🗺️ はじめに
AI 関連のリリースが多く出される今日この頃ですが、
「新しいモデルがリリースされたけど、何がどのくらい伸びたの?」
というのがイマイチわからないな、と思っていました。
そういうときに自分はいつも
- Google の AI モードでサクサク概要を掴む
- Gemini 3 Pro でより深掘りする
- YouTube で解説動画を 2~3本 見て使用感を把握する
のような形で情報収集をしていました。
そんなときに見つけたのが Artificial Analysis というサイトです。
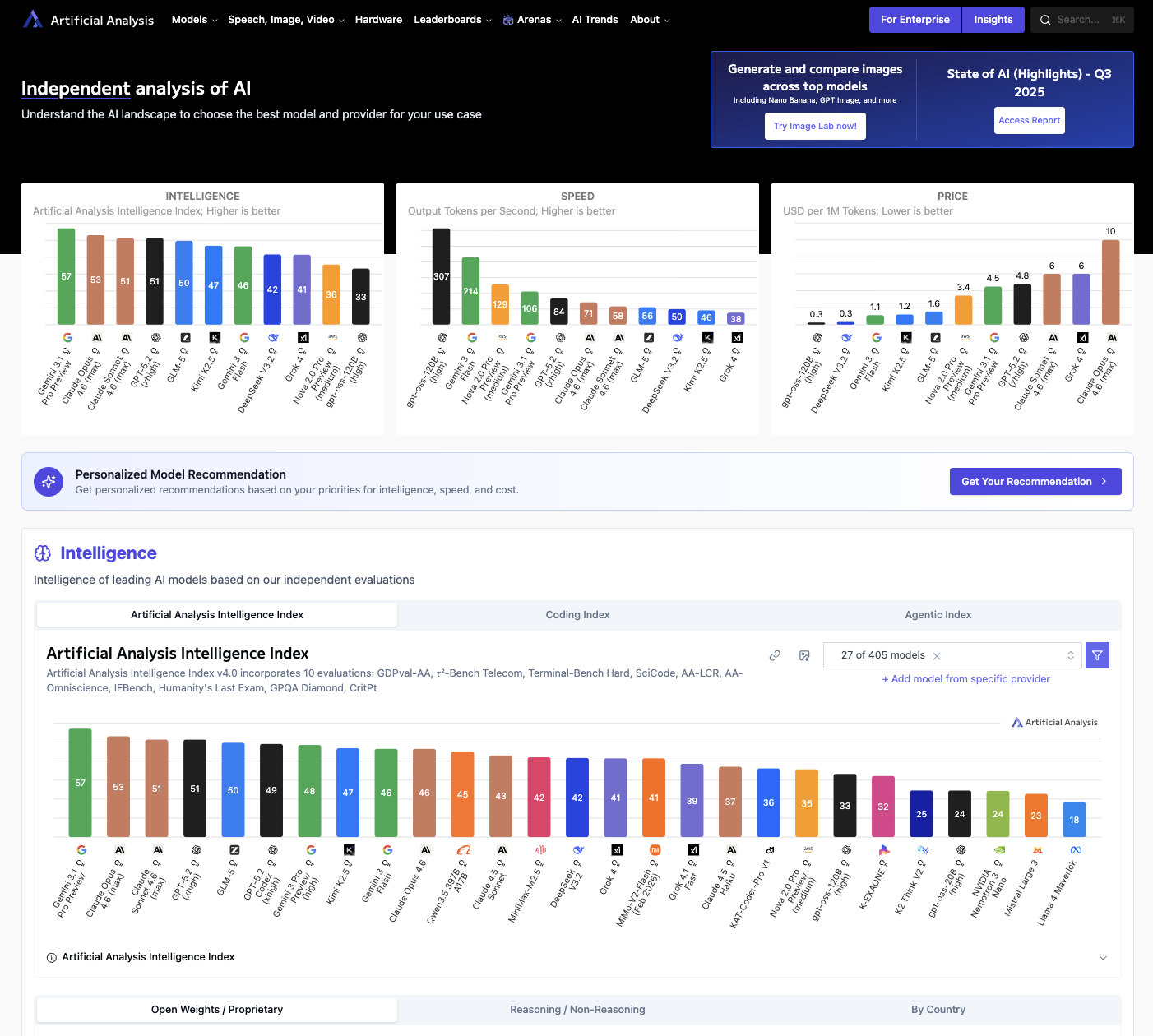
LLM のベンチマーク結果をわかりやすくまとめた比較サイトで、「どのAIがどの能力に優れているか」を一目で確認できます。
...のはずなんですが、
「英語で書かれてるし、謎のグラフばっかりだし、指標の名前ワケわからないし、一体なに?」
という感想が正直なところで、なにもわかりませんでした。
この記事は、そのときの自分に向けて書いています 🙋♀️
📝 この記事で書くこと
Artificial Analysis Intelligence Index に採択されている 10 の評価指標を、4つのカテゴリに分けて
「各指標についてざっくりどういうこと言ってるんだっけ?何がわかるんだっけ?」
というのをまとめます。
Artificial Analysis Intelligence Index とは 🤔
AI の「総合偏差値」を測る指標。
くわしくはこちら: 総合スコア|Artificial Analysis Intelligence Index
できる限りわかりやすく、正確性も担保しながら...
と書いたつもりですがそうでない点があったらすみません🙏
🙋♀️ この記事はこんな人に向け
- ChatGPT, Claude, Gemini などを日常的に使っているが、ベンチマークとかよくわからない
- AI の性能比較を正しくできるようになりたい (そして自慢気に友達や同僚に話したい)
- 過去に Artificial Analysis の大海原に飲み込まれた経験がある
この記事は2026年2月時点の情報をもとにしています。
スコアや順位は執筆後に大きく変わる可能性があります。
最新情報は必ず Artificial Analysis の公式サイトで確認してください。
📊 Artificial Analysis とは?
Artificial Analysis は、LLM の性能・速度・コストを横断的に比較できるサービスです。
単純にスコアを並べるだけでなく、スループット(1秒あたりの出力トークン数)や価格帯なども合わせて確認できるため、
「実用目的でどのモデルを選ぶか」を考えるときに非常に重宝します。
(と言いつつ、自分はただ「なんだかおもしろいから」というだけの理由で見ています)
--
サイト内にある Intelligence Evaluations というセクションが、今回解説する評価指標の一覧です。
ここで各指標ごとのモデル比較グラフを確認できます。
いろんな種類のグラフが、カラフルに表示されていてイケメンな UI です。
でも各指標がなんなのかわかっていないとただ「イケメンだなあ...」と思うだけで
なんの示唆も得ることができません 😿
↑ の状況を打開すべく、各指標が一体なになのかをまとめていきます。
📈 総合スコア|Artificial Analysis Intelligence Index
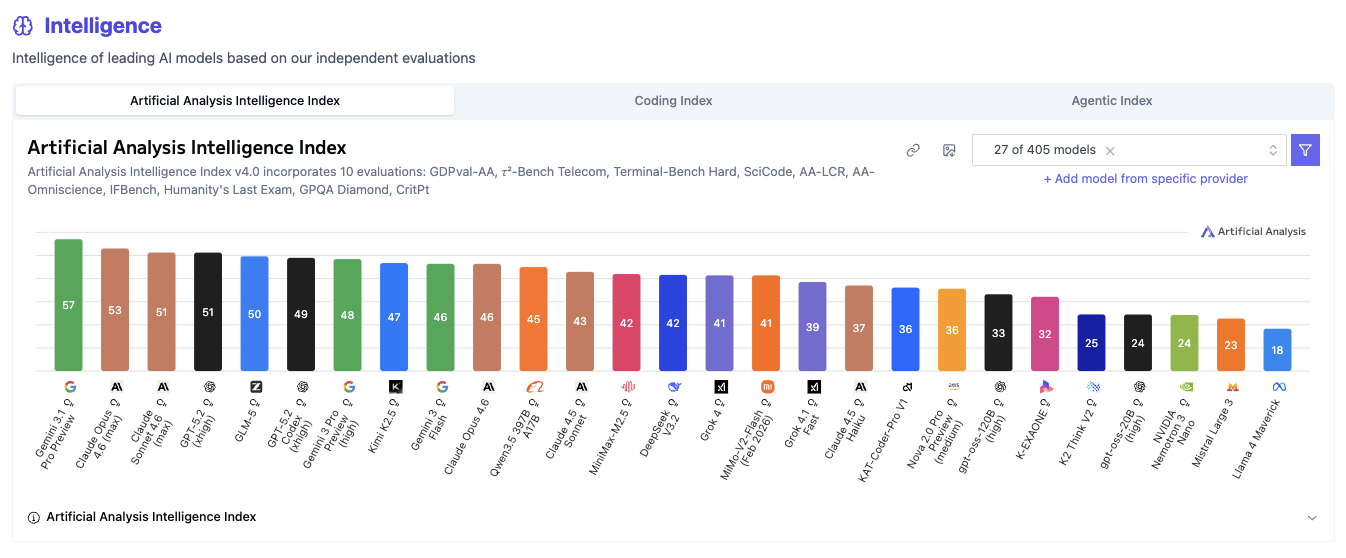
📌 一言で言うと:
AI の「総合偏差値」を測る指標
🔍 何をやらせるか:
エージェント・コーディング・科学的推論・一般知識の4カテゴリにわたる10のベンチマークを統合して1つのスコアにまとめています。
📊 スコアについて:
100点満点で、2026年2月時点ではトップモデルが50〜60点台に集まっています。
「え、50点台?」と思うかもしれませんが、これは意図的な設計です。
旧バージョン(v3.0)ではトップモデルのスコアが73点前後に達してしまい、「差がつかない」問題が起きていました。
2026年1月のv4.0では、飽和しつつあったベンチマークを削除して難しい新項目に差し替え、
スコアが「上がりにくい」状態を維持するように再設計されています。
💬 実用の目安:
「総合的にどのモデルが優秀か」を手早く確認したいときに見る指標です。
ただし総合スコアなので、「得意・不得意の内訳」はほかの指標で補う必要があります。
🧞 指標カテゴリ1|Agentic Workflows(仕事の完遂力)
「調べておいて」と言われたときに、自分でツールを使いこなし、最後まで仕事をやり遂げる力です。
単に答えるだけでなく、複数の手順を自分で考えて動ける「自律的な実行力」をチェックしています。
◼︎ GDPval-AA
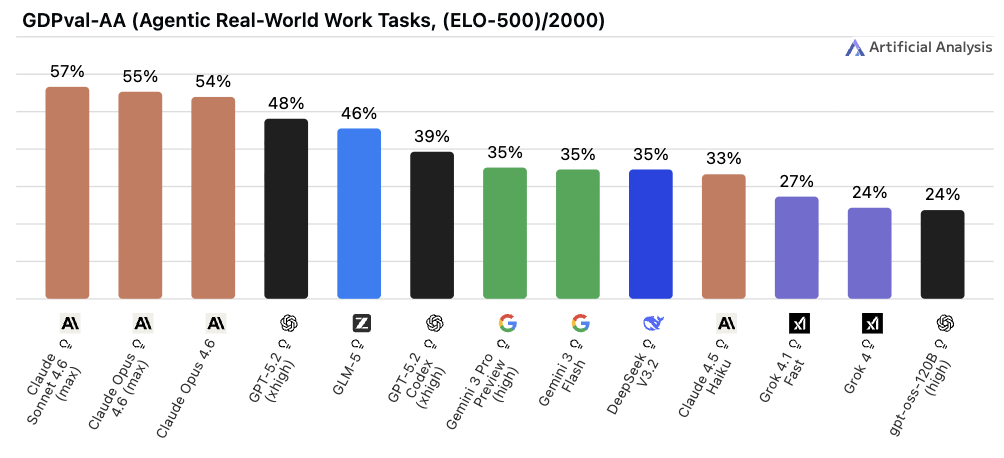
📌 一言で言うと:
「実際の仕事ができるか」を44職種でテストする指標
🔍 何をやらせるか:
現実のビジネス環境(44の職業・9産業)でのタスク遂行能力を測ります。
AI にブラウザやシェルの操作権限を与え、動的な環境の中でタスクを完了できるかどうかを評価します。
ELO レーティングを使うため、人間と AI を同じ尺度で比較できるのが特徴です。
📊 スコアについて:
スコアは % ではなく ELO レーティングで表示されます。2026年1月のトップは GPT-5.2 (xhigh) の ELO 1442 でしたが、1ヶ月足らずで Claude Sonnet 4.6 が ELO 1633 まで急上昇しており、現在最も動きが速い指標のひとつです。なお他の指標で総合首位の Gemini 3.1 Pro はこの指標では上位に届いておらず、「総合で強いモデル ≠ 実務タスクで強いモデル」という逆転現象が起きているのがおもしろいところです。
| 指標 | 問うていること | Gemini 3.1 Pro | Claude Sonnet 4.6 |
|---|---|---|---|
| GPQA Diamond | 博士レベルの科学的推論 | 🥇 94.3%(首位) | 74.1% |
| GDPval-AA | 44職種の実務成果物の質 | ELO 1310(14位) | 🥇 ELO 1633(首位) |
「賢さ」と「仕事ができること」は別の能力だ、という話がここに数値として現れています。
人を採用するときの「頭は良いんだけど、なぜかアウトプットがいまいち」というあの感覚と、同じ構造かもしれません。
💬 実用の目安:
「 AI を業務フローに組み込んで自律的に動かしたい」という場面で特に参考になります。2024〜2025年のエージェント型 AI 進化を最も直接的に反映しており、現在最もスコアの動きが速い指標のひとつです。
ELO レーティングとは 🤔
対戦相手との相対的な「強さ」を数値化する仕組み。基本原則: 勝者が敗者からポイント(レーティング)を奪う。
- 格上に勝つ(番狂わせ): 大量のポイントを奪える。
- 格下に勝つ(順当な結果): もらえるポイントは少ない。
AI 評価に導入する最大の利点は、テスト問題自体の難易度を事前に測る必要がない点にある。
AI と人間に同じタスクを与えて「擬似的な対戦」をさせることで、
「どのレベルの人間に勝てる(同じタスクをこなせる)AI か」を共通の数値で客観的に比較できる。
◼︎ Terminal-Bench Hard
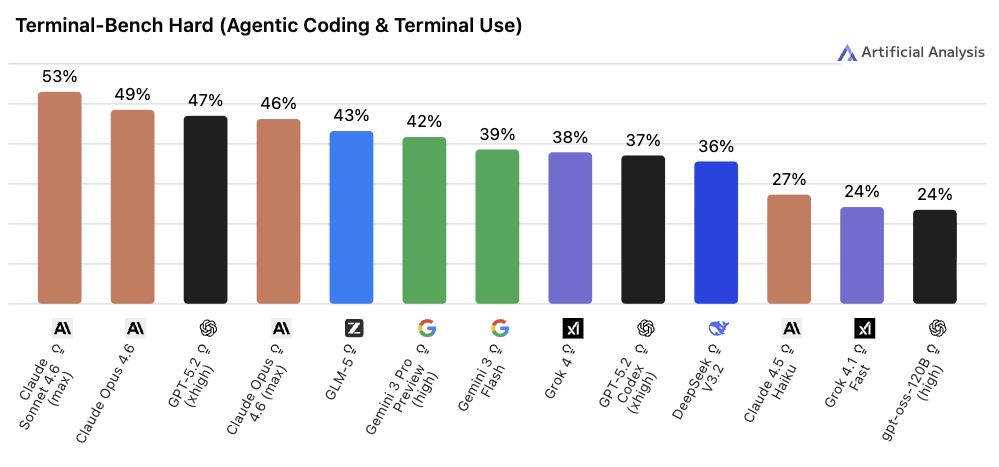
📌 一言で言うと:
ターミナル(コマンドライン)で実際にシステム操作ができるかを測る指標
🔍 何をやらせるか:
実際の OS 環境でシステム設定やデータ処理を行わせ、最終的なシステム状態と正解を自動照合することで、実操作の正確性を評価します。
📊 スコアについて:
2025年11月頃はトップモデルでも 44% 前後に留まっており、まさに「上位モデルでも正答率が限定的」な状況でした。2026年2月時点では Gemini 3.1 Pro Preview が 53.8% でトップに立っていますが、50% 台前半と依然として差がつきやすい水準を保っており、飽和にはほど遠い状態です。
💬 実用の目安:
「エンジニア業務の自動化」を検討する際に参考になります。Artificial Analysis Intelligence Index v4.0(2026年1月)への採用で注目度が上がりました。
◼︎ 𝜏²-Bench Telecom(タウスクエアドベンチ)
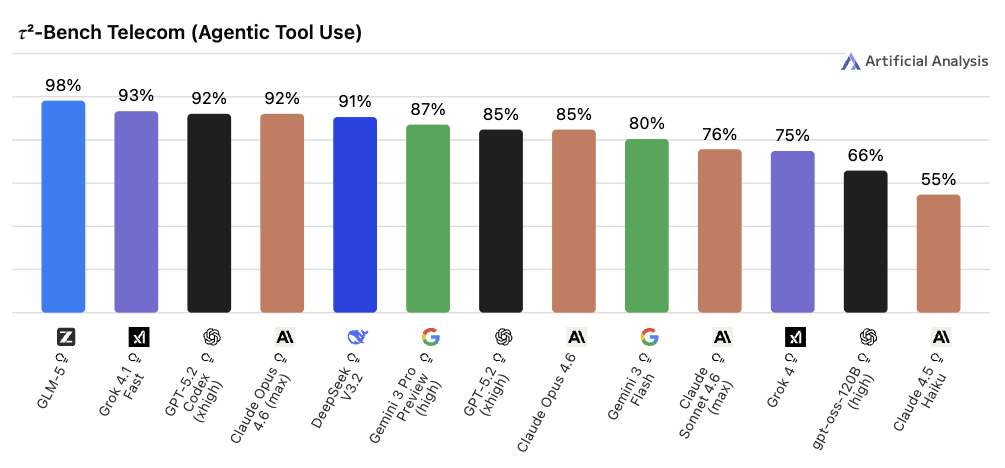
📌 一言で言うと:
テクニカルサポートのような「対話しながら問題を解決する能力」を測る指標
🔍 何をやらせるか:
ユーザーとの対話を行いながら、同時にデータベースや API の操作も伴うトラブルシューティング全体をシミュレーションします。
📊 スコアについて:
2026年2月時点でのトップスコアは98%と非常に高く、上位モデルの多くが90%台後半に集まっています。ベンチマーク登場当初は「単一制御から双方向制御への移行でスコアが大幅に低下する」という論文の報告通り、AI にとって難しい構造でしたが、現在の上位モデルはその壁をほぼ乗り越えた状態です。飽和に近づきつつある指標のひとつと言えます。
💬 実用の目安:
「カスタマーサポートや社内ヘルプデスクに AI を使いたい」という用途で参考になります。比較的新しいベンチマークのため経年データは少ないですが、対話型エージェントの性能向上を追う指標として注目されています。
🛠️ 指標カテゴリ2|Technical Capability(技術的な専門性)
難しい計算や高度なプログラミング、あるいは「教科書数冊分」のような長い資料を正確に読み解く力です。
専門職が使うような、より高度でテクニカルな処理がどれだけ得意かを測ります。
◼︎ SciCode
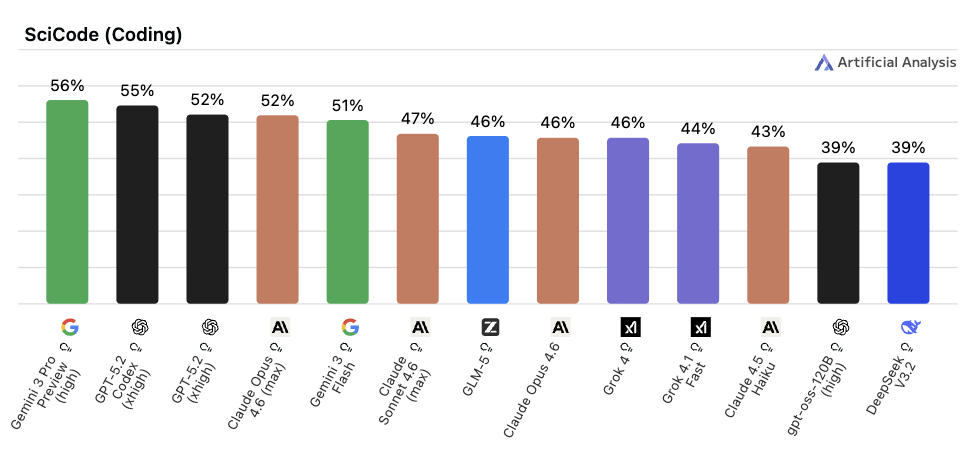
📌 一言で言うと:
「科学研究で使える計算コードが書けるか」を測る指標
🔍 何をやらせるか:
実際の科学論文や研究課題に基づく計算・シミュレーション用コードを生成させ、その実行結果の科学的な正当性を検証します。創薬や素材探索などの「AI for Science」領域での実用性を測る設計です。
📊 スコアについて:
2024年の公開当初、最高スコアは 4.6% と際立って低く、「AI による科学研究支援がまだほとんどできていない」現実を示すものでした。しかし、その後の推論モデルの進化により能力は急激に改善し、現在のトップモデルは50%台後半(最高56.1%)に達しており、急速な改善が続いています。
Gemini 3.1 Pro Preview リリースにより、現在は 59% まで上昇しています。
💬 実用の目安:
科学研究・データサイエンス・数値計算の領域で AI を使いたいときに参考になります。スコアが低かった当初の補助ツール的な立ち位置から、現在では高い推論能力を活かして実用的な科学計算コードを生成する「研究パートナー」として活用できるレベルへと急速に移行しつつあります。
◼︎ AA-LCR(Long Context Reasoning)
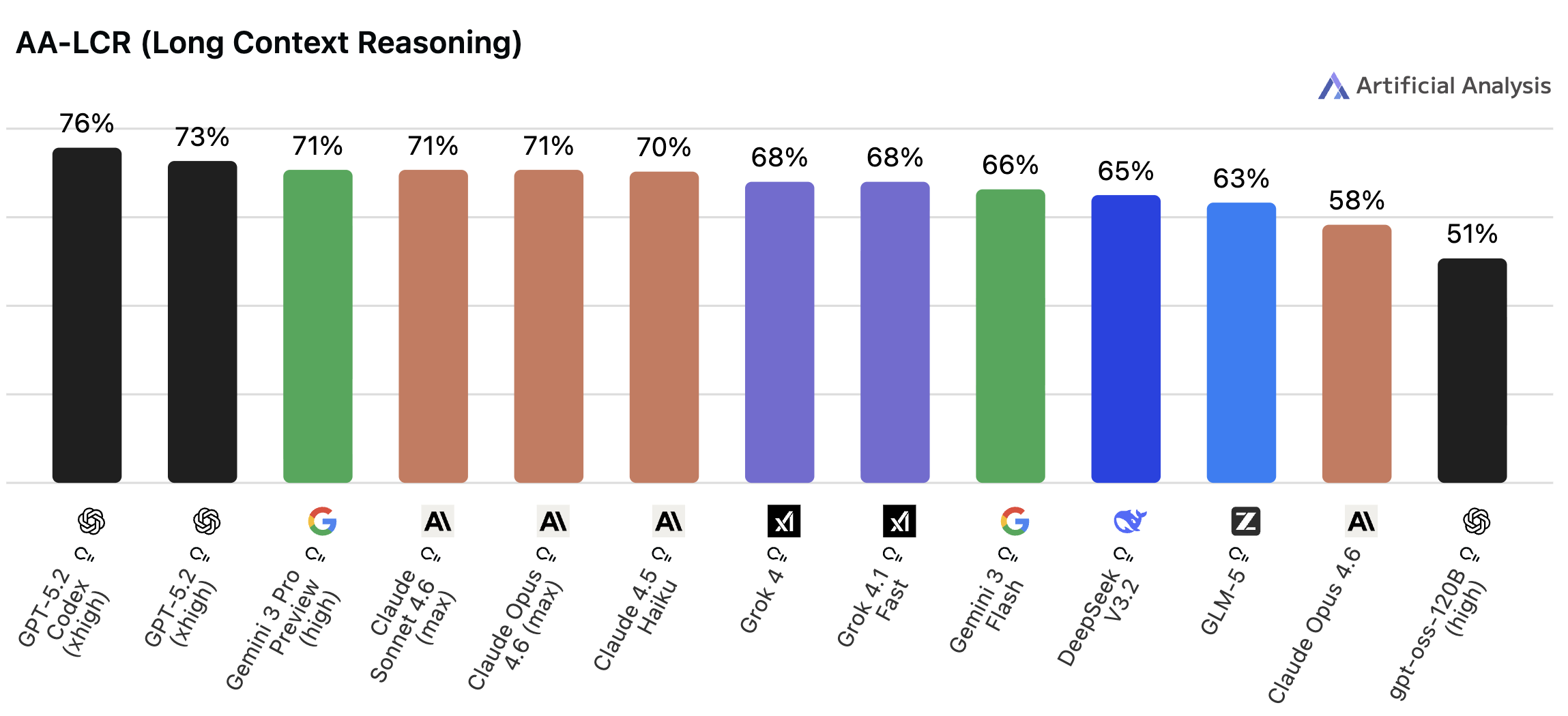
📌 一言で言うと:
「長い文書をちゃんと読んで理解できるか」を測る指標
🔍 何をやらせるか:
1万〜10万トークン(数万〜数十万文字相当)の大規模テキストから、情報を抽出して推論するタスクです。単純な「文中のキーワード探し」ではなく、文書内に分散した複数の情報を統合・推論しなければ解けない問題を使います。
📊 スコアについて:
AA-LCR リリース時(2025年8月)のトップは約 69% で、人間が初見で正解できる 40〜60% をすでに上回っていました。2026年2月時点では GPT-5.2 Codex が 75.7% でトップに立っており、上位モデルが 70% 台に集まっています。ただし飽和にはまだ余地があります。また他の指標と異なり、推論モデルより大きなコンテキストウィンドウを持つ非推論モデルの方が高スコアを出すケースがあるのも読みどころです。
💬 実用の目安:
「契約書の審査」「大規模コードベースの解析」「長い報告書の要約」など、長文処理が業務の核心になる場合に特に重要な指標です。
◼︎ MMLU-Pro
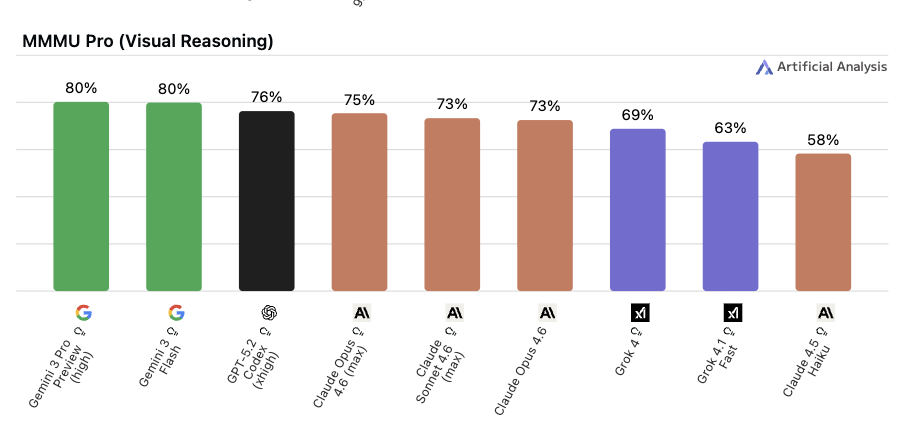
📌 一言で言うと:
「大学院レベルの専門知識と深い推論力」を測る指標
🔍 何をやらせるか:
もともと「MMLU」という有名なベンチマーク(4択問題)がありましたが、AI が高スコアを出しすぎて差がつかなくなってしまいました。 そこで選択肢を 4択 から 10択 に拡張して難易度を上げたのが MMLU-Pro です。消去法や偶然による正答を排除し、実質的な理解と推論を評価します。
📊 スコアについて:
人間専門家の正答率は約 70% 前後と推定でき、2025〜2026年の最先端モデルはすでに70%台に達しています。AI が「専門家水準を超えた」という節目を越えたことで、現在はより難しい HLE や GPQA Diamond へ関心がシフトしています。
MMLU-Pro の原論文には人間専門家の正答率は明示されていません。
参考として、元の MMLU における人間専門家の正答率は約 89.8% とされており、MMLU-Pro はそれより 16〜33% 難しく設計されているため、MMLU-Pro での専門家正答率は 70% 台前後に収まると推測されます。
💬 実用の目安:
専門知識を必要とする業務(法務・医療・研究支援など)でモデルを選ぶときに参考になります。ただしスコアが飽和しつつあるため、差がつきにくくなってきているのも事実です。
📚 指標カテゴリ3|Knowledge & Reliability(知識と正確さ)
知っている知識が正確か、そして「指示通りに動くか」です。
ハルシネーションの少なさや、複雑な制約・指示をどれだけ忠実に守れるか、道具としての「信頼性」を評価します。
◼︎ AA-Omniscience (Knowledge & Hallucination)
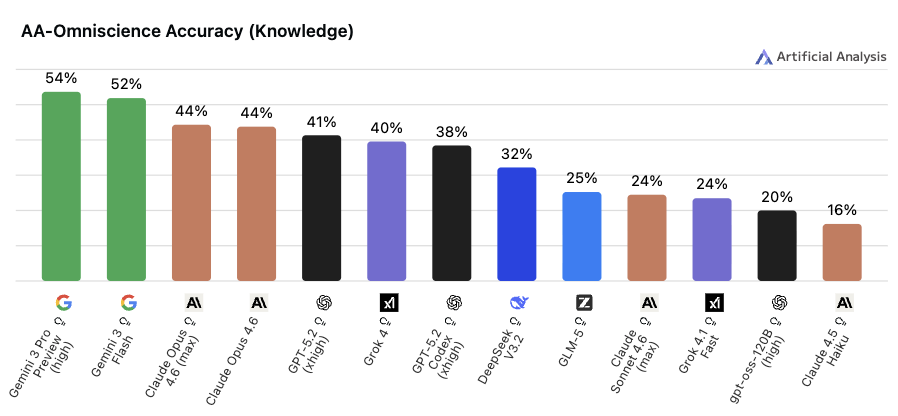
AA-Omniscience Accuracy(Knowledge)
📌 一言で言うと:
「事実に基づく質問に、正しく答えられるか」を測る指標
🔍 何をやらせるか:
明確な正解が存在する事実ベースの質問を使い、AI が正確な知識を出力できているかを検証します。「確信を持って答えられる場合だけ回答する」という設計のため、スコアが低くても「知識量が少ない」とは一概に言えません。
--
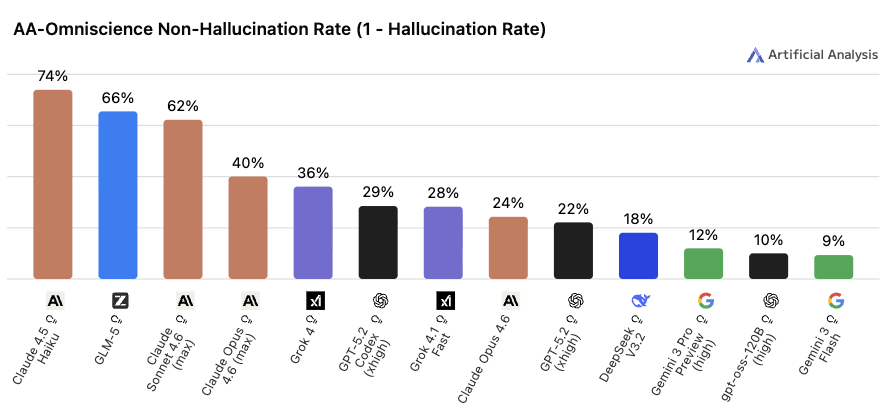
AA-Omniscience Non-Hallucination Rate(1 - Hallucination Rate)
📌 一言で言うと:
「答えた内容のうち、でたらめを言っていない割合」を測る指標
🔍 何をやらせるか:
事実ベースの質問に対してモデルが出力した回答の中から、ハルシネーション(もっともらしい嘘)がどれだけ混入しているかを検証します。スコアは「1 − ハルシネーション率」で算出されるため、高いほど信頼性が高いことを意味します。
--
📊 スコアについて:
最新モデルほど正確性は高まっていますが、ハルシネーション率は依然として無視できない水準です。スコアが高くても「間違いがゼロではない」点に注意が必要です。
💬 実用の目安:
「ビジネスで使うAIの信頼性を確認したい」「誤情報のリスクを下げたい」という場面で見る指標です。ほかの能力が高くてもこのスコアが低いモデルは、業務利用では慎重な運用が必要になります。
◼︎ IFBench
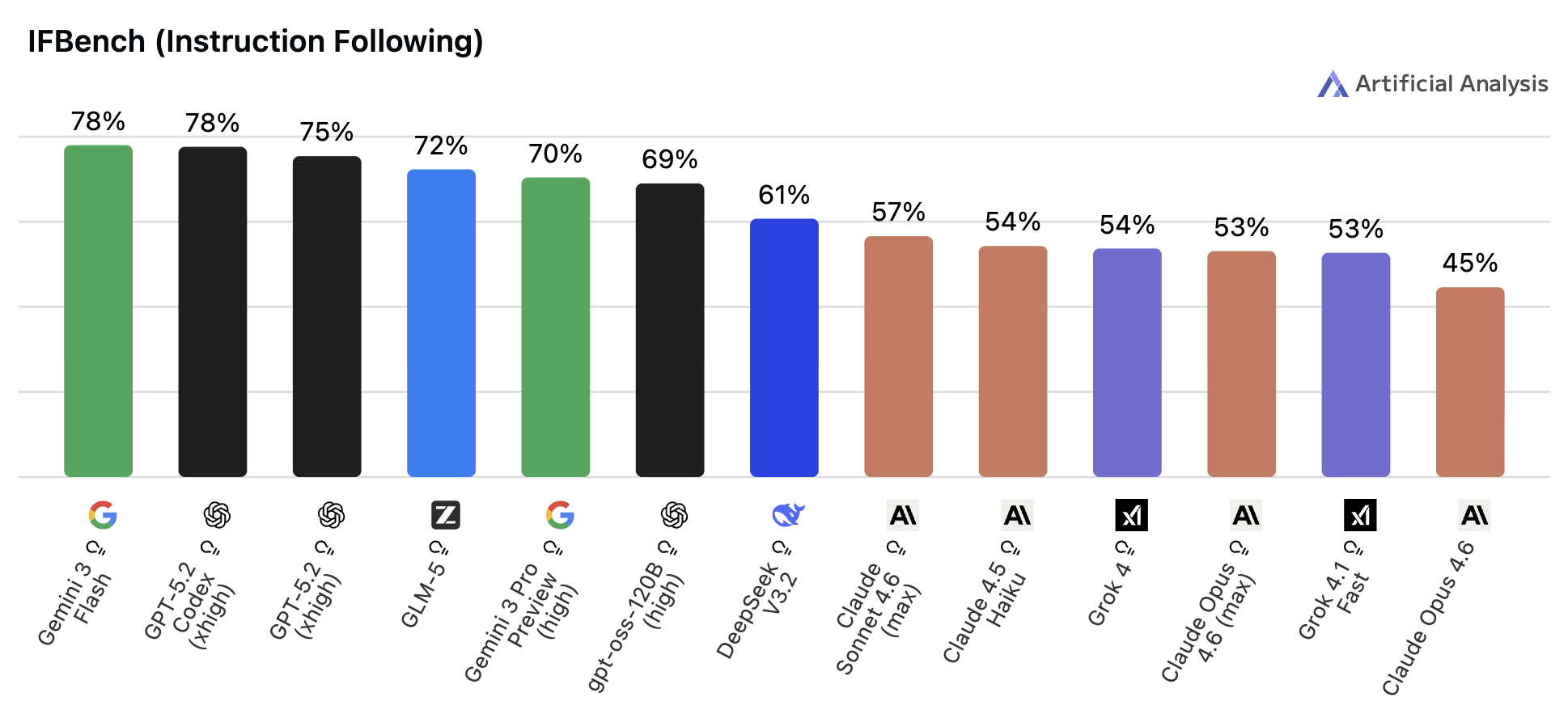
📌 一言で言うと:
「指定されたフォーマットや条件通りに出力できるか」を測る指標
🔍 何をやらせるか:
出力形式(例:JSONフォーマット)や構造に関する客観的な制約を複数設定し、それをどれだけ正確に守れるかを評価します。
📊 スコアについて:
公開当初(2025年7月)は最先端モデルでも正答率が50%以下という状況でしたがその後、モデルの進化は著し2026年2月時点ではトップモデルが70〜80%台に達しています。
前身のIFEvalでは比較的高スコアが出るようになったため、より難しい「未知の制約(OOD制約)」を問うIFBenchが新設されました。まだ飽和には程遠く、AI全体の「苦手な穴」として際立っています。
💬 実用の目安:
AIをシステムに組み込んで出力フォーマットを厳密に管理したい場合(APIレスポンスのJSON生成など)に特に重要です。このスコアが低いモデルは、出力のパースエラーが頻発するリスクがあります。
🧠 指標カテゴリ4|Hard Reasoning(地頭の良さ)
「AIを限界まで追い込む」最難関の思考力を評価します。
検索しても答えが出ないような、最高難易度のパズルや物理の難問を解く力です。
丸暗記が一切通用しない問題で、「未知の課題に対してどこまで深く考え抜けるか」という地頭の強さを試します。
◼︎ Humanity's Last Exam(HLE)
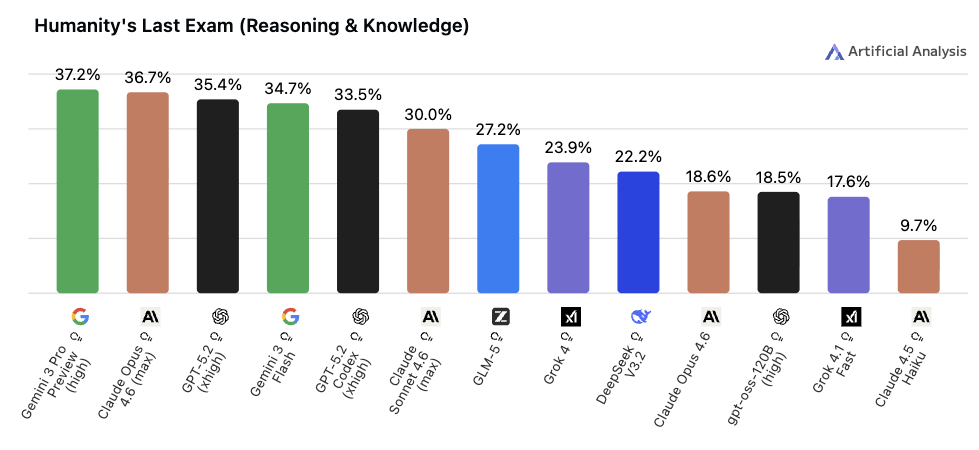
📌 一言で言うと:
「問題を作った専門家自身も全問正解できない最難関」を測る指標
🔍 何をやらせるか:
既存の学習データに含まれない新規に作成・検証された問題を使用しており、「暗記による正答」の影響を排除しています。名前の通り「人類最後の試験」という位置づけで、AI の現在の限界を示す役割を担っています。
📊 スコアについて:
2025年初頭の公開時はトップモデルでも10%未満でしたが、2026年2月時点では最高スコアが37%に到達しています。1年足らずで急上昇しており、今後の飽和が懸念されるものの、多くのモデルはまだ 30% 台に留まっており、差がつく指標として機能しています。
Gemini 3.1 Pro Preview リリースにより、現在は 44.7% まで上昇しています。
💬 実用の目安:
「現時点で AI はどこまでできるのか」という限界を知りたいときに見る指標です。スコアが低くて当然ですが、この数字の変化を追うことで「 AI がどれだけ速く成長しているか」が実感できます。
(直訳で "人類最後の試験" ってすごいですよね🙃)
◼︎ GPQA Diamond
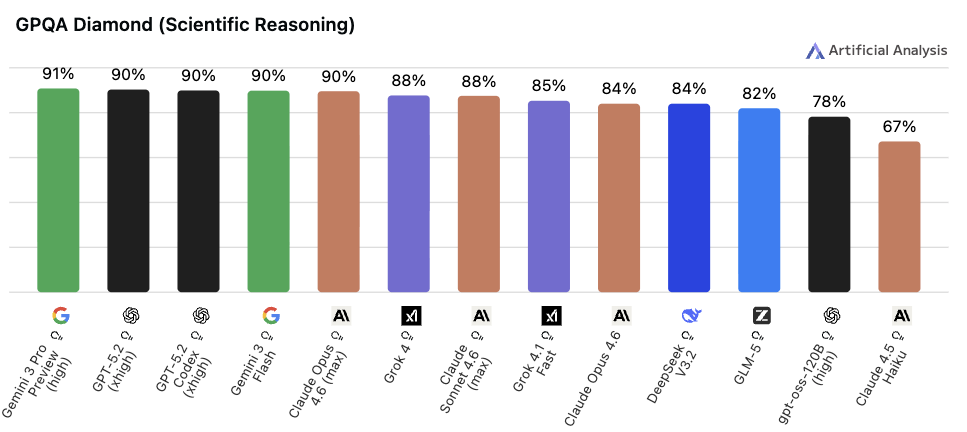
📌 一言で言うと:
「博士号レベルの超難問」を正解できるかを測る指標
🔍 何をやらせるか:
生物学・化学・物理学の各分野の専門家が作成・検証した問題で構成されています。ポイントは「 Google で検索しても答えが出ない」ように設計されていること(通称"Google-proof")。生物・化学・物理のPhD取得者でも正答率は約65〜70%という難易度です。
📊 スコアについて:
GPQA(全448問)がリリースされた 2023年11月時点での最高スコアは GPT-4 の 39% でした。(Diamond はその中でも最難関の198問に絞ったサブセットであるため、Diamond 単体でのスコアはさらに低くなると推定できます)
2025年以降の最先端モデルは Diamond の正答率が 90% に達し、人間のPhD専門家を大きく上回るようになりました。飽和が近づいており、後継ベンチマークの開発が急がれている状況です。
💬 実用の目安:
研究開発の支援や高度な専門的コンサルティングに AI を使いたいときに参考になります。ただし現在はほぼ飽和しているため、モデル間の差をつける力が弱くなっています。
◼︎ CritPt
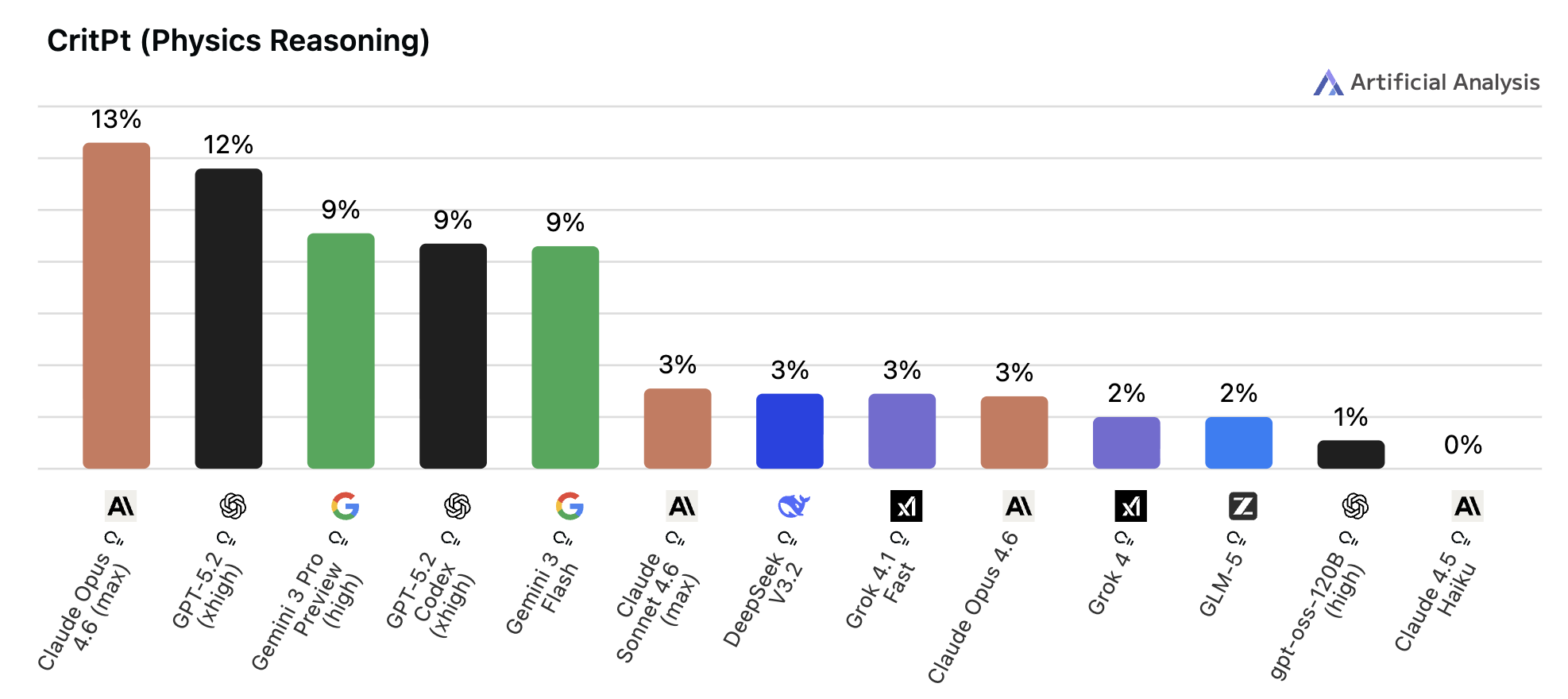
📌 一言で言うと:
「研究レベルの物理学が理解できるか」を測る指標
🔍 何をやらせるか:
凝縮系物理・量子物理・天体物理などの71問の研究レベル問題を使います。公式の単純な適用ではなく、物理法則の理解に基づく数式化や複雑なモデル構築が求められるため、「パターンマッチング」では解けない設計になっています。
📊 スコアについて:
博士号以上の専門家が日常的に扱う難易度で、現在のトップモデルでも正解率は限定的。物理学分野はAIにとって依然として高い壁が残っています。
💬 実用の目安:
物理学・材料科学・天文学などの研究支援にAIを活用したいときに参考になります。Artificial Analysis Intelligence Index v4.0(2026年1月)で新採用された新しいベンチマークです。
🤔 結局どの指標を見ればいい?
「この指標がこういう役割を果たしているんだとしたら、こういう時にはこの指標見ると参考になりそうだよね」
というのをなんとなく自分なりにまとめてみました。
APIやシステムに組み込んで、かっちり動かしたい
見るべき指標:
IFBench / Terminal-Bench Hard
理由:
Webアプリケーションの裏側でJSONを出力させたり、厳格なフォーマットを要求したりする場合、地頭の良さよりも「指示された制約を完璧に守る能力」が大事かなと思い IFBench を選びました。
システム操作でコマンド操作するなら Terminal-Bench Hard も見ておく方がいいかなと思います。
業務フローを自律的に遂行させたい(エージェント化)
見るべき指標:
GDPval-AA / 𝜏²-Bench Telecom
理由:
ユーザーの指示を待つだけでなく、自らツールを使い問題解決まで導く能力が求められるため、𝜏²-Bench Telecom で対話しながら課題を特定できるかを測り、GDPval-AA で人間と同等のタスク完遂力があるかを測るイメージです。
膨大な仕様書やドキュメントを読み込ませて分析したい
見るべき指標:
AA-LCR / AA-Omniscience
理由:
プロダクトの要件定義書や長文の技術ドキュメントを読み込ませる場合、
広大なコンテキストから正確に情報を抽出する力 AA-LCR と、ハルシネーションを起こさない信頼性 AA-Omniscience が必要と思い選定しました。
専門的な研究や、未知の課題解決の壁打ち相手が欲しい
見るべき指標:
Humanity's Last Exam (HLE) / SciCode
理由:
シンプルに地頭の良さを測る Humanity's Last Exam (HLE) と科学的推論を測る SciCode を見ておく感じかなと思います。
🍭 おまけ: 2026/01 にあった [v3 → v4] 指標アップデートについて
実は先述の10指標は 2026年1月に3つ入れ替わったばかり なんですが、
「賢さの定義の変化に応じて、AI の性能を測るための指標も変化する」
ということが起きているみたいです。
消えた3指標と、その理由
MMLU-Pro・LiveCodeBench・AIME 2025 の3つが削除されました。
理由はひとことで、「スコアが高くなりすぎて、モデルを比較する道具として機能しなくなったから」です。
| 削除された指標 | 削除時点のトップスコア |
|---|---|
| MMLU-Pro | Gemini 3 Pro 89.8% / Claude Opus 4.5 89.5% |
| LiveCodeBench | Gemini 3 Pro 91.7% / Gemini 3 Flash 90.8% |
| AIME 2025 | オープンソースモデルが97%(有償モデルと同等) |
卑近な例にすると
「みんながテストで高得点取っちゃうから、テストの意味なくなってるよ!」
という話だと自分は理解しました。
新しく追加された3指標
| 追加された指標 | ひとことで |
|---|---|
| GDPval-AA | 44職種の実務タスクをエージェントとして遂行 |
| AA-Omniscience | 知識の正確さ+ハルシネーション率を同時に測定 |
| CritPt | 現役研究者50名以上が作った物理学フロンティア問題 |
どれもまだトップスコアは低くて余裕がある状態みたいですが、
「半年・1年後にはどうなってるかわからない」と考えると AI の進化って凄まじいですね...
変化のポイントを簡潔に
- 削除:「知識の暗記・静的な正答率」を問う指標
- 追加:「実際に業務をこなせるか・でたらめを言わないか」を問う指標
"intelligence is being measured less by recall
and more by economically useful action."
— Aravind Sundar
「知性の証明は、物知りであることから、仕事ができることへ移行しつつある」
↑ ある研究者の言葉ですが、つまりそういうことなんだと思います。
思ったこと
個人的には「知性があること」「仕事ができること」はある程度の相関はあれど根本的には別の話と思っているんですが、
これまで使っていた指標 (知識の有無で賢さを測る) だともうワークしないから、
なんらか別の方法で賢さを測らないと...! ということでいろいろけ検討や工夫がされていまの形になっているんだろうなあと想像しました。
『"知性があること" を測るための先行指標が [知識があること → それを利活用して便益が得られること] に変化している』と捉えると、
「[知識 → 便益] の橋渡しをしているもの (つまり矢印それ自体) が知性なんだな」と思えて、
ということは知識が知性の源であると解釈することができて、
「つまり AI がどんだけ賢くなっても勉強をする ( ≒ 知識を強化する) ことは人間にとって必要だ!」と思ったんですが、
その次の瞬間には「あれ、でも便益それ自体の価値がなくなったら意味なくね?」と思って、
向上心がなくなりかけつつ
「いや、そもそも勉強って便益のためにやってるのか?」
「世界を、外界から得られるインプットを、より瑞々しく受け取って、深く咀嚼して味わうためにやってるのでは?」
「そうに違いない、人生をより豊かにするために、前向きに生きよう」
という謎の着地をしたところで、この記事の締めとしたいと思います。
ありがとうございました!🐟