はじめに
AWSが提供する代表的なDBサービスには、クラウド前提で設計されたRDBのAmazon Aurora、 データ分析特化型RDBのAmazon Redshift、ワイドカラム型DB(NoSQL)のAmazon DynamoDB1があります。AWSの各DBサービスの使い分けについては、一般的には概ね業務系システムのDBにはAuroraやDynamoDB、分析系システムのDBにはRedshiftを利用すれば良いとされていますが2、その根拠について定量的に確かめてみたいと思ったので、実際にOLTP/OLAPワークロード別の負荷をかけて各DBサービスの性能特性の違いについて確認してみました。
※実際のシステム性能は様々な条件により変動します。あくまでも参考情報の一つとして捉えていただきますようお願いします。
前提知識
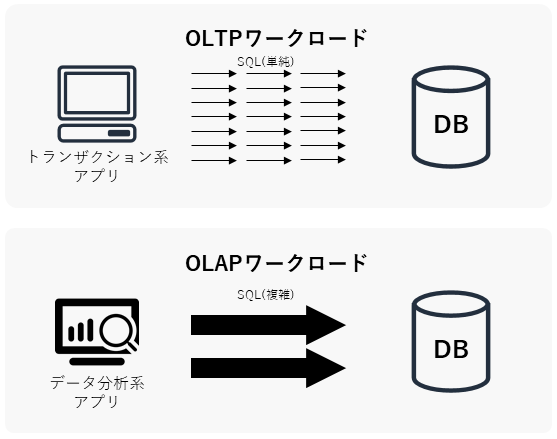
まず前提となる考え方として、OLTP/OLAPワークロードについて概説しておきます。OLTP/OLAPは、データウェアハウスやBI(Business Intelligence)の分野でよく出てくる概念で、DBに対する処理の内容を分類したものです。下図はイメージ図で、図中の矢印の数はSQLの実行頻度を、矢印大きさはSQL単体の負荷の大きさを示しています。
-
OLTP (Online Transaction Processing | オンライントランザクション処理)
- 主に業務系システムから定常的に実行される、単一行の参照/更新/挿入/削除処理。
- SQLクエリの典型例:
SELECT ... FROM A WHERE id = N;UPDATE A SET value = 'x' WHERE id = N;INSERT INTO A VALUES (...);DELETE FROM A WHERE id = N;
-
OLAP (Online Analytical Processing | オンライン分析処理)
- 主に分析系システムから一時的に実行される、(表結合を伴う)大量データの集計処理。
- SQLクエリの典型例:
SELECT ..., SUM(A.z) FROM A INNER JOIN B ON ... INNER JOIN C ON ... GROUP BY ...;
OLTPとOLAPのワークロードではそれぞれDBに求められる性能要件が異なるので、システム設計ではワークロード別に複数のDBを使い分ける場合があります。ちなみに昔はオンプレ環境しかなかったので、DBをOLAPの性能要件に対応させるために、ハードウェア一体となった高価なDWHアプライアンス製品を導入したり、通常のOracle Databaseを鬼チューニングしたりしていました。
計測方法
今回は、ワークロード別のDB性能をそれぞれ下記の方法で計測します。
OLTPワークロードの設計
下記の単一行挿入クエリを10万件発行し、スループット(1分あたりの挿入件数)を計測します。
INSERT INTO order_details (order_id, item_id, sales_price, amount)
VALUES (:order_id, :item_id, :sales_price, :amount);
CREATE TABLE order_details( -- 注文明細表
order_id int NOT NULL, -- 注文ID
item_id int NOT NULL, -- 商品ID
sales_price int NOT NULL, -- 売値
amount int NOT NULL, -- 数量
PRIMARY KEY (order_id, item_id) -- 主キー
);
計測対象のDBは下記とします。3
- Aurora Serverless
- PostgreSQL 10.7
- MySQL 5.6.10a
- DynamoDB on-demand
- Redshift
- ra3.4xlarge (12 vCPU, メモリ 96GiB, 2ノード)
OLAPワークロードの設計
下記の5億件のデータを集計するSQLクエリを発行し、応答時間を計測します。
CREATE TABLE sales_order(
order_id int NOT NULL, -- 注文ID
timestamp timestamp NOT NULL, -- 日時
store_id int NOT NULL, -- 店舗ID
customer_id int NOT NULL, -- 顧客ID
total_price int, -- 合計金額
PRIMARY KEY (order_id) -- 主キー
)
sortkey(store_id, timestamp) -- ソートキー(Redshiftのみ)
;
SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order GROUP BY store_id, month;
計測対象のDBは下記とします。4
- Aurora
- PostgreSQL 11.6 db.r5.4xlarge (16 vCPU, 128 GiB)
- Redshift
- ra3.4xlarge (12 vCPU, メモリ 96GiB, 2ノード)
計測結果 (OLTP)
まずは、OLTPワークロードの性能比較から計測結果を載せていきます。
スループット比較
下図は、行挿入ワークロードのスループット(件/sec)の計測結果です。スループットは高いほど良い性能です。負荷かけサーバには、リソース設定を最大にしたAWS Lambdaを利用しました。Aurora Serverlessは他のDBの条件を近づけるため、Data APIとDBアダプタ(psycopg2)の2種類の接続方法で計測しました。
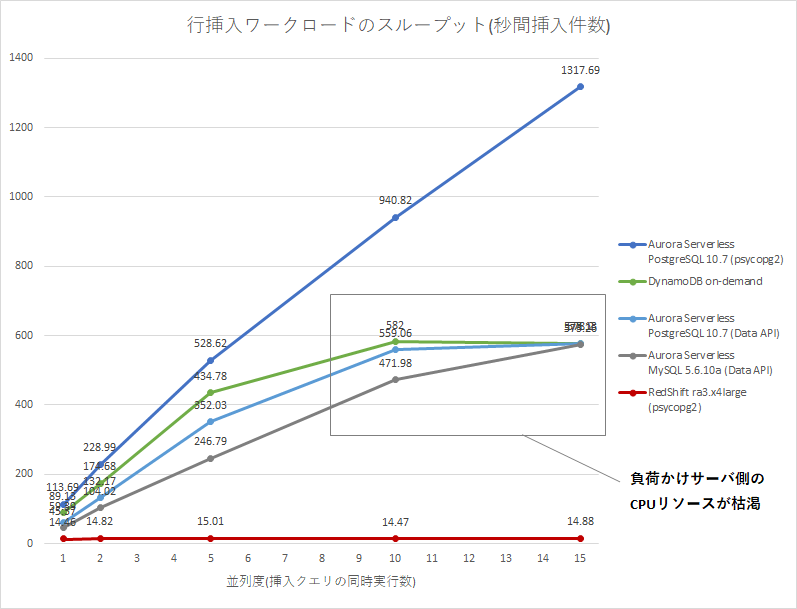
|並列度(p)|Aurora Serverless PostgreSQL 10.7 (psycopg2)|DynamoDB On-Demand|Aurora Serverless PostgreSQL 10.7 (Data API)|Aurora Serverless MySQL 5.6.10a (Data API)|Redshift ra3.x4large (psycopg2)|
|:--|--:|--:|--:|--:|--:|--:|
|p=1|113.69 rows/sec|89.13 rows/sec|59.39 rows/sec|45.37 rows/sec|14.46 rows/sec|
|p=2|228.99 rows/sec|174.68 rows/sec|132.17 rows/sec|104.02 rows/sec|14.82 rows/sec|
|p=5|528.62 rows/sec|434.78 rows/sec|352.03 rows/sec|246.79 rows/sec|15.01 rows/sec|
|p=10|940.82 rows/sec|582.00 rows/sec|559.06 rows/sec|471.98 rows/sec|14.47 rows/sec|
|p=15|1317.69 rows/sec|578.13 rows/sec|578.20 rows/sec|573.26 rows/sec|14.88 rows/sec|
- 並列度(p)は、負荷かけスクリプトの挿入クエリの同時実行数。詳細は付録のスクリプトを参照。
- Aurora Serverlessのキャパシティユニット(ACU)5は、いずれも2 ACUで計測。
結果グラフを確認すると、Aurora Serverless (Data API)とDynamoDBで、並列度10-15のあたりでスループットが頭打ちになっています。これはDB側の問題ではなく、HTTP APIは負荷かけサーバ側にかかるCPU負荷が重いようで、負荷かけサーバ側(Lambda)のCPU負荷がボトルネックになってしまったためでした6。Redshiftに関しては、並列度1からRedshift側の性能限界(約15件/秒)となりました。
計測環境
このスループット性能を計測した際の、システム環境は下図の通りです。DynamoDBはVPC内に配置できないため、VPC endpointを経由してインターネットを介さずに通信するように構成しています。
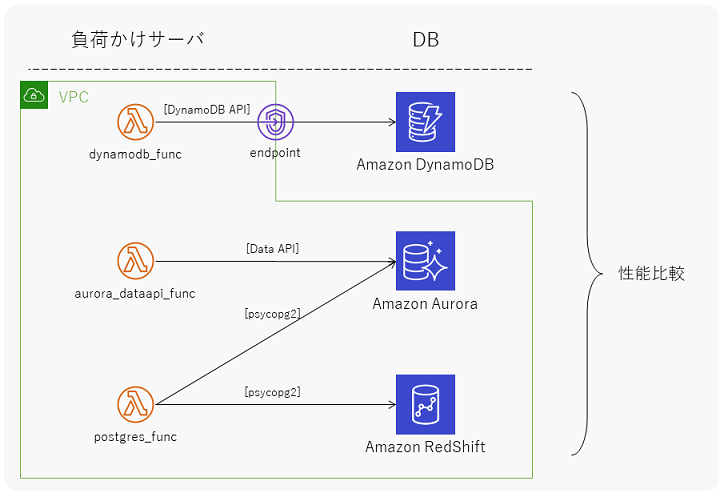
負荷かけスクリプトの内容とLambda関数の設定の詳細については、記事最後の付録を参照してください。
コスト比較
下表は、各DBサービスの1時間あたりのコスト比較です。DynamoDB On-Demandは書込み件数により金額が変動するので、比較のためにスループット1件/secを1 WCU7に換算してプロビジョニング済キャパシティーの料金を記載しました。Aurora Serverlessは、計測時のキャパシティユニット(2 ACU5)の料金を記載しました。
|並列度|DynamoDB
(1WCU=1件/sec, Provisioned)|Aurora Serverless (2 ACU)|Redshift ra3.x4large|
|:--|--:|--:|--:|--:|--:|
|p=1|(89 WCU)
0.06 USD/hour|0.12 USD/hour|3.38 USD/hour|
|p=2|(174 WCU)
0.12 USD/hour|0.12 USD/hour|3.38 USD/hour|
|p=5|(434 WCU)
0.32 USD/hour|0.12 USD/hour|3.38 USD/hour|
|p=10|(482 WCU)
0.35 USD/hour|0.12 USD/hour|3.38 USD/hour|
|p=15|(578 WCU)
0.42 USD/hour|0.12 USD/hour|3.38 USD/hour|
- 2020年6月時点の東京リージョン(asia-northeast1)の料金。
- 小数点第3位以下は切り捨て。
- インスタンス以外にかかる料金(ストレージ容量やIO課金)は一旦無視。
比較表を見ると、秒間約200件以上の挿入クエリが定常的に続くような場合では、Aurora Serverlessの方がコストを抑えられそうです。ただ、定常的な負荷ではない場合では、料金体系がより柔軟なDynamoDBの方がコストを抑えられるケースもありそうです。
確認できたこと
-
RedshiftのOLTP性能(挿入系)は、約15件/秒が限界。
- Auroraでは並列度を上げると秒間1,000件以上の挿入クエリを捌けた一方で、Redshift ra3.x4largeでは約15件/秒で頭打ちになってしまった。
- RedshiftのCPU利用率が2ノードとも約20%で張り付いていたため、Redshiftのリソース制限に引っ掛かったと思われる。
-
DBアダプタ経由とHTTP API経由のDB接続方法で、負荷かけサーバのCPU利用率が10倍以上異なる。
- HTTP経由のクエリ(DynamoDB APIとAurora Data API)は、並列度10-15でLambda側の限界でスループット性能が頭打ちになった。
- 並列度10-15では、Aurora Data APIではCPU利用率90-100%となっていた一方で、psycopg2では10%以下で推移していた。
もしLambdaが性能のボトルネックにならなければ、Aurora ServerlessよりもDynamoDBの方が性能上限が高い(ほぼ無限)はずだと思っていますが、今回はそこまでの負荷はかけられませんでした。Redshiftは、その潤沢なリソースの割には早々に性能が頭打ちになってしまいました。
計測結果 (OLAP)
さてOLTP編はこれで終わりで、次にOLAPワークロードの性能を比較します。RedshiftのOLTPワークロード(挿入計)は悲惨な結果でしたが、そもそもRedshiftはOLAP特化のDBとして設計されているので、ここで本領を発揮してもらいます。
応答時間比較
下図は、OLAPクエリの応答時間(sec)の計測結果です。応答時間は短いほど良い性能です。PostgreSQLの並列度は、parallel_workers系のパラメータで制御できるクエリ並列度8です。
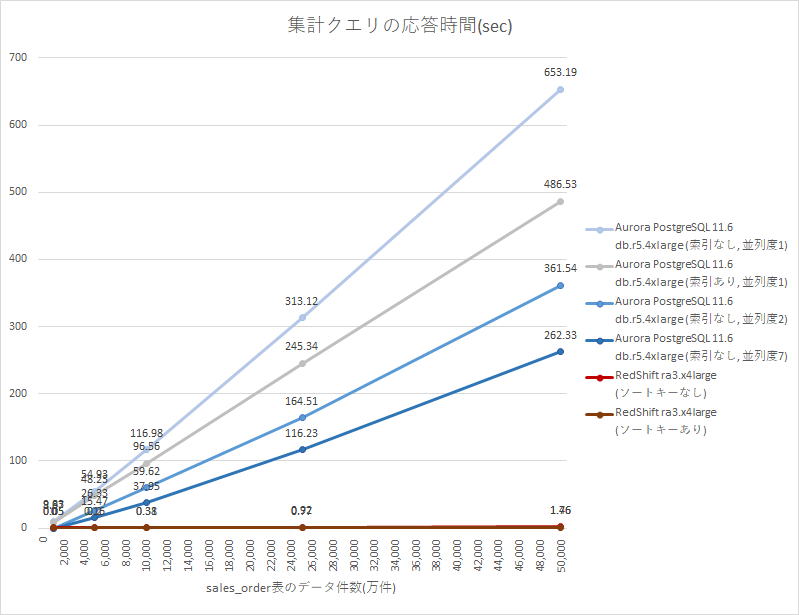
| データ件数 | Aurora db.r5.4xlarge (索引なし,並列度1) |
Aurora db.r5.4xlarge (索引あり,並列度2) |
Aurora db.r5.4xlarge (索引なし,並列度2) |
Aurora db.r5.4xlarge (索引なし,並列度7) |
Redshift ra3.x4large (ソートキーなし) |
Redshift ra3.x4large (ソートキーあり) |
|---|---|---|---|---|---|---|
| 1,000万件 | 9.85 sec | 8.97 sec | - | - | 0.05 sec | 0.05 sec |
| 5,000万件 | 54.93 sec | 48.23 sec | 26.33 sec | 15.47 sec | 0.20 sec | 0.16 sec |
| 10,000万件 | 116.98 sec | 96.56 sec | 59.62 sec | 37.95 sec | 0.38 sec | 0.31 sec |
| 25,000万件 | 313.12 sec | 245.34 sec | 164.51 sec | 116.23 sec | 0.92 sec | 0.77 sec |
| 50,000万件 | 653.19 sec | 486.53 sec | 361.54 sec | 262.33 sec | 1.76 sec | 1.46 sec |
- Aurora PostgreSQLの並列度について、
- 索引ありの条件では、実行計画を並列実行(Parallel Index Scan)に誘導できなかったため並列度1のみ計測。
- データ件数1,000万件の条件では、実行計画を並列実行(Parallel Seq Scan)に誘導できなかったため並列度1のみ計測。
- 最大並列度7について、デフォルトのパラメータグループでは並列度を8よりも大きい値に設定できなかったため、最大7(8 - 1管理接続用プロセス)で計測。
ほぼ同じシステムスペックを持つAurora db.r5.4xlargeとRedshift ra3.x4largeですが、Auroraでは5億件(50,000万件)のデータ集計にチューニング後でも4分以上かかっていたところ、Redshiftでは2秒以下とその1/100以下の時間で処理できました。クエリ並列度をさらに上げたり索引並列スキャンに誘導する等の追加チューニングで、Aurora PostgreSQLの応答時間をもう少し早くすることは可能かもしれませんが、Redshiftの方が圧倒的に高速であることには変わりないでしょう。
計測環境
下記の集計クエリを実行して、応答時間を計測しました。(計測時はORDER BY句は省略)
> SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order GROUP BY store_id, month ORDER BY store_id, month;
store_id | month | sales_by_month
----------+---------------------+----------------
0 | 2014-04-01 00:00:00 | 67222780
0 | 2014-05-01 00:00:00 | 72365720
0 | 2014-06-01 00:00:00 | 69271910
(..省略..)
99 | 2020-02-01 00:00:00 | 70760330
99 | 2020-03-01 00:00:00 | 66501940
時間: 26337.9245 ms
- psqlでDBにログインして
\timing設定をonにし、SQL実行後に表示される時間を計測。 - キャッシュに乗った状態で計測するため、同じSQLを2回実行した2回目の結果を採用。
- PostgreSQLでは、
max_parallel_workersとmax_parallel_workers_per_gatherのパラメータでクエリ並列度を制御。 - Redshiftでは、
SET enable_result_cache_for_session = off;でリザルトキャッシュをOFFに設定。
索引設計
B-tree索引やソートキーを設定する場合は、下記のようにデータの物理配置がstore_id,timestampの順番に並ぶように指定します。
CREATE INDEX sales_order_idx_01
ON sales_order (store_id, date_trunc('month', timestamp), total_price);
PostgreSQLのB-tree索引は、索引生成後に大量データ生成SQLを実行しようとすると長い時間がかかってしまうので、必ずデータ生成後に生成するようにします。Redshiftのソートキーは、CREATE TABLE文で指定します。
コスト比較
下表は、各DBサービスの1時間あたりのコスト比較です。
|Aurora for PostgreSQL db.r5.4xlarge|Redshift ra3.x4large|
|--:|--:|--:|--:|--:|
|2.80 USD/hour|3.38 USD/hour|
- 2020年6月時点の東京リージョン(asia-northeast1)の料金。
- 小数点第3位以下は切り捨て。
- インスタンス以外にかかる料金(ストレージ容量やIO課金)は一旦無視。
AuroraよりもRedShitの方が高価ですが、性能比で考えればRedshiftの方がコスト効率が良いと言えそうです。
確認できたこと
-
RedshiftのOLAP性能は、ほぼ同スペックのAurora PostgreSQLよりも数百倍以上高速。
- Auroraでは4分以上かかる5億件(50,000万件)のデータ集計を、Redshiftでは2秒以下で完了。
-
Aurora for PostgreSQLはチューニングにより2倍以上高速化できたが、無チューニングのRedshiftに及ばない。
- チューニング後でも、依然として100倍以上の応答時間の差がある。
設計ポイント (OLTP/OLAP観点)
以上を踏まえて、データ分析基盤を設計する際にOLTP/OLAPの考え方をどう生かせるかについて話します。
OLTP/OLAP混在システム
OLTP/OLAP両方のワークロードが存在するシステムでは、下図のようにDBを分離するアークテクチャを検討することがよくあります。OLTP DBとは、DynamoDBやAurora等のOLTPワークロードに向いたDBのことで、OLAP DBとは、Redshift等のOLAPワークロードに向いたDBのことを指しています。
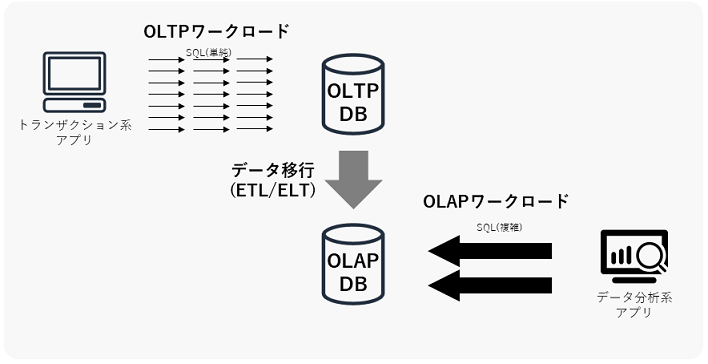
例えば、ECサイトのシステムを設計している場合に、顧客の注文を受け付ける機能はOLTPのワークロードなのでOLTP DBのDynamoDBやAuroraを採用し、週次/月次の売上を集計する機能はOLAPワークロードなのでOLAP DBのRedshiftを採用する、といったDB設計パターンが考えられます。このようなアーキテクチャ構成を取ると、DBの性能を最大限に生かすことができます。
ETLか、ELTか
OLTP DBとOLAP DBを分離して設計する場合は、定期的なDB間のデータ移行についても考えなければなりません。データ分析基盤の分野では、このDB間のデータ移行のことをよくETL(Extract,Transform,Load)と呼びます。ETLは「抽出」「変換」「投入」のそれぞれの頭文字を取ったものですが、下図のようにその順番を変えてELT(Extract, Load, Transform)と呼ぶこともあります。
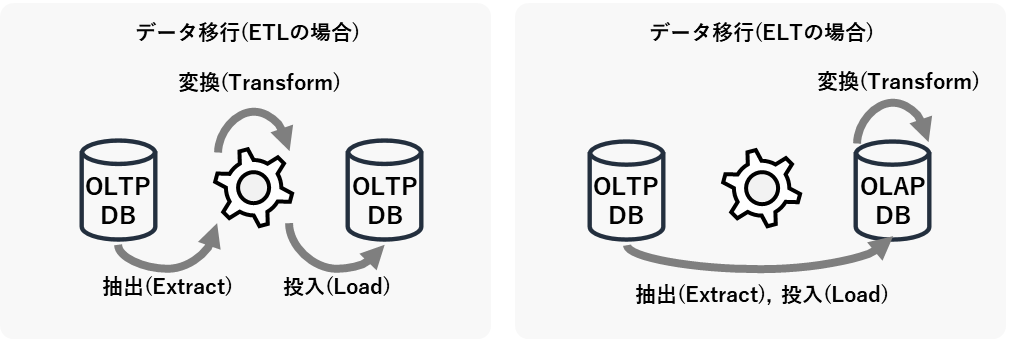
ETLとELTのどちらが良いかは、ケースバイケースです。ETL方式は、DBの性能リソースへの影響を与えにくい利点がある一方で、バッチサーバ(上図の歯車の部分)の処理能力がボトルネックになりやすい欠点があるといえます。OLAP DBに大量データを移行する場合はETLの欠点が顕在化しやすいので、そのような場合はELT方式で実装してデータ移行先のOLAP DBのデータ処理能力を活用するか、データ処理能力に長けたAWS Glueのようなクラウド型のETLサービスを利用することを検討します。
HTAP DB
OLTP DBとOLAP DBの利点を併せ持つDBのことを、HTAP DB(Hybrid Transaction Analytical Processing)と言います。HTAP DBが利用できると、OLTP DBからOLAP DBへのETL/ELT(データ移行)が不要になり、リアルタイムデータをデータ分析に利用できるようになる恩恵を受けられると言われています。
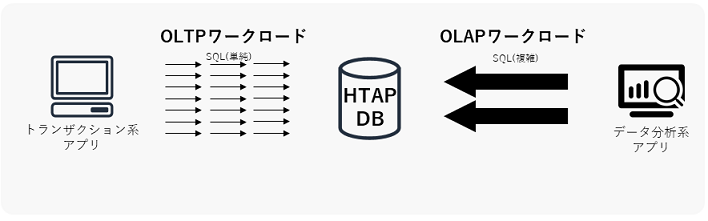
ただし、現在のHTAP技術は少なくとも私の観測範囲内では完全ではなく、既存製品もOLTPかOLAPのどちらかの性能に寄っている傾向があるようなので、現状のデータ基盤設計ではOLTP DBとOLAP DBを分けて構成する方が無難だと個人的には思っています。将来的にはさらに使いやすいHTAP DBが登場するかもしれないので、今後の技術進歩に注目したいです。
まとめ
以上で、Amazon Aurora, Redshift, DynamoDBのワークロード別性能を計測しました。特にRedshiftはOLTP/OLAPワークロードの得意/不得意がはっきりしているので、その特性を理解して適材適所で利用することが重要だと思います。スループットが秒間15件しか出ないからといって、もっとすごい長所があるので叩かないであげてください。
付録
計測環境の構築に関するやや細かい内容について、付録に記載します。
負荷かけスクリプト(OLTP)
- OLTPワークロードのLambda用負荷かけスクリプト。
- スクリプト中の
parallel変数の値で、クエリの並列実行数(pythonプログラムの同時実行プロセス数)を変更可能。 - 実行環境は全てPython 3.7を想定。
DynamoDB
- DynamoDB API(Boto3)を利用してDynamoDBに接続し、挿入クエリを発行する。
import boto3
import random
import time
from datetime import datetime
import multiprocessing
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('order_details') # 挿入先テーブル名
total_num = 100000 # 挿入件数 (可変)
parallel = 10 # 並列度 (可変)
# 親プロセス
def lambda_handler(event, context):
process_list = []
for i in range(parallel):
process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成
start_time = time.time() # 計測開始
for process in process_list:
process.start() # 子プロセス実行開始
for process in process_list:
process.join() # 子プロセス実行完了待ち合わせ
end_time = time.time() # 計測終了
result = {
'total_num': total_num,
'parallel': parallel,
'total time': "{:.2f}".format(end_time - start_time) + " sec",
}
print (result) # コンソール上にも出力
return result
# 子プロセス
def child_proc():
for i in range(int(total_num / parallel)): # (合計件数/並列度)回実行
table.put_item(
Item={
"order_id": int(random.random() * 1000000000), # 注文ID
"item_id": int(random.random() * 10000), # 商品ID
"sales_price": int(random.random() * 100) * 10, # 売値
"amount": int(random.random() * 100), # 数量
}
)
Aurora Serverless DataAPI
- Data API(Boto3)を利用してAurora Serverlessに接続し、挿入クエリを発行する。
- コード中のSECRET_ARNは、Amazon Secrets Managerで生成する。
import boto3
import random
import time
from datetime import datetime
import multiprocessing
total_num = 100000 # 挿入件数 (可変)
parallel = 10 # 並列度 (可変)
rds_data = boto3.client('rds-data')
resource_arn = 'arn:aws:rds:ap-northeast-1:999999999999:cluster:test'
secret_arn = 'arn:aws:secretsmanager:ap-northeast-1:999999999999:secret:test-xxxxxx'
sql = "INSERT INTO order_details (order_id, item_id, sales_price, amount) VALUES (:order_id, :item_id, :sales_price, :amount)"
# 親プロセス
def lambda_handler(event, context):
process_list = []
for i in range(parallel):
process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成
start_time = time.time() # 計測開始
for process in process_list:
process.start() # 子プロセス実行開始
for process in process_list:
process.join() # 子プロセス実行完了待ち合わせ
end_time = time.time() # 計測終了
result = {
'total_num': total_num,
'parallel': parallel,
'total time': "{:.2f}".format(end_time - start_time) + " sec",
}
print (result) # コンソール上にも出力
return result
# 子プロセス
def child_proc():
for i in range(int(total_num / parallel)): # (合計件数/並列度)回実行
parameters = [
{'name':'order_id','value':{'longValue':int(random.random() * 1000000000)}}, # 注文ID
{'name':'item_id','value':{'longValue':int(random.random() * 10000)}}, # 商品ID
{'name':'sales_price','value':{'longValue':int(random.random() * 100) * 10}}, # 売値
{'name':'amount','value':{'longValue':int(random.random() * 100)}}, # 数量
]
try:
response = rds_data.execute_statement(
resourceArn = resource_arn,
secretArn = secret_arn,
database = 'sales',
sql = sql,
parameters = parameters
)
if response["ResponseMetadata"]["HTTPStatusCode"] != 200:
print(response)
except Exception as e:
print(e) # 一意制約違反等のエラーを出力
PostgreSQL, Redshift
- PostgreSQL向けDBアダプタのpsycopg2を利用して、AuroraまたはRedshiftに接続して挿入クエリを発行する。
- 正規のpsycopg2のライブラリをそのままLambdaにアップロードして実行するとエラーとなっため、awslambda-psycopg2を利用。
import psycopg2
import random
import time
from datetime import datetime
import multiprocessing
sql = "INSERT INTO order_details (order_id, item_id, sales_price, amount) VALUES (%s,%s,%s,%s)"
total_num = 100000 # 挿入件数 (可変)
parallel = 10 # 並列度 (可変)
# 接続情報
def get_connection():
return psycopg2.connect(host="db-name.xxxxxxxxxxxx.ap-northeast-1.<rds/redshift>.amazonaws.com", port=<5432/5439>, user="admin", password="xxxxxxxxxxxx", dbname="sales")
# 親プロセス
def lambda_handler(event, context):
process_list = []
for i in range(parallel):
process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成
start_time = time.time() # 計測開始
for process in process_list:
process.start() # 子プロセス実行開始
for process in process_list:
print(process.join()) # 子プロセス実行完了待ち合わせ
end_time = time.time() # 計測終了
result = {
'total_num': total_num,
'parallel': parallel,
'total time': "{:.2f}".format(end_time - start_time) + " sec",
}
print (result) # コンソール上にも結果を出力
return result
# 子プロセス
def child_proc():
with get_connection() as conn:
for j in range(int(total_num / parallel)): # (合計件数/並列度)回実行
order_id = int(random.random() * 1000000000) # 注文ID
item_id = int(random.random() * 10000) # 商品ID
sales_price = int(random.random() * 100) * 10 # 売値
amount = int(random.random() * 100) # 数量
try:
with conn.cursor() as cur:
cur.execute(sql, (order_id, item_id, sales_price, amount))
conn.commit()
except Exception as e:
print(type(e), e) # 一意制約違反等のエラーを出力
Lambda関数の設定
Lambda関数のパラメータ設定を、デフォルト値から下記の値に変更する。
- メモリ割当: 3,008MB(最大)
- 実行時間: 15分(最大)
- 同時実行数の予約: 1
- 非同期呼び出しの再試行数: 0
メモリ割当を最大に設定すると、それに合わせてCPUリソースも最大になる(公式ドキュメント)。同時実行数の予約と非同期呼び出しの再試行数の設定については、この設定をしないとAPI アクションの呼び出しに失敗しました。エラーメッセージ: Network Error (または Rate Exceeded)のエラーが発生してLambda関数が再実行されてしまう場合があったため。実行完了までにかかった時間は、LambdaのUI上からは確認できなかったので、Cloudwatch Logsの出力から確認した。
データ生成 (OLAP)
データ生成SQL
- PostgreSQLの
generate_series関数を利用して、数千万行以上の大量データを生成する。
INSERT INTO sales_order
SELECT
generate_series as order_id, -- 注文ID
timestamp '2014-04-01 00:00:00' + random() * (timestamp '2020-04-01 00:00:00' - timestamp '2014-04-01 00:00:00'), -- 日時
trunc(random() * 100), -- 店舗ID
trunc(random() * 100000000), -- 顧客ID
trunc(random() * 10000) * 10 -- 合計金額
FROM
generate_series(1,50000000); -- データ生成件数を指定 ☆
sales=> select * from sales_order limit 5;
order_id | timestamp | store_id | customer_id | total_price
----------+----------------------------+----------+-------------+-------------
4012545 | 2017-12-11 02:22:17.412715 | 66 | 11732886 | 88080
4012546 | 2014-11-23 10:27:58.553224 | 79 | 39502508 | 17440
4012547 | 2019-09-12 15:34:49.932418 | 56 | 5110535 | 85080
4012548 | 2016-05-13 19:18:07.550354 | 86 | 44695746 | 58170
4012549 | 2016-05-10 15:47:55.556803 | 65 | 14394220 | 68390
このSQLで5億件のデータを生成したところ、Aurora PostgreSQL db.r5.4xlargeインスタンスで約50分かかった。Auroraの料金も起動時間とIO料金を合わせてこれだけで500円以上かかった。
データ移行
Redshiftではgenerate_series関数を利用できないため、今回はPostgreSQLで生成したデータをS3経由でRedShiftに移行した。方法としては、まずは下記コマンドでAurora PosgreSQL(11以降)からS3にデータエクスポートする(公式ドキュメントの手順を参照)。
SELECT *
FROM aws_s3.query_export_to_s3(
'select * from sales_order',
aws_commons.create_s3_uri('<bucket_name>', 'sales_order.csv', 'ap-northeast-1'),
options :='format csv');
そして、エクスポートしたデータをCOPYコマンドでRedshiftにロードする(公式ドキュメントの手順を参照)。
COPY <table_name> FROM 's3://<bucket_name>/<file_path>'
iam_role 'arn:aws:iam::<aws-account-id>:role/<role-name>'
FORMAT csv MAXERROR 10000 COMPUPDATE ON;
エクスポートしたcsvデータファイルに破損データ行が存在していたため、MAXERROR句で破損データ行の許容行数を指定して読み込んだ(性能検証では少数行の差異は誤差の範囲として許容)。エクスポートしたcsvデータファイルのサイズは5億行で約25GBで、Redshiftへのロード時間は約15分かかった。
実行計画(OLAP)
PostgreSQL
- 10,000万件, 索引なし, 並列度7の条件
sales=> EXPLAIN ANALYZE SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order_100m GROUP BY store_id, month ORDER BY store_id, month;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=2793263.25..17409493.29 rows=100000120 width=20) (actual time=35255.091..37910.722 rows=7200 loops=1)
Group Key: store_id, (date_trunc('month'::text, "timestamp"))
-> Gather Merge (cost=2793263.25..15409490.89 rows=100000120 width=20) (actual time=35254.343..37904.037 rows=57600 loops=1)
Workers Planned: 8
Workers Launched: 7
-> Partial GroupAggregate (cost=2792263.11..3073513.45 rows=12500015 width=20) (actual time=35209.875..37738.059 rows=7200 loops=8)
Group Key: store_id, (date_trunc('month'::text, "timestamp"))
-> Sort (cost=2792263.11..2823513.15 rows=12500015 width=16) (actual time=35209.404..36555.793 rows=12500000 loops=8)
Sort Key: store_id, (date_trunc('month'::text, "timestamp"))
Sort Method: external merge Disk: 367000kB
Worker 0: Sort Method: external merge Disk: 368024kB
Worker 1: Sort Method: external merge Disk: 367000kB
Worker 2: Sort Method: external merge Disk: 365976kB
Worker 3: Sort Method: external merge Disk: 368016kB
Worker 4: Sort Method: external merge Disk: 365976kB
Worker 5: Sort Method: external merge Disk: 367000kB
Worker 6: Sort Method: external merge Disk: 367000kB
-> Parallel Seq Scan on sales_order_100m (cost=0.00..891545.19 rows=12500015 width=16) (actual time=0.008..2387.244 rows=12500000 loops=8)
Planning Time: 0.091 ms
Execution Time: 37952.773 ms
Parallel Seq Scan(並列全表スキャン)が7 Workers(並列度7)で実行されている。
- 5,000万件, 索引あり, 並列度1の条件
sales=> EXPLAIN ANALYZE SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order_50m GROUP BY store_id, month;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=0.56..4337021.90 rows=50000000 width=20) (actual time=7.162..48230.888 rows=7200 loops=1)
Group Key: store_id, date_trunc('month'::text, "timestamp")
-> Index Scan using sales_order_50m_idx_01 on sales_order_50m (cost=0.56..3337021.90 rows=50000000 width=16) (actual time=0.027..43732.779 rows=50000000 loops=1)
Planning Time: 0.136 ms
Execution Time: 48235.022 ms
(5 行)
Index Scan(直列索引スキャン)が実行されている。Workerは起動/実行されていない。
Redshift
- 10,000万行の条件
sales=# SELECT plannode || ' ' || info FROM stl_explain WHERE query = 677 ORDER BY nodeid;
?column?
----------------------------------------------------------------------------------------
XN HashAggregate (cost=1999991.84..2488343.60 rows=97670353 width=16)
-> XN Seq Scan on sales_order_100m (cost=0.00..1249994.90 rows=99999592 width=16)
(2 行)
ソートキーの有無で、実行計画の変化はなかった。
-
AWS公式サイトではDynamoDBはワイドカラムストアではなくKVSおよびドキュメント型DBと分類されていますが、代表的なワイドカラムストアであるCassandraがDynamoDBの論文を元に作られていることや、CassandraとDynamoDBのデータの持ち方や性能特性が類似していることから、個人的にはワイドカラムストアの一種と認識してもいいのではと思ってます。 ↩
-
業務系システム/分析系システムについて、業務系システムとは業務自動化/効率化のためのシステム(例:注文販売システムや生産管理システムなど)を、分析系システムとはデータを可視化/分析して洞察を得るためのシステム(例:売上集計システムや財務分析システムなど)を言っています。 ↩
-
Aurora PostgreSQL 11.6 db.r5.4xlarge(16 vCPU, 128 GiB)は、性能が出すぎたので比較グラフからは除外しました。ちなみに計測結果としては、Aurora Serverless PostgreSQL 10.7 (ACU 2)と比較して、約2.5倍から3.0倍ほど良いスループットが出ました。 ↩
-
DynamoDBは集計クエリ(GROUP BY句)に対応していないため、Aurora Servrelessはオートスケーリング機能により安定した性能を計測することが難しかったため、それぞれ比較対象から除外しました。 ↩
-
負荷かけサーバをLambdaからEC2に変更して確認したところ、並列度10-15ではAurora Data APIではCPU利用率90-100%となっていた一方で、psycopg2では10%以下で推移していました。HTTPS通信のための暗号化処理のためのCPU負荷などが原因か? ↩
-
公式ドキュメントの説明には、
1 つの書き込みキャパシティーユニット(WCU)は、最大でサイズが 1 KB までの項目について、1 秒あたり 1 回の書き込みを表します。とあります。 ↩ -
OLTPグラフの並列度(クエリ自体の同時実行数)と、OLAPグラフの並列度(1クエリ内のCPUプロセス並列実行数)の意味の違いに注意。 ↩