使い始めることができますが、利用者がクラスターでストリーミング処理をかけ流しの状態にするなど、クラスターを長時間起動し続けるような使い方をしてしまうと、うっかり大きな料金がかかってしまう場合もあります。
本記事では、databricksクラスターの起動状態を監視することで、業務時間外等の本来想定しない時間にクラスターが起動していた際に、システム管理者にメール通知するように設定する方法を紹介しようと思います。
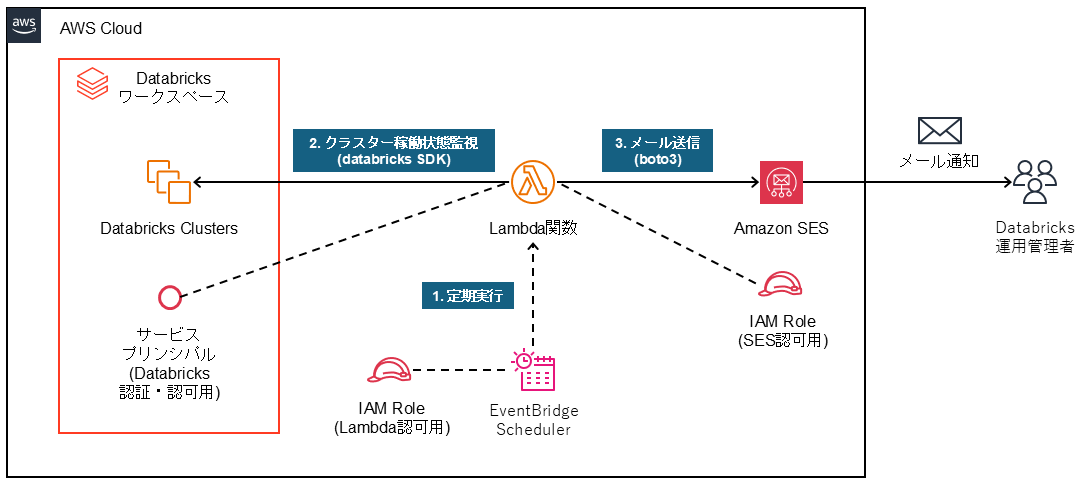
システム構成図
今回は下図のような構成および流れで、AWS LambdaとAmazon SES(Simple Email Service)を利用してDatabricksクラスターの起動状態を監視します。
- EventBridgeを利用して、Lambda関数をスケジュール実行する
- Lambda関数でDatabricks SDKを利用して、databricksクラスター稼働状態を確認する。
- Lambda関数でboto3を利用して、Amazon SESでDatabricks運用管理者に通知メールを送信する。
databricksの設定
databricks側の設定について記載します。databricks側では、サービスプリンシパルの作成のみ行います。
サービスプリンシパルの作成
- サービスプリンシパルとは
サービスプリンスパルはそもそも何かというと、システムユーザのことだと解釈すると分かりやすいと思います。databricks認証にサービスプリンシパルの代わりに個人用アクセストークンを利用することも可能ですが、その場合は認証用のトークンが特定のユーザアカウントに紐づくため、そのユーザが運用管理者でなくなった場合の引継ぎの時に困ることがあります。この監視プログラム専用のサービスプリンシパルを作成することで、システム運用管理者のユーザアカウントとは独立した認証主体(システムユーザ)を利用できるようになり、運用がしやすくなります。
- 作成手順
今回は、databricksワークスペース単位でサービスプリンシパルを作成し、OAuth M2M(Machine to Machine)方式で認証できるようにします。この設定方法については、下記の公式ドキュメントをご確認ください。
設定した後に、Lambda関数上に設定する下記のサービスプリンシパルの情報を控えておきます。
- クライアントID
- シークレット
特に、シークレットの値は初回作成時にしか表示されないため、もし値を忘れてしまった場合はシークレットの再作成をやり直します。
AWSの設定
AWS側の設定について記載します。AWSでは、Amazon SES, AWS IAM, AWS Lambda, Amazon EventBridgeを設定します。
Amazon SES (Simple Email Service)の設定
Amazon SESの設定をします。Amazon SESでは、送信元メールアドレスの偽装を防ぐために、事前に送信元のメールアドレスまたはそのドメインをIDとして登録しておく必要があります。今回は下記の方法で、メールアドレス単位で送信元のIDを登録します。
- Amazon SES画面に遷移して、「ID」メニュー選択する。
- 画面右上の「IDの作成」ボタンを選択し、下記の情報を入力してIDを作成する。
- IDの詳細:
Eメールアドレス - Eメールアドレス:
<送信元メールアドレス>
- IDの詳細:
- AWSから上記メールアドレスに検証用のメールが届くので、メール本文内のURLにアクセスして承認する。
- 「ID」メニュー画面のID一覧に入力したID情報が登録され、下記の状態になったことを確認する。
- IDステータスが「
検証済み」の状態
- IDステータスが「
AWS IAMの設定
下記の処理を実行する際のアクセス許可に利用するための、IAMロールを作成します。
- AWS LambdaからAmazon SESを呼び出す。
- Amazon EventBridgeからAWS Lambda関数を呼び出す。
今回は、2のIAMロールはEventBridgeの設定時に自動作成されるものを利用しようと思いますので、1のIAMロールのみ作成します。
1のIAMロールの作成手順については、下記のブログを参考にします。
今回は、下記のJSON定義のインラインポリシーを持つIAMロールを作成しました。このIAMロールをLambda関数に割り当てることで、そのLambda関数からAmazon SESのメール送信のAPIを呼び出せるようになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ses:SendEmail",
"ses:SendRawEmail"
],
"Resource": "*"
}
]
}
AWS Lambdaの設定
databricksの状態をポーリングで監視するLambda関数を作成します。処理の流れをざっくり説明すると下記のとおりです。
- Databricksワークスペースの下記のリソースの状態を確認する(Databricks SDK for Python利用)。
- 汎用クラスター
- SQLウェアハウス
- もし起動中リソースが存在した場合は、下記の処理を行う。
- Amazon SESを呼び出して、通知メールを送信する(AWS SDK for Python(Boto3)利用)
下記はソースコードの例です。ランタイムはPython 3.12を利用しています。
import boto3
import json
import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service import compute
from databricks.sdk.service import sql
client = boto3.client('ses', region_name='ap-northeast-1')
def lambda_handler(event, context):
# ワークスペースクライアント認証でDatabricksに接続
w = WorkspaceClient(
# databricksのホスト名
host='dbc-xxxxxxxx-xxxx.cloud.databricks.com',
# databricksサービスプリンシパルの情報
client_id='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx',
client_secret='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
auth_type='oauth-m2m'
)
# クラスタおよびSQLウェハウス情報をまとめる変数を初期化
running_objects = ''
# for文でクラスタ情報をコンソール出力する際の見出し
print("Cluster name, Cluster ID, state")
# 汎用クラスタの起動状態確認
for c in w.clusters.list():
# クラスタ情報のコンソール出力
print(f"{c.cluster_name}, {c.cluster_id}, {c.state}")
# クラスタが起動中であれば running_objects にクラスタ情報を追加
if c.state == compute.State.RUNNING:
formated_text = pprint.pformat(c)
running_objects += f"{formated_text}\r\n"
# SQLウェアハウス情報をコンソール出力する際の見出し
print("Warehouse name, Warehouse ID, state")
# SQLウェアハウスの起動状態確認
for h in w.warehouses.list():
# SQLウェアハウス情報のコンソール出力
print(f"{h.name}, {h.id}, {h.state}")
# SQLウェアハウスが起動中であれば running_objects にSQLウェアハウス情報を追加
if h.state == sql.State.RUNNING:
formated_text = pprint.pformat(h)
running_objects += f"{formated_text}\r\n"
# 戻り値用の変数を初期化
return_body = "No running clusters detected."
# 起動中のクラスタが存在すれば、Amazon SES を介したメール送信
if len(running_objects) > 0:
response = client.send_email(
Destination={
'ToAddresses': ['<送信先メールアドレス1>', '<送信先メールアドレス2>']
},
Message={
'Body': {
'Text': {
'Charset': 'UTF-8',
'Data': f'{running_objects}',
}
},
'Subject': {
'Charset': 'UTF-8',
'Data': '【Databricks】起動中のクラスタ情報',
},
},
Source='<送信元メールアドレス>'
)
return_body = "Email Sent Successfully. MessageId is: " + response['MessageId']
return {
'statusCode': 200,
'body': json.dumps(return_body)
}
Databricks SDK for Pythonは外部ライブラリとなるため、Lambdaのレイヤー機能等を利用して別途アップロードします。下記は参考記事です。
前述の手順で作成したIAMロールを、Lambda関数に割り当てます。割り当てるには、Lambda関数の「設定」タブの「アクセス権限」メニューを選択して、「実行ロール」に作成したIAMロールを選択します。
Amazon EventBridgeの設定
Amazon EventBridgeスケジューラを利用して、databricksクラスター監視用に作成したLambda関数を定期的にキックするように設定します。下記のような手順で作成することができます(パラメータは主要のもののみ記載します)。
- Amazon EventBridge画面に遷移して、「スケジュール」メニューを選択する。
- 画面右上の「スケジュールを作成」ボタンを選択する。
- 「ステップ1_スケジュールの詳細の指定」画面で、下記の情報を入力する。
- スケジュールのパターン (毎日18時に実行する場合)
- 頻度:
定期的なスケジュール - タイムゾーン:
(UTC+09:00)Asia/Tokyo - スケジュールの種類:
cronベースのスケジュール - cron式:
- 分:
0, 時間:18, 日:*, 月:*, 曜日:?, - 年:*
- 分:
- 頻度:
- スケジュールのパターン (毎日18時に実行する場合)
- 「ステップ2_ターゲット」画面で、下記の情報を入力する。
- ターゲットAPI:
AWS Lambda - Lambda関数:
<作成したLambda関数名>
- ターゲットAPI:
- 「ステップ3_設定」画面を、お好みで設定する。
- 実行ロール:
このスケジュールの新しいロールを作成
- 実行ロール:
- 「ステップ4_スケジュールの確認と作成」画面で、「スケジュールを作成」ボタンを選択する。
この設定により、Amazon EventBridgeからLambda関数が定期的にキックされて実行されるようになります。
通知メールの内容
AWS Lambdaが起動中のクラスターを検知すると、指定した送信先メールアドレスに対して下記のような情報を含むメールが送信されます。下記は通知メール本文のサンプルです。
通知メール本文のサンプル
ClusterDetails(autoscale=None,
autotermination_minutes=10,
aws_attributes=AwsAttributes(availability=<AwsAvailability.ON_DEMAND: 'ON_DEMAND'>,
ebs_volume_count=3,
ebs_volume_iops=None,
ebs_volume_size=100,
ebs_volume_throughput=None,
ebs_volume_type=<EbsVolumeType.GENERAL_PURPOSE_SSD: 'GENERAL_PURPOSE_SSD'>,
first_on_demand=0,
instance_profile_arn=None,
spot_bid_price_percent=100,
zone_id='auto'),
azure_attributes=None,
cluster_cores=2.0,
cluster_id='xxxx-xxxxxx-xxxxxxxx',
cluster_log_conf=None,
cluster_log_status=None,
cluster_memory_mb=8192,
cluster_name="Personal Compute Cluster",
cluster_source=<ClusterSource.UI: 'UI'>,
creator_user_name='username01',
custom_tags={'ResourceClass': 'SingleNode'},
data_security_mode=<DataSecurityMode.SINGLE_USER: 'SINGLE_USER'>,
default_tags={'ClusterId': 'xxxx-xxxxxx-xxxxxxxx',
'ClusterName': " Personal Compute Cluster",
'Creator': 'username01',
'Vendor': 'Databricks'},
docker_image=None,
driver=SparkNode(host_private_ip='x.x.x.x',
instance_id='i-xxxxxxxxxxxxxxxxx',
node_aws_attributes=SparkNodeAwsAttributes(is_spot=False),
node_id='xxxxxxxxxxxxxxxxxxxxxx',
private_ip='x.x.x.x',
public_dns=None,
start_timestamp=1718787609346),
driver_instance_pool_id=None,
driver_node_type_id='m5.large',
enable_elastic_disk=True,
enable_local_disk_encryption=False,
executors=[],
gcp_attributes=None,
init_scripts=[],
instance_pool_id=None,
jdbc_port=10000,
last_restarted_time=1718787793228,
last_state_loss_time=0,
node_type_id='m5.large',
num_workers=0,
policy_id='0012F6759FF01DC3',
runtime_engine=<RuntimeEngine.STANDARD: 'STANDARD'>,
single_user_name='username01',
spark_conf={'spark.databricks.cluster.profile': 'singleNode',
'spark.master': 'local[*, 4]'},
spark_context_id=9020288339649455191,
spark_env_vars=None,
spark_version='14.3.x-cpu-ml-scala2.12',
spec=None,
ssh_public_keys=None,
start_time=1718787415576,
state=<State.RUNNING: 'RUNNING'>,
state_message='',
terminated_time=None,
termination_reason=None,
workload_type=None)
この情報から、例えばcreator_user_nameからクラスター作成者、driver_node_type_id>からクラスターサイズ等の起動中のクラスター情報が確認できます。今回はDatabricks SDK for pythonで取得したクラスターの情報をそのまま転送していますが、 Lambda関数のコード内容を修正すれば、必要な情報のみ通知メールの本文に含めるようにすることもできます。
この通知メールの受信時刻やログの情報を確認してクラスターの起動状態を把握することで、databricksの運用管理者は下記のような対策を実行して、意図しないライセンス費用を抑制できるようになると思います。
- クラスター利用者に停止可否を確認して、クラスターポリシーの設定を見直す。
- 起動中のクラスターをワークスペース管理者権限で停止する。
このようなクラスターの起動状態監視の仕組みが存在していると、databricks運用管理者に通知メールが来ない間は、少なくとも常時起動してコストがかかり続けているクラスターが存在しないことになるので、クラウド破産しないことの安心感が増すように思います。
本手法の拡張
本記事で対象とした汎用クラスターやSQLウェアハウス以外にも、起動時間に応じてライセンス料金がかかるdatabricksのサービスとしては、モデルサービングやベクトル検索用エンドポイントがあります。これらのdatabricksクラスター以外のサービスに対しても、本記事の方法を流用・拡張することで、同様に監視対象に含めることができると思います。